If the cluster becomes unavailable, the DB Console and Cluster API will also become unavailable. You can continue to monitor the cluster via the and .
Built-in monitoring tools
CockroachDB includes several tools to help you monitor your cluster’s workloads and performance.If a cluster becomes unavailable, most of the monitoring tools in the following sections become unavailable. In that case, Cockroach Labs recommends that you consult the . To maintain access to a cluster’s historical metrics when the cluster is unavailable, configure a like Prometheus or Datadog to collect metrics periodically from the . The metrics are stored outside the cluster, and can be used to help troubleshoot what led up to an outage.
DB Console
The collects time-series cluster metrics and displays basic information about a cluster’s health, such as node status, number of unavailable ranges, and queries per second and service latency across the cluster. This tool is designed to help you optimize cluster performance and troubleshoot issues. The DB Console is accessible from every node athttp://<host:<http-port, or http://<host:8080 by default.
The DB Console automatically runs in the cluster. The following sections describe some of the pages that can help you to monitor and observe your cluster. For more information on accessing the DB Console, see .
Metrics dashboards
The , which are located within Metrics in DB Console, provide information about a cluster’s performance, load, and resource utilization. The Metrics dashboards are built using time-series metrics collected from the cluster. By default, metrics are collected every 10 minutes and stored within the cluster, and data is retained at 10-second granularity for 10 days , and at 30-minute granularity for 90 days. To learn more, refer to . Each cluster automatically exposes its metrics at an , enabling you to collect them in an external tool like Datadog or your own Prometheus, Grafana, and AlertManager instances. These tools:- Collect metrics from the cluster’s Prometheus endpoint at an interval you define.
- Store historical metrics according to your data retention requirements.
- Allow you to create and share dashboards, reports, and alerts based on metrics.
- Do not run within the cluster, and can help you to investigate a situation that led up to cluster outage even if the cluster is unavailable.
SQL Activity pages
The SQL Activity pages, which are located within SQL Activity in DB Console, provide information about SQL , , and . The information on the SQL Activity pages comes from the cluster’scrdb_internal system catalog. It is not exported via the cluster’s .
Active Session History
This feature is in and subject to change. To share feedback and/or issues, contact Support.
Cluster API
The is a REST API that runs in the cluster and provides much of the same information about your cluster and nodes as is available from the DB Console or the , and is accessible from each node at the same address and port as the DB Console. If the cluster is unavailable, the Cluster API is also unavailable. For more information, see the Cluster API and .crdb_internal system catalog
The crdb_internal system catalog is a schema in each database that contains information about internal objects, processes, and metrics about that database. DBMarlin provides a third-party tool that collects metrics from a cluster’s crdb_internal system catalogs rather than the cluster’s Prometheus endpoint.
If the cluster is unavailable, a database’s crdb_internal system catalog cannot be queried.
For details, see .
Authenticate to API endpoints
To call the HTTP API endpoints on this page usingcurl:
For an insecure or local testing cluster, use HTTP:
curl.
Health endpoints
CockroachDB provides two HTTP endpoints for checking the health of individual nodes. These endpoints are also available through the under/v2/health/.
If the cluster is unavailable, these endpoints are also unavailable.
/health
If a node is down, thehttp://<host:<http-port/health endpoint returns a Connection refused error:
200 OK status response code with an empty body:
/health endpoint does not returns details about the node such as its private IP address. These details could be considered privileged information in some deployments. If you need to retrieve node details, you can use the /_status/details endpoint along with a valid authentication cookie.
/health?ready=1
Thehttp://<node-host:<http-port/health?ready=1 endpoint returns an HTTP 503 Service Unavailable status response code with an error in the following scenarios:
- The node is in the . This causes load balancers and connection managers to reroute traffic to other nodes before the node is drained of SQL client connections and leases, and is a necessary check during .
- The node is . This causes load balancers and connection managers to reroute traffic to other nodes while replicas are rebalanced away from the node.
- The node is unable to communicate with a majority of the other nodes in the cluster, likely because the cluster is unavailable due to too many nodes being down.
-i flag includes the HTTP response status in the curl output. Without -i, curl prints only the response body by default.
