While developing an application against CockroachDB, it's sufficient to deploy a single-node cluster close to your test application, whether that's on a single VM or on your laptop.
If you haven't already, review the full range of topology patterns to ensure you choose the right one for your use case.
Prerequisites
- Multi-region topology patterns are almost always table-specific. If you haven't already, review the full range of patterns to ensure you choose the right one for each of your tables.
- Review how data is replicated and distributed across a cluster, and how this affects performance. It is especially important to understand the concept of the "leaseholder". For a summary, see Reads and Writes in CockroachDB. For a deeper dive, see the CockroachDB Architecture documentation.
- Review the concept of locality, which makes CockroachDB aware of the location of nodes and able to intelligently place and balance data based on how you define replication controls.
- Review the recommendations and requirements in our Production Checklist.
- This topology doesn't account for hardware specifications, so be sure to follow our hardware recommendations and perform a POC to size hardware for your use case.
- Adopt relevant SQL Best Practices to ensure optimal performance.
Configuration
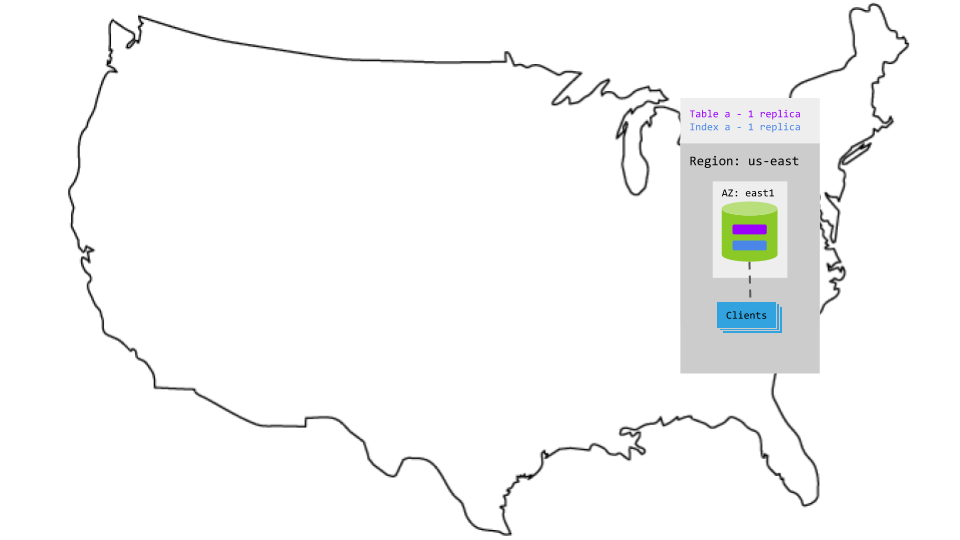
For this pattern, you can either run CockroachDB locally or deploy a single-node cluster on a cloud VM.
Characteristics
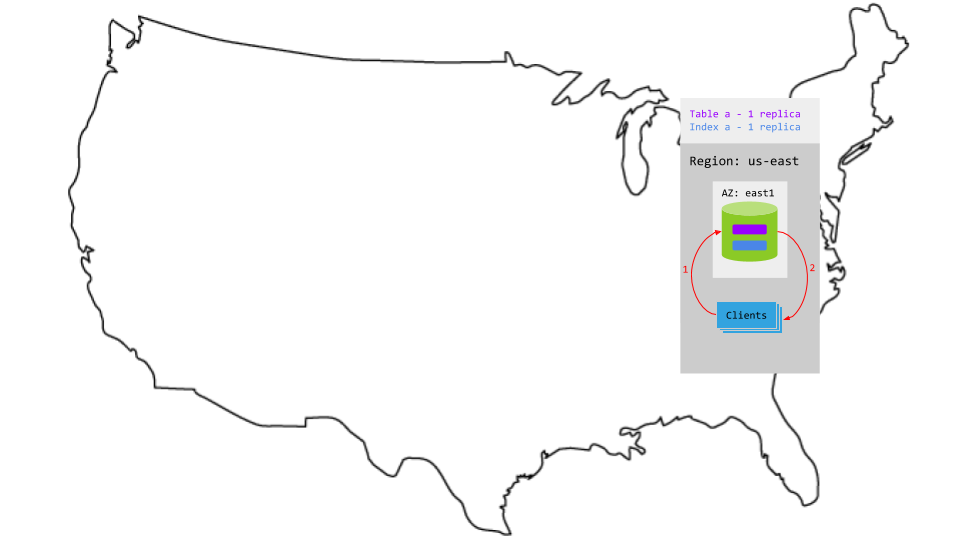
Latency
With the CockroachDB node in the same region as your client, and without the overhead of replication, both read and write latency are very low:
Resiliency
In a single-node cluster, CockroachDB does not replicate data and, therefore, is not resilient to failures. If the machine where the node is running fails, or if the region or availability zone containing the machine fails, the cluster becomes unavailable: