


What happens when you connect a fleet of autonomous AI agents to your enterprise data stack? You quickly discover that agentic workloads do not behave like human-driven applications: Autonomous agents do not pause between clicks. They issue frequent tool calls, run tasks in parallel, retry aggressively, and expect low-latency access to current data.
Autonomous agents, as detailed in our previous post Scaling AI Agents: PostgreSQL vs CockroachDB Under High-Concurrency Workloads, create unique database pressure. Thousands of concurrent agents generate transactional load that can overwhelm traditional single-node databases, prompting the question of whether the database can scale under this "agentic pressure."
The recent Cockroach Labs blog post 8 AI Use Cases That Depend on Database Resilience, establishes that resilient infrastructure is now essential for AI workloads that write to systems of record. Correctness, availability, and durability matter even more when model outputs can trigger durable business actions.
This article builds on that foundation but takes a different angle: rather than focusing on resilience as an infrastructure requirement, we’ll examine how CockroachDB can sit on the critical path for durable agent state, retrieval metadata, and governed database access. That includes user-scoped permissions, execution metadata, cost tracking, latency telemetry, and SQL audit trails.
In other words, CockroachDB is not just where agents store data. It is where builders can store the metadata that application teams use to observe, govern, and improve agent behavior. That matters because production agentic AI architecture is not only about getting agents to complete tasks; it’s about making their decisions repeatable, auditable, cost-aware, and safe enough to operate against enterprise systems of record.
In agentic systems, the database moves into the reasoning loop. It stores the durable state agents retrieve, the schema context they use to generate actions, and the operational metadata teams need to evaluate what happened after the fact.
That is where CockroachDB becomes more than a transactional backend. In an enterprise agent architecture, CockroachDB can serve as the operational layer for:
the system of record
the Long-Term-Memory (LTM) store (Note – In this article we touch on two agent memory layers: short-term – e.g, RAM for active conversations – and long-term – persistence for cross-session history and preferences)
the source of schema and cluster context
the place where agent activity can be governed, observed, and audited.
Two capabilities are central to that pattern. First, CockroachDB’s MCP Server gives agents a structured interface for using the Model Context Protocol to inspect schema, check cluster health, and execute database operations with the right context. Second, native vector search allows agents to persist prior analyses as embeddings and retrieve semantically similar work later. Together, these capabilities support a practical form of AI agent memory: Agents can ground new work in current database context while reusing relevant prior analysis instead of starting from scratch, reducing repeated computation and lowering latency.
As Sr. Staff Sales Engineer at Cockroach Labs, I turned customer feedback into a prototype to show how we solve their Agentic AI requirements. To make this concrete, I built the Autonomous Revenue Swarm: a reference multi-agent system that combines LangChain, LangGraph, CockroachDB, MCP, and vector search. The swarm acts like a digital analyst. It can:
diagnose database state
generate SQL
cross-reference internal revenue data with external market signals
audit its own output before producing an executive report.
The goal is not simply to show that agents can answer business questions. It is to show the operational pattern behind production-ready agentic systems: memory, context, governance, and scale. CockroachDB anchors the durable, transactional parts of the architecture in the database.
An agentic AI architecture for memory, context, and control 
Building production-ready AI isn't just about chaining prompts. It requires a structured "Command and Control" system. The Autonomous Revenue Swarm system isolates concerns into three operational tiers (see Figure 1):
AI agent memory: How the long-term memory gateway works
This is the entry and exit point of the system. It manages user I/O and interfaces with CockroachDB for LTM persistence,checks previous results, and avoids redundant computation.
How does the planner route agent tasks?
LangGraph is a powerful tool for orchestration, where a Planner evaluates the user request and a Router dynamically dispatches tasks to specific specialist nodes.
How do specialist agents execute and audit work?
This tier coordinates a set of specialized agents for DB Diagnostics, SQL Generation, and Web Research that stream their findings to an Analyst agent, which then compiles the information into a report. The entire process is coordinated via the LangGraph Shared State Whiteboard, which facilitates all communication. Finally, a Critic agent reviews and audits the Analyst's output before the final report is produced.
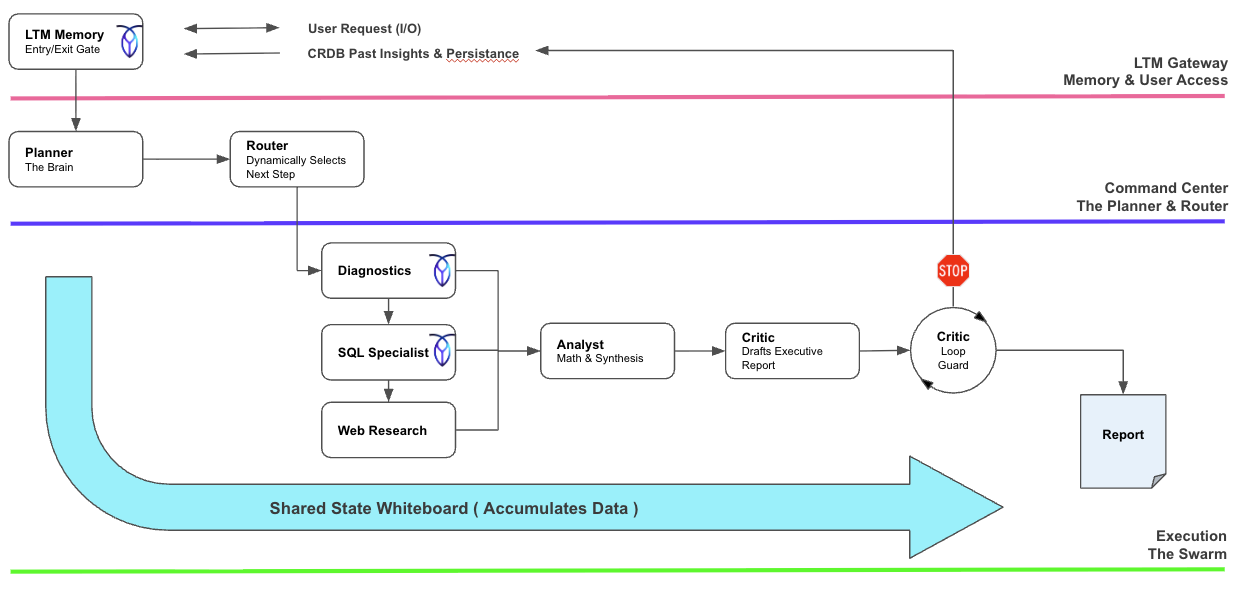
Figure 1: The three layers foundation diagram
How does the agentic application work?
Operating the Autonomous Revenue Swarm application feels like a standard chat interface, but behind the scenes it behaves more like an enterprise analytics workflow. A user enters a natural-language business prompt in the dashboard, such as:
“Identify our top three growth regions in the last six months. Cross-reference this with 2026 emerging SaaS market trends to determine whether our success is internal or market-driven.”
Once submitted, the Command Center activates the specialized agents in real time. The system moves through its reasoning tiers:
checking cluster health
generating and executing SQL
performing external market research
synthesizing the findings into an executive-ready report
The final analysis appears in the main viewing area, where the user can export it to PDF or clear the state to begin a new investigation (Figure 2).
The key capability under the hood is persistent agent memory. When the swarm completes a complex task, it saves the experience as vector embeddings in CockroachDB. This allows the system to recognize when a future question is semantically similar to work it has already completed.
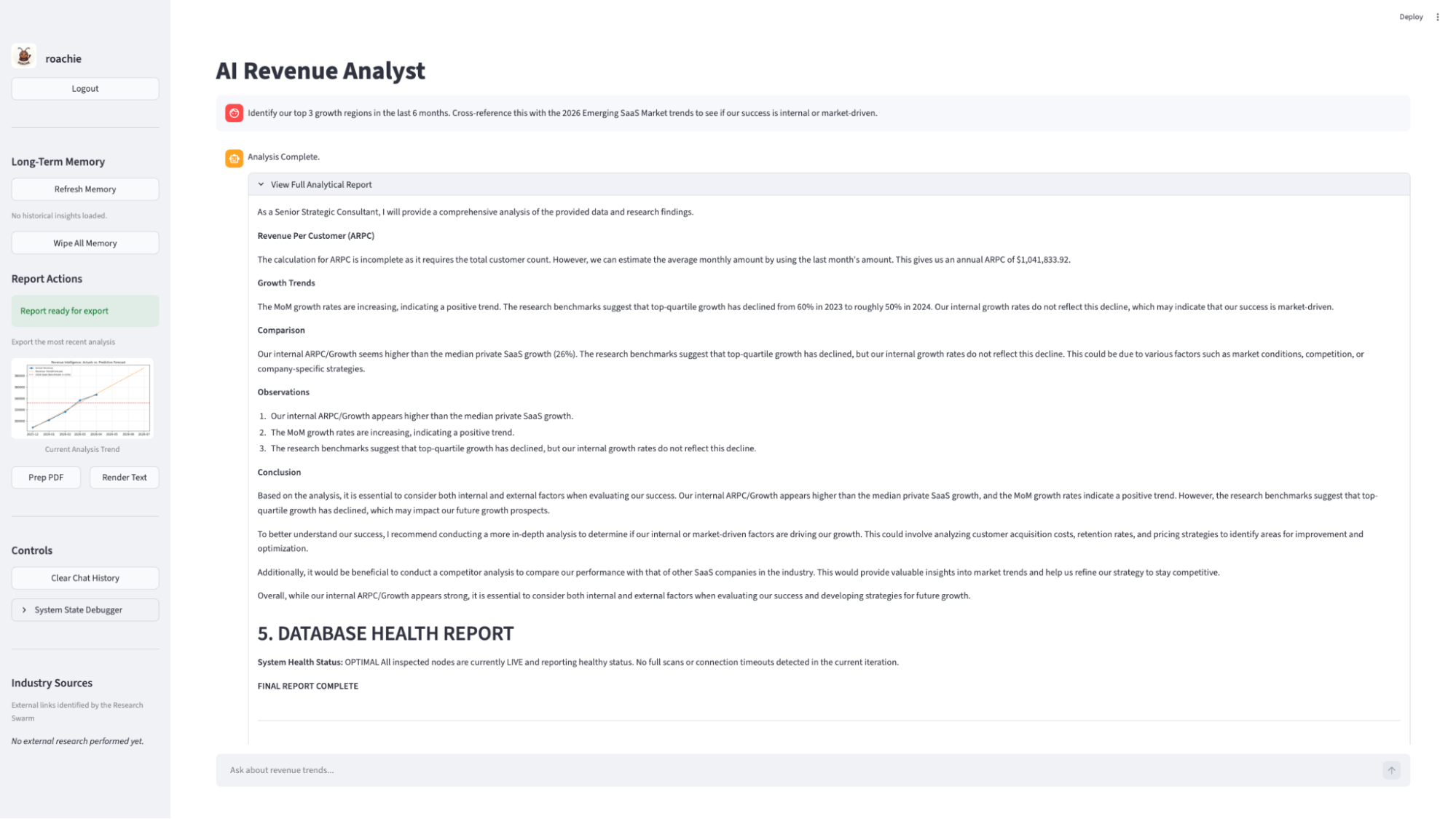
Figure 2. Main dashboard screen.
For example, another user might later ask a slightly reworded version of the same business question:
“Identify the top 3 regions with the most growth in the last 6 months. Cross-reference this with 2026 SaaS market trends to determine whether our success is internal or market-driven.”
Instead of rerunning the full workflow from scratch, the LTM Gateway performs a similarity search against prior completed analyses. In this case, the system identifies an 80.82% match and offers the user a choice: reuse the existing research or refresh the analysis with a new run (Figure 3).
This reuse-first retrieval path reduces repeated computation, lowers latency, and helps control LLM inference and token costs. At the same time, the agents remain operationally aware. Through the MCP server, they can check database health and inspect table schemas before generating SQL, reducing the risk of brittle queries, schema mismatches, or unnecessary load on the database. For application teams, that changes the economics of agentic workloads: Prior work becomes a reusable operational asset, rather than a one-time model output that must be regenerated every time a similar question appears.
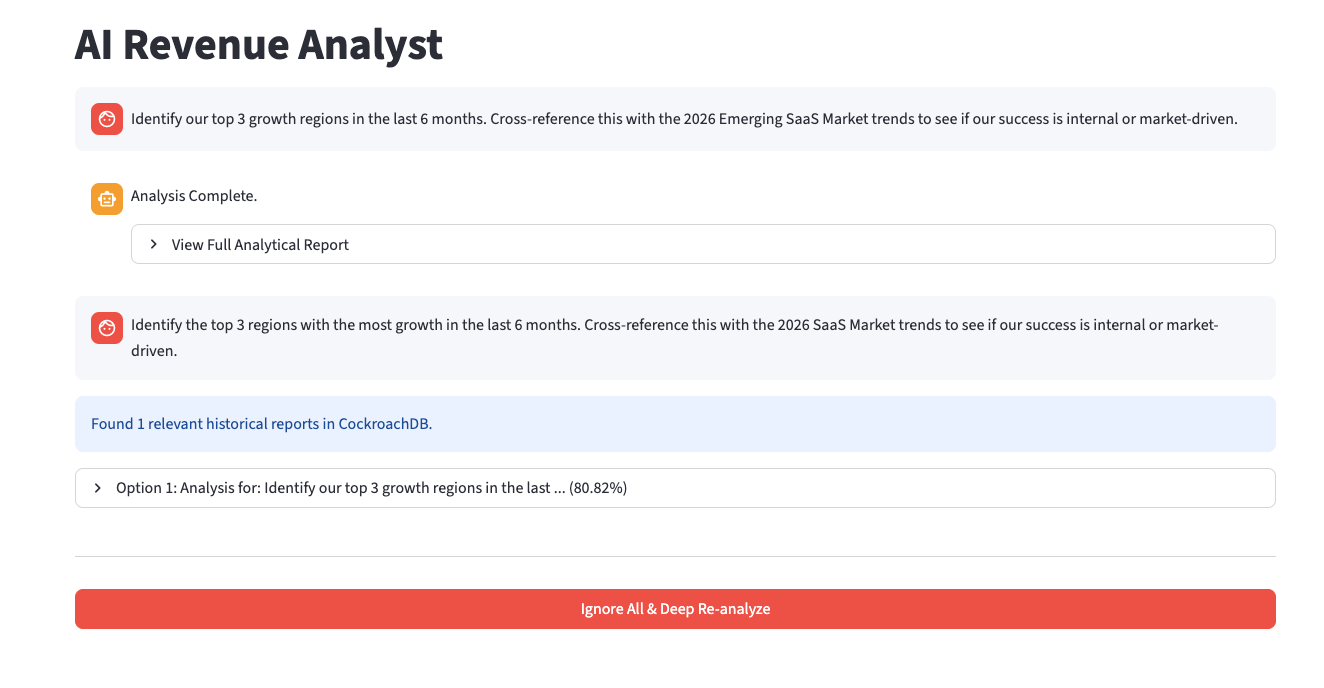
Figure 3. When presented with a similar query, the system offers the option to use the existing research or update it, noting an 80.82% match.
Production readiness also requires visibility. The Autonomous Revenue Swarm Performance Dashboard gives operators a real-time view into how the agentic system behaves across cost, latency, and context usage. In the example below (See Figure 4), the swarm has run 132 tasks with an average latency of 0.29 minutes, a total cost of $1.4972, and an average context saturation of 21.9% (Note – Context saturation degrades performance when an agent's working memory is overwhelmed by excessive or noisy data).
The latency distribution context refers to the total pool of information the model can "see" and consider at any given moment. It breaks performance down by agent, showing that the memory agent returns almost instantly while the critic, analyst, SQL specialist, and planner agents consume more measurable execution time.
The token usage chart compares each agent’s consumption against the hard context ceiling, confirming that the swarm is operating well below its limit.