200 OK status response code with an empty body:
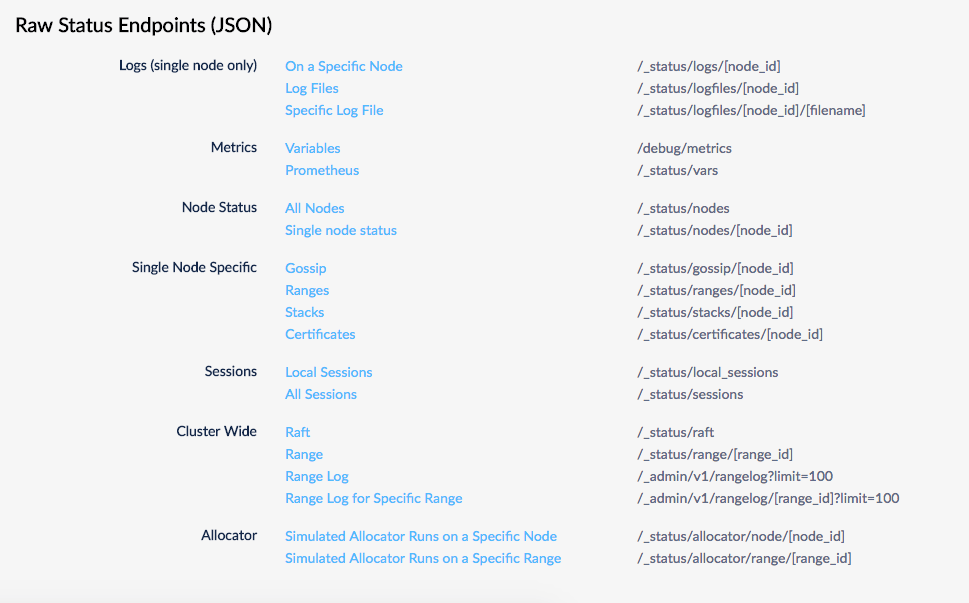
Raw status endpoints
The JSON endpoints are deprecated in favor of the Cluster API.The
/_status/vars metrics endpoint is in Prometheus format and is not deprecated. For more information, refer to .http://<host:<http-port/#/debug. You can investigate and use these endpoints, but note that they are subject to change.
Node status command
The command gives you metrics about the health and status of each node.- With the
--rangesflag, you get granular range and replica details, including unavailability and under-replication. - With the
--statsflag, you get granular disk usage details. - With the
--decommissionflag, you get details about the process. - With the
--allflag, you get all of the above.
Prometheus endpoint
Each node in a CockroachDB cluster exports granular time-series metrics at two available endpoints:Critical nodes endpoint
The critical nodes status endpoint is used to:- Check if any of your nodes are in a critical state. A node is critical if that node becoming unreachable would cause .
- Check if any ranges are . This is useful when determining whether a node is ready for .
- Check if any of your cluster’s data placement constraints (set via or direct ) are being violated. This is useful when implementing or generally.
Request the endpoint
To return the JSON response, send aPOST request to /_status/critical_nodes. For authentication details, refer to Authenticate to API endpoints.
Fields
The JSON object returned by the critical nodes status endpoint contains the following top-level fields.
The
criticalNodes portion of the response contains a (possibly empty) list of objects, each of which has the following fields.
Each report subtype (e.g.,
report.unavailable, report.violatingConstraints, etc.) returns a (possibly empty) list of objects describing the that report applies to. Each object contains a rangeDescriptor and a config that describes the range.
Examples
- Replication status - normal
- Replication status - constraint violation
- Replication status - under-replicated ranges
- Replication status - ranges in critical localities
Replication status - normal
The following example assumes you are running a newly started, local multi-region cluster started using the following command:You may have to wait a few minutes after setting the database regions before getting the ‘all clear’ output above. This can happen because it takes time for to occur in order to meet the constraints given by the .
Replication status - constraint violation
The following example assumes you are running a newly started, local multi-region cluster started using the following command:users table, so you know what to modify.
PRIMARY REGION (us-east1) that they are supposed to be in the europe-west1 locality:
us-east1 locality will now be in a state where they are explicitly now supposed to be in the europe-west1 locality, and are thus in violation of a constraint.
In other words, this tells the ranges that “where you are now is not where you are supposed to be”. This will cause the cluster to rebalance the ranges, which will take some time. During the time it takes for the rebalancing to occur, the ranges will be in violation of a constraint.
The critical nodes endpoint should now report a constraint violation in the violatingConstraints field of the response, similar to the one shown below.
Replication status - under-replicated ranges
The following example assumes you are running a newly started, local multi-region cluster started using the following command:movr database.
movr database. During the time it takes for the rebalancing to occur, these ranges will be considered under-replicated, since there are not yet as many copies (9) of each range as you have just specified.
The critical nodes endpoint should now report ranges in the underReplicated field of the response, similar to the one shown below.
Replication status - ranges in critical localities
The following example assumes you are running a newly started, local multi-region cluster started using the following command:criticalNodes field in the response.
To artificially put the nodes in this demo cluster in “critical” status, we can issue the following SQL statement, which uses to tell the cluster to store more copies of each range underlying the movr database than there are nodes in the cluster.
criticalNodes field of the response.
Store status endpoint
The store status endpoint at/_status/stores provides information about the attached to each of your cluster.
The response is a JSON object containing a stores array of objects. Each store object has the following fields:
For example, to get the status of the stores of nodeID
1, use the following:
Alerting tools
In addition to actively monitoring the overall health and performance of a cluster, it is also essential to configure alerting rules that promptly send notifications when CockroachDB experiences events that require investigation or intervention. Many of the , such as Datadog and Kibana, also support event-based alerting using metrics collected from a cluster’s . Refer to the documentation for an integration for more details. This section identifies the most important events that you might want to create alerting rules for, and provides pre-defined rules definitions for these events appropriate for use with Prometheus’s Alertmanager service.Alertmanager
If you have configured to monitor your CockroachDB instance, you can also configure alerting rule definitions to have Alertmanager detect important events and alert you when they occur.Prometheus alerting rules endpoint
Every CockroachDB node exports an alerting rules template athttp://<host:<http-port/api/v2/rules/. These rule definitions are formatted for easy integration with Alertmanager.
