
This page shows you how to decommission one or more nodes. Decommissioning a node removes it from the CockroachDB cluster.
You might do this, for example, when downsizing a cluster or reacting to hardware failures.
Node decommissioning should not be performed when upgrading your cluster's version of CockroachDB or performing planned maintenance (e.g., upgrading system software). In these scenarios, you will want to temporarily stop the node and restart it later.
Overview
How it works
A node is considered to be decommissioned when it meets two criteria:
- The node has completed the decommissioning process.
- The node has been stopped and has not updated its liveness record for the duration configured via
server.time_until_store_dead, which defaults to 5 minutes.
The decommissioning process transfers all range replicas on the node to other nodes. During and after this process, the node is considered "decommissioning" and continues to accept new SQL connections. Even without replicas, the node can still function as a gateway to route connections to relevant data. For this reason, the /health?ready=1 monitoring endpoint continues to consider the node "ready" so load balancers can continue directing traffic to the node.
After all range replicas have been transferred, a graceful shutdown is initiated by sending SIGTERM, during which the node is drained of SQL clients, distributed SQL queries, and range leases. Meanwhile, the /health?ready=1 monitoring endpoint starts returning a 503 Service Unavailable status response code so that load balancers stop directing traffic to the node. Once draining completes and the process is terminated, the node stops updating its liveness record, and after the duration configured via server.time_until_store_dead is considered to be decommissioned.
You can check the status of node decommissioning with the CLI.
Considerations
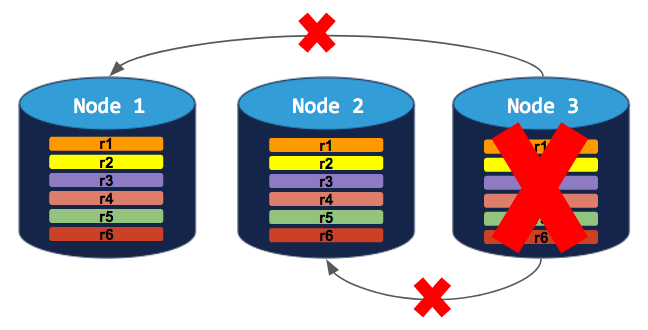
Before decommissioning a node, make sure other nodes are available to take over the range replicas from the node. If no other nodes are available, the decommissioning process will hang indefinitely. See the Examples below for more details.
Examples
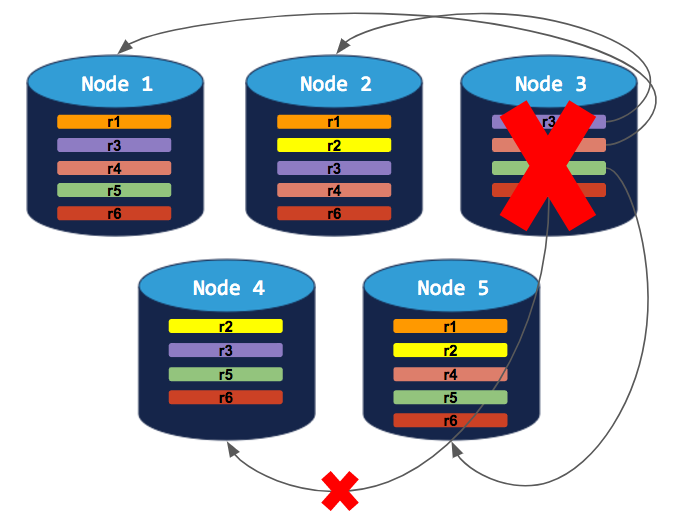
3-node cluster with 3-way replication