The cost chart attributes cumulative spend by agent, with the critic agent representing the largest share of cost, followed by the analyst and SQL specialist.
For the business perspective, this visibility turns AI from an unpredictable black box into a measurable operating system. Teams can see which agents are creating value, which ones are driving cost, and where optimization work should be prioritized. If latency spikes, context saturation increases, or a specific agent starts consuming a disproportionate share of budget, engineering and operations teams can detect the issue early and tune the workflow before it affects users or margins. This creates a practical governance layer for agentic AI: every task has a measurable cost, every agent has a performance profile, and every reasoning workflow can be evaluated against service-level, budget, and compliance expectations.
In production, that means agentic AI can be managed with the same discipline as any other mission-critical enterprise workload. All the agent state, LTMLT, telemetry, audit metadata, and business data is stored in CockroachDB.
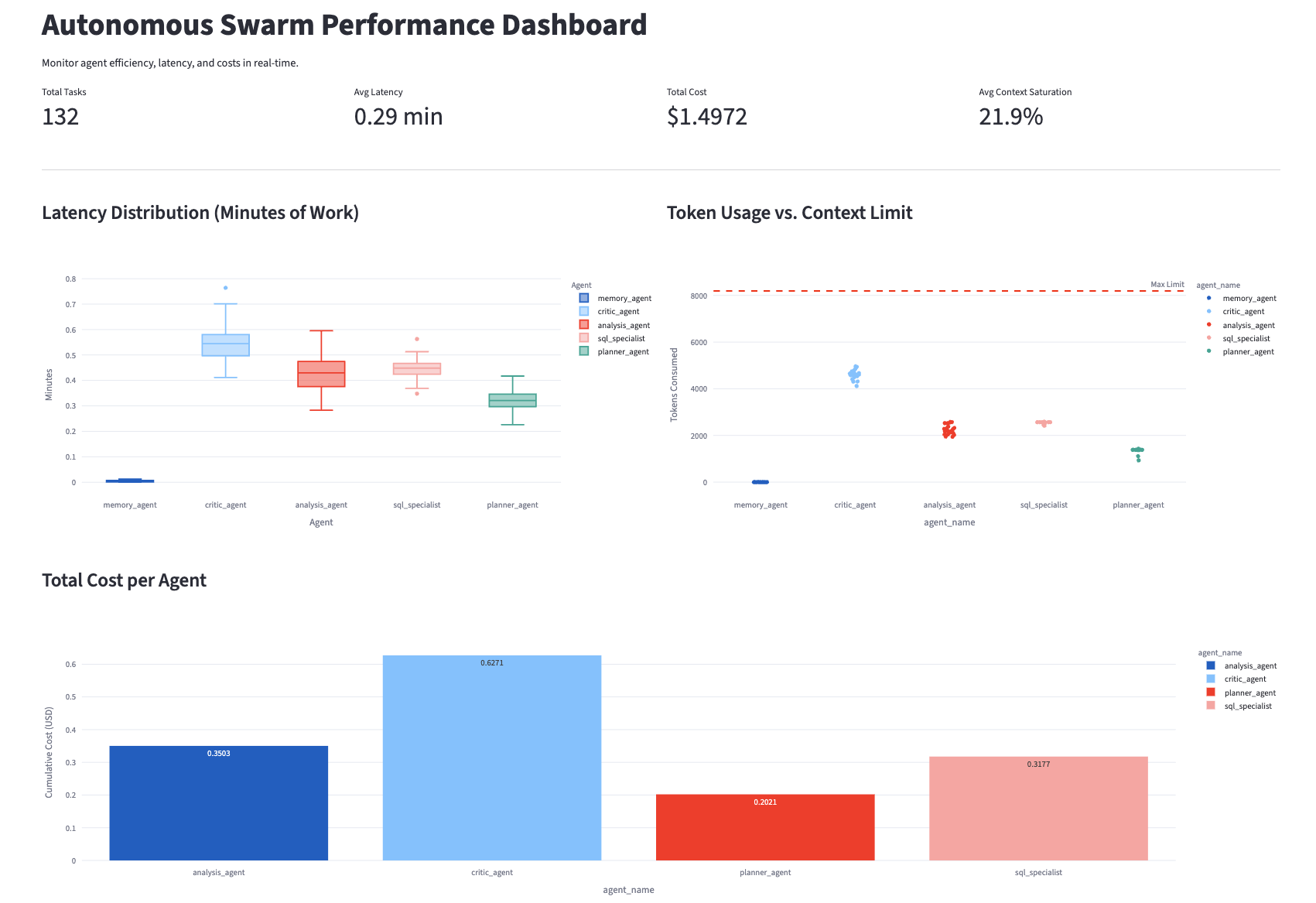
Figure 4. Autonomous Revenue Swarm Performance Dashboard showing latency, token usage, context saturation, and cumulative cost by agent.
