


When your AI agent makes a bad decision in production, what do you blame? The problem isn't the model. It's what the model doesn't know.
Most teams go straight to the model: Wrong temperature setting, not enough examples in the prompt, the model isn't smart enough yet. That answer feels intuitive because the model is the most visible thing in the stack.
Over the last several months at Cockroach Labs, I’ve spent a lot of time talking with engineering leaders across enterprises, and the pattern I keep seeing tells a different story. A year ago, everyone was asking whether agents could actually deliver real value. Now the question has shifted to something harder: Why do agents that pass every staging benchmark keep making decisions nobody can explain or defend in production?
The honest answer, more often than not, isn't the model. It's context.
In production, agentic AI architecture is less about connecting a model to tools and more about giving agents reliable access to the context, memory, permissions, and observability data they need to act safely. Without that foundation, even a strong model can make decisions based on stale data, incomplete system state, or architectural assumptions that do not hold up in production.
I sat across from a VP Engineering last quarter who had just shut down a deployment his team spent eight months building. The model performed well in testing. In production, the agents were making confident, coherent-sounding decisions based on data that was three days old, accessing tables they had no business seeing, and repeating expensive analytical workflows they had already completed with no memory that any of it happened before.
Nobody had thought hard enough about the context layer.
That's not a prompt engineering problem, it's a data infrastructure problem. And most organizations building on agents right now don't know they have it yet.
Why isn’t AI agent context the same as retrieval?
The first-generation agent architectures I see treat the database as a passive storage layer. Vector search retrieves something semantically relevant, the model gets a chunk of text, done. It works fine in demos, but it breaks in production.
AI agent context management is the discipline of giving agents the right operational context at the right time: what data exists, what data is current, what the agent is allowed to access, and what system constraints apply before it acts. That distinction matters because production failures rarely come from missing text alone; they come from agents reasoning over an incomplete or outdated view of the system.
Enterprise agent systems need something harder from the data layer. They need:
to know what the agent is allowed to see, not just what's relevant to retrieve
to know whether the data they're reasoning over is current or three days stale
genuine awareness of the system they're operating in before they generate a single query
Our engineering team has been working through this with the CockroachDB MCP server, giving agents structured real-time access to schema state, cluster health, and security permissions before any query gets written. The difference in output quality when an agent actually knows the system it's working with versus guessing at it is not subtle. A confident agent working from a wrong schema assumption does not fail gracefully. It generates plausible-looking garbage that can make it all the way to a business decision before anyone catches it.
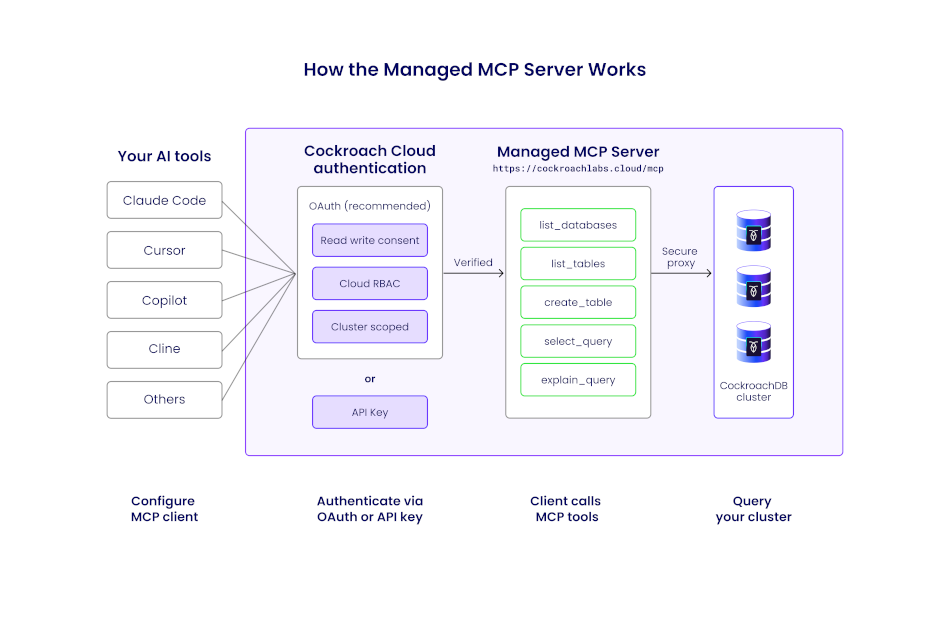
This managed MCP request flow illustrates how an AI agent interacts with CockroachDB Cloud through the managed MCP endpoint.
Why does AI agent memory have a dollar sign attached to it?
One of the more painful lessons I see AI teams learn the hard way: Agents without persistent memory don't learn. They start from scratch every single time a question arrives.
Every similar task triggers the full workflow again. Full LLM inference, full tool calls, full latency, full cost. You're paying for the same reasoning over and over, with no compounding return on what the system already figured out.
That becomes a business problem quickly. At enterprise scale, AI agent memory is not just a developer convenience; it affects application responsiveness, infrastructure spend, customer experience, and how much value each autonomous workflow can return before its economics break down.