In this scenario, each range is replicated 3 times, with each replica on a different node:
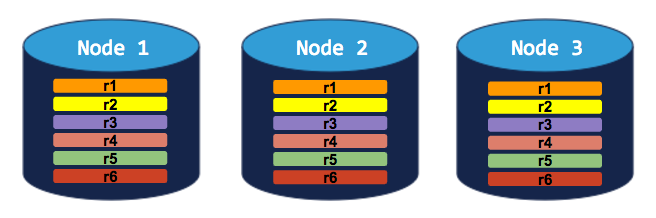
If you try to decommission a node, the process will hang indefinitely because the cluster cannot move the decommissioning node's replicas to the other 2 nodes, which already have a replica of each range:
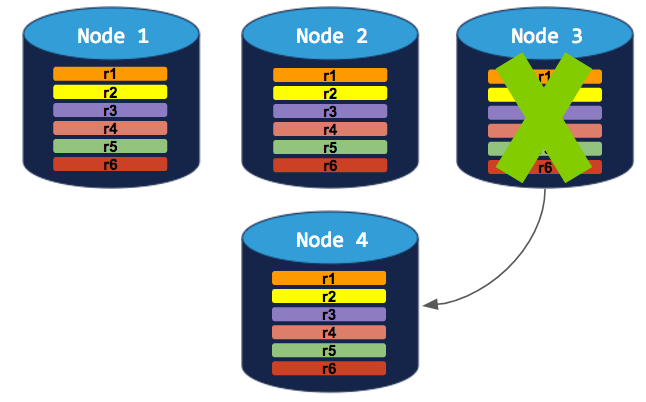
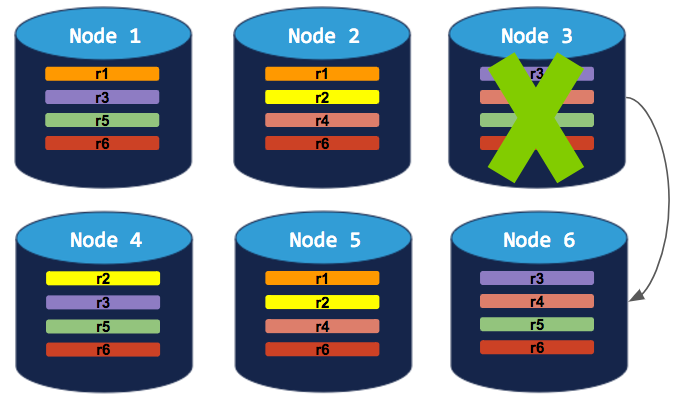
To successfully decommission a node in this cluster, you need to add a 4th node. The decommissioning process can then complete:
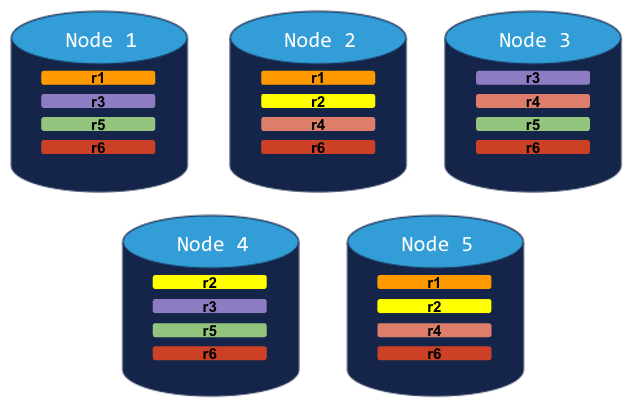
5-node cluster with 3-way replication
In this scenario, like in the scenario above, each range is replicated 3 times, with each replica on a different node:
If you decommission a node, the process will run successfully because the cluster will be able to move the node's replicas to other nodes without doubling up any range replicas:
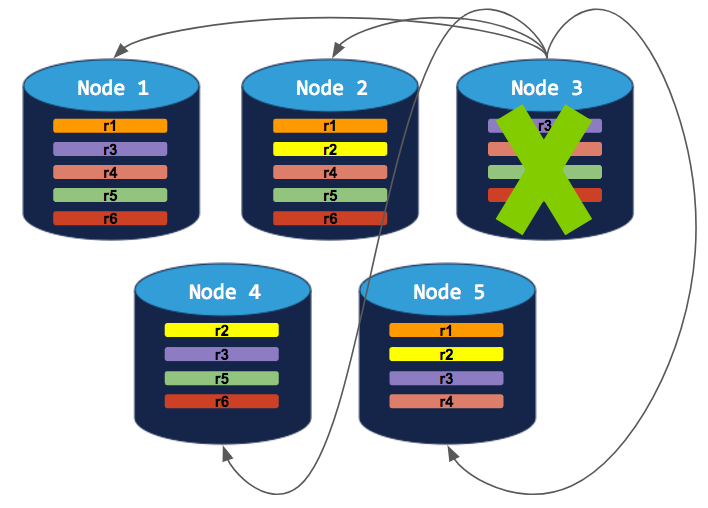
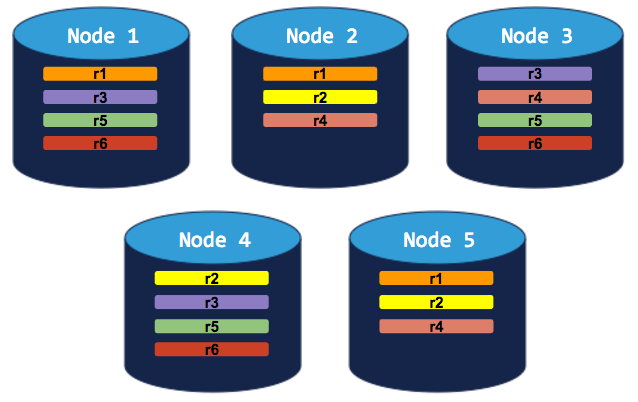
5-node cluster with 5-way replication for a specific table
In this scenario, a custom replication zone has been set to replicate a specific table 5 times (range 6), while all other data is replicated 3 times:
If you try to decommission a node, the cluster will successfully rebalance all ranges but range 6. Since range 6 requires 5 replicas (based on the table-specific replication zone), and since CockroachDB will not allow more than a single replica of any range on a single node, the decommissioning process will hang indefinitely:
To successfully decommission a node in this cluster, you need to add a 6th node. The decommissioning process can then complete:
Remove a single node (live)
Before decommissioning a node
To ensure your cluster can adequately handle decommissioning nodes:
- Before decommissioning each node verify that there are no underreplicated or unavailable ranges.
If you have a decommissioning node that appears to be hung, you can recommission the node. If you notice any issues persisting, contact our support team.
If possible, keep the node running instead of stopping it, because a hung decommissioning process might be a symptom of a problem that could result in data loss.
Confirm that there are enough nodes to take over the replicas from the node you want to remove. See some Example scenarios above.
