Query issues
Hanging or stuck queries
When you experience a hanging or stuck query and the cluster is healthy (i.e., no , , etc), the cause could be a long-running transaction holding or on the same rows as your query. Such long-running queries can hold locks for (practically) unlimited durations. If your query tries to access those rows, it must wait for that transaction to complete (by or ) before it can make progress. Until the transaction is committed or rolled back, the chances of concurrent transactions internally retrying and throwing a retry error increase. Refer to the performance tuning recipe for . If you experience this issue on a CockroachDB Standard or Basic cluster, your cluster may be throttled or disabled because you’ve reached your monthly .Identify slow queries
You can identify high-latency SQL statements on the or pages in the DB Console. If these graphs reveal latency spikes, CPU usage spikes, or slow requests, these might indicate slow queries in your cluster. You can also enable the to log all queries whose latency exceeds a configured threshold, as well as queries that perform a full table or index scan. You can collect richer diagnostics of a high-latency statement by creating a when a statement fingerprint exceeds a certain latency. To identify slow transactions in an active workload, you can selectively log traces of transactions that exceed a configured latency threshold. If you find queries that are consuming too much memory, to free up memory usage. For information on optimizing query performance, see .Visualize statement traces in Jaeger
You can look more closely at the behavior of a statement by visualizing a in Jaeger. A statement trace contains messages and timing information from all nodes involved in the execution.Run Jaeger
-
Start Jaeger:
This runs the latest version of Jaeger, and forwards two ports to the container.
6831is the trace ingestion port,16686is the UI port. By default, Jaeger will store all received traces in memory.
Import a trace from a diagnostics bundle into Jaeger
- Activate on the DB Console Statements Page or run to obtain a diagnostics bundle for the statement.
-
Go to
http://localhost:16686. -
Click JSON File in the Jaeger UI and upload
trace-jaeger.jsonfrom the diagnostics bundle. The trace will appear in the list on the right.
-
Click the trace to view its details. It is visualized as a collection of spans with timestamps. These may include operations executed by different nodes.
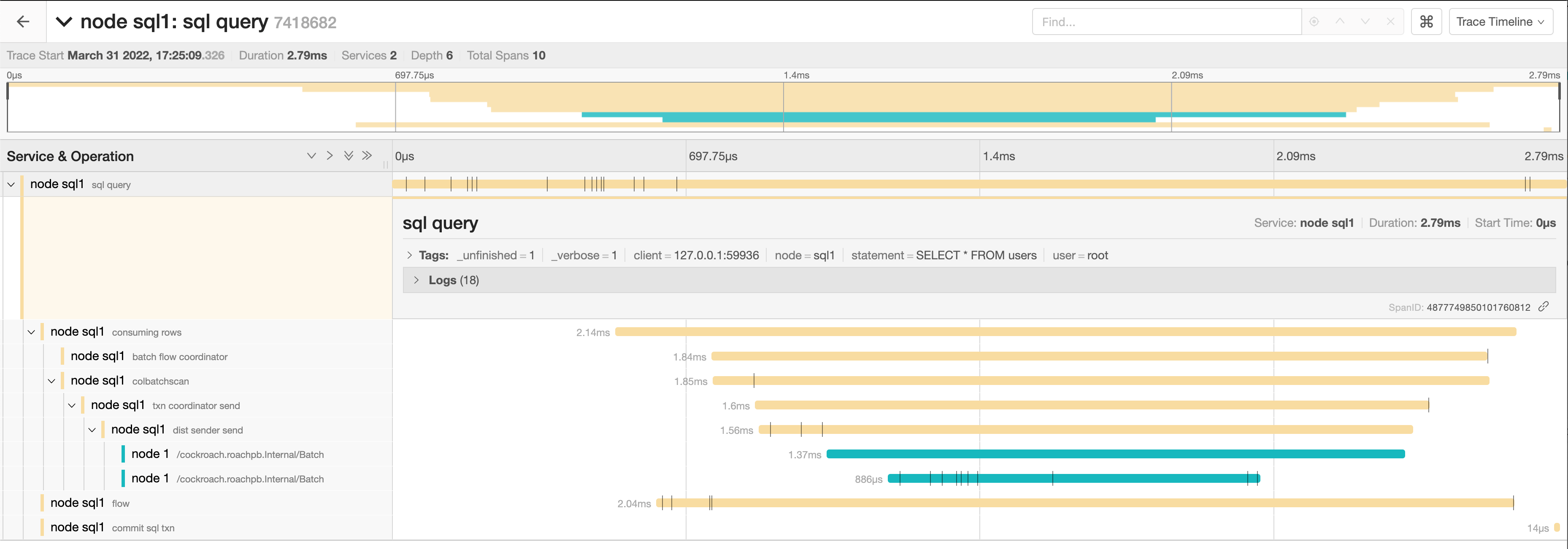
-
Click a span to view details for that span and log messages.
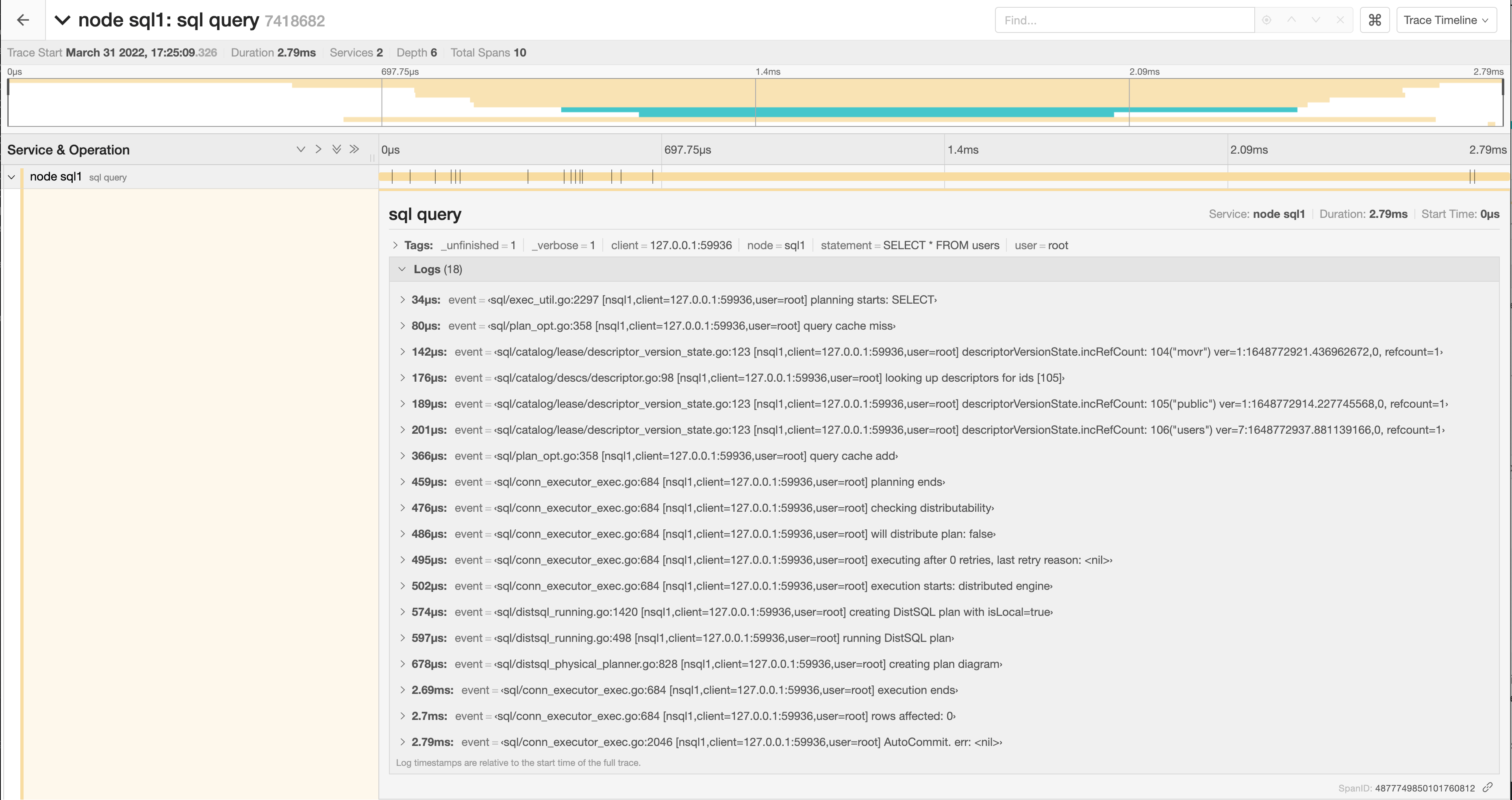
-
You can troubleshoot , for example, by gathering on statements with high latency and looking through the log messages in
trace-jaeger.jsonfor jumps in latency. In the following example, the trace shows that there is significant latency between a push attempt on a transaction that is holding a (56.85ms) and that transaction being committed (131.37ms).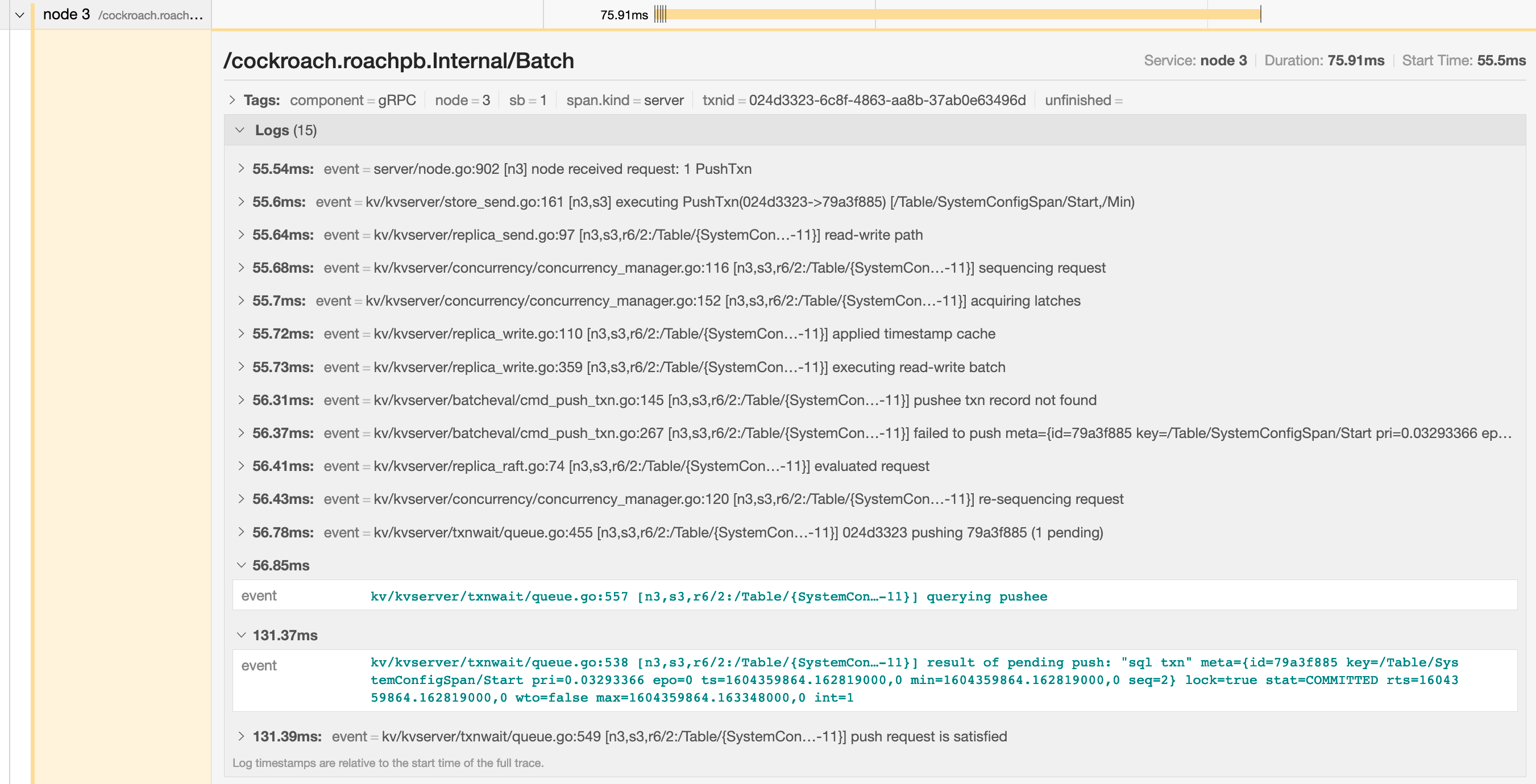
Visualize traces sent directly from CockroachDB
This example shows how to configure CockroachDB to route all traces to Jaeger. For details on sending traces from CockroachDB to Jaeger and other trace collectors, see Configure CockroachDB to send traces to a third-party trace collector.Enabling full tracing is expensive both in terms of CPU usage and memory footprint, and is not suitable for high throughput production environments.
-
Run CockroachDB and set the Jaeger agent configuration:
-
Go to
http://localhost:16686. -
In the Service field, select CockroachDB.
- Click Find Traces.
.log files to correlate events.
Jaeger’s memory storage works well for small use cases, but can result in out of memory errors when collecting many traces over a long period of time. Jaeger also supports disk-backed local storage using Badger. To use this, start Jaeger by running the following Docker command:
Log traces for transactions
CockroachDB allows you to trace to help troubleshoot performance issues. is controlled through the following cluster settings that govern when a transaction trace is captured and emitted.Trace sampling and emission
To enable tracing for a subset of transactions and emit relevant traces to the , configure the following cluster settings:- : Specifies the probability (between
0.0and1.0) that a given transaction will have tracing enabled. A value of0.01means that approximately 1% of transactions are traced. The default is1, which means 100% of transactions are sampled. - : Specifies a duration threshold. A trace is emitted only if a sampled transaction’s execution time exceeds this value. When set to
0(default), tracing is disabled regardless of whether the value ofsql.trace.txn.sample_rateis greater than0.
- The transaction is selected based on the sampling probability.
- Its execution duration exceeds the configured threshold.
sql.trace.txn.include_internal.enabled: Enables inclusion of internal transactions in probabilistic transaction tracing and latency-based logging. This setting is enabled by default. Set this tofalseto omit internal transactions and reduce noise when debugging user workloads.sql.trace.txn.jaeger_json_output.enabled: Enables output of transaction traces in Jaeger-compatible JSON format for easier ingestion by observability tools. This setting is disabled by default.
Trace configuration example
To configure the trace sampling probability and duration, set the following cluster settings:Queries are always slow
If you have consistently slow queries in your cluster, use the page to drill down to an individual statement and for the statement. A diagnostics bundle contains a record of transaction events across nodes for the SQL statement. You can also use an statement, which executes a SQL query and returns a physical query plan with execution statistics. You can use query plans to troubleshoot slow queries by indicating where time is being spent, how long a processor (i.e., a component that takes streams of input rows and processes them according to a specification) is not doing work, etc. Cockroach Labs recommends sending either the diagnostics bundle (preferred) or theEXPLAIN ANALYZE output to our for analysis.