The takeaway is straightforward: When memory, context, governance, and scale live close to the data, agentic systems become faster, less expensive to run, and easier to trust. This pattern can reduce repeated work and improve observability when reuse, permissions, and freshness are handled explicitly.
How does an MCP server help AI agents act on database context?
Working with tools in LLMs introduces real failure modes because they can generate incorrect or fabricated outputs, pick the wrong tool, and be slow. For instance, an agent creates a SQL query from a basic description and runs it, hoping for the best. If the database schema is different or the system is busy, the whole thing just breaks.
In the Autonomous Revenue Swarm, we reduced schema-related guesswork by adding a CockroachDB MCP server.

When the Diagnostic Agent is turned on, it doesn't just run queries. It queries the MCP server to assess current cluster health rather than relying on assumptions baked into the prompt.
status = await mcp_client.call_tool("get_cluster_status")
slow_queries = await mcp_client.call_tool("get_slow_queries")
Once the cluster’s health is verified, the SQL Specialist agent takes the reins. This transition isn’t about self-healing; it’s about establishing a strict, preventive guardrail before a single line of code is executed.
To pull this off reliably, you need to minimize LLM hallucinations as much as possible. Start by leveraging the describe_table MCP tool to dynamically fetch the current table schema at SQL query execution time.
schema_raw = await call_cockroach_mcp("describe_table", {"table_name": "revenue"})Combine this with a hard rule: Set your LLM temperature to zero. This significantly reduces output variance, though schema grounding via the system prompt is the primary guardrail.
llm = ChatOllama(model="llama3", temperature=0)However, deterministic temperature settings and fresh schema data are only half the battle; the true linchpin of this engineering pattern is that a carefully constrained system prompt can reduce invalid SQL patterns, but it should not be treated as a safety boundary. The system prompt acts as the ultimate deterministic framework, dictating precise architectural rules, syntax constraints, and explicit query patterns that the agent must follow. In practice, you inject the live schema directly into this prompt using a placeholder like {schema_safe} to guarantee the agent is never writing queries blindly.
Here is an example of how you can structure this system prompt to enforce absolute compliance and CockroachDB compatibility:
system_prompt = f"""You are a precise CockroachDB SQL Expert.
CRITICAL RULES:
...
SCHEMA:
{schema_safe}
"""
By grounding the LLM with this immutable system prompt and injecting the runtime truth via {schema_safe}, you effectively transition the agent from an unpredictable text-generator into a deterministic compiler for CockroachDB. This guardrailing ensures that complex syntax – such as window functions or window-based ratio calculations highlighted in the rules – is generated without manual developer oversight. With the schema locked down and the behavior strictly bound, the SQL Specialist is now fully equipped to safely execute precision queries against your live database infrastructure.
How does vector search support persistent AI agent memory?
AI agent memory is the durable context an agent can retrieve across sessions, tasks, or users. In this architecture, CockroachDB stores prior analyses as embeddings so agents can use vector search to find semantically similar work – before deciding whether to rerun a full workflow.
Agents generate traffic loops. If an agent has to run a complex, multi-step analytical workflow every single time a user asks a similar question, it wastes compute, drives up LLM token costs, and increases latency.