Step 1. Check the node before decommissioning
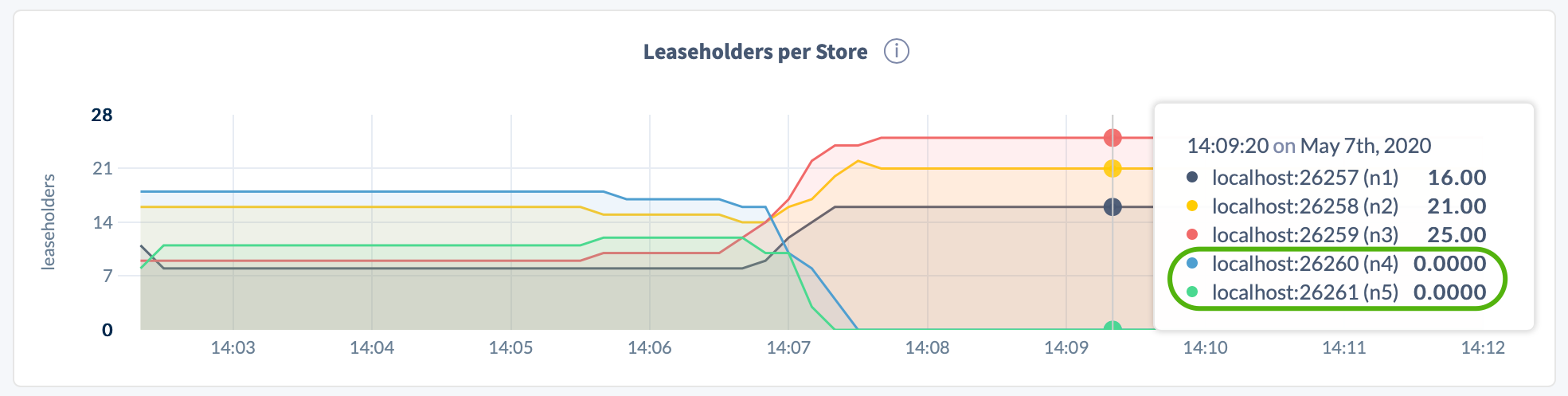
Open the DB Console, click Metrics on the left, select the Replication dashboard, and hover over the Replicas per Store and Leaseholders per Store graphs:
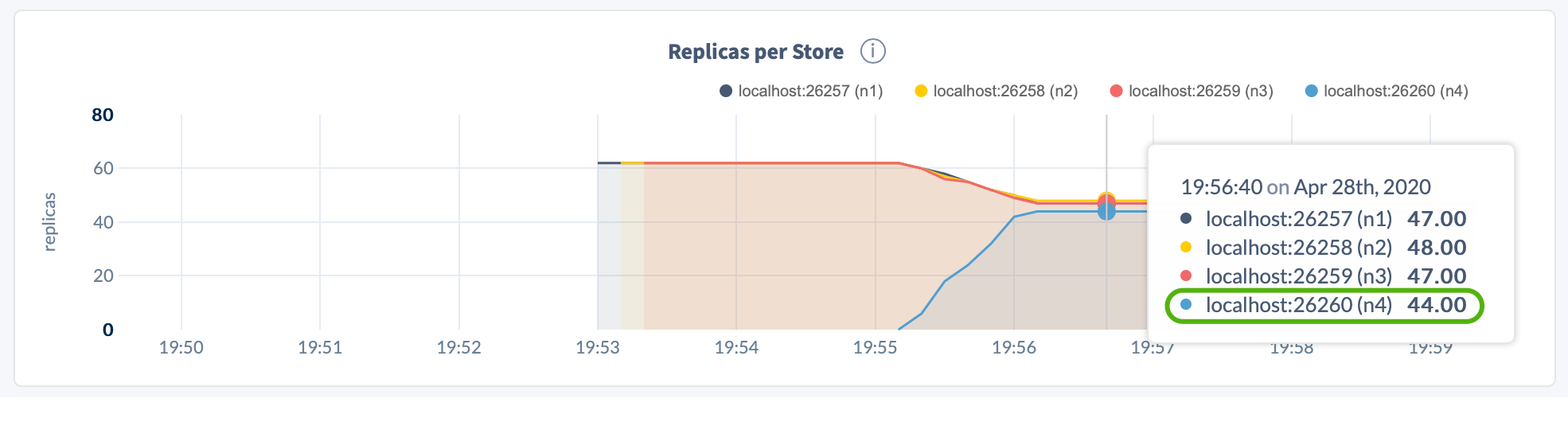
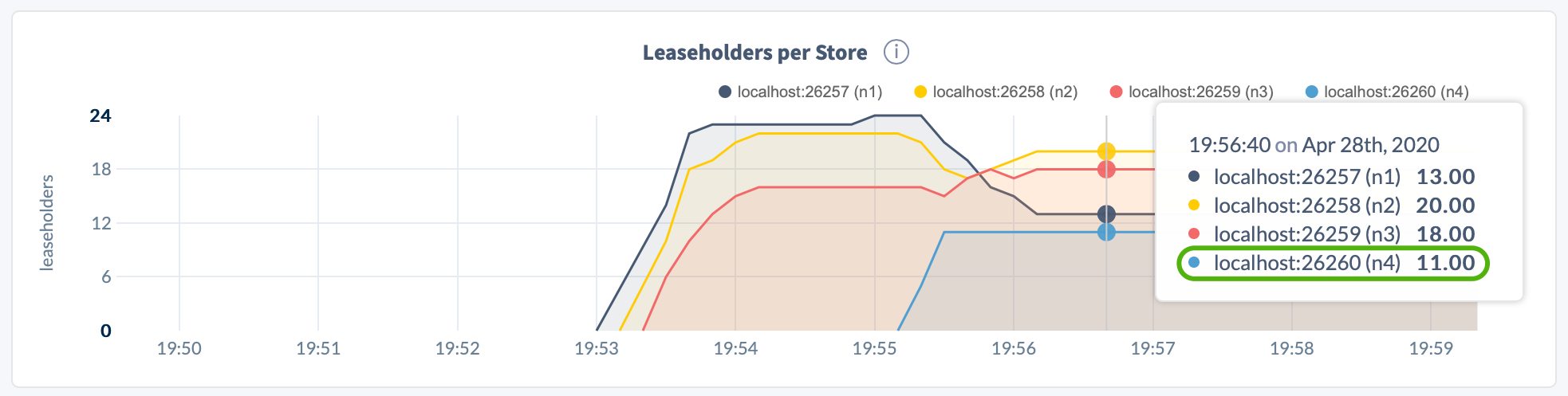
Step 2. Start the decommissioning process on the node
Run the cockroach node decommission command against the address of the node to decommission:
$ cockroach node decommission --self --certs-dir=certs --host=<address of node to decommission>
$ cockroach node decommission --self --insecure --host=<address of node to decommission>
You'll then see the decommissioning status print to stderr as it changes:
id | is_live | replicas | is_decommissioning | is_draining
+---+---------+----------+--------------------+-------------+
4 | true | 45 | true | false
(1 row)
Once the node has completed the decommissioning process, you'll see a confirmation:
id | is_live | replicas | is_decommissioning | is_draining
+---+---------+----------+--------------------+-------------+
4 | true | 0 | true | false
(1 row)
No more data reported on target nodes. Please verify cluster health before removing the nodes.
Note that is_decommissioning will remain true after all replicas have been transferred from the node.
Step 3. Check the node and cluster after the decommissioning process
In the DB Console Replication dashboard, again hover over the Replicas per Store and Leaseholders per Store graphs. For the decommissioning node, the counts should be 0:
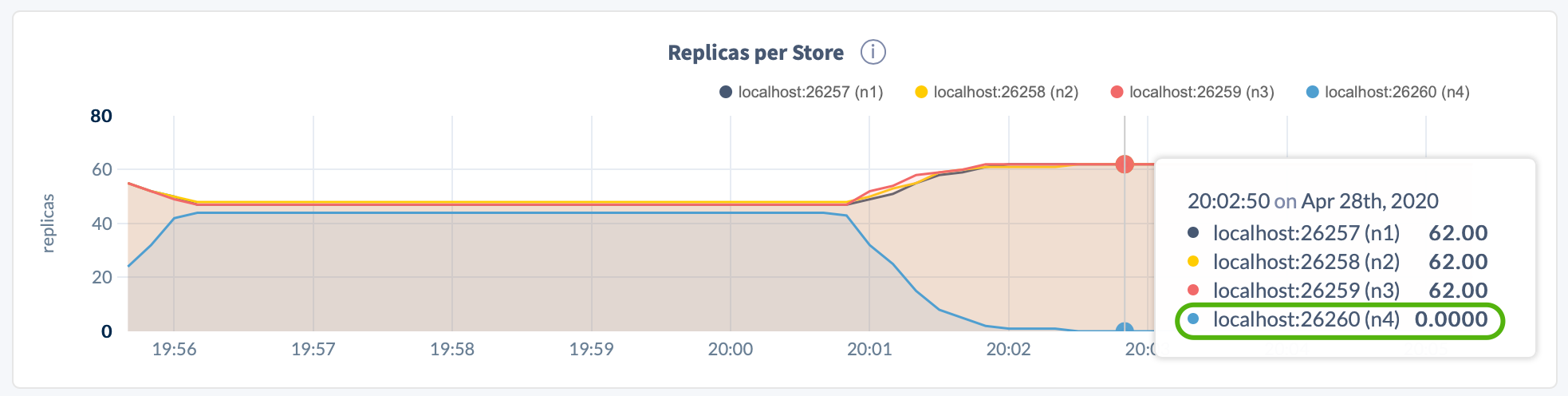
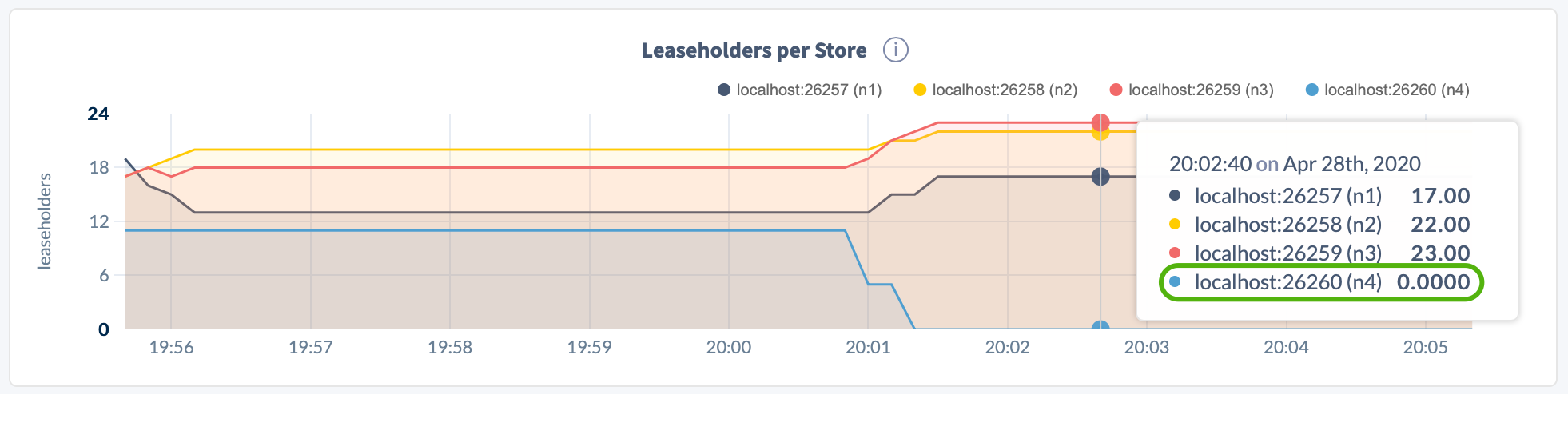
Return to the Node List on the Overview page. The DECOMMISSIONING node should have 0 replicas, and all other nodes should be healthy (LIVE):
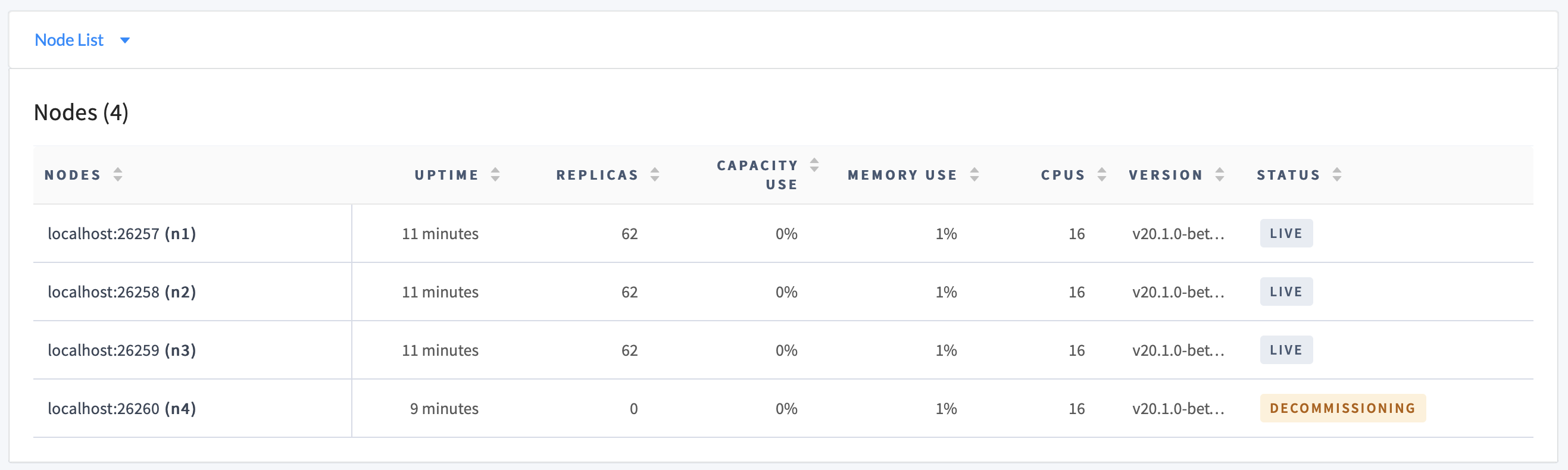
Even with zero replicas on a node, its status on the Node List will be DECOMMISSIONING until you stop the node. It is also counted as a "Suspect" node in the Cluster Overview panel until being shut down.
Step 4. Stop the decommissioning node
Drain and stop the node using one of the following methods:
- If the node was started with a process manager, gracefully stop the node by sending
SIGTERMwith the process manager. If the node is not shutting down after 1 minute, sendSIGKILLto terminate the process. When usingsystemd, for example, setTimeoutStopSec=60in your configuration template and runsystemctl stop <systemd config filename>to stop the node withoutsystemdrestarting it. - If the node was started using
cockroach startand is running in the foreground, pressctrl-cin the terminal. - If the node was started using
cockroach startand the--backgroundand--pid-fileflags, runkill <pid>, where<pid>is the process ID of the node.
The amount of time you should wait before sending SIGKILL can vary depending on your cluster configuration and workload, which affects how long it takes your nodes to complete a graceful shutdown. In certain edge cases, forcefully terminating the process before the node has completed shutdown can result in temporary data unavailability, latency spikes, uncertainty errors, ambiguous commit errors, or query timeouts. If you need maximum cluster availability, you can run cockroach node drain prior to node shutdown and actively monitor the draining process instead of automating it.
After the duration configured via server.time_until_store_dead, you'll see the stopped node listed under Recently Decommissioned Nodes:

At this point, the node is DECOMMISSIONED and will no longer appear in timeseries graphs unless you view a time range during which the node was live. However, it will never disappear from the historical list of decommissioned nodes, linked beneath Recently Decommissioned Nodes.
Remove a single node (dead)
After a node has been dead for 5 minutes, CockroachDB transfers the range replicas and range leases on the node to available live nodes. However, if the dead node is restarted, the cluster will rebalance replicas and leases to the node.
To prevent the cluster from rebalancing data to a dead node if it comes back online, do the following:
You can check that a node is dead and find its internal ID by either running cockroach node status or opening the DB Console and scrolling to the Node List on the Overview page.
Step 1. Mark the dead node as decommissioned
Run the cockroach node decommission command against the address of any live node, specifying the ID of the dead node:
$ cockroach node decommission <id of the dead node> --certs-dir=certs --host=<address of any live node>
$ cockroach node decommission <id of the dead node> --insecure --host=<address of any live node>
id | is_live | replicas | is_decommissioning | is_draining
+---+---------+----------+--------------------+-------------+
4 | false | 0 | true | true
(1 row)
No more data reported on target nodes. Please verify cluster health before removing the nodes.
Within 5 minutes, you'll see the node move from the Node List to the Recently Decommissioned Nodes list in the DB Console, with its status changed from DEAD to DECOMMISSIONED.
At this point, the node is DECOMMISSIONED and will no longer appear in timeseries graphs unless you view a time range during which the node was live. However, it will never disappear from the historical list of decommissioned nodes, linked beneath Recently Decommissioned Nodes.
Remove multiple nodes
Before decommissioning nodes
- Before decommissioning each node verify that there are no underreplicated or unavailable ranges.
If you have a decommissioning node that appears to be hung, you can recommission the node. If you notice any issues persisting, contact our support team.
If possible, keep the node running instead of stopping it, because a hung decommissioning process might be a symptom of a problem that could result in data loss.
Confirm that there are enough nodes to take over the replicas from the node you want to remove. See some Example scenarios above.
Step 1. Check the nodes before decommissioning
Open the DB Console, click Metrics on the left, select the Replication dashboard, and hover over the Replicas per Store and Leaseholders per Store graphs:
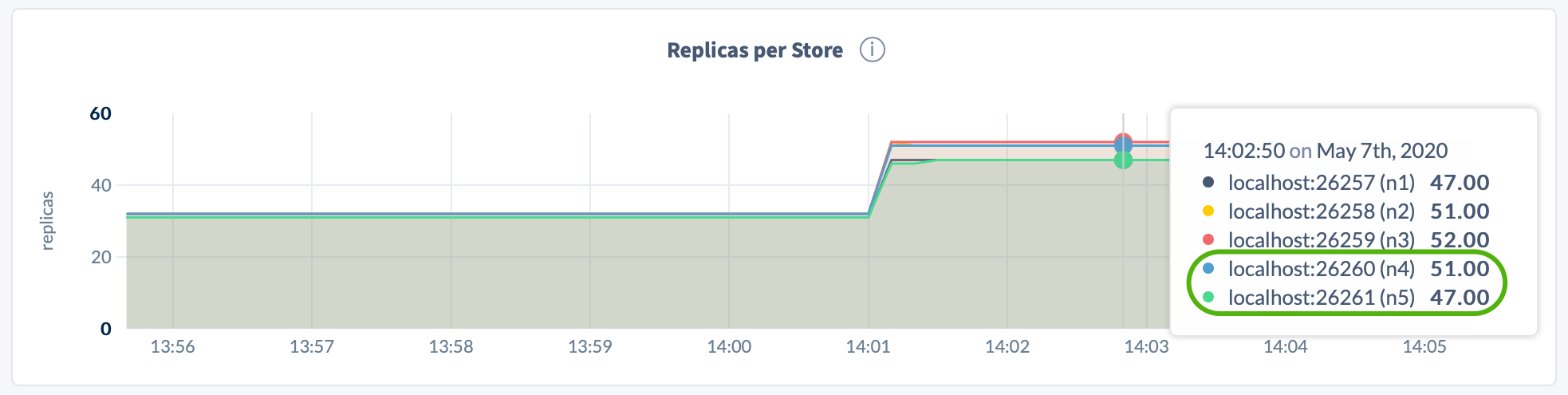
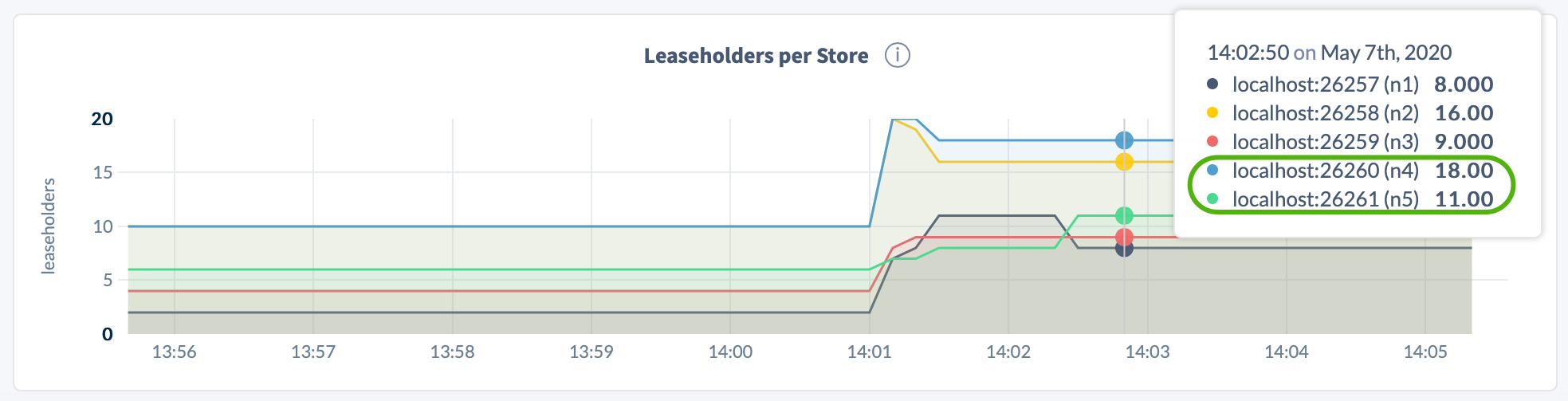
Step 2. Start the decommissioning process on the nodes
Run the cockroach node decommission command against the address of each node to decommission:
$ cockroach node decommission --self --certs-dir=certs --host=<address of node to decommission>
$ cockroach node decommission --self --certs-dir=certs --host=<address of another node to decommission>
$ cockroach node decommission --self --insecure --host=<address of node to decommission>
$ cockroach node decommission --self --insecure --host=<address of another node to decommission>
You'll then see the decommissioning status print to stderr as it changes:
id | is_live | replicas | is_decommissioning | is_draining
+---+---------+----------+--------------------+-------------+
4 | true | 18 | true | false
5 | true | 16 | true | false
(2 rows)
Once the nodes have been fully decommissioned, you'll see a confirmation:
id | is_live | replicas | is_decommissioning | is_draining
+---+---------+----------+--------------------+-------------+
4 | true | 0 | true | false
5 | true | 0 | true | false
(2 rows)
No more data reported on target nodes. Please verify cluster health before removing the nodes.
