
Once you've installed the official CockroachDB Docker image, it's simple to run an insecure multi-node cluster across multiple Docker containers on a single host, using Docker volumes to persist node data.
To try CockroachDB Cloud instead of running CockroachDB yourself, refer to the Cloud Quickstart.
The --insecure flag used in this tutorial is intended for non-production testing only. To run CockroachDB in production, use a secure cluster instead.
Before you begin
- Make sure you have already installed the official CockroachDB Docker image.
- For quick SQL testing or application development, consider running a single-node cluster. When you use Docker to run a single-node cluster, some additional features are available to assist you with testing and development. See Start a single-node cluster. Single-node clusters are not highly available or fault tolerant, and are not appropriate for production use.
- Running multiple nodes on a single host is useful for testing CockroachDB, but it's not highly available or fault tolerant, and is not suitable for production. To run a physically-distributed cluster in containers, use an orchestration tool like Kubernetes. See Orchestration for more details, and review the Production Checklist.
Start a multi-node cluster
Step 1. Create a bridge network
Since you'll be running multiple Docker containers on a single host, with one CockroachDB node per container, create a Docker bridge network. The network has configurable properties such as a pool of IP addresses, network gateway, and routing rules. All nodes will connect to this network and can communicate openly by default, but incoming traffic can reach a container only through the container's published port mappings, as described in Step 3: Start the cluster. Because the network is a bridge, from the point of view of the client, the Docker host seems to service the request directly.
docker network create -d bridge roachnet
To customize your bridge network or create a different type of Docker network, refer to Docker's documentation for docker network create.
In subsequent steps, replace roachnet with the name of your Docker network.
Step 2: Create Docker volumes for each cluster node
Cockroach Labs recommends that you store cluster data in Docker volumes rather than in the storage layer of the running container. Using a volume has the following advantages over using bind mounts or writing directly to the running container's filesystem.
- Volumes are managed entirely by Docker. A bind mount mounts an arbitrary directory on the Docker host into the container, and that directory could potentially be modified or deleted by any process with permission.
- Volumes persist even if the containers that were using it are deleted. A container's local storage is temporarily unavailable if the container is stopped, and is permanently removed if the container is deleted.
- When compared to a container's local storage, writing to either a local volume or a bind mount has considerably better performance because it uses fewer kernel system calls on the Docker host. For an explanation, refer to Manage Data in Docker.
- A volume can be backed up, restored, or migrated to a different container or Docker host. Refer to Back Up, Restore, or Migrate Data Volumes.
- A volume can be pre-populated before connecting it to a container. Refer to Populate a Volume Using a Container.
- A volume can be backed by local storage, a cloud storage resource, SSH, NFS, Samba, or raw block storage, among others. For details, refer to Use a Volume Driver.
Avoid using the -v / --volume command to mount a local macOS filesystem into the container. Use Docker volumes or a tmpfs mount.
Create a Docker volume for each container. You can create only one volume at a time.
docker volume create roach1
docker volume create roach2
docker volume create roach3
Step 3. Start the cluster
This section shows how to start a three-node cluster where:
- Each node will store its data in a unique Docker volume.
- Each node will listen for SQL and HTTP connections at a unique port each on the
roachnetnetwork, and these ports are published. Client requests to the Docker host at a given port are forwarded to the container that is publishing that port. Nodes do not listen onlocalhost. - Each node will listen and advertise for inter-node cluster traffic at port 26357 on the
roachnetnetwork. This port is not published, so inter-node traffic does not leave this network.
When SQL and inter-node traffic are separated, some client commands need to be modified with a --host flag or a --uri connection string. Some commands, such as cockroach init, default to port 26257 but must use the inter-node traffic port (the --listen-addr or --advertise-addr) rather than the SQL traffic port when traffic is separated.
Optionally, on each node, set the
COCKROACH_ARGSenvironment variable to the string of arguments to use when starting CockroachDB. IfCOCKROACH_ARGSis set, its value is automatically passed to thecockroachcommand, and any additional arguments to thecockroachcommand are ignored.Start the first node and configure it to listen on
roach1:26257for SQL clients androach1:8080for the DB Console and to publish these ports, and to useroach1:26357for inter-node traffic. The Docker host will forward traffic to a published port to the publishing container. CockroachDB starts in insecure mode and acertsdirectory is not created.docker run -d \ --name=roach1 \ --hostname=roach1 \ --net=roachnet \ -p 26257:26257 \ -p 8080:8080 \ -v "roach1:/cockroach/cockroach-data" \ cockroachdb/cockroach:v26.2.2 start \ --advertise-addr=roach1:26357 \ --http-addr=roach1:8080 \ --listen-addr=roach1:26357 \ --sql-addr=roach1:26257 \ --insecure \ --join=roach1:26357,roach2:26357,roach3:26357This command creates a container and starts the first CockroachDB node inside it. Take a moment to understand each part:
docker run: The Docker command to start a new container.-d: This flag runs the container in the background so you can continue the next steps in the same shell.--name: The name for the container. This is optional, but a custom name makes it significantly easier to reference the container in other commands, for example, when opening a Bash session in the container or stopping the container.--hostname: The hostname for the container. You will use this to join other containers/nodes to the cluster.--net: The bridge network for the container to join. See step 1 for more details.-p 26257:26257 -p 8080:8080: These flags cause the Docker host to publish ports 26257 and 8080 and to forward requests to a published port to the same port on the container.-v "roach1:/cockroach/cockroach-data": This flag mounts theroach1Docker volume into the container's filesystem at/cockroach/cockroach-data/. This volume will contain data and logs for the container, and the volume will persist after the container is stopped or deleted. For more details, see Docker's volumes documentation.cockroachdb/cockroach:v26.2.2 start (...) --join: The CockroachDB command to start a node in the container. The--advertise-addr,--http-addr,--listen-addr, and--sql-addrflags cause CockroachDB to listen on separate ports for inter-node traffic, DB Console traffic, and SQL traffic. The--joinflag contains each node's hostname or IP address and the port where it listens for inter-node traffic from other nodes.
Start the second node and configure it to listen on
roach2:26258for SQL clients androach2:8081for the DB Console and to publish these ports, and to useroach2:26357for inter-node traffic. The offsets for the published ports avoid conflicts withroach1's published ports. The named volumeroach2is mounted in the container at/cockroach/cockroach-data.CockroachDB starts in insecure mode and a
certsdirectory is not created.docker run -d \ --name=roach2 \ --hostname=roach2 \ --net=roachnet \ -p 26258:26258 \ -p 8081:8081 \ -v "roach2:/cockroach/cockroach-data" \ cockroachdb/cockroach:v26.2.2 start \ --advertise-addr=roach2:26357 \ --http-addr=roach2:8081 \ --listen-addr=roach2:26357 \ --sql-addr=roach2:26258 \ --insecure \ --join=roach1:26357,roach2:26357,roach3:26357Start the third node and configure it to listen on
roach3:26259for SQL clients androach2:8082for the DB Console and to publish these ports, and to useroach3:26357for inter-node traffic. The offsets for the published ports avoid conflicts withroach1's androach2's published ports. The named volumeroach3is mounted in the container at/cockroach/cockroach-data.docker run -d \ --name=roach3 \ --hostname=roach3 \ --net=roachnet \ -p 26259:26259 \ -p 8082:8082 \ -v "roach3:/cockroach/cockroach-data" \ cockroachdb/cockroach:v26.2.2 start \ --advertise-addr=roach3:26357 \ --http-addr=roach3:8082 \ --listen-addr=roach3:26357 \ --sql-addr=roach3:26259 \ --insecure \ --join=roach1:26357,roach2:26357,roach3:26357Perform a one-time initialization of the cluster. This example runs the
cockroach initcommand from within theroach1container, but you can run it from any container or from an external system that can reach the Docker host.cockroach initconnects to the node's--advertise-addr, rather than the node's--sql-addr. Replaceroach1:26357with the node's--advertise-addrvalue (not the node's--sql-addr). This example runs thecockroachcommand directly on a cluster node, but you can run it from any system that can connect to the Docker host.docker exec -it roach1 ./cockroach --host=roach1:26357 init --insecureThe following message displays:
Cluster successfully initializedEach node also prints helpful startup details to its log. For example, the following command runs the
grepcommand from within theroach1container to display lines in its/cockroach-data/logs/cockroach.loglog file that contain the stringnode startingand the next 11 lines.docker exec -it roach1 grep 'node starting' /cockroach/cockroach-data/logs/cockroach.log -A 11The output will look something like this:
CockroachDB node starting at build: CCL v26.2.2 @ 2026-06-05 00:00:00 (go1.19.6) webui: http://roach1:8080 sql: postgresql://root@roach1:26357?sslmode=disable client flags: /cockroach/cockroach <client cmd> --host=roach1:26357 logs: /cockroach/cockroach-data/logs temp dir: /cockroach/cockroach-data/cockroach-temp273641911 external I/O path: /cockroach/cockroach-data/extern store[0]: path=/cockroach/cockroach-data status: initialized new cluster clusterID: 1a705c26-e337-4b09-95a6-6e5a819f9eec nodeID: 1
Step 4. Connect to the cluster
Now that your cluster is live, you can use any node as a SQL gateway. To test this out, let's use the docker exec command to start the built-in SQL shell in the roach1 container.
