
CockroachDB's flexible replication controls make it trivially easy to run a single CockroachDB cluster across cloud platforms and to migrate data from one cloud to another without any service interruption. This page walks you through a local simulation of the process.
Watch the demo
Step 1. Install prerequisites
In this tutorial, you'll use CockroachDB, the HAProxy load balancer, and CockroachDB's version of the YCSB load generator, which requires Go. Before you begin, make sure these applications are installed:
- Install the latest version of CockroachDB.
- Install HAProxy. If you're on a Mac and using Homebrew, use
brew install haproxy. - Install Go version 1.9 or higher. If you're on a Mac and using Homebrew, use
brew install go. You can check your local version by runninggo version. - Install the CockroachDB version of YCSB:
go get github.com/cockroachdb/loadgen/ycsb
Also, to keep track of the data files and logs for your cluster, you may want to create a new directory (e.g., mkdir cloud-migration) and start all your nodes in that directory.
Step 2. Start a 3-node cluster on "cloud 1"
If you've already started a local cluster, the commands for starting nodes should be familiar to you. The new flag to note is --locality, which accepts key-value pairs that describe the topography of a node. In this case, you're using the flag to specify that the first 3 nodes are running on cloud 1.
In a new terminal, start node 1 on cloud 1:
$ cockroach start \
--insecure \
--locality=cloud=1 \
--store=cloud1node1 \
--listen-addr=localhost:26257 \
--http-addr=localhost:8080 \
--cache=100MB \
--join=localhost:26257,localhost:26258,localhost:26259
In a new terminal, start node 2 on cloud 1:
$ cockroach start \
--insecure \
--locality=cloud=1 \
--store=cloud1node2 \
--listen-addr=localhost:26258 \
--http-addr=localhost:8081 \
--cache=100MB \
--join=localhost:26257,localhost:26258,localhost:26259
In a new terminal, start node 3 on cloud 1:
$ cockroach start \
--insecure \
--locality=cloud=1 \
--store=cloud1node3 \
--listen-addr=localhost:26259 \
--http-addr=localhost:8082 \
--cache=100MB \
--join=localhost:26257,localhost:26258,localhost:26259
Step 3. Initialize the cluster
In a new terminal, use the cockroach init command to perform a one-time initialization of the cluster:
$ cockroach init \
--insecure \
--host=localhost:26257
Step 4. Set up HAProxy load balancing
You're now running 3 nodes in a simulated cloud. Each of these nodes is an equally suitable SQL gateway to your cluster, but to ensure an even balancing of client requests across these nodes, you can use a TCP load balancer. Let's use the open-source HAProxy load balancer that you installed earlier.
In a new terminal, run the cockroach gen haproxy command, specifying the port of any node:
$ cockroach gen haproxy \
--insecure \
--host=localhost:26257
This command generates an haproxy.cfg file automatically configured to work with the 3 nodes of your running cluster. In the file, change bind :26257 to bind :26000. This changes the port on which HAProxy accepts requests to a port that is not already in use by a node and that will not be used by the nodes you'll add later.
global
maxconn 4096
defaults
mode tcp
# Timeout values should be configured for your specific use.
# See: https://cbonte.github.io/haproxy-dconv/1.8/configuration.html#4-timeout%20connect
timeout connect 10s
timeout client 1m
timeout server 1m
# TCP keep-alive on client side. Server already enables them.
option clitcpka
listen psql
bind :26000
mode tcp
balance roundrobin
option httpchk GET /health?ready=1
server cockroach1 localhost:26257 check port 8080
server cockroach2 localhost:26258 check port 8081
server cockroach3 localhost:26259 check port 8082
Start HAProxy, with the -f flag pointing to the haproxy.cfg file:
$ haproxy -f haproxy.cfg
Step 5. Start a load generator
Now that you have a load balancer running in front of your cluster, let's use the YCSB load generator that you installed earlier to simulate multiple client connections, each performing mixed read/write workloads.
In a new terminal, start ycsb, pointing it at HAProxy's port:
$ $HOME/go/bin/ycsb -duration 20m -tolerate-errors -concurrency 10 -max-rate 1000 'postgresql://root@localhost:26000?sslmode=disable'
This command initiates 10 concurrent client workloads for 20 minutes, but limits the total load to 1000 operations per second (since you're running everything on a single machine).
Step 6. Watch data balance across all 3 nodes
Now open the Admin UI at http://localhost:8080 and click Metrics in the left-hand navigation bar. The Overview dashboard is displayed. Hover over the SQL Queries graph at the top. After a minute or so, you'll see that the load generator is executing approximately 95% reads and 5% writes across all nodes:
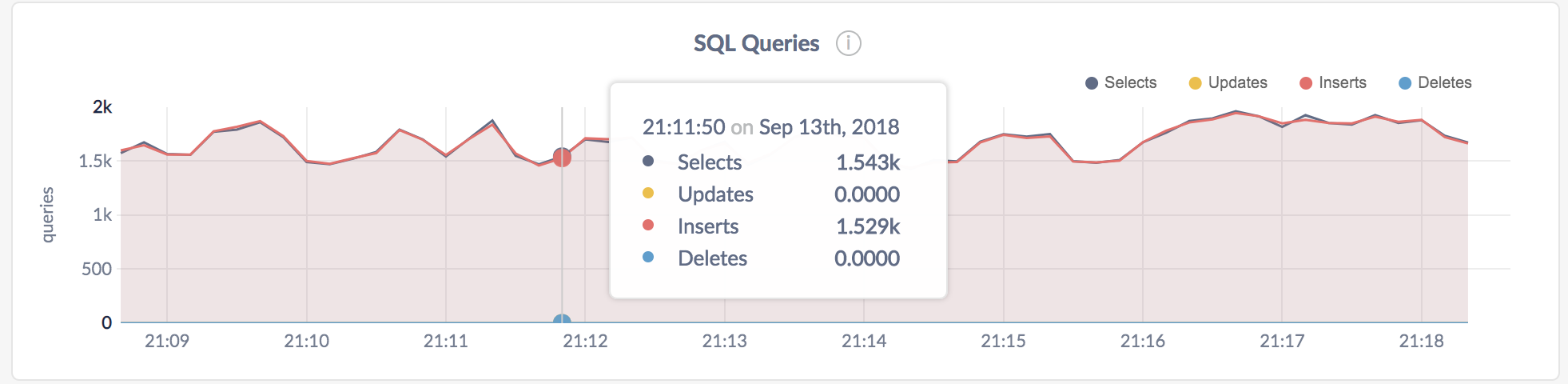
Scroll down a bit and hover over the Replicas per Node graph. Because CockroachDB replicates each piece of data 3 times by default, the replica count on each of your 3 nodes should be identical:
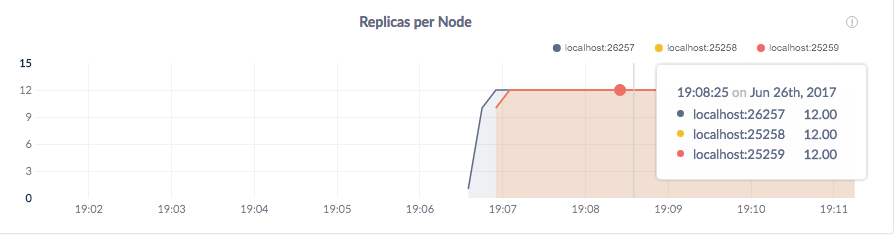
Step 7. Add 3 nodes on "cloud 2"
At this point, you're running three nodes on cloud 1. But what if you'd like to start experimenting with resources provided by another cloud vendor? Let's try that by adding three more nodes to a new cloud platform. Again, the flag to note is --locality, which you're using to specify that these next 3 nodes are running on cloud 2.
In a new terminal, start node 4 on cloud 2:
$ cockroach start \
--insecure \
--locality=cloud=2 \
--store=cloud2node4 \
--listen-addr=localhost:26260 \
--http-addr=localhost:8083 \
--cache=100MB \
--join=localhost:26257,localhost:26258,localhost:26259
In a new terminal, start node 5 on cloud 2:
$ cockroach start \
--insecure \
--locality=cloud=2 \
--store=cloud2node5 \
--advertise-addr=localhost:26261 \
--http-addr=localhost:8084 \
--cache=100MB \
--join=localhost:26257,localhost:26258,localhost:26259
In a new terminal, start node 6 on cloud 2:
$ cockroach start \
--insecure \
--locality=cloud=2 \
--store=cloud2node6 \
--advertise-addr=localhost:26262 \
--http-addr=localhost:8085 \
--cache=100MB \
--join=localhost:26257,localhost:26258,localhost:26259
Step 8. Watch data balance across all 6 nodes
Back on the Overview dashboard in Admin UI, hover over the Replicas per Node graph again. Because you used --locality to specify that nodes are running on 2 clouds, you'll see an approximately even number of replicas on each node, indicating that CockroachDB has automatically rebalanced replicas across both simulated clouds:
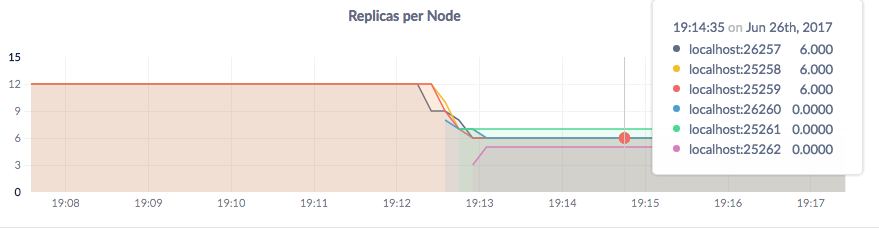
Note that it takes a few minutes for the Admin UI to show accurate per-node replica counts on hover. This is why the new nodes in the screenshot above show 0 replicas. However, the graph lines are accurate, and you can click View node list in the Summary area for accurate per-node replica counts as well.
Step 9. Migrate all data to "cloud 2"
So your cluster is replicating across two simulated clouds. But let's say that after experimentation, you're happy with cloud vendor 2, and you decide that you'd like to move everything there. Can you do that without interruption to your live client traffic? Yes, and it's as simple as running a single command to add a hard constraint that all replicas must be on nodes with --locality=cloud=2.
In a new terminal, edit the default replication zone:
$ cockroach sql --execute="ALTER RANGE default CONFIGURE ZONE USING constraints='[+cloud=2]';" --insecure --host=localhost:26257
Step 10. Verify the data migration
Back on the Overview dashboard in the Admin UI, hover over the Replicas per Node graph again. Very soon, you'll see the replica count double on nodes 4, 5, and 6 and drop to 0 on nodes 1, 2, and 3:
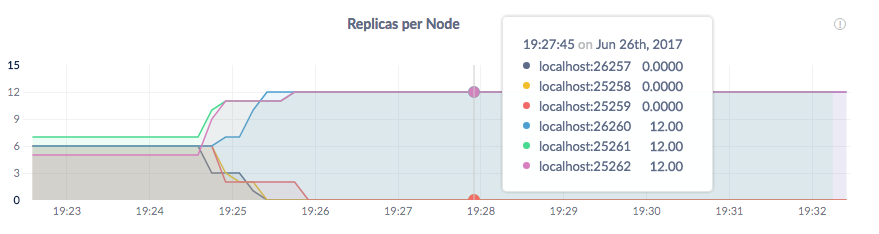
This indicates that all data has been migrated from cloud 1 to cloud 2. In a real cloud migration scenario, at this point you would update the load balancer to point to the nodes on cloud 2 and then stop the nodes on cloud 1. But for the purpose of this local simulation, there's no need to do that.
Step 11. Stop the cluster
Once you're done with your cluster, stop YCSB by switching into its terminal and pressing CTRL-C. Then do the same for HAProxy and each CockroachDB node.
If you do not plan to restart the cluster, you may want to remove the nodes' data stores and the HAProxy config file:
$ rm -rf cloud1node1 cloud1node2 cloud1node3 cloud2node4 cloud2node5 cloud2node6 haproxy.cfg
What's next?
Explore other core CockroachDB benefits and features:
- Data Replication
- Fault Tolerance & Recovery
- Automatic Rebalancing
- Serializable Transactions
- Cross-Cloud Migration
- Follow-the-Workload
- Orchestration
- JSON Support
You may also want to learn other ways to control the location and number of replicas in a cluster:
