
Replication zones give you the power to control what data goes where in your CockroachDB cluster. Specifically, they are used to control the number and location of replicas for data belonging to the following objects:
- Databases
- Tables
- Rows
- Indexes
- All data in the cluster, including internal system data (via the default replication zone)
For each of these objects you can control:
- How many copies of each range to spread through the cluster.
- Which constraints are applied to which data, e.g., "table X's data can only be stored in the German availability zones".
- The maximum size of ranges (how big ranges get before they are split).
- How long old data is kept before being garbage collected.
- Where you would like the leaseholders for certain ranges to be located, e.g., "for ranges that are already constrained to have at least one replica in
region=us-west, also try to put their leaseholders inregion=us-west".
This page explains how replication zones work and how to use the ALTER ... CONFIGURE ZONE statement to manage them. CONFIGURE ZONE is a subcommand of the ALTER DATABASE, ALTER TABLE, ALTER INDEX, ALTER PARTITION, and ALTER RANGE statements.
For instructions showing how to troubleshoot replication zones that may be misconfigured, see Troubleshoot Replication Zone Configurations.
To configure replication zones, a user must be a member of the admin role or have been granted CREATE or ZONECONFIG privileges. To configure system objects, the user must be a member of the admin role.
Cockroach Labs does not recommend modifying zone configurations manually.
Most users should use multi-region SQL statements instead. If additional control is needed, use Zone Config Extensions to augment the multi-region SQL statements.
Overview
Every range in the cluster is part of a replication zone. Each range's zone configuration is taken into account as ranges are rebalanced across the cluster to ensure that any constraints are honored.
When a cluster starts, there are two categories of replication zone:
- Pre-configured replication zones that apply to internal system data.
- A single default replication zone that applies to the rest of the cluster.
You can adjust these pre-configured zones as well as add zones for individual databases, tables, rows, and indexes as needed.
For example, you might rely on the default zone to spread most of a cluster's data across all of your availability zones, but create a custom replication zone for a specific database to make sure its data is only stored in certain availability zones and/or geographies.
Replication zone levels
There are five replication zone levels for table data in a cluster, listed from least to most granular:
| Level | Description |
|---|---|
| Cluster | CockroachDB comes with a pre-configured default replication zone that applies to all table data in the cluster not constrained by a database, table, or row-specific replication zone. This zone can be adjusted but not removed. See View the Default Replication Zone and Edit the Default Replication Zone for more details. |
| Database | You can add replication zones for specific databases. See Create a Replication Zone for a Database for more details. |
| Table | You can add replication zones for specific tables. See Create a Replication Zone for a Table. |
| Index | The indexes on a table will automatically use the replication zone for the table. However, with an Enterprise license, you can add distinct replication zones for indexes. See Create a Replication Zone for a Secondary Index for more details. |
| Row | You can add replication zones for specific rows in a table or index by defining table partitions. See Create a Replication Zone for a Table Partition for more details. |
For system data
In addition, CockroachDB stores internal system data in what are called system ranges. There are two replication zone levels for this internal system data, listed from least to most granular:
| Level | Description |
|---|---|
| Cluster | The default replication zone mentioned above also applies to all system ranges not constrained by a more specific replication zone. |
| System Range | CockroachDB comes with pre-configured replication zones for important system ranges, such as the "meta" and "liveness" ranges. If necessary, you can add replication zones for the "timeseries" range and other system ranges as well. Editing replication zones for system ranges may override settings from default. See Create a Replication Zone for a System Range for more details.CockroachDB also comes with pre-configured replication zones for the internal system database and the system.jobs table, which stores metadata about long-running jobs such as schema changes and backups. |
Level priorities
When replicating data, whether table or system, CockroachDB always uses the most granular replication zone available. For example, for a piece of user data:
- If there's a replication zone for the row (a.k.a. partition), CockroachDB uses it.
- If there's no applicable row replication zone and the row is from an index, CockroachDB uses the index replication zone.
- If the row isn't from a index or there is no applicable index replication zone, CockroachDB uses the table replication zone.
- If there's no applicable table replication zone, CockroachDB uses the database replication zone.
- If there's no applicable database replication zone, CockroachDB uses the
defaultcluster-wide replication zone.
As this example shows, CockroachDB chooses which replication zone applies to a specific schema object using a hierarchy of inheritance. For most users who never modify their zone configurations, this level of understanding is sufficient.
However, there are nuances in how inheritance works that are not explained by this example. For more details about how zone config inheritance works, see the section How zone config inheritance works.
How zone config inheritance works
As discussed previously, CockroachDB always uses the most granular replication zone available for each schema object (database, table, etc.). More-specific settings applied to schema objects at lower levels of the inheritance tree will always override the settings of objects above them in the tree. All configurations will therefore be modified versions of the default range, which acts as the root of the tree. This means that in practice, any changes to a specific schema object's zone configurations are by definition user-initiated, either via Multi-region SQL abstractions or manual changes.
Because each zone config inherits all of its initial values from its parent object, it only stores the values that differ from its parent. Any fields that are unset will be looked up in the parent object’s zone configuration. This continues recursively up the inheritance hierarchy all the way to the default zone config. In practice, most values are cached for performance.
For more information, see the following subsections:
- The zone config inheritance hierarchy
- Zone config inheritance - example SQL session
- Why manual zone config management is not recommended
The zone config inheritance hierarchy
The hierarchy of inheritance for zone configs can be visualized using the following outline-style diagram, in which each level of indentation denotes an inheritance relationship.
The only exception to this simple inheritance relationship is that due to a known limitation, sub-partitions do not inherit their values from their parent partitions. Instead, sub-partitions inherit their values from the parent table. For more information, see cockroachdb/cockroach#75862.
- default
- database A
- table A.B
- index A.B.1
- partition (row) 1
- sub-partition 1.1 (NB. Sub-partitions inherit from tables, *not* partitions - see cockroachdb/cockroach#75862)
- sub-partition 1.1.1
- sub-partition 1.2
- table A.C
- index A.C.1
- index A.C.2
- ...
The way the zone config inheritance hierarchy works can be thought of from a "bottom-up" or "top-down" perspective; both are useful, but which one is easier to understand may depend on what you are trying to do.
The "bottom-up" view of how zone config inheritance works is useful when you are troubleshooting unexpected replication behavior.
In this view, you start with the most granular schema object whose replication behavior currently interests you. In a troubleshooting session, this is the one you think is the source of the unexpected behavior. You start at the target schema object, looking at the specific state of its configuration to see what is different about it from its parent object (if anything), and work upwards from there.
The "top-down" perspective of how zone config inheritance works can be useful when thinking about how the system works as a whole.
From the whole-system perspective, the hierarchy of schema object zone configs can be thought of as a tree. From this point of view, the system does a depth-first traversal down the tree of schema objects. For each object, it uses the value of the most specific modified field from the current object's zone config, unless or until it finds a modified value of that field on an object deeper in the tree. For each field on the current schema object's zone config where it doesn't find any modified value, it uses the inherited value from the node's parent, which inherits from its parent, and so on all the way back up to the root of the tree (the default range).
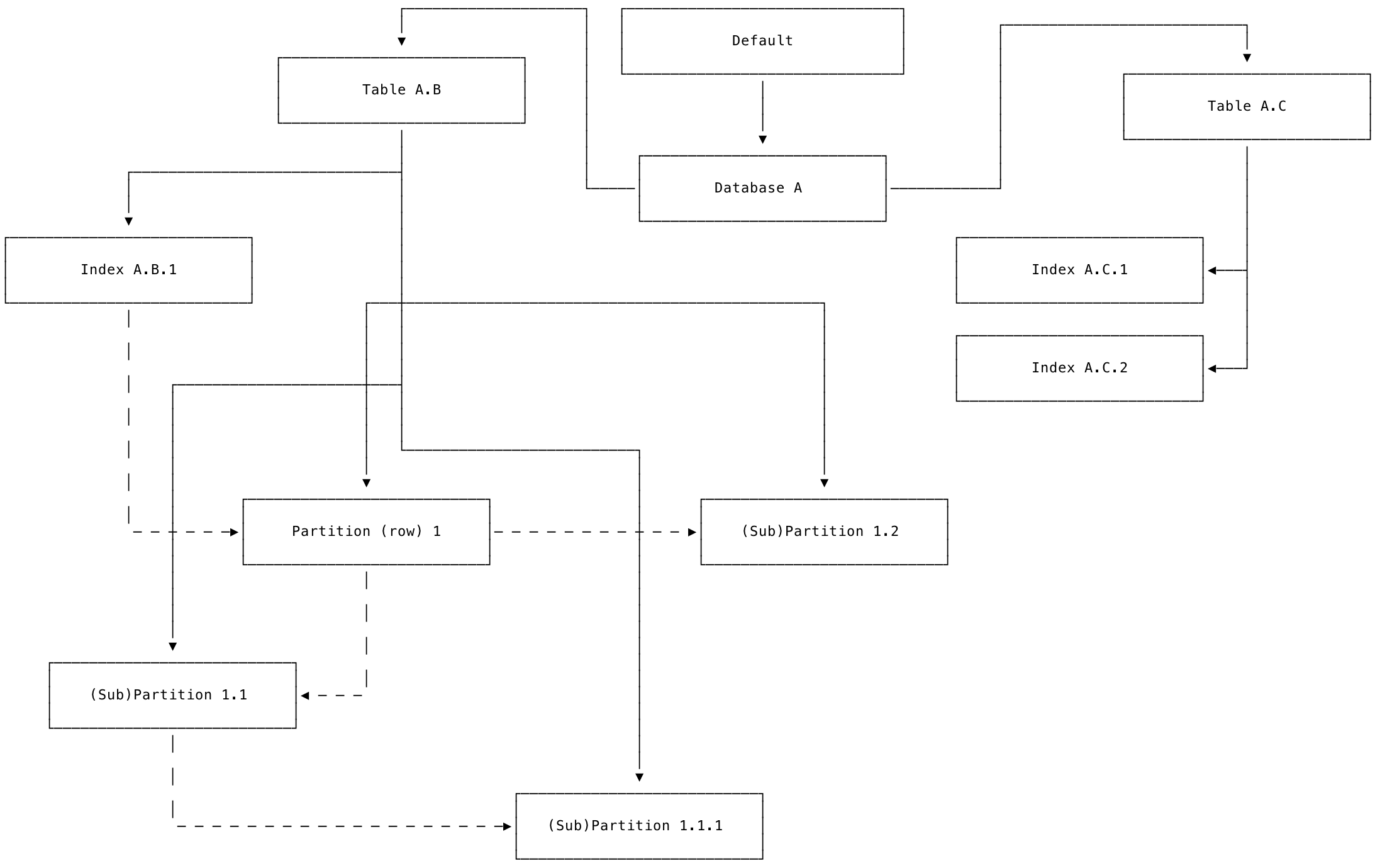
The following diagram presents the same set of schema objects as the previous outline-style diagram, but using boxes and lines joined with arrows that represent the "top-down" view.
Each box represents a schema object in the zone configuration inheritance hierarchy. Each solid line ends in an arrow that points from a parent object to its child object, which will inherit the parent's values unless those values are changed at the child level. The dotted lines between partitions and sub-partitions represent the known limitation mentioned previously that sub-partitions do not inherit their values from their parent partitions. Instead, sub-partitions inherit their values from the parent table. For more information about this limitation, see cockroachdb/cockroach#75862.
Zone config inheritance - example SQL session
You can verify the inheritance behavior described previously in a SQL session.
Start a demo cluster. Create a sample database and table:
CREATE DATABASE IF NOT EXISTS test;
USE test;
CREATE TABLE IF NOT EXISTS kv (k INT, v INT);
Next, manually set a zone configuration field at the database level. In this example, use num_replicas:
ALTER DATABASE test CONFIGURE ZONE USING num_replicas = 1;
Check that the child table test.kv inherits the value of num_replicas from its parent database. You should see output like the following:
SHOW ZONE CONFIGURATION FROM TABLE test.kv;
target | raw_config_sql
----------------+-------------------------------------------
DATABASE test | ALTER DATABASE test CONFIGURE ZONE USING
| range_min_bytes = 134217728,
| range_max_bytes = 536870912,
| gc.ttlseconds = 14400,
| num_replicas = 1,
| constraints = '[]',
| lease_preferences = '[]'
(1 row)
Then, set the num_replicas field on the table to a different value than its parent database:
ALTER TABLE kv CONFIGURE ZONE USING num_replicas = 5;
This overrides the value of num_replicas set by the parent test database. From this point forward, until you discard the changed settings at the table level, the table will no longer inherit those changed values from its parent database.
In other words, the value of this field on the table's zone config has diverged from its parent database, and all state on this field must be managed manually going forward. This divergence in state between parent and child objects, and the necessity to manage it manually once it diverges, is the reason why manual zone config management is not recommended.
Next, check the zone config for the table test.kv, and verify that its value of num_replicas has diverged:
SHOW ZONE CONFIGURATION FROM TABLE kv;
target | raw_config_sql
-----------+--------------------------------------
TABLE kv | ALTER TABLE kv CONFIGURE ZONE USING
| range_min_bytes = 134217728,
| range_max_bytes = 536870912,
| gc.ttlseconds = 14400,
| num_replicas = 5,
| constraints = '[]',
| lease_preferences = '[]'
(1 row)
Next, change the value of num_replicas for the test database again. Once again, choose a different value than its child table test.kv (which has num_replicas = 5).
ALTER DATABASE test CONFIGURE ZONE USING num_replicas = 7;
The reason for doing this is to confirm the previous claim that "the value of this field on the table's zone config has diverged from its parent database, and all state on this field must be managed manually going forward".
The following SHOW ZONE CONFIGURATION statement confirms that the value of the num_replicas field on the kv table is no longer inherited from its parent database test.
SHOW ZONE CONFIGURATION FROM TABLE kv;
target | raw_config_sql
-----------+--------------------------------------
TABLE kv | ALTER TABLE kv CONFIGURE ZONE USING
| range_min_bytes = 134217728,
| range_max_bytes = 536870912,
| gc.ttlseconds = 14400,
| num_replicas = 5,
| constraints = '[]',
| lease_preferences = '[]'
(1 row)
Note that even if you manually change the value of num_replicas in kv to match the value of its parent test, further changes to test will still not be propagated downward to test.kv. Confirm this by running the following statements:
ALTER TABLE test.kv CONFIGURE ZONE USING num_replicas = 7;
ALTER DATABASE test CONFIGURE ZONE USING num_replicas = 9;
SHOW ZONE CONFIGURATION FROM TABLE kv;
target | raw_config_sql
-----------+--------------------------------------
TABLE kv | ALTER TABLE kv CONFIGURE ZONE USING
| range_min_bytes = 134217728,
| range_max_bytes = 536870912,
| gc.ttlseconds = 14400,
| num_replicas = 7,
| constraints = '[]',
| lease_preferences = '[]'
(1 row)
One way to think about this from a programming perspective is that a "dirty bit" has been set on the num_replicas field in the kv table's zone config.
However, you can confirm that other fields on test.kv which have not been modified from their default values still inherit from the parent database test as expected by changing the value of gc.ttlseconds on the test database.
Change the value of gc.ttlseconds on the test database:
ALTER DATABASE test CONFIGURE ZONE USING gc.ttlseconds = 600;
Next, confirm that the value of gc.ttlseconds from the test database is inherited by the test.kv table as expected:
SHOW ZONE CONFIGURATION FROM TABLE test.kv;
target | raw_config_sql
-----------------------+--------------------------------------------------
TABLE test.public.kv | ALTER TABLE test.public.kv CONFIGURE ZONE USING
| range_min_bytes = 134217728,
| range_max_bytes = 536870912,
| gc.ttlseconds = 600,
| num_replicas = 7,
| constraints = '[]',
| lease_preferences = '[]'
(1 row)
To return the test.kv table to a state where it goes back to inheriting all of its values from its parent database test, use the ALTER TABLE ... CONFIGURE ZONE DISCARD statement:
ALTER TABLE test.kv CONFIGURE ZONE DISCARD;
As you can see from this example, these kinds of manual "tweaks" to zone configurations can leave the cluster in a state where its operators are managing its replication in a very manual and error-prone fashion. This example shows why, for most users, manual zone config management is not recommended. Instead, most users should use Multi-region SQL.
Why manual zone config management is not recommended
Reasons to avoid modifying zone configurations manually using CONFIGURE ZONE include:
- It is difficult to do proper auditing and change management of manually altered zone configurations.
- It is easy to introduce logic errors (a.k.a., bugs) and end up in a state where your replication is not behaving as it is "supposed to".
- Manual zone config modifications must be entirely maintained by the user with no help from the system. Such manual changes must be fully overwritten on each configuration change in order to take effect; this introduces another avenue for error.
Given the previous description of how zone config inheritance works, if you manually modify zone configs using CONFIGURE ZONE, you will see the following behavior:
- If you set some field F at the database level, the updated value of that field will propagate down the inheritance tree to all of the database's child tables.
- However, if you then edit that same field F on a child table, the table will no longer inherit its value of F from its parent database. Instead, the field F across these two schema objects is now in a diverged state. This means that any changes to the value of F at the database level no longer propagate downward to the child table, which has its own value of F.
- In other words, once you touch any schema object O to manually edit some field F, a "dirty bit" is set on O.F, and CockroachDB will no longer modify O.F without user intervention. Instead, you are now responsible for managing the state of O.F via direct calls to
ALTER DATABASE ... CONFIGURE ZONEanytime something needs to change in your configuration.
Avoiding this error-prone manual state management was the motivation behind the development of the abstractions provided by Multi-region SQL statements and Multi-region Zone Config Extensions.
Manage replication zones
Use the ALTER ... CONFIGURE ZONE statement to add, modify, reset, and remove replication zones.