Working with Alertmanager rules
To add a rule from theapi/v2/rules/ rules endpoint, create or edit your alerts.rules.yml file and copy the rule definition for the event you want to alert on. For example, to add a rule to alert you when unavailable ranges are detected, copy the following from the rules endpoint into your alerts.rules.yml file:
alerts.rules.yml file. If you are creating a new alerts.rules.yml file, be sure that it begins with the following three lines:
rules: header. For example, the following shows an alerts.rules.yml file with the unavailable ranges rule defined:
alerts.rules.yml file, reference it in your prometheus.yml configuration file with the following:
prometheus.yml file.
Start Prometheus and Alertmanager to begin watching for events to alert on. You can view imported rules on your Prometheus server’s web interface at http://<host:<http-port/rules. Use the “State” column to verify that the rules were imported correctly.
Events to alert on
Currently, not all events listed have corresponding alert rule definitions available from the
api/v2/rules/ endpoint. Many events not yet available in this manner are defined in the . For more details, see .Node is down
- Rule: Send an alert when a node has been down for 15 minutes or more.
-
How to detect: If a node is down, its Prometheus endpoint will return a
Connection refusederror. Otherwise, theliveness_livenodesmetric will be the total number of live nodes in the cluster. -
Rule definition: Use the
InstanceDeadalert from our .
Node is restarting too frequently
- Rule: Send an alert if a node has restarted more than once in the last 10 minutes.
-
How to detect: Calculate this using the number of times the
sys_uptimemetric in the node’s Prometheus endpoint output was reset back to zero. Thesys_uptimemetric gives you the length of time, in seconds, that thecockroachprocess has been running. -
Rule definition: Use the
InstanceFlappingalert from our .
Node is running low on disk space
- Rule: Send an alert when a node has less than 15% of free space remaining.
-
How to detect: Divide the
capacitymetric by thecapacity_availablemetric in the node’s Prometheus endpoint output. -
Rule definition: Use the
StoreDiskLowalert from our .
Node is not executing SQL
- Rule: Send an alert when a node is not executing SQL despite having connections.
-
How to detect: The
sql_connsmetric in the node’s Prometheus endpoint output will be greater than0while thesql_query_countmetric will be0. You can also break this down by statement type usingsql_select_count,sql_insert_count,sql_update_count, andsql_delete_count.
CA certificate expires soon
- Rule: Send an alert when the CA certificate on a node will expire in less than a year.
-
How to detect: Calculate this using the
security_certificate_expiration_cametric in the node’s Prometheus endpoint output. -
Rule definition: Use the
CACertificateExpiresSoonalert from our .
Node certificate expires soon
- Rule: Send an alert when a node’s certificate will expire in less than a year.
-
How to detect: Calculate this using the
security_certificate_expiration_nodemetric in the node’s Prometheus endpoint output. -
Rule definition: Use the
NodeCertificateExpiresSoonalert from our .
Changefeed is experiencing high latency
- Rule: Send an alert when the latency of any changefeed running on any node is higher than the set threshold, which depends on the variable set in the cluster.
-
How to detect: Calculate this using a threshold, where the threshold is less than the value of the variable. For example,
changefeed.max_behind_nanos > [some threshold].
Unavailable ranges
- Rule: Send an alert when the number of ranges with fewer live replicas than needed for quorum is non-zero for too long.
-
How to detect: Calculate this using the
ranges_unavailablemetric in the node’s Prometheus endpoint output. -
Rule definition: Use the
UnavailableRangesalerting rule from your cluster’sapi/v2/rules/metrics endpoint.
Tripped replica circuit breakers
- Rule: Send an alert when a replica stops serving traffic due to other replicas being offline for too long.
-
How to detect: Calculate this using the
kv_replica_circuit_breaker_num_tripped_replicasmetric in the node’s Prometheus endpoint output. -
Rule definition: Use the
TrippedReplicaCircuitBreakersalerting rule from your cluster’sapi/v2/rules/metrics endpoint.
Under-replicated ranges
- Rule: Send an alert when the number of ranges with replication below the is non-zero for too long.
-
How to detect: Calculate this using the
ranges_underreplicatedmetric in the node’s Prometheus endpoint output. -
Rule definition: Use the
UnderreplicatedRangesalerting rule from your cluster’sapi/v2/rules/metrics endpoint.
Requests stuck in Raft
- Rule: Send an alert when requests are taking a very long time in replication. This can be a symptom of a .
-
How to detect: Calculate this using the
requests_slow_raftmetric in the node’s Prometheus endpoint output. -
Rule definition: Use the
RequestsStuckInRaftalerting rule from your cluster’sapi/v2/rules/metrics endpoint.
High open file descriptor count
- Rule: Send an alert when a cluster is getting close to the .
-
How to detect: Calculate this using the
sys_fd_softlimitmetric in the node’s Prometheus endpoint output. -
Rule definition: Use the
HighOpenFDCountalerting rule from your cluster’sapi/v2/rules/metrics endpoint.