


The thundering herd of the past was externally triggered. A service restores after downtime. A notification fires to a million users at once. A cache expires and everyone hits the database simultaneously. The fix is well-documented: exponential backoff with jitter, circuit breakers, staggered TTLs. These work when you can identify where the synchronized load originated.
Agentic AI creates a different version of this hazard: Here, the synchronization is internally generated. Fan-out is the feature and parallelization is the design. The load doesn’t arrive because something external triggered a crowd. It arrives because the architecture created one, on purpose, running at machine speed.
The standard playbook transfers in part, but it also breaks. The place it fails most completely is the place staging environments almost never expose: There is a non-linear saturation point, typically between 700 and 1,000 concurrent agents, after which performance behavior changes sharply. What a system does at 500 agents gives almost no signal about what it does at 5,000. Most teams hit this wall in production, not in load testing
What is the thundering herd problem? 
The thundering herd problem is not about high traffic. It’s about synchronized traffic.
If 10,000 users arrive at your system over an hour, that is a busy hour. If 10,000 users arrive in the same two seconds because a timer fired, a cache expired, or a service came back online, that is a thundering herd. The system can’t distinguish those two scenarios at the request level; it just sees 10,000 simultaneous attempts to access the same resource.
Things fail in sequence:
cache misses hit the database
the database saturates
retries compound the load
a brief spike becomes a sustained outage
The standard responses mentioned above work. However, there’s a prerequisite: that you can identify where the synchronization originated. In the classic thundering herd, you can.
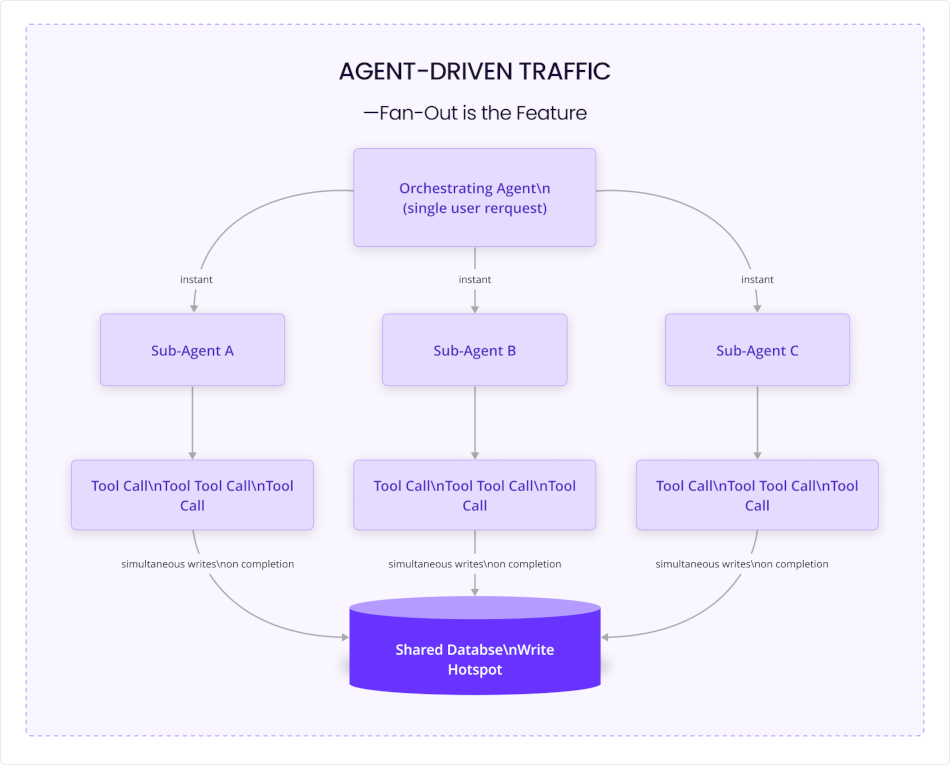
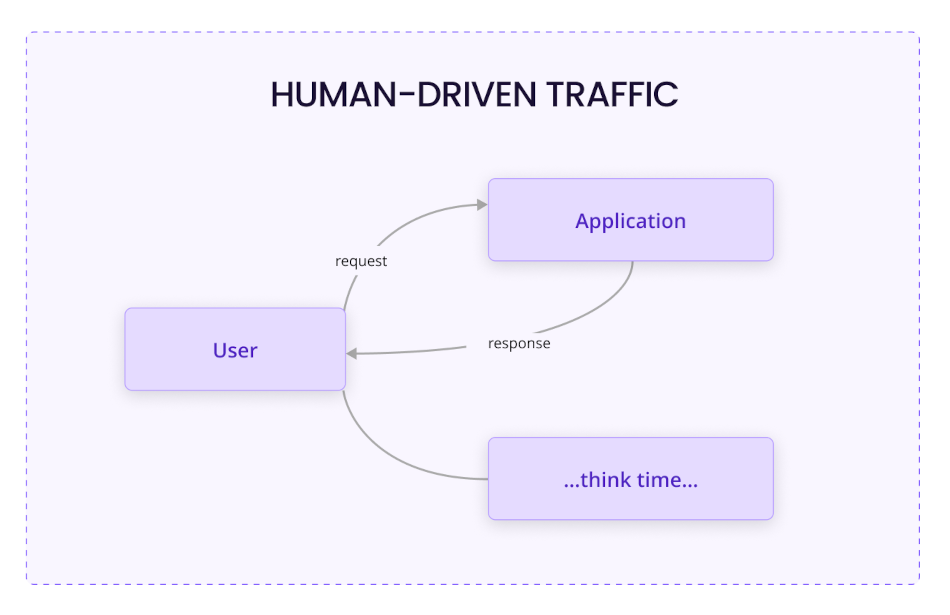
How is the thundering herd problem different in agentic AI?
In agentic AI architecture, orchestration is often designed to increase parallel work: One agent delegates tasks, sub-agents call tools, and results converge back into a shared workflow. That makes AI agent orchestration useful, but it also changes the shape of downstream infrastructure demand.
Bruce Schneier and Barath Raghavan's 2025 analysis of agentic AI security precisely frames what differentiates Agentic AI’s thundering herd. Agents execute the OODA loop: Observe, Orient, Decide, Act, repeat.
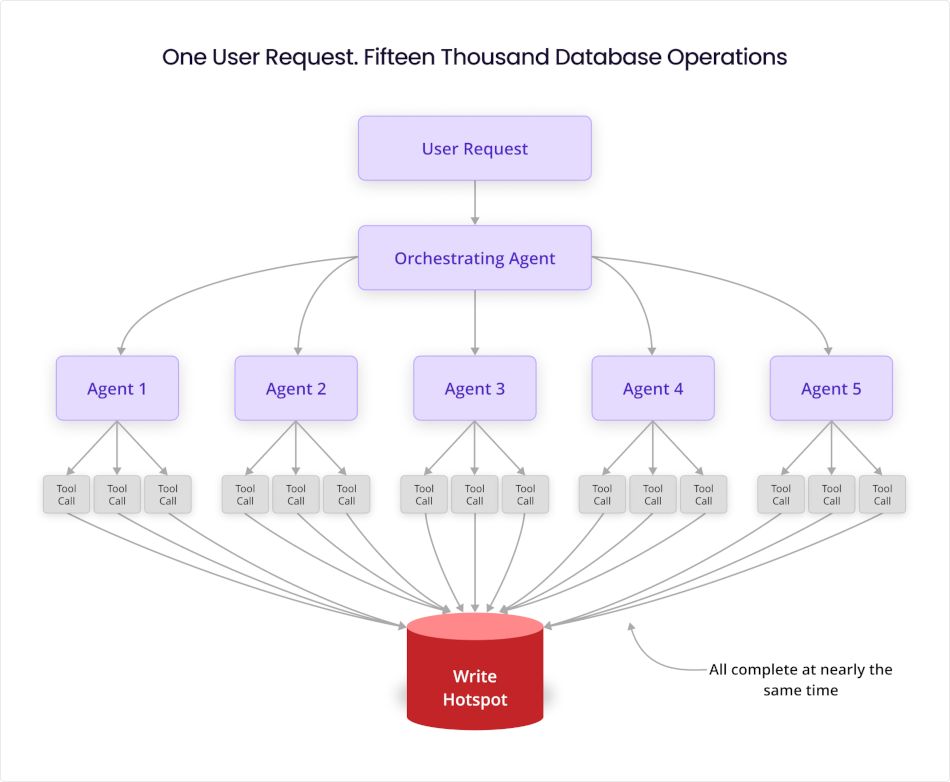
In a multi-agent system, each tool has its own OODA loop nesting inside the agent's loop, running in parallel with other tools. Here’s what that means structurally: When an orchestrator spawns five sub-agents, each running two or three tool calls in parallel, you have ten to fifteen simultaneous OODA cycles executing from a single user request. Scale that to 1,000 concurrent users and you have ten thousand to fifteen thousand simultaneous cycles. None of them waiting, while generating downstream operations at the system’s maximum rate.
A human using a web application has think-time between every interaction. They read a response, consider their next action, click. That cognitive pause is a natural throttle on downstream traffic.
Agent OODA loops have no equivalent pause. The loops nest and race simultaneously. When you have a thousand concurrent users, each triggering an orchestrator that spawns multiple sub-agents each running several tool calls, you have thousands upon thousands of simultaneous database operations initiated at nearly the same moment and converging on completion at nearly the same moment. The load profile looks like nothing a human-traffic model predicts.
Anthropic's framework for building effective agents describes parallelization as a core design pattern:
orchestrators spawn sub-agents to work simultaneously
sub-agents call multiple tools in parallel
results converge back to the orchestrator
In this framework, a single user request produces dozens of downstream operations within seconds. Their research showed that this reduced task completion time by as much as 90% for complex queries, which calls for a fundamentally different concurrency model than anything most infrastructure teams have planned for.
Scale that to thousands of concurrent users and the load profile becomes something with no precedent in traditional web engineering. Datadog's 2026 State of AI Engineering report found that 18% of agentic application requests made three or more service calls. In a web application, three service calls per user request is a complex interaction. In an agentic system, three is a simple workflow. The tail of multi-call requests is where the infrastructure load actually concentrates.
What happens when agent concurrency reaches database saturation?
Our benchmarking at Cockroach Labs quantified what this looks like against a real database under agent load. The test used a travel booking agent running a genuine transactional workflow: parse intent, query available flights, select a candidate, attempt a booking, commit or retry. This is not a synthetic benchmark. It’s a representative agentic workload scaled from a single agent to ten thousand concurrent ones.
Both PostgreSQL and CockroachDB tracked closely at low concurrency. The first inflection point appeared between 700 and 1,000 concurrent agents, where PostgreSQL began shedding throughput more aggressively. By 5,000 agents, PostgreSQL had dropped to roughly 57 ops/sec while CockroachDB held near 130, a 2.3x gap. By 10,000 agents, PostgreSQL was at approximately 42 ops/sec while CockroachDB remained near 129, approaching 3x. A note: this is a Cockroach Labs benchmark run by a Cockroach Labs team member. The methodology and code are published here. The specific numbers matter less than the shape of the curve. As always with vendor benchmarks, test your own workload.
Here’s the practical lesson: Database concurrency under agentic AI load can behave non-linearly. Teams should not assume that a system validated at hundreds of concurrent agents will behave predictably at thousands, especially when each agent can fan out into multiple tool calls, transactions, and retries.
The finding that matters most is not the throughput gap; it’s the shape of the saturation curve. Systems do not degrade gradually under agent load in a way that gives you time to react. They hold, then drop sharply past the inflection point. Nothing in staging at 500 agents predicts what happens at 5,000. This is the practical problem with the agentic thundering herd: It is invisible until it isn't.
Three ways the thundering herd problem appears in agentic AI systems
Agentic concurrency creates thundering herd conditions in three specific patterns. They share a name with the classic problem but have different causes and require different solutions. Understanding these patterns matters because each one can turn a successful AI workflow into an availability, latency, or cost problem once the system reaches production scale.
Write convergence during agent fan-in – An orchestrating agent dispatches work to ten specialist agents at the same moment. The specialists complete at nearly the same time, because they started at the same time and the task distribution was roughly even. All ten write their results back to a shared state simultaneously.
