
This page explains how reads and writes are affected by the replicated and distributed nature of data in CockroachDB. It starts by summarizing how CockroachDB executes queries and then guides you through a few simple read and write scenarios.
For a more detailed information about how transactions work in CockroachDB, see the Transaction Layer documentation.
CockroachDB architecture terms
| Term | Definition |
|---|---|
| cluster | A group of interconnected storage nodes that collaboratively organize transactions, fault tolerance, and data rebalancing. |
| node | An individual instance of CockroachDB. One or more nodes form a cluster. |
| range | CockroachDB stores all user data (tables, indexes, etc.) and almost all system data in a sorted map of key-value pairs. This keyspace is divided into contiguous chunks called ranges, such that every key is found in one range. From a SQL perspective, a table and its secondary indexes initially map to a single range, where each key-value pair in the range represents a single row in the table (also called the primary index because the table is sorted by the primary key) or a single row in a secondary index. As soon as the size of a range reaches 512 MiB (the default), it is split into two ranges. This process continues for these new ranges as the table and its indexes continue growing. |
| replica | A copy of a range stored on a node. By default, there are three replicas of each range on different nodes. |
| leaseholder | The replica that holds the "range lease." This replica receives and coordinates all read and write requests for the range. For most types of tables and queries, the leaseholder is the only replica that can serve consistent reads (reads that return "the latest" data). |
| Raft protocol | The consensus protocol employed in CockroachDB that ensures that your data is safely stored on multiple nodes and that those nodes agree on the current state even if some of them are temporarily disconnected. |
| Raft leader | For each range, the replica that is the "leader" for write requests. The leader uses the Raft protocol to ensure that a majority of replicas (the leader and enough followers) agree, based on their Raft logs, before committing the write. The Raft leader is almost always the same replica as the leaseholder. |
| Raft log | A time-ordered log of writes to a range that its replicas have agreed on. This log exists on-disk with each replica and is the range's source of truth for consistent replication. |
Query execution
When CockroachDB executes a query, the cluster routes the request to the leaseholder for the range containing the relevant data. If the query touches multiple ranges, the request goes to multiple leaseholders. For a read request, only the leaseholder of the relevant range retrieves the data. For a write request, the Raft consensus protocol dictates that a majority of the replicas of the relevant range must agree before the write is committed.
Let's consider how these mechanics play out in some hypothetical queries.
Read scenario
First, imagine a simple read scenario where:
- There are 3 nodes in the cluster.
- There are 3 small tables, each fitting in a single range.
- Ranges are replicated 3 times (the default).
- A query is executed against node 2 to read from table 3.
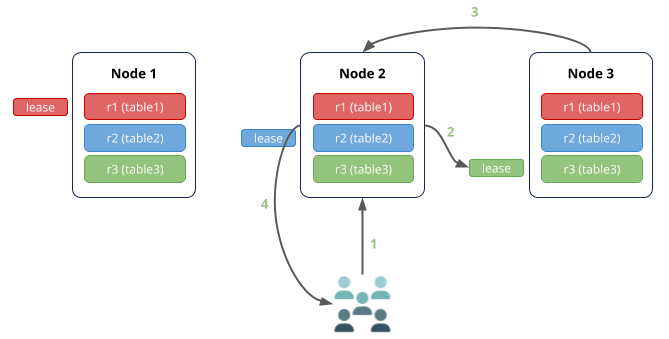
In this case:
- Node 2 (the gateway node) receives the request to read from table 3.
- The leaseholder for table 3 is on node 3, so the request is routed there.
- Node 3 returns the data to node 2.
- Node 2 responds to the client.
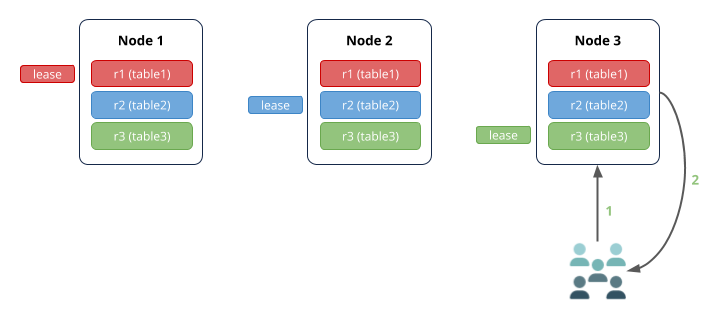
If the query is received by the node that has the leaseholder for the relevant range, there are fewer network hops:
Write scenario
Now imagine a simple write scenario where a query is executed against node 3 to write to table 1:
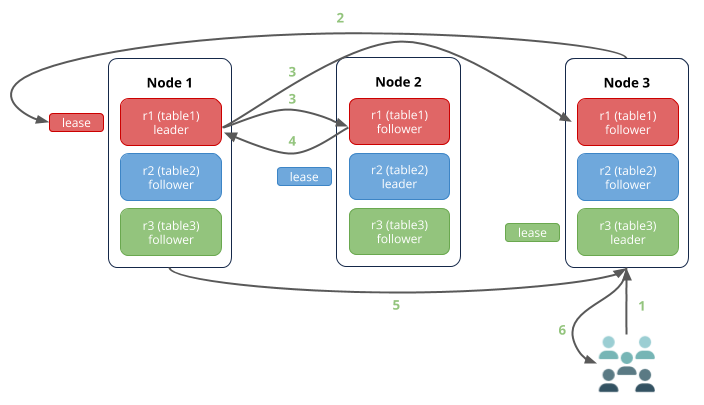
In this case:
- Node 3 (the gateway node) receives the request to write to table 1.
- The leaseholder for table 1 is on node 1, so the request is routed there.
- The leaseholder is the same replica as the Raft leader (as is typical), so it simultaneously appends the write to its own Raft log and notifies its follower replicas on nodes 2 and 3.
- As soon as one follower has appended the write to its Raft log (and thus a majority of replicas agree based on identical Raft logs), it notifies the leader and the write is committed to the key-values on the agreeing replicas. In this diagram, the follower on node 2 acknowledged the write, but it could just as well have been the follower on node 3. Also note that the follower not involved in the consensus agreement usually commits the write very soon after the others.
- Node 1 returns acknowledgement of the commit to node 3.
- Node 3 responds to the client.
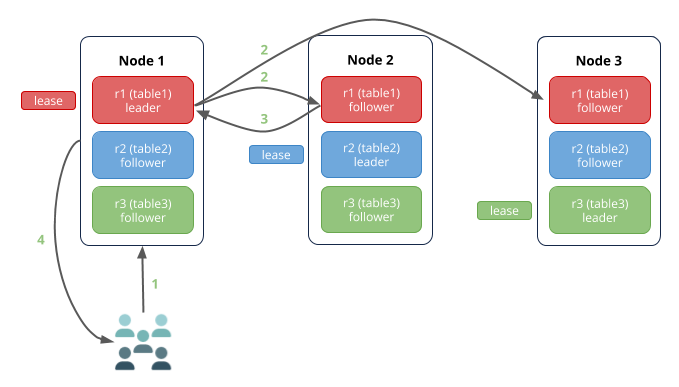
Just as in the read scenario, if the write request is received by the node that has the leaseholder and Raft leader for the relevant range, there are fewer network hops:
Network and I/O bottlenecks
With the above examples in mind, it's always important to consider network latency and disk I/O as potential performance bottlenecks. In summary:
- For reads, hops between the gateway node and the leaseholder add latency.
- For writes, hops between the gateway node and the leaseholder/Raft leader, and hops between the leaseholder/Raft leader and Raft followers, add latency. In addition, since Raft log entries are persisted to disk before a write is committed, disk I/O is important.