You can solve this by turning CockroachDB into a store of long-lived, user-scoped prior analyses and their embeddings. Every finalized report generated by our Analysis and Critic agents is vectorized using the all-MiniLM-L6-v2 model and saved into our swarm_memory table.
When a new user prompt comes in, the swarm performs a Vector Similarity Search using CockroachDB's native vector distance operator (<=>). In this pattern, the system compares the new prompt embedding against stored report embeddings, ranks prior analyses by similarity, and uses a configured threshold to decide whether an existing result is relevant enough to reuse or offer as a candidate:
SELECT
memory_value,
full_report_text,
1 - (embedding <=> $1::vector) AS similarity
FROM public.swarm_memory
WHERE username = $2::text
ORDER BY similarity DESC
LIMIT 10;
What is the impact of similarity search on cost and latency?
During a live demo of the application, we tested this exact paradigm:
Run 1: We asked the swarm to identify regional revenue growth trends and cross-reference them with 2026 emerging market data. There were no matches with a confidence level greater than 0.80

The swarm spun up the full execution path:
Diagnostics → SQL Specialist → Web Research → Analyst → Critic
It took approximately 45 seconds to complete.
Run 2: We submitted a semantically similar question.

In this example the system returned an 85.78% similarity match.
Because the math was calculated natively inside CockroachDB, the LTM Gateway recognized that it had a result that was similar enough to offer as a reuse candidate. It bypassed the planner, bypassed the SQL execution, bypassed the web search, and returned the cached insight instantly.
We reduced LLM inference costs significantly for this query, bypassing the model pipeline completely. This pattern turns prior reports into retrievable artifacts that can reduce repeated LLM calls.
Related
Vector Search Meets Distributed SQL: A New Blueprint for AI-Ready Data – This Intellyx analyst report explores why AI workloads are breaking conventional data architectures, and how native vector indexing in distributed SQL unlocks a unified, scalable foundation for agentic apps.
AI observability for cost, latency, and context usage
AI observability is the ability to measure how an AI system behaves in production, including cost, latency, token usage, context saturation, failures, and output quality signals. For agentic systems, observability also needs to show:
which agent performed which action
how long it took
what it consumed
whether the workflow stayed within operational guardrails
To capture the granular metadata shown in our performance dashboard, we implemented a non-invasive telemetry system using Python decorators. This approach allows us to wrap any agentic function – whether it’s a SQL query or a web search – and automatically log its performance metrics directly to CockroachDB without cluttering the core business logic.
Here is a look at the simplified implementation:
How does agent telemetry work?
The @track_swarm_telemetry decorator acts as a "silent observer" around our agents. When a specialist like the SQL_Specialist starts its work, the decorator triggers a high-precision timer. Because it uses the functools.wraps pattern, it maintains access to the agent's Shared State, allowing it to extract crucial metadata like token usage or context saturation in real-time.
The true power of this pattern lies in the final block. Regardless of whether the agent succeeds or hits a "hallucination loop," the decorator ensures the outcome and timing are recorded in our agent_metadata table. This is how we identify the outliers mentioned earlier: It provides the "operational visibility" required to prove the swarm is operating within the expected enterprise guardrails.
By logging these data points directly to our agent_metadata table, we can analyze the workload across three key vectors. The telemetry reveals:
Latency Optimization: Early executions revealed that the Critic Agent would occasionally spiral into an 11-minute hallucination loop. By using metadata to flag these outliers, we implemented "Termination Guards" and "Instruction Stripping." This successfully flattened the Critic's average latency down to a highly consistent 40 seconds in measured runs.
Token Margin & Context Headroom: A red line at 8,192 tokens marks the hard context limit. Telemetry confirms our agents operate well below this ceiling, averaging just 21.8% context saturation. This low saturation rate means the swarm has substantial headroom, allowing us to execute more real-time database retrieval before encountering context overflow or memory truncation.
Economic Viability: The economics are straightforward. We executed over 132 tasks for a total cumulative cost of $1.49. While our heavy-duty reasoning tasks consume standard token rates, our Memory Agent generates no LLM inference cost: The similarity calculation runs natively inside CockroachDB at a fraction of what an equivalent model call would cost. By leaning on the native vector store inside CockroachDB rather than paying an external LLM for long-term data lookup, our working memory remains functionally free to query.