Queries are sometimes slow
If the query performance is irregular:- Run for the query twice: once when the query is performing as expected and once when the query is slow.
-
to help analyze the outputs of the
SHOW TRACEcommand.
SELECT statements are slow
The common reasons for a sub-optimal SELECT performance are inefficient scans, full scans, and incorrect use of indexes. To improve the performance of SELECT statements, refer to the following documents:
SELECT statements with GROUP BY columns are slow
Suppose you have a that
- Has a
GROUP BYclause. - Uses an index that has a
STORINGclause. - Where some or all of the columns in the query’s
GROUP BYclause are part of the index’sSTORINGclause and are not index key columns.
GROUP BY clause are organization, os, and version.
The query plan shows that it is using index nodes_lastseen_organization_storing:
nodes_lastseen_organization_storing index has the GROUP BY column organization as an index key column. However, the STORING clause includes the GROUP BY columns os and version.
Solution
Create a new secondary index that has all of theGROUP BY columns as key columns in the index.
GROUP BY rather than a hash GROUP BY. After you make this change, you should notice an improvement in the latency of the example query.
INSERT and UPDATE statements are slow
Use the to identify the slow .
Refer to the following pages to improve INSERT and UPDATE performance:
Cancel running queries
See .Low throughput
Throughput is affected by the disk I/O, CPU usage, and network latency. Use the DB Console to check the following metrics:- Disk I/O:
- CPU usage:
- Network latency:
Query runs out of memory
If your query returns the error codeSQLSTATE: 53200 with the message ERROR: root: memory budget exceeded, follow the guidelines in .
Transaction retry errors
Messages with the error code40001 and the string restart transaction are known as . These indicate that a transaction failed due to with another concurrent or recent transaction attempting to write to the same data. The transaction needs to be retried by the client.
In most cases, the correct actions to take when encountering transaction retry errors are:
-
Under
SERIALIZABLEisolation, update your application to support when transaction retry errors are encountered. Follow the guidance for the . - Take steps to in the first place. This means reducing transaction contention overall, and increasing the likelihood that CockroachDB can a failed transaction.
Unsupported SQL features
CockroachDB has support for . Additionally, CockroachDB supports . This means that existing applications can often be migrated to CockroachDB without changing application code. However, you may encounter features of SQL or the PostgreSQL dialect that are not supported by CockroachDB. For example, the following PostgreSQL features are not supported:CREATE DOMAIN
CockroachDB does not support CREATE DOMAIN.
PostgreSQL range types
CockroachDB does not support PostgreSQL range types.Other unsupported features
- Events.
- Drop primary key.
Each table must have a primary key associated with it. You can .
- XML functions.
- Column-level privileges.
- XA syntax.
- Creating a database from a template.
- .
- Foreign data wrappers.
- Advisory Lock Functions (although some functions are defined with no-op implementations).
Node issues
Single hot node
A is one that has much higher resource usage than other nodes. To determine if you have a hot node in your cluster, and check the following:- Click Metrics and navigate to the following graphs. Hover over each graph to see the per-node values of the metrics. If one of the nodes has a higher value, you have a hot node in your cluster.
- > Average Queries per Store graph
- > Service Latency graph
- > CPU Percent graph
- > SQL Connections graph
- > Disk IOPS in Progress graph
- Open the and check for ranges with significantly higher QPS on any nodes.
Solution
- If you have a small table that fits into one range, then only one of the nodes will be used. This is expected behavior. However, you can to distribute the table across multiple nodes.
- If the SQL Connections graph shows that one node has a higher number of SQL connections and other nodes have zero connections, check if your app is set to talk to only one node.
- Check load balancer settings.
- Check for .
- If you have a monotonically increasing index column or primary Key, then your index or primary key should be redesigned. For more information, see .
- If a range has significantly higher QPS on a node, it may indicate a hotspot that needs to be addressed. For more information, refer to .
- If you have a monotonically increasing index column or primary key, then your index or primary key should be redesigned. See for more information.
