changefeed.random_replica_selection.enabled cluster setting to change the way in which a changefeed distributes work across the cluster. With changefeed.random_replica_selection.enabled set to true, the job will evenly distribute changefeed work across the cluster by assigning it to any for a particular range. For changefeed.random_replica_selection.enabled to take effect on changefeed jobs, ensure you enable the cluster setting and then and existing changefeeds.
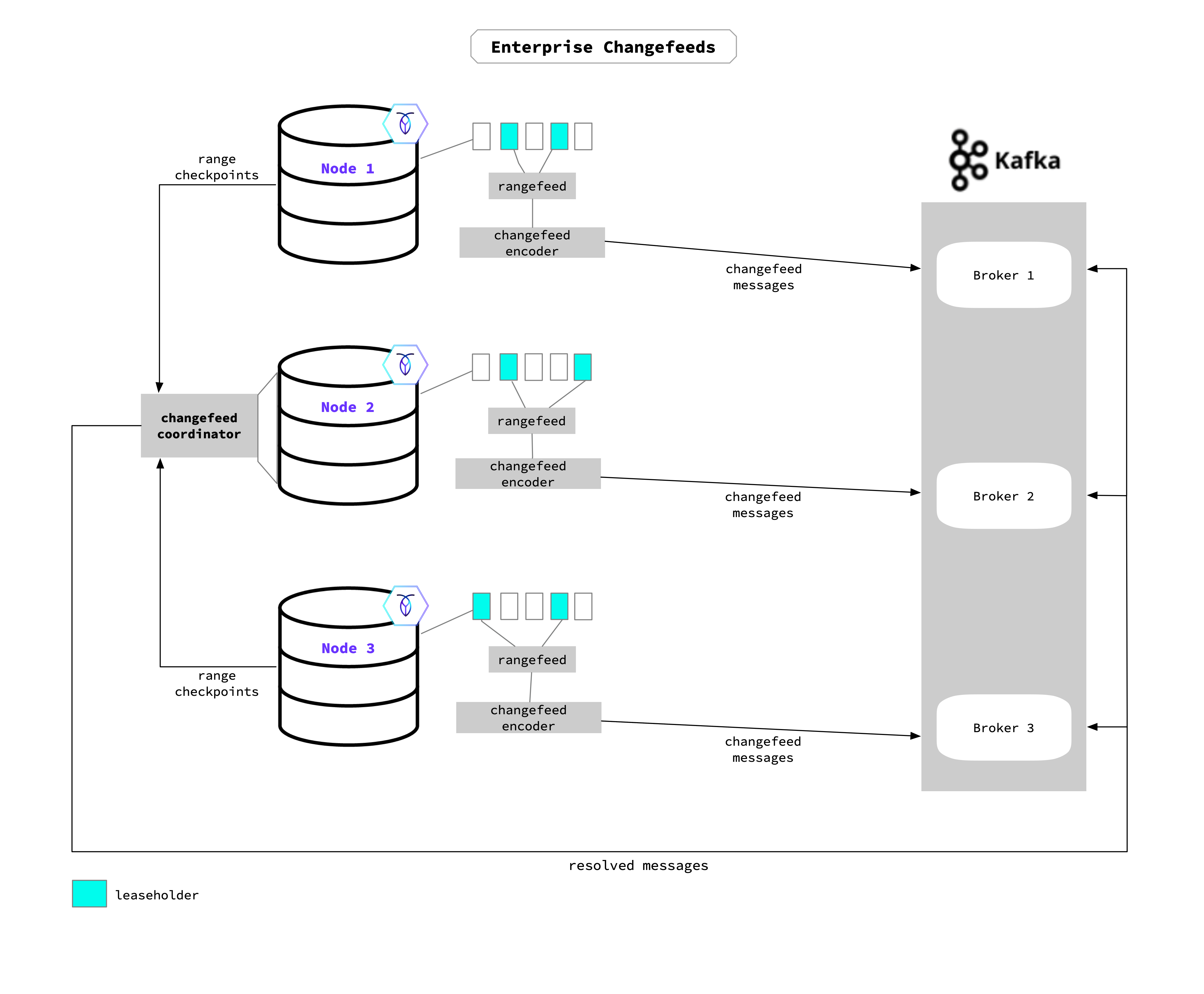
Each node uses its aggregator processors to send back checkpoint progress to the coordinator, which gathers this information to update the high-water mark timestamp. The high-water mark acts as a checkpoint for the changefeed’s job progress, and guarantees that all changes before (or at) the timestamp have been emitted. In the unlikely event that the changefeed’s coordinating node were to fail during the job, that role will move to a different node and the changefeed will restart from the last checkpoint. If restarted, the changefeed may starting at the high-water mark time to the current time. Refer to for detail on CockroachDB’s at-least-once-delivery-guarantee and how per-key message ordering is applied.
When you create a changefeed using , the will evaluate and optimize the query before the job sends the selected row changes to the changefeed encoder. The optimizer can restrict the rows a changefeed job considers during table scans, initial scans, and catch-up scans, which can make these more efficient using CDC queries.