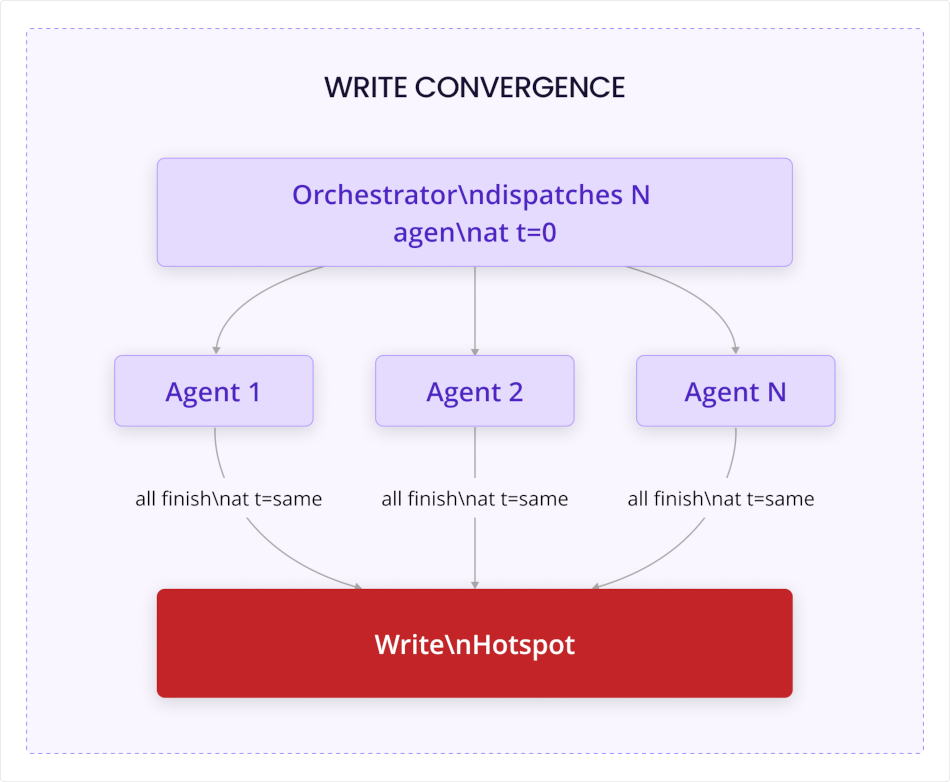
The result is a burst of synchronized writes to a shared data layer, not because of an external event, but because of the workflow’s internal architecture. This pattern is not triggered by an outage or a timer, butby completion. Every parallelized workflow creates it by design.
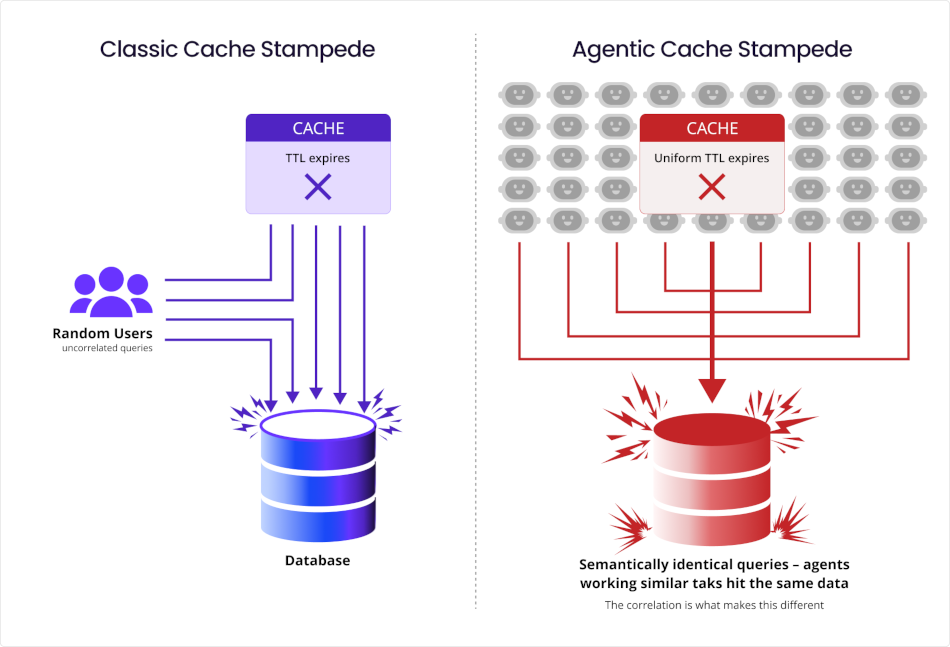
Correlated cache expiry and cache stampedes – Web application caching has the well-known cache stampede failure: A cached result expires and all clients who depended on it fall back to the underlying database simultaneously. The fix is staggered TTLs with jitter.

Agentic systems create a semantically correlated version of this problem: When thousands of agents share the same knowledge base or tool result cache with uniform TTLs, expiry is correlated. But the agents don't just hit the database at the same time; they hit the same specific queries, because they’re often working on semantically similar tasks like:
customer support agents handling similar ticket types
booking agents querying overlapping flight routes
research agents pulling the same regulatory documents
Each cache miss generates a semantically identical query. The correlation is what makes agentic AI’s thundering herd different from the time-honored version.
One customer support team encountered this when a nightly knowledge base refresh synchronized cache expiry across roughly 3,000 agents. They all hit the retrieval layer simultaneously with semantically identical queries, and the retrieval layer went down for 40 minutes.
The postmortem: database saturation. The connection to the cache refresh schedule was identified two weeks later, during an architecture review, not during the incident response itself.
Multi-step retry storms – The classic retry storm happens when a service fails and every client retries on the same schedule without jitter. Agentic frameworks make this worse in two ways.
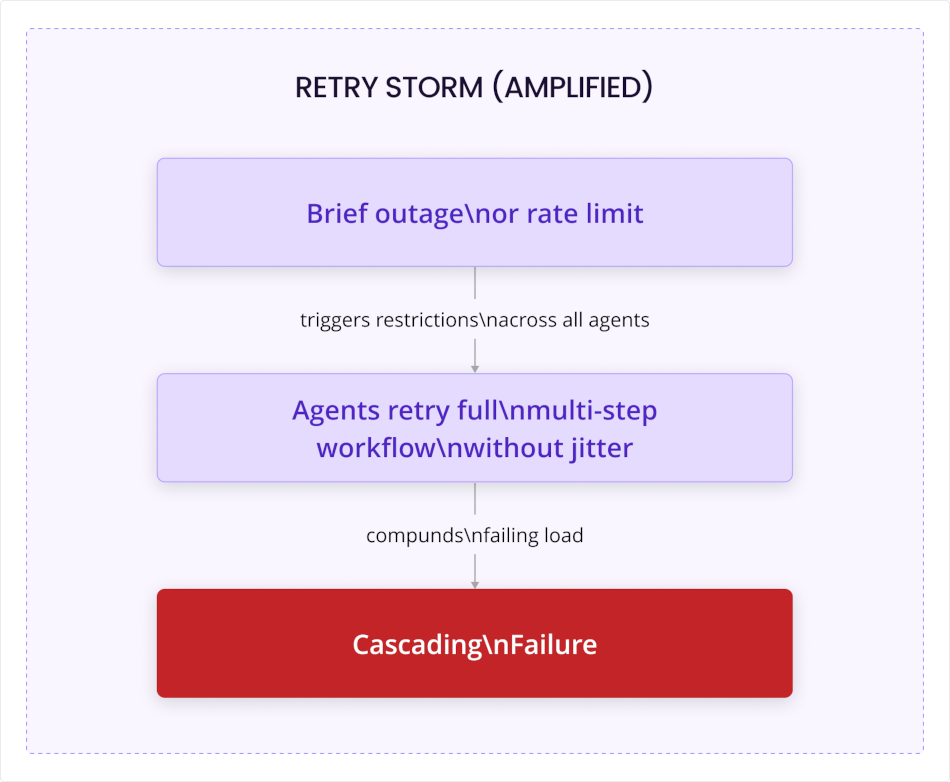
Agents retry aggressively and automatically, by framework design rather than explicit application code.
Agents don't just retry the failed call. They retry the entire multi-step workflow from the last durable checkpoint. If checkpoint granularity is low, a brief outage triggers a synchronized re-run of substantial compute across thousands of sessions simultaneously.
Datadog found that rate limit errors accounted for 60 percent of all LLM call span errors in February 2026, nearly 8.4 million errors in one month. That’s what happens when retry logic is not explicitly designed for machine-speed, multi-step workflows.