Replication zone variables
Use the ALTER ... CONFIGURE ZONE statement to set a replication zone:
> ALTER TABLE t CONFIGURE ZONE USING range_min_bytes = 0, range_max_bytes = 90000, gc.ttlseconds = 89999, num_replicas = 5, constraints = '[-region=west]';
| Variable | Description |
|---|---|
range_min_bytes |
The minimum size, in bytes, for a range of data in the zone. When a range is less than this size, CockroachDB will merge it with an adjacent range. Default: 134217728 (128 MiB) |
range_max_bytes |
The maximum size, in bytes, for a range of data in the zone. When a range reaches this size, CockroachDB will split it into two ranges. Default: 536870912 (512 MiB) |
gc.ttlseconds |
The number of seconds overwritten MVCC values will be retained before garbage collection. Default: 14400 (4 hours) Smaller values can save disk space and improve performance if values are frequently overwritten or for queue-like workloads. The smallest value we regularly test is 600 (10 minutes); smaller values are unlikely to be beneficial because of the frequency with which GC runs. If you use non-scheduled incremental backups, the GC TTL must be greater than the interval between incremental backups. Otherwise, your incremental backups will fail with the error message protected ts verification error. To avoid this problem, we recommend using scheduled backups instead, which automatically use protected timestamps to ensure they succeed. Larger values increase the interval allowed for AS OF SYSTEM TIME queries and allow for less frequent incremental backups. The largest value we regularly test is 90000 (25 hours). Increasing the GC TTL is not meant to be a solution for long-term retention of history; for that you should handle versioning in the schema design at the application layer. Setting the GC TTL too high can cause problems if the retained versions of a single row approach the maximum range size. This is important because all versions of a row are stored in a single range that never splits. |
num_replicas |
The number of replicas in the zone, also called the "replication factor". Default: 3For the system database and .meta, .liveness, and .system ranges, the default value is 5.For multi-region databases configured to survive region failures, the default value is 5; this will include both voting and non-voting replicas. |
constraints |
An array of required (+) and/or prohibited (-) constraints influencing the location of replicas. See Types of Constraints and Scope of Constraints for more details.To prevent hard-to-detect typos, constraints placed on store attributes and node localities must match the values passed to at least one node in the cluster. If not, an error is signalled. To prevent this error, make sure at least one active node is configured to match the constraint. For example, apply constraints = '[+region=west]' only if you had set --locality=region=west for at least one node while starting the cluster.Default: No constraints, with CockroachDB locating each replica on a unique node and attempting to spread replicas evenly across localities. |
lease_preferences |
An ordered list of required and/or prohibited constraints influencing the location of leaseholders. Whether each constraint is required or prohibited is expressed with a leading + or -, respectively. Note that lease preference constraints do not have to be shared with the constraints field. For example, it's valid for your configuration to define a lease_preferences field that does not reference any values from the constraints field. It's also valid to define a lease_preferences field with no constraints field at all. If the first preference cannot be satisfied, CockroachDB will attempt to satisfy the second preference, and so on. If none of the preferences can be met, the lease will be placed using the default lease placement algorithm, which is to base lease placement decisions on how many leases each node already has, trying to make all the nodes have around the same amount. Each value in the list can include multiple constraints. For example, the list [[+zone=us-east-1b, +ssd], [+zone=us-east-1a], [+zone=us-east-1c, +ssd]] means "prefer nodes with an SSD in us-east-1b, then any nodes in us-east-1a, then nodes in us-east-1c with an SSD."For a usage example, see Constrain leaseholders to specific availability zones. Default: No lease location preferences are applied if this field is not specified. |
global_reads |
If true, transactions operating on the range(s) affected by this zone config should be non-blocking, which slows down writes but allows reads from any replica in the range. Most users will not need to modify this setting; it is applied automatically when you use the GLOBAL table locality in a multi-region cluster. |
num_voters |
Specifies the number of voting replicas. When set, num_replicas will be the sum of voting and non-voting replicas. Most users will not need to modify this setting; it is part of the underlying machinery that enables improved multi-region capabilities in v21.1 and above. |
voter_constraints |
Specifies the constraints that govern the placement of voting replicas. This differs from the constraints field, which will govern the placement of all voting and non-voting replicas. Most users will not need to modify this setting; it is part of the underlying machinery that enables improved multi-region capabilities in v21.1 and above. |
If a value is not set, new zone configurations will inherit their values from their parent zone (e.g., a partition zone inherits from the table zone), which is not necessarily default.
If a variable is set to COPY FROM PARENT (e.g., range_max_bytes = COPY FROM PARENT), the variable will copy its value from its parent replication zone. The COPY FROM PARENT value is a convenient shortcut to use so you do not have to look up the parent's current value. For example, the range_max_bytes and range_min_bytes variables must be set together, so when editing one value, you can use COPY FROM PARENT for the other. Note that if the variable in the parent replication zone is changed after the child replication zone is copied, the change will not be reflected in the child zone.
Replication constraints
The location of replicas, both when they are first added and when they are rebalanced to maintain cluster equilibrium, is based on the interplay between descriptive attributes assigned to nodes and constraints set in zone configurations.
Descriptive attributes assigned to nodes
When starting a node with the cockroach start command, you can assign the following types of descriptive attributes:
| Attribute Type | Description |
|---|---|
| Node Locality | Using the --locality flag, you can assign arbitrary key-value pairs that describe the location of the node. Locality might include region, country, availability zone, etc. The key-value pairs should be ordered into locality tiers that range from most inclusive to least inclusive (e.g., region before availability zone as in region=eu,az=paris), and the keys and the order of key-value pairs must be the same on all nodes. It is typically better to include more pairs than fewer. For example:--locality=region=east,az=us-east-1--locality=region=east,az=us-east-2--locality=region=west,az=us-west-1CockroachDB attempts to spread replicas evenly across the cluster based on locality, with the order of locality tiers determining the priority. Locality can also be used to influence the location of data replicas in various ways using replication zones. When there is high latency between nodes, CockroachDB uses locality to move range leases closer to the current workload, reducing network round trips and improving read performance. See Follow-the-workload for more details. Note: Repeating an exact locality value has no effect, but locality values are case-sensitive. For example, from the point of view of CockroachDB, the following values result in two separate localities: --locality datacenter=us-east-1 --locality datacenter=datacenter=US-EAST-1This type of configuration error can lead to issues that are difficult to diagnose. |
| Node Capability | Using the --attrs flag, you can specify node capability, which might include specialized hardware or number of cores, for example:--attrs=ram:64gb |
| Store Type/Capability | Using the attrs field of the --store flag, you can specify disk type or capability, for example:--store=path=/mnt/ssd01,attrs=ssd--store=path=/mnt/hda1,attrs=hdd:7200rpm |
Types of constraints
The node-level and store-level descriptive attributes mentioned above can be used as the following types of constraints in replication zones to influence the location of replicas. However, note the following general guidance:
- When locality is the only consideration for replication, it's recommended to set locality on nodes without specifying any constraints in zone configurations. In the absence of constraints, CockroachDB attempts to spread replicas evenly across the cluster based on locality.