Start the SQL shell in a container or from an external system that can reach the Docker host. Set
--hostto the Docker host's IP address and use any of the ports where nodes are listening for SQL connections,26257,26258, or26259. This example connects the SQL shell within theroach1container toroach2:26258. You could also connect toroach3:26259.docker exec -it roach1 ./cockroach sql --host=roach2:26258 --insecureRun some basic CockroachDB SQL statements:
> CREATE DATABASE bank;> CREATE TABLE bank.accounts (id INT PRIMARY KEY, balance DECIMAL);> INSERT INTO bank.accounts VALUES (1, 1000.50);> SELECT * FROM bank.accounts;id | balance +----+---------+ 1 | 1000.50 (1 row)Exit the SQL shell on
roach1and open a new shell onroach2:> \qdocker exec -it roach2 ./cockroach --host=roach2:26258 sql --insecureRun the same
SELECTquery as before:> SELECT * FROM bank.accounts;id | balance +----+---------+ 1 | 1000.50 (1 row)As you can see,
roach1androach2perform identically as SQL gateways.Exit the SQL shell on
roach2:> \q
Step 5. Run a sample workload
CockroachDB also comes with a number of built-in workloads for simulating client traffic. Let's run the workload based on CockroachDB's sample vehicle-sharing application, MovR.
The cockroach workload command does not support connection or security flags like other cockroach commands. Instead, you must use a connection string at the end of the command.
Load the initial dataset on
roach1:26257docker exec -it roach1 ./cockroach workload init movr 'postgresql://root@roach1:26257?sslmode=disable'Run the workload for five minutes:
docker exec -it roach1 ./cockroach workload run movr --duration=5m 'postgresql://root@roach1:26257?sslmode=disable'
Step 6. Access the DB Console
The DB Console gives you insight into the overall health of your cluster as well as the performance of the client workload.
When you started the first node's container, you mapped the node's default HTTP port
8080to port8080on the Docker host, so go to http://localhost:8080. If necessary, replacelocalhostwith the hostname or IP address of the Docker host.On the Cluster Overview, notice that three nodes are live, with an identical replica count on each node:
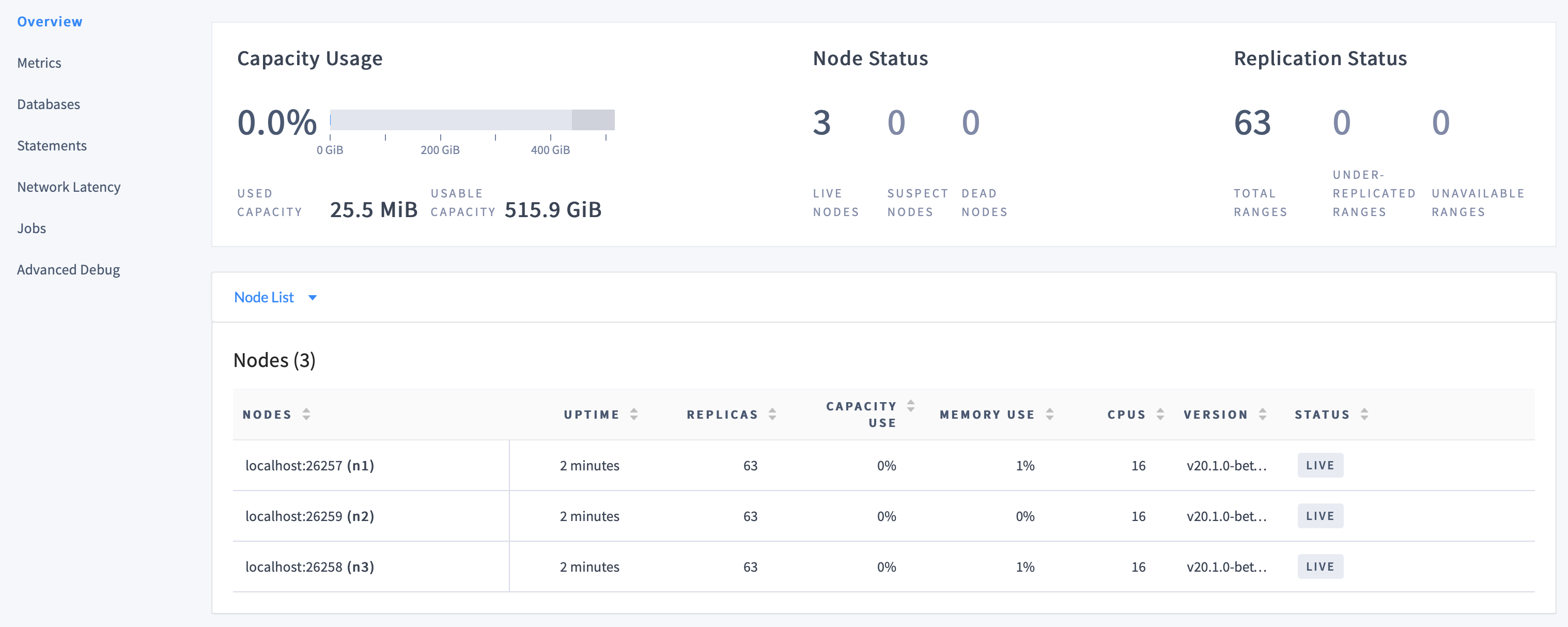
This demonstrates CockroachDB's automated replication of data via the Raft consensus protocol.
Note:Capacity metrics can be incorrect when running multiple nodes on a single machine. For more details, refer to Capacity metrics.
Click Metrics to access a variety of time series dashboards, including graphs of SQL queries and service latency over time:
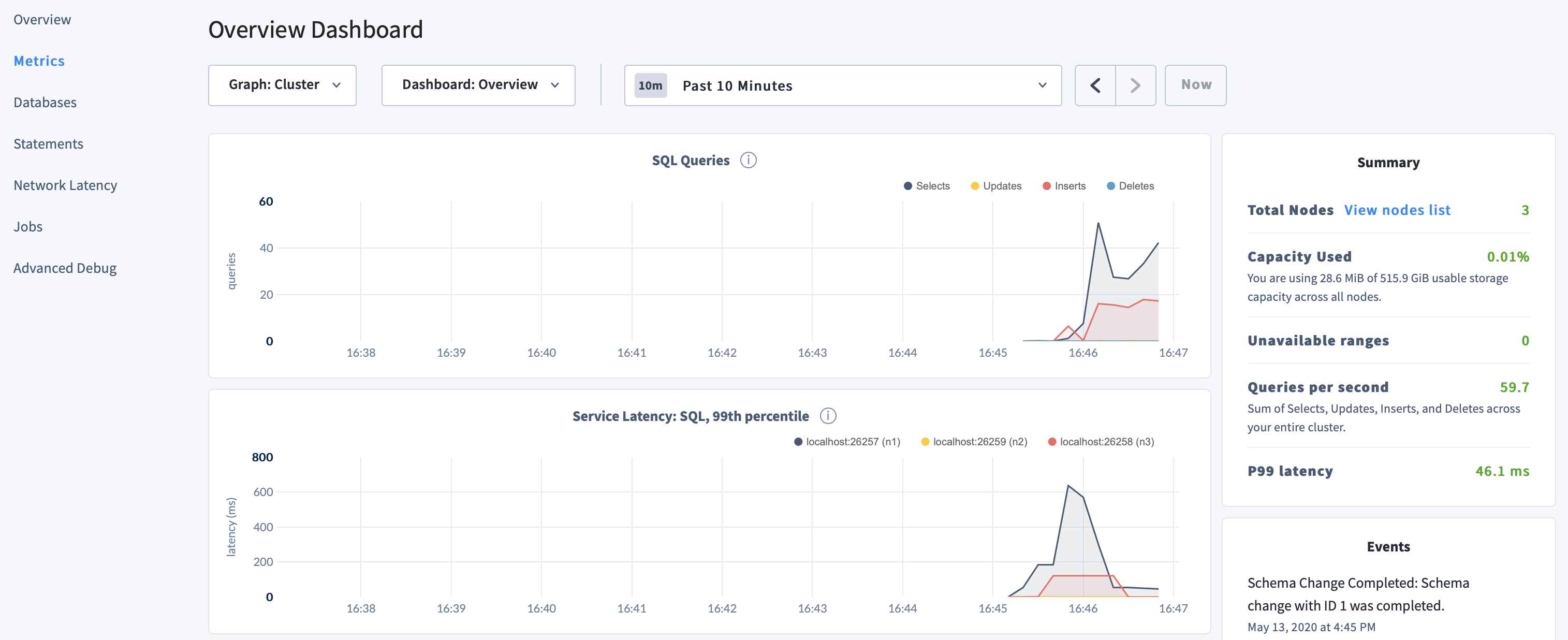
Use the Databases, Statements, and Jobs pages to view details about your databases and tables, to assess the performance of specific queries, and to monitor the status of long-running operations like schema changes, respectively.
Optionally verify that DB Console instances for
roach2androach3are reachable on ports 8081 and 8082 and show the same information as port 8080.
Step 7. Stop the cluster
Use the
docker stopanddocker rmcommands to stop and remove the containers (and therefore the cluster). By default,docker stopsends aSIGTERMsignal, waits for 10 seconds, and then sends aSIGKILLsignal. Cockroach Labs recommends that you allow between 5 and 10 minutes before forcibly stopping thecockroachprocess, so this example sets the grace period to 5 minutes. If you do not plan to restart the cluster, you can omit-t.docker stop -t 300 roach1 roach2 roach3docker rm roach1 roach2 roach3If you do not plan to restart the cluster, you can also remove the Docker volumes and the Docker network:
docker volume rm roach1 roach2 roach3docker network rm roachnet
Start a single-node cluster
When you use the cockroach start-single-node command to start a single-node cluster with Docker, additional features are available to help with testing and development.
Single-node clusters are not highly available or fault-tolerant. They are not appropriate for production use.
You can optionally set the following Docker environment variables to create a database and user automatically and to set a password for the user.
COCKROACH_DATABASECOCKROACH_USERCOCKROACH_PASSWORD
To prevent loss of a cluster's existing data, the environment variables are used only if the
/cockroach/cockroach-datadirectory within the container is empty.You can optionally mount a directory of initialization scripts into the
docker-entrypoint-initdb.ddirectory within the container. These scripts are run after CockroachDB starts and after the database and user (if specified as environment variables) have been created. The scripts run in the alphanumeric sort order imposed by your locale. The init scripts are run only if the/cockroach/cockroach-datadirectory within the container is empty.
During local development and testing, you can re-initialize the default database, user, and password by deleting the contents of /cockroach/cockroach-data within the running container and then restarting the container.
This section shows how to start a single-node cluster that uses these features.
Step 1. Create a Docker volume for the node
Cockroach Labs recommends that you store cluster data in a Docker volume rather than in the storage layer of the running container. Otherwise, if a Docker container is inadvertently deleted, its data is inaccessible.
Avoid using the -v / --volume command to mount a local macOS filesystem into the container. Use Docker volumes or a tmpfs mount.
To create the Docker volume where the cluster will store its data, run the following:
docker volume create roach-single
Step 2. Start the cluster
This section shows how to start a single-node cluster that:
- Stores its data in the
roach-singlevolume on the Docker host, which is mounted on the/cockroach/cockroach-datadirectory within the container. If the
/cockroach/cockroach-datadirectory within the container is empty, creates the specified database, user, and password automatically.Tip:Instead of specifying each value directly by using the
-eor--envflag, you can store them in a file on the Docker host. Use one key-value pair per line and set the--env-fileflag to the file's path.Bind-mounts the
~/init-scriptsdirectory on the Docker host onto the/docker-entrypoint-initdb.ddirectory within the container. Initialization scripts stored in this directory are run after CockroachDB starts and the default database, user, and password are initialized.Accepts database client connections on hostname
roach-singleon port 26257.Accepts connections to the DB Console on hostname
roach-singleon port 8080.
The cockroach process listens on 127.0.0.1:26257 and localhost:26257, and this cannot be changed for single-node cluster running in a container. The --listen-address option is ignored.
Start the cluster node and configure it to listen on port 26257 for SQL clients and run DB Console on port 8080.
docker run -d \ --env COCKROACH_DATABASE={DATABASE_NAME} \ --env COCKROACH_USER={USER_NAME} \ --env COCKROACH_PASSWORD={PASSWORD} \ --name=roach-single \ --hostname=roach-single \ -p 26257:26257 \ -p 8080:8080 \ -v "roach-single:/cockroach/cockroach-data" \ cockroachdb/cockroach:v26.2.2 start-single-node \ --http-addr=roach-single:8080By default, a
certsdirectory is created and CockroachDB starts in secure mode.Note:The
COCKROACH_DATABASE,COCKROACH_USER, andCOCKROACH_PASSWORDenvironment variables and the contents of the/docker-entrypoint-initdb.ddirectory are ignored if you usecockroach startrather thancockroach start-single-node. They are also ignored if data exists in the/cockroach/cockroach-datadirectory within the container.Docker adds a DNS entry that resolves the hostname
roach-singleto the container's IP address in Docker's default network. The following examples use this hostname.After the cluster is initialized, the cluster node prints helpful startup details to its log, including the DB Console URL and the SQL connection string. To retrieve
roach-single's startup details:docker exec -it roach-single grep 'node starting' /cockroach/cockroach-data/logs/cockroach.log -A 11CockroachDB node starting at 2023-11-07 20:26:36.11359443 +0000 UTC m=+1.297365572 (took 1.0s) build: CCL @ 2023/09/27 02:36:23 (go1.19.10) webui: https://127.0.0.1:8080 sql: postgresql://root@127.0.0.1:26257/defaultdb?sslcert=certs%2Fclient.root.crt&sslkey=certs%2Fclient.root.key&sslmode=verify-full&sslrootcert=certs%2Fca.crt sql (JDBC): jdbc:postgresql://127.0.0.1:26257/defaultdb?sslcert=certs%2Fclient.root.crt&sslkey=certs%2Fclient.root.key&sslmode=verify-full&sslrootcert=certs%2Fca.crt&user=root RPC client flags: /cockroach/cockroach <client cmd> --host=127.0.0.1:26257 --certs-dir=certs logs: /cockroach/cockroach-data/logs temp dir: /cockroach/cockroach-data/cockroach-temp2611102055 external I/O path: /cockroach/cockroach-data/extern store[0]: path=/cockroach/cockroach-data storage engine: pebble clusterID: 60f29a4e-1c87-4b0c-805d-eb73460766b1 status: initialized new cluster nodeID: 1
Step 3. Connect to the cluster
After the cluster is initialized, you can connect to it, run tests on it, and stop it using the same instructions as a multi-node cluster. To monitor the cluster node's logs interactively:
docker logs --follow roach-singleTo stop monitoring the logs, press Ctrl+C to exit the
docker logscommand.To connect to the cluster interactively using the
cockroach sqlcommand-line interface, set--urlcluster's SQL connection string, which is printed next tosql:in the cluster's startup details. Connect to theroach-singlecluster:docker exec -it roach-single ./cockroach sql --url="postgresql://root@127.0.0.1:26257/defaultdb?sslcert=certs%2Fclient.root.crt&sslkey=certs%2Fclient.root.key&sslmode=verify-full&sslrootcert=certs%2Fca.crt"
Step 4. Access the DB Console
The DB Console gives you insight into the overall health of your cluster as well as the performance of the client workload.
When you started the cluster container, you published the container's DB Console port 8080 to port 8080 on the Docker host so that DB Console can be accessed from outside the cluster container. To connect to DB Console, go to http://localhost:8080. If necessary, replace localhost with the hostname or IP address of the Docker host.
Step 5. Stop the cluster
Use the
docker stopanddocker rmcommands to stop and remove the container (and therefore the single-node cluster). By default,docker stopsends aSIGTERMsignal, waits for 10 seconds, and then sends aSIGKILLsignal. Cockroach Labs recommends that you allow between 5 and 10 minutes before forcibly stopping thecockroachprocess, so this example sets the grace period to 5 minutes. If you do not plan to restart the cluster, you can omit-t.docker stop -t 300 roach-singledocker rm roach-singleIf you do not plan to restart the cluster, you can also remove the Docker volume that contains the cluster's data:
docker volume rm roach-single
What's next?
- Create a CockroachDB Cloud account where you can generate and manage licenses for CockroachDB installations
- Learn more about CockroachDB SQL and the built-in SQL client
- Install the client driver for your preferred language
- Further explore CockroachDB capabilities like fault tolerance and automated repair, multi-region performance, serializable transactions, and JSON support