How do IAM and metadata create trust in agentic AI?
When you build for real organizations, security is not an afterthought. Autonomous agents cannot operate with superuser privileges.
Our architecture binds every agent execution thread to CockroachDB's Identity and Access Management (IAM). The SQL Specialist generates queries that are executed within the tight security context of that specific user's session.
Furthermore, because every intermediate thought, token count, and latency metric is logged back into our agent_metadata telemetry table, the entire reasoning process is fully auditable. If the Critic Agent rejects a report because it suspects a calculation error, the exact transaction sequence, prompt context, and raw SQL data used by the Analyst are preserved for review. For regulated or high-stakes environments, this turns agent execution from an opaque model interaction into an auditable workflow that can be investigated, tuned, and governed like other enterprise software systems.
Related
Built for AI: Scaling IAM, Metadata Management, and Vector Search on One Database – Explore how AI innovators are simplifying complex infrastructure challenges – including IAM, metadata management, and vector search – with case studies from Ory/OpenAI and CoreWeave.
Why does agentic AI architecture matter more than features?
The architecture question for agentic systems is not which database supports vector search – most modern databases do. Instead, it is which database was designed to remain correct, available, and consistent when:
the load is continuous
the concurrency is in the thousands
and a mid-execution failure cannot be allowed to cascade through an active reasoning chain
When a database goes down mid-reasoning, partial state is already written, the next retrieval step returns stale or absent data, and the failure propagates – not through one query, but through every agent sharing that memory context. In systems designed for human-timed workloads, that is an edge case. In a production multi-agent swarm, it is an architectural constraint that determines whether the system can be trusted.
CockroachDB's distributed-by-design architecture – no write master, no single point of failure, online schema changes, automatic query rerouting undesr node failure – was not retrofitted for AI. It was built for exactly this class of problem.
Data architecture is AI architecture
This example didn't just validate CockroachDB under an agentic flow: It reframed the question enterprises should be asking.
Most teams treat the database as the last layer of the stack: a place to persist what the AI decides. That's the wrong mental model. In an agentic system, the database is inside the reasoning loop. Is where the agent grounds itself, resolves ambiguity, retrieves context, and reconciles competing signals in real time. What lives in the database, how fast it can be read, how safely it can be written under concurrency, and how intelligently it can be queried directly shapes what data the agent can retrieve, verify, and safely act on.
Data architecture is AI architecture. They are not adjacent decisions, they are one and the same.
CockroachDB's MCP Server, native vector math, multi-region consistency, and fine-grained IAM weren't bolt-on features for this workload – they were the conditions that made the workload possible. Remove any one of them and you don't get a slower system; you get a different system, with different limits on what the agent can reason about and act on.
If you are designing an agentic system today, the database belongs in the design conversation from day one: not as infrastructure, but as cognitive foundation. When teams make that shift early, they can build agentic systems that are easier to scale, less expensive to operate, and safer to connect to business-critical workflows. The result is not just better AI performance, but a clearer path from prototype to production.
Ready to build on the right foundation? Talk to the Cockroach Labs team about architecting CockroachDB for your agentic workloads. Get in touch, and we'll show you what's possible when your data layer supports high-concurrency, stateful agent workloads with transactional consistency and operational visibility.
Try CockroachDB Today
Spin up your first CockroachDB Cloud cluster in minutes. Start with $400 in free credits. Or get a free 30-day trial of CockroachDB Enterprise on self-hosted environments.
Alex Infanzon holds an M.S. in New Generation Computing from The University of Exeter. He has over 35 years of professional experience in consulting, pre-sales, and management roles at companies including SAS, MariaDB, Sun Microsystems, Dun and Bradstreet, Aerospike, and Tiger Graph. He has worked with Fortune 500 companies in various industries, with deep experience in architecting and implementing Business Intelligence, Analytics, Data Management, High-Performance Computing, and AI solutions.