- Required and prohibited constraints are useful in special situations where, for example, data must or must not be stored in a specific country or on a specific type of machine.
- Avoid conflicting constraints. CockroachDB returns an error if you:
- Redefine a required constraint key within the same
constraintsdefinition on all replicas. For example,constraints = '[+region=west, +region=east]'will result in an error. - Define a required and prohibited definition for the same key-value pair. For example,
constraints = '[-region=west, +region=west]'will result in an error.
- Redefine a required constraint key within the same
| Constraint Type | Description | Syntax |
|---|---|---|
| Required | When placing replicas, the cluster will consider only nodes/stores with matching attributes or localities. When there are no matching nodes/stores, new replicas will not be added. | +ssd |
| Prohibited | When placing replicas, the cluster will ignore nodes/stores with matching attributes or localities. When there are no alternate nodes/stores, new replicas will not be added. | -ssd |
Scope of constraints
Constraints can be specified such that they apply to all replicas in a zone or such that different constraints apply to different replicas, meaning you can effectively pick the exact location of each replica.
| Constraint Scope | Description | Syntax |
|---|---|---|
| All Replicas | Constraints specified using JSON array syntax apply to all replicas in every range that's part of the replication zone. | constraints = '[+ssd, -region=west]' |
| Per-Replica | Multiple lists of constraints can be provided in a JSON object, mapping each list of constraints to an integer number of replicas in each range that the constraints should apply to. The total number of replicas constrained cannot be greater than the total number of replicas for the zone ( num_replicas). However, if the total number of replicas constrained is less than the total number of replicas for the zone, the non-constrained replicas will be allowed on any nodes/stores.Note that per-replica constraints must be "required" (e.g., '{"+region=west": 1}'); they cannot be "prohibited" (e.g., '{"-region=west": 1}'). Also, when defining per-replica constraints on a database or table, num_replicas must be specified as well, but not when defining per-replica constraints on an index or partition.See the Per-replica constraints example for more details. |
constraints = '{"+ssd,+region=west": 2, "+region=east": 1}', num_replicas = 3 |
Node/replica recommendations
See Cluster Topology recommendations for production deployments.
Troubleshooting zone constraint violations
For instructions showing how to troubleshoot replication zones that may be misconfigured, see Troubleshoot Replication Zone Configurations.
View replication zones
Use the SHOW ZONE CONFIGURATIONS statement to view details about existing replication zones.
You can also use the SHOW PARTITIONS statement to view the zone constraints on existing table partitions, or SHOW CREATE TABLE to view zone configurations for a table.
In testing, scripting, and other programmatic environments, we recommend querying the crdb_internal.partitions internal table for partition information instead of using the SHOW PARTITIONS statement. For more information, see Querying partitions programmatically.
Basic examples
Setup
The following examples use MovR, a fictional vehicle-sharing application, to demonstrate CockroachDB SQL statements. For more information about the MovR example application and dataset, see MovR: A Global Vehicle-sharing App.
To follow along, run cockroach demo with the --geo-partitioned-replicas flag. This command opens an interactive SQL shell to a temporary, 9-node in-memory cluster with the movr database.
$ cockroach demo --geo-partitioned-replicas
These examples focus on the basic approach and syntax for working with zone configuration. For examples demonstrating how to use constraints, see Scenario-based examples.
For more examples, see SHOW ZONE CONFIGURATIONS.
View all replication zones
> SHOW ALL ZONE CONFIGURATIONS;
target | raw_config_sql
-------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------
RANGE default | ALTER RANGE default CONFIGURE ZONE USING
| range_min_bytes = 134217728,
| range_max_bytes = 536870912,
| gc.ttlseconds = 90000,
| num_replicas = 3,
| constraints = '[]',
| lease_preferences = '[]'
DATABASE system | ALTER DATABASE system CONFIGURE ZONE USING
| range_min_bytes = 134217728,
| range_max_bytes = 536870912,
| gc.ttlseconds = 90000,
| num_replicas = 5,
| constraints = '[]',
| lease_preferences = '[]'
RANGE meta | ALTER RANGE meta CONFIGURE ZONE USING
| range_min_bytes = 134217728,
| range_max_bytes = 536870912,
| gc.ttlseconds = 3600,
| num_replicas = 5,
| constraints = '[]',
| lease_preferences = '[]'
RANGE system | ALTER RANGE system CONFIGURE ZONE USING
| range_min_bytes = 134217728,
| range_max_bytes = 536870912,
| gc.ttlseconds = 90000,
| num_replicas = 5,
| constraints = '[]',
| lease_preferences = '[]'
RANGE liveness | ALTER RANGE liveness CONFIGURE ZONE USING
| range_min_bytes = 134217728,
| range_max_bytes = 536870912,
| gc.ttlseconds = 600,
| num_replicas = 5,
| constraints = '[]',
| lease_preferences = '[]'
TABLE system.public.replication_constraint_stats | ALTER TABLE system.public.replication_constraint_stats CONFIGURE ZONE USING
| gc.ttlseconds = 600,
| constraints = '[]',
| lease_preferences = '[]'
TABLE system.public.replication_stats | ALTER TABLE system.public.replication_stats CONFIGURE ZONE USING
| gc.ttlseconds = 600,
| constraints = '[]',
| lease_preferences = '[]'
PARTITION us_west OF INDEX movr.public.users@primary | ALTER PARTITION us_west OF INDEX movr.public.users@primary CONFIGURE ZONE USING
| constraints = '[+region=us-west1]'
PARTITION us_east OF INDEX movr.public.users@primary | ALTER PARTITION us_east OF INDEX movr.public.users@primary CONFIGURE ZONE USING
| constraints = '[+region=us-east1]'
PARTITION europe_west OF INDEX movr.public.users@primary | ALTER PARTITION europe_west OF INDEX movr.public.users@primary CONFIGURE ZONE USING
| constraints = '[+region=europe-west1]'
PARTITION us_west OF INDEX movr.public.vehicles@primary | ALTER PARTITION us_west OF INDEX movr.public.vehicles@primary CONFIGURE ZONE USING
| constraints = '[+region=us-west1]'
PARTITION us_west OF INDEX movr.public.vehicles@vehicles_auto_index_fk_city_ref_users | ALTER PARTITION us_west OF INDEX movr.public.vehicles@vehicles_auto_index_fk_city_ref_users CONFIGURE ZONE USING
| constraints = '[+region=us-west1]'
PARTITION us_east OF INDEX movr.public.vehicles@primary | ALTER PARTITION us_east OF INDEX movr.public.vehicles@primary CONFIGURE ZONE USING
| constraints = '[+region=us-east1]'
PARTITION us_east OF INDEX movr.public.vehicles@vehicles_auto_index_fk_city_ref_users | ALTER PARTITION us_east OF INDEX movr.public.vehicles@vehicles_auto_index_fk_city_ref_users CONFIGURE ZONE USING
| constraints = '[+region=us-east1]'
PARTITION europe_west OF INDEX movr.public.vehicles@primary | ALTER PARTITION europe_west OF INDEX movr.public.vehicles@primary CONFIGURE ZONE USING
| constraints = '[+region=europe-west1]'
PARTITION europe_west OF INDEX movr.public.vehicles@vehicles_auto_index_fk_city_ref_users | ALTER PARTITION europe_west OF INDEX movr.public.vehicles@vehicles_auto_index_fk_city_ref_users CONFIGURE ZONE USING
| constraints = '[+region=europe-west1]'
PARTITION us_west OF INDEX movr.public.rides@primary | ALTER PARTITION us_west OF INDEX movr.public.rides@primary CONFIGURE ZONE USING
| constraints = '[+region=us-west1]'
PARTITION us_west OF INDEX movr.public.rides@rides_auto_index_fk_city_ref_users | ALTER PARTITION us_west OF INDEX movr.public.rides@rides_auto_index_fk_city_ref_users CONFIGURE ZONE USING
| constraints = '[+region=us-west1]'
PARTITION us_west OF INDEX movr.public.rides@rides_auto_index_fk_vehicle_city_ref_vehicles | ALTER PARTITION us_west OF INDEX movr.public.rides@rides_auto_index_fk_vehicle_city_ref_vehicles CONFIGURE ZONE USING
| constraints = '[+region=us-west1]'
PARTITION us_east OF INDEX movr.public.rides@primary | ALTER PARTITION us_east OF INDEX movr.public.rides@primary CONFIGURE ZONE USING
| constraints = '[+region=us-east1]'
PARTITION us_east OF INDEX movr.public.rides@rides_auto_index_fk_city_ref_users | ALTER PARTITION us_east OF INDEX movr.public.rides@rides_auto_index_fk_city_ref_users CONFIGURE ZONE USING
| constraints = '[+region=us-east1]'
PARTITION us_east OF INDEX movr.public.rides@rides_auto_index_fk_vehicle_city_ref_vehicles | ALTER PARTITION us_east OF INDEX movr.public.rides@rides_auto_index_fk_vehicle_city_ref_vehicles CONFIGURE ZONE USING
| constraints = '[+region=us-east1]'
PARTITION europe_west OF INDEX movr.public.rides@primary | ALTER PARTITION europe_west OF INDEX movr.public.rides@primary CONFIGURE ZONE USING
| constraints = '[+region=europe-west1]'
PARTITION europe_west OF INDEX movr.public.rides@rides_auto_index_fk_city_ref_users | ALTER PARTITION europe_west OF INDEX movr.public.rides@rides_auto_index_fk_city_ref_users CONFIGURE ZONE USING
| constraints = '[+region=europe-west1]'
PARTITION europe_west OF INDEX movr.public.rides@rides_auto_index_fk_vehicle_city_ref_vehicles | ALTER PARTITION europe_west OF INDEX movr.public.rides@rides_auto_index_fk_vehicle_city_ref_vehicles CONFIGURE ZONE USING
| constraints = '[+region=europe-west1]'
PARTITION us_west OF INDEX movr.public.vehicle_location_histories@primary | ALTER PARTITION us_west OF INDEX movr.public.vehicle_location_histories@primary CONFIGURE ZONE USING
| constraints = '[+region=us-west1]'
PARTITION us_east OF INDEX movr.public.vehicle_location_histories@primary | ALTER PARTITION us_east OF INDEX movr.public.vehicle_location_histories@primary CONFIGURE ZONE USING
| constraints = '[+region=us-east1]'
PARTITION europe_west OF INDEX movr.public.vehicle_location_histories@primary | ALTER PARTITION europe_west OF INDEX movr.public.vehicle_location_histories@primary CONFIGURE ZONE USING
| constraints = '[+region=europe-west1]'
TABLE movr.public.promo_codes | ALTER TABLE movr.public.promo_codes CONFIGURE ZONE USING
| num_replicas = 3,
| constraints = '{+region=us-east1: 1}',
| lease_preferences = '[[+region=us-east1]]'
INDEX movr.public.promo_codes@promo_codes_idx_us_west | ALTER INDEX movr.public.promo_codes@promo_codes_idx_us_west CONFIGURE ZONE USING
| num_replicas = 3,
| constraints = '{+region=us-west1: 1}',
| lease_preferences = '[[+region=us-west1]]'
INDEX movr.public.promo_codes@promo_codes_idx_europe_west | ALTER INDEX movr.public.promo_codes@promo_codes_idx_europe_west CONFIGURE ZONE USING
| num_replicas = 3,
| constraints = '{+region=europe-west1: 1}',
| lease_preferences = '[[+region=europe-west1]]'
PARTITION us_west OF INDEX movr.public.user_promo_codes@primary | ALTER PARTITION us_west OF INDEX movr.public.user_promo_codes@primary CONFIGURE ZONE USING
| constraints = '[+region=us-west1]'
PARTITION us_east OF INDEX movr.public.user_promo_codes@primary | ALTER PARTITION us_east OF INDEX movr.public.user_promo_codes@primary CONFIGURE ZONE USING
| constraints = '[+region=us-east1]'
PARTITION europe_west OF INDEX movr.public.user_promo_codes@primary | ALTER PARTITION europe_west OF INDEX movr.public.user_promo_codes@primary CONFIGURE ZONE USING
| constraints = '[+region=europe-west1]'
(34 rows)
For more information, see SHOW ZONE CONFIGURATIONS.
View the default replication zone
> SHOW ZONE CONFIGURATION FROM RANGE default;
target | raw_config_sql
----------------+-------------------------------------------
RANGE default | ALTER RANGE default CONFIGURE ZONE USING
| range_min_bytes = 134217728,
| range_max_bytes = 536870912,
| gc.ttlseconds = 90000,
| num_replicas = 3,
| constraints = '[]',
| lease_preferences = '[]'
(1 row)
For more information, see SHOW ZONE CONFIGURATIONS.
Edit the default replication zone
To edit the default replication zone, use the ALTER RANGE ... CONFIGURE ZONE statement to define the values you want to change (other values will remain the same):
> ALTER RANGE default CONFIGURE ZONE USING num_replicas = 5, gc.ttlseconds = 100000;
CONFIGURE ZONE 1
> SHOW ZONE CONFIGURATION FROM RANGE default;
target | raw_config_sql
+---------------+------------------------------------------+
RANGE default | ALTER RANGE default CONFIGURE ZONE USING
| range_min_bytes = 134217728,
| range_max_bytes = 536870912,
| gc.ttlseconds = 100000,
| num_replicas = 5,
| constraints = '[]',
| lease_preferences = '[]'
(1 row)
Create a replication zone for a system range
In addition to the databases and tables that are visible via the SQL interface, CockroachDB stores internal data in what are called system ranges. CockroachDB comes with pre-configured replication zones for some of these ranges:
| Target Name | Description |
|---|---|
meta |
The "meta" ranges contain the authoritative information about the location of all data in the cluster. These ranges must retain a majority of replicas for the cluster as a whole to remain available and historical queries are never run on them, so CockroachDB comes with a pre-configured meta replication zone with num_replicas set to 5 to make these ranges more resilient to node failure and a lower-than-default gc.ttlseconds to keep these ranges smaller for reliable performance.If your cluster is running in multiple datacenters, it's a best practice to configure the meta ranges to have a copy in each datacenter. |
liveness |
The "liveness" range contains the authoritative information about which nodes are live at any given time. These ranges must retain a majority of replicas for the cluster as a whole to remain available and historical queries are never run on them, so CockroachDB comes with a pre-configured liveness replication zone with num_replicas set to 5 to make these ranges more resilient to node failure and a lower-than-default gc.ttlseconds to keep these ranges smaller for reliable performance. |
system |
There are system ranges for a variety of other important internal data, including information needed to allocate new table IDs and track the status of a cluster's nodes. These ranges must retain a majority of replicas for the cluster as a whole to remain available, so CockroachDB comes with a pre-configured system replication zone with num_replicas set to 5 to make these ranges more resilient to node failure. |
timeseries |
The "timeseries" ranges contain monitoring data about the cluster that powers the graphs in CockroachDB's DB Console. If necessary, you can add a timeseries replication zone to control the replication of this data. |
Use caution when editing replication zones for system ranges, as they could cause some (or all) parts of your cluster to stop working.
To control replication for one of the above sets of system ranges, use the ALTER RANGE ... CONFIGURE ZONE statement to define the relevant values (other values will be inherited from the parent zone):
> ALTER RANGE meta CONFIGURE ZONE USING num_replicas = 7;
CONFIGURE ZONE 1
> SHOW ZONE CONFIGURATION FROM RANGE meta;
target | raw_config_sql
+------------+---------------------------------------+
RANGE meta | ALTER RANGE meta CONFIGURE ZONE USING
| range_min_bytes = 134217728,
| range_max_bytes = 536870912,
| gc.ttlseconds = 3600,
| num_replicas = 7,
| constraints = '[]',
| lease_preferences = '[]'
(1 row)
For more information, see ALTER RANGE ... CONFIGURE ZONE.
Create a replication zone for a database
To control replication for a specific database, use the ALTER DATABASE ... CONFIGURE ZONE statement to define the relevant values (other values will be inherited from the parent zone):
> ALTER DATABASE movr CONFIGURE ZONE USING num_replicas = 5, gc.ttlseconds = 100000;
CONFIGURE ZONE 1
> SHOW ZONE CONFIGURATION FROM DATABASE movr;
target | raw_config_sql
----------------+-------------------------------------------
DATABASE movr | ALTER DATABASE movr CONFIGURE ZONE USING
| range_min_bytes = 134217728,
| range_max_bytes = 536870912,
| gc.ttlseconds = 100000,
| num_replicas = 5,
| constraints = '[]',
| lease_preferences = '[]'
(1 row)
For more information, see ALTER DATABASE ... CONFIGURE ZONE.
Create a replication zone for a table
To control replication for a specific table, use the ALTER TABLE ... CONFIGURE ZONE statement to define the relevant values (other values will be inherited from the parent zone):
> ALTER TABLE users CONFIGURE ZONE USING num_replicas = 5, gc.ttlseconds = 100000;
CONFIGURE ZONE 1
> SHOW ZONE CONFIGURATION FROM TABLE users;
target | raw_config_sql
--------------+-----------------------------------------
TABLE users | ALTER TABLE users CONFIGURE ZONE USING
| range_min_bytes = 134217728,
| range_max_bytes = 536870912,
| gc.ttlseconds = 100000,
| num_replicas = 5,
| constraints = '[]',
| lease_preferences = '[]'
(1 row)
For more information, see ALTER TABLE ... CONFIGURE ZONE.