Note that these failures may not show up in postmortems as “agent-triggered” incidents. They’re more likely to be recorded as connection pool saturation, database latency, retrieval-layer failure, or elevated infrastructure cost. Without observability that connects agent behavior to downstream systems, the initiating pattern can stay hidden even after the outage is resolved. According to the AI Incidents Database, AI-related incidents rose 21 percent from 2024 to 2025. in monthly AI-related incidents reported by the media: incidents grew from approximately 50 in early 2020 to more than 200 by early 2024, reaching nearly 500 by January 2026.
Related
The State of AI Infrastructure 2026 – Based on new global research, this report reveals how close organizations are to hitting their infrastructure limits, and why AI scale is becoming a defining risk for reliability, performance, and cost in 2026. Get the report here.
Why traditional web engineering assumptions break down in agentic AI
The patterns that handle web application concurrency are insufficient for agentic workloads. Not because they’re wrong, but because the underlying assumptions don’t hold. A common fallback, scaling out when load increases, doesn't help against a thundering herd either. By the time new instances provision, the spike has passed. Or the new instances worsen it by issuing simultaneous cache misses on cold start.
How to reduce thundering herd risk in agentic AI systems
The agentic solutions are extensions of the classic ones. The difference is where they’re applied and how they’re tuned for machine-speed, fan-out workloads.
Jitter belongs in the agent framework, not just the infrastructure layer. Infrastructure-level backoff handles external retry storms. It doesn’t handle synchronized completion of parallel sub-agents. In practice, this means not dispatching all sub-agents simultaneously. A randomized stagger between task dispatches, and jittered TTL offsets assigned at cache population time, can spread the completion patterns enough to flatten write convergence spikes. This feels counterintuitive when you designed for parallelism. The database behavior under production load is the argument for doing it anyway.
Connection pooling must account for fan-out ratio, not user count. Web applications often assume user needs roughly one connection at a time. Agentic workflows can require multiple simultaneous connections per agent as sub-agents execute in parallel. For production AI systems, database connection pooling becomes part of workload control, not just an efficiency setting.
Circuit breakers should trigger on behavioral drift, not just error rates. Agentic systems can saturate a database before error metrics move significantly because write pressure builds gradually until it reaches a tipping point.. Signals such as tool calls per session, latency growth, and abnormal write volume often provide earlier warning than error rates alone.
Write patterns need hotspot avoidance baked in from the beginning. Sequential primary keys can create contention during agent fan-in events, while hash-distributed keys or append-only patterns help spread load. Because this is fundamentally a schema decision, it becomes much harder to correct after production scale is reached.
Six questions to ask before scaling agentic workloads
Rather than treating agentic AI as a larger version of a web application, teams should pressure-test their architecture against six questions:
What is the expected fan-out ratio per user request, and is your connection pool sized for that, not just for agent count?
Where are your shared caches populated, and are TTLs staggered with jitter or uniformly set at population time?
What retry behavior does each framework in your stack implement, and does it use exponential backoff with jitter or fixed-interval retries?
What triggers your circuit breakers, and do those signals include behavioral drift or only error rates?
What schema pattern governs writes from parallel sub-agents, and does it route writes away from sequential hotspots?
What is the granularity of your workflow checkpoints, and what is the blast radius if a brief outage triggers a full workflow retry across thousands of sessions simultaneously?
The Big Lesson: Agentic AI changes where synchronization comes from. Traditional thundering herd events are typically triggered by external events. Agentic systems can generate the same conditions internally through fan-out, parallel tool execution, retries, and shared state.
The six questions above won't eliminate every scaling challenge, but they will surface many of the architectural assumptions that fail first under production-scale agent workloads. The teams that answer them early can avoid the availability, performance, and cost surprises that often emerge as agentic systems move from pilot projects to production environments.
Related
The Architect's Playbook for Building AI-Ready Systems – Practical architectures and design patterns for building AI-ready systems on distributed SQL. This useful guide covers vector workloads, real-time data consistency, and global scalability. Get it here.
Built for AI-driven scale
Unify operational data, vector search, and durable agent state in one resilient, distributed SQL database. Start with $400 in free credits. Trusted by Fortune 50 financial institutions and teams in 40+ countries.
Quentin Packard is VP of Americas Sales at Cockroach Labs, where he works with engineering and infrastructure leaders building production-grade agentic AI systems. He previously helped build Splunk’s observability business and has worked across infrastructure automation, secrets management, and real-time data governance at HashiCorp and early stage startups. His writing draws on direct conversations with enterprise teams navigating AI and data architecture in production.