Our product marketing and field team have been building reference architectures to make this concrete. When agents have access to persistent vector memory stored natively in the same database handling their transactional workload, the economics shift in a meaningful way. The second time a semantically similar task arrives, the system recognizes it, retrieves the prior work, and returns a result at near-zero incremental LLM cost. A 45-second multi-step analysis workflow returns in seconds on a repeated pattern.
The DoorDash team understood the infrastructure-economics side of this earlier than most. As their ML feature count grew 10x, they were upscaling Redis clusters every single week trying to keep pace. After moving CockroachDB in as their ML feature store, they cut cloud spend per stored value by 75% without giving up on latency. The infrastructure went from a weekly operational headache to part of the competitive advantage. That's not a benchmark result, it’s production at scale.
At the scale most enterprises are planning for, persistent memory isn't a nice-to-have optimization. It's a material difference in operating economics.
Why is the exhaust agents generate actually valuable data?
This one doesn't get enough attention.
Every agent action leaves a trail:
which tools were called
what the latency looked like
how confident the model was
how saturated the context window got
Most teams discard all of it; but that's a mistake, and it's about to become an expensive one.
AI agent observability depends on preserving that operational trail. Tool calls, latency, confidence signals, context-window usage, and permission checks are the evidence teams need to debug behavior, control costs, and prove that autonomous actions stayed within policy.
Our benchmarking work on agent-driven database load surfaced something important. Agentic workloads don't just create data pressure. They create an entirely new category of governance pressure that traditional database observability wasn't built to handle. The volume and velocity of agent writes don't look like anything human-driven applications produce, and you can't bolt your existing monitoring stack onto an agent fleet and expect it to tell you what's actually happening.
The operational exhaust that agents produce is exactly what you need to answer the questions that matter in production. These include:
Is this agent making decisions you can defend?
Is it staying within cost parameters?
When it acted autonomously and something went wrong, can you show exactly what happened and why?
The teams building agentic AI responsibly are treating this metadata as a first-class output of their systems, not an afterthought. That's how you turn autonomous AI from a governance liability into something a compliance team can actually trust and evaluate.
How does fragmentation break agentic AI architecture?
Here's the structural trap most teams don't see coming until they're already in it.
To manage context for agents, you end up running:
a vector database for embeddings
a relational store for operational data
a separate logging system for telemetry
a metadata catalog bolted on after the fact, that's perpetually out of sync with everything else
In a human-driven application, the synchronization overhead between those systems is manageable. Traffic arrives in predictable patterns, data moves in batches, and the seams stay hidden.
Agents don't work that way. They generate reads and writes across all of those systems simultaneously, continuously, at a pace and volume that turns synchronization lag from an inconvenience into a reliability failure. The data lag between systems is exactly where agent correctness breaks down, and it's not a tuning problem. Instead, it's a race condition built into the architecture.
The business impact is real. This fragmented architecture creates higher operational overhead, slower incident response, weaker auditability, and less confidence in deploying agents into workflows where incorrect decisions have financial or customer-facing consequences.
The work we've been doing with CockroachDB is oriented around collapsing that fragmentation: embeddings, relational data, operational metadata, and governance context handled together, transactionally, in one system. Not because it's architecturally elegant, though it is, but because the synchronization overhead of the alternative is a quiet killer you don't notice until you're already on the wrong side of it.
RELATED
The State of AI Infrastructure 2026: Can Systems Withstand AI Scale?
Where I think this is heading
We're still early. The patterns for production-grade agentic AI are evolving quickly, and I don't think anyone has the full picture figured out, including us.
But the teams I see getting ahead of this share something. They've stopped treating the database as a passive layer the agent queries, and started treating it as an active participant in agentic AI architecture: the place where memory, permissions, context, and observability live together close to the data, under the same consistency guarantees.
That's the architectural shift worth paying attention to right now. Not a better model, but a better foundation for the model to work from.
If you're working through any of this, some of our resources are worth your time depending on where you are in your agentic AI journey.
If you're still designing the architecture and want to understand what agentic load actually looks like under concurrency, our breakdown is the clearest technical picture I've come across: Scaling AI Agents: PostgreSQL vs CockroachDB Under High-Concurrency Workloads
If you're already in production and hitting reliability or governance problems, our framework maps directly to what breaks and why when model outputs start triggering real business actions: 8 AI Use Cases That Depend on Database Resilience
Where is the context layer actually breaking for your team? Reliability, cost, governance, or something more specific I haven't named here? Get in touch and let us know – genuinely curious what you're running into. The feedback on articles like this tend to surface better edge cases than any analyst report I've read.
RELATED
Webinar: The distributed SQL foundation for agentic scale
Quentin Packard is VP of Americas Sales at Cockroach Labs, where he works with engineering and infrastructure leaders building production-grade agentic AI systems. He previously helped build Splunk’s observability business and has worked across infrastructure automation, secrets management, and real-time data governance at HashiCorp and early stage startups. His writing draws on direct conversations with enterprise teams navigating AI and data architecture in production.