Note that is_decommissioning will remain true after all replicas have been transferred from each node.
Step 3. Check the nodes and cluster after the decommissioning process
In the DB Console Replication dashboard, again hover over the Replicas per Store and Leaseholders per Store graphs. For the decommissioning nodes, the counts should be 0:
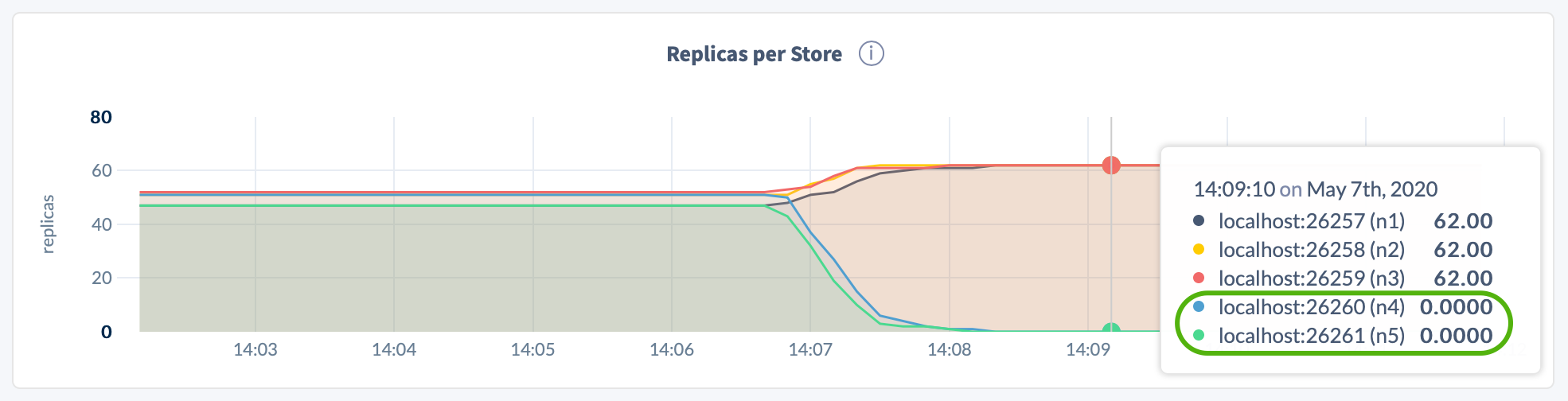
Return to the Node List on the Overview page. The DECOMMISSIONING nodes should each have 0 replicas, and all other nodes should be healthy (LIVE):
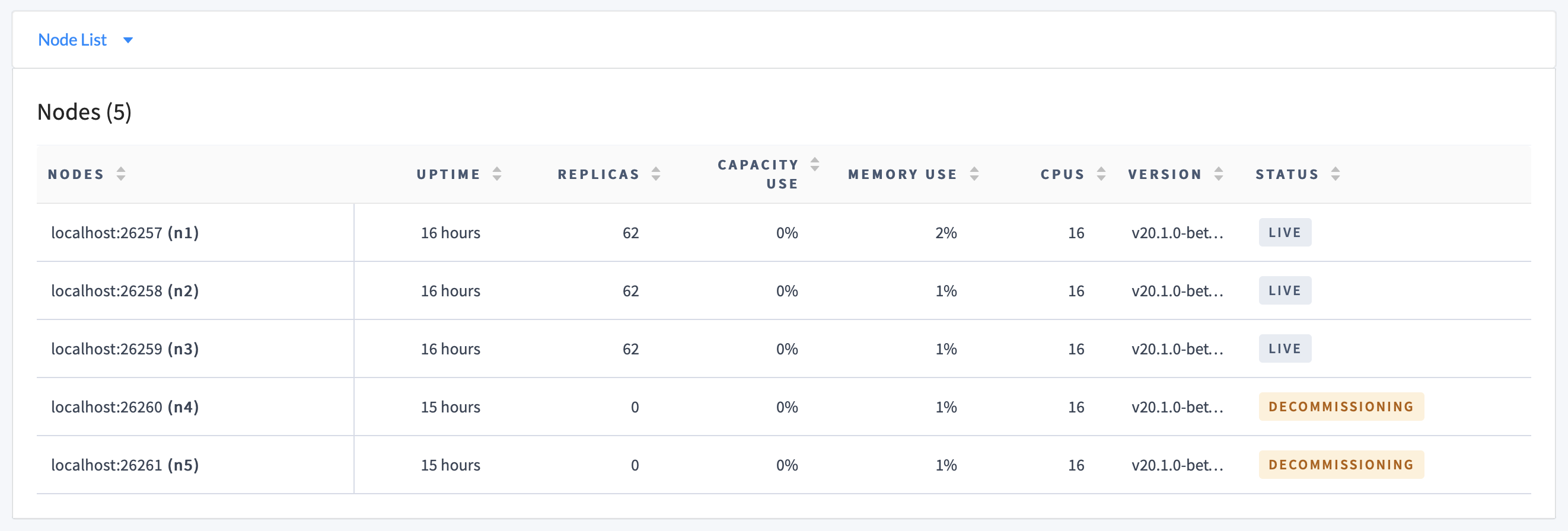
Even with zero replicas on a node, its status on the Node List will be DECOMMISSIONING until you stop the node. It is also counted as a "Suspect" node in the Cluster Overview panel until being shut down.