Per-node queries per second (QPS) is high
If a cluster is not idle, it is useful to monitor the per-node queries per second. CockroachDB will automatically distribute load throughout the cluster. If one or more nodes is not performing any queries there is likely something to investigate. Seeexec_success and exec_errors which track operations at the KV layer and sql_{select,insert,update,delete}_count which track operations at the SQL layer.
Increasing number of nodes does not improve performance
Seebad connection and closed responses
A response of bad connection or closed normally indicates that the node to which you are connected has terminated. You can check this by connecting to another node in the cluster and running .
Once you find the node, you can check its (stored in cockroach-data/logs by ).
Because this kind of behavior is unexpected, you should .
Log queries executed by a specific node
If you are testing CockroachDB locally and want to log queries executed by a specific node, you can either pass a CLI flag at node startup or execute a SQL function on a running node. Using the CLI to start a new node, use the--vmodule flag with the command. For example, to start a single node locally and log all client-generated SQL queries it executes, run:
crdb_internal.set_vmodule() :
DEV , which outputs by to the primary cockroach log file in /cockroach-data/logs. Use the symlink cockroach.log to open the most recent log.
Configure CockroachDB to send traces to a third-party trace collector
You can configure CockroachDB to send traces to a third-party collector. CockroachDB supports Jaeger, Zipkin, and any trace collector that can ingest traces over the standard OTLP protocol. Enabling tracing also activates all the log messages, at all verbosity levels, as traces include the log messages printed in the respective trace context. Enabling full tracing is expensive both in terms of CPU usage and memory footprint, and is not suitable for high throughput production environments. You can configure the CockroachDB tracer to route to the OpenTelemetry tracer, with OpenTelemetry being supported by all observability tools. In particular, you can configure CockroachDB to output traces to:- A collector that uses the OpenTelemetry Protocol (OTLP).
- The OpenTelemetry (OTEL) collector, which can in turn route them to other tools. The OTEL collector is a canonical collector, using the OTLP protocol, that can buffer traces and perform some processing on them before exporting them to Jaeger, Zipkin, and other OTLP tools.
- Jaeger or Zipkin using their native protocols. This is implemented by using the Jaeger and Zipkin dedicated “exporters” from the OTEL SDK.
Troubleshoot SQL client application problems
High client CPU load, connection pool exhaustion, or increased connection latency when SCRAM Password-based Authentication is enabled
Overview
When (SCRAM Authentication) is enabled on a cluster, some additional CPU load is incurred on client applications, which are responsible for handling SCRAM hashing. It’s important to plan for this additional CPU load to avoid performance degradation, CPU starvation, and exhaustion on the client. For example, the following set of circumstances can exhaust the client application’s resources:- SCRAM Authentication is enabled on the cluster (the
server.user_login.password_encryptionis set toscram-sha-256). - The client driver’s has no defined maximum number of connections, or is configured to close idle connections eagerly.
- The client application issues concurrently.
Mitigation steps while keeping SCRAM enabled
To mitigate against this situation while keeping SCRAM authentication enabled, Cockroach Labs recommends that you:- Test and adjust your workloads in batches when migrating to SCRAM authentication.
- Start by enabling SCRAM authentication in a testing environment, and test the performance of your client application against the types of workloads you expect it to handle in production before rolling the changes out to production.
- Limit the maximum number of connections in the client driver’s connection pool.
- Limit the maximum number of concurrent transactions the client application can issue.
Lower default hashing cost and reapply the password
To decrease the CPU usage of SCRAM password hashing while keeping SCRAM enabled:-
Set the to
4096: -
Make sure the is set to
true(the default).
Downgrade from SCRAM authentication
As an alternative to the mitigation steps listed above, you can downgrade from SCRAM authentication to bcrypt as follows:-
Set the to
crdb-bcrypt: -
Ensure the is set to
true:
The can be left at its default value of
true.