Step 4. Stop the decommissioning nodes
Drain and stop each node using one of the following methods:
- If the node was started with a process manager, gracefully stop the node by sending
SIGTERMwith the process manager. If the node is not shutting down after 1 minute, sendSIGKILLto terminate the process. When usingsystemd, for example, setTimeoutStopSec=60in your configuration template and runsystemctl stop <systemd config filename>to stop the node withoutsystemdrestarting it. - If the node was started using
cockroach startand is running in the foreground, pressctrl-cin the terminal. - If the node was started using
cockroach startand the--backgroundand--pid-fileflags, runkill <pid>, where<pid>is the process ID of the node.
The amount of time you should wait before sending SIGKILL can vary depending on your cluster configuration and workload, which affects how long it takes your nodes to complete a graceful shutdown. In certain edge cases, forcefully terminating the process before the node has completed shutdown can result in temporary data unavailability, latency spikes, uncertainty errors, ambiguous commit errors, or query timeouts. If you need maximum cluster availability, you can run cockroach node drain prior to node shutdown and actively monitor the draining process instead of automating it.
After the duration configured via server.time_until_store_dead, you'll see the stopped nodes listed under Recently Decommissioned Nodes:
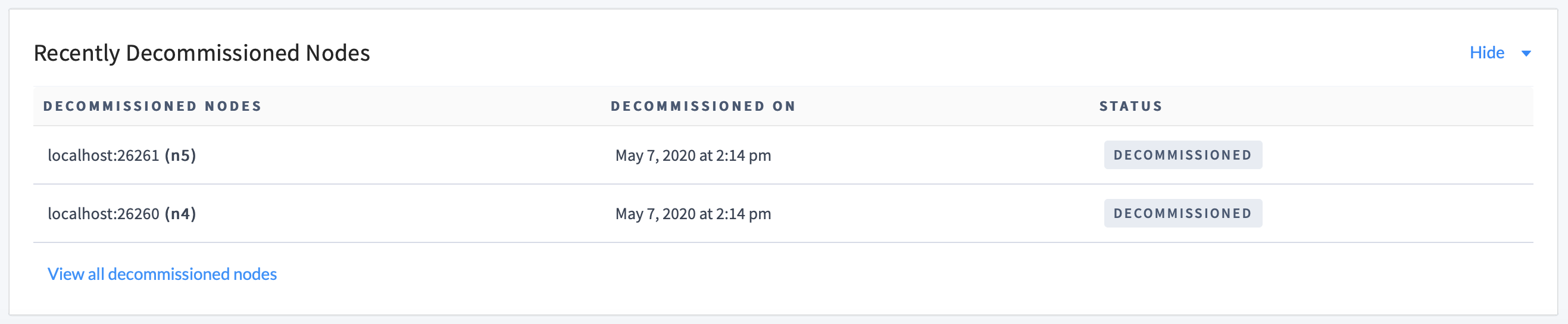
At this point, the nodes are DECOMMISSIONED and will no longer appear in timeseries graphs unless you view a time range during which the nodes were live. However, they will never disappear from the historical list of decommissioned nodes, linked beneath Recently Decommissioned Nodes.
Recommission nodes
If you accidentally started decommissioning a node, or have a node with a hung decommissioning process, you can recommission the node. This cancels the process of transferring replicas on the node to other nodes.
Recommissioning is intended to cancel an active decommissioning process. If all ranges have been removed from a node, you must start a new node. As of v20.2, a fully decommissioned node is permanently decommissioned, and cannot be recommissioned.
Step 1. Cancel the decommissioning process
Press ctrl-c in each terminal with an ongoing decommissioning process that you want to cancel.
Step 2. Recommission the decommissioning nodes
Execute the cockroach node recommission command against the address of the node to recommission:
$ cockroach node recommission --self --certs-dir=certs --host=<address of node to recommission>
$ cockroach node recommission --self --insecure --host=<address of node to recommission>
The value of is_decommissioning will change back to false:
id | is_live | replicas | is_decommissioning | is_draining
+---+---------+----------+--------------------+-------------+
4 | false | 0 | false | false
(1 row)
On the Node List, you should soon see the recommissioned nodes listed as LIVE. After a few minutes, you should see replicas rebalanced to the nodes.
Check the status of decommissioning nodes
To check the progress of decommissioning nodes, run the cockroach node status command with the --decommission flag:
$ cockroach node status --decommission --certs-dir=certs --host=<address of any live node>
$ cockroach node status --decommission --insecure --host=<address of any live node>
id | address | build | started_at | updated_at | is_available | is_live | gossiped_replicas | is_decommissioning | is_draining
+---+------------------------+---------+----------------------------------+----------------------------------+--------------+---------+-------------------+--------------------+-------------+
1 | 165.227.60.76:26257 | 91a299d | 2018-10-01 16:53:10.946245+00:00 | 2018-10-02 14:04:39.280249+00:00 | true | true | 26 | false | false
2 | 192.241.239.201:26257 | 91a299d | 2018-10-01 16:53:24.22346+00:00 | 2018-10-02 14:04:39.415235+00:00 | true | true | 26 | false | false
3 | 67.207.91.36:26257 | 91a299d | 2018-10-01 17:34:21.041926+00:00 | 2018-10-02 14:04:39.233882+00:00 | true | true | 25 | false | false
4 | 138.197.12.74:26257 | 91a299d | 2018-10-01 17:09:11.734093+00:00 | 2018-10-02 14:04:37.558204+00:00 | true | true | 25 | false | false
5 | 174.138.50.192:26257 | 91a299d | 2018-10-01 17:14:01.480725+00:00 | 2018-10-02 14:04:39.293121+00:00 | true | true | 0 | true | false
(5 rows)
is_decommissioning == trueimplies that replicas are being or have been transferred to other nodes. The node is either undergoing or has completed the decommissioning process.is_draining == trueimplies that the node is no longer accepting SQL connections. The node is either in the process of shutting down or has already done so.