Create a replication zone for a secondary index
The Cost-based Optimizer can take advantage of replication zones for secondary indexes when optimizing queries.
The secondary indexes on a table will automatically use the replication zone for the table. You can also add distinct replication zones for secondary indexes.
To control replication for a specific secondary index, use the ALTER INDEX ... CONFIGURE ZONE statement to define the relevant values (other values will be inherited from the parent zone).
To get the name of a secondary index, which you need for the CONFIGURE ZONE statement, use the SHOW INDEX or SHOW CREATE TABLE statements.
> ALTER INDEX vehicles@vehicles_auto_index_fk_city_ref_users CONFIGURE ZONE USING num_replicas = 5, gc.ttlseconds = 100000;
CONFIGURE ZONE 1
> SHOW ZONE CONFIGURATION FROM INDEX vehicles@vehicles_auto_index_fk_city_ref_users;
target | raw_config_sql
+------------------------------------------------------+---------------------------------------------------------------------------------+
INDEX vehicles@vehicles_auto_index_fk_city_ref_users | ALTER INDEX vehicles@vehicles_auto_index_fk_city_ref_users CONFIGURE ZONE USING
| range_min_bytes = 134217728,
| range_max_bytes = 536870912,
| gc.ttlseconds = 100000,
| num_replicas = 5,
| constraints = '[]',
| lease_preferences = '[]'
(1 row)
For more information, see ALTER INDEX ... CONFIGURE ZONE.
Create a replication zone for a partition
Once partitions have been defined for a table or a secondary index, to control replication for a partition, use ALTER PARTITION <partition> OF INDEX <table@index> CONFIGURE ZONE:
> ALTER PARTITION us_west OF INDEX vehicles@primary
CONFIGURE ZONE USING
num_replicas = 5,
constraints = '[+region=us-west1]';
CONFIGURE ZONE 1
> ALTER PARTITION us_west OF INDEX vehicles@vehicles_auto_index_fk_city_ref_users
CONFIGURE ZONE USING
num_replicas = 5,
constraints = '[+region=us-west1]';
CONFIGURE ZONE 1
To define replication zones for identically named partitions of a table and its secondary indexes, you can use the <table>@* syntax to save several steps:
> ALTER PARTITION us_west OF INDEX vehicles@*
CONFIGURE ZONE USING
num_replicas = 5,
constraints = '[+region=us-west1]';
To view the zone configuration for a partition, use SHOW ZONE CONFIGURATION FROM PARTITION <partition> OF INDEX <table@index>:
> SHOW ZONE CONFIGURATION FROM PARTITION us_west OF INDEX vehicles@primary;
target | raw_config_sql
----------------------------------------------+-------------------------------------------------------------------------
PARTITION us_west OF INDEX vehicles@primary | ALTER PARTITION us_west OF INDEX vehicles@primary CONFIGURE ZONE USING
| range_min_bytes = 134217728,
| range_max_bytes = 536870912,
| gc.ttlseconds = 90000,
| num_replicas = 5,
| constraints = '[+region=us-west1]',
| lease_preferences = '[]'
(1 row)
You can also use the SHOW CREATE TABLE statement or SHOW PARTITIONS statements to view details about all of the replication zones defined for the partitions of a table and its secondary indexes.
For more information, see ALTER PARTITION ... CONFIGURE ZONE.
Reset a replication zone
> ALTER TABLE t CONFIGURE ZONE USING DEFAULT;
CONFIGURE ZONE 1
Remove a replication zone
When you discard a zone configuration, the objects it was applied to will then inherit a configuration from an object "the next level up"; e.g., if the object whose configuration is being discarded is a table, it will use its parent database's configuration.
You cannot DISCARD any zone configurations on multi-region tables, indexes, or partitions if the multi-region abstractions created the zone configuration.
> ALTER TABLE t CONFIGURE ZONE DISCARD;
CONFIGURE ZONE 1
Constrain leaseholders to specific availability zones
In addition to constraining replicas to specific availability zones, you may also specify preferences for where the range's leaseholders should be placed. This can result in increased performance in some scenarios.
The ALTER TABLE ... CONFIGURE ZONE statement below requires that the cluster try to place the ranges' leaseholders in zone us-east1; if that is not possible, it will try to place them in zone us-west1.
For more information about how the lease_preferences field works, see its description in the Replication zone variables section.
> ALTER TABLE users CONFIGURE ZONE USING num_replicas = 3, constraints = '{"+region=us-east1": 1, "+region=us-west1": 1}', lease_preferences = '[[+region=us-east1], [+region=us-west1]]';
CONFIGURE ZONE 1
> SHOW ZONE CONFIGURATION FROM TABLE users;
target | raw_config_sql
+-------------+--------------------------------------------------------------------+
TABLE users | ALTER TABLE users CONFIGURE ZONE USING
| range_min_bytes = 134217728,
| range_max_bytes = 536870912,
| gc.ttlseconds = 100000,
| num_replicas = 3,
| constraints = '{+region=us-east1: 1, +region=us-west1: 1}',
| lease_preferences = '[[+region=us-east1], [+region=us-west1]]'
(1 row)
Scenario-based examples
Even replication across availability zones
Scenario:
- You have 6 nodes across 3 availability zones, 2 nodes in each availability zone.
- You want data replicated 3 times, with replicas balanced evenly across all three availability zones.
Approach:
Start each node with its availability zone location specified in the
--localityflag:Availability zone 1:
$ cockroach start --insecure --advertise-addr=<node1 hostname> --locality=az=us-1 \ --join=<node1 hostname>,<node3 hostname>,<node5 hostname> $ cockroach start --insecure --advertise-addr=<node2 hostname> --locality=az=us-1 \ --join=<node1 hostname>,<node3 hostname>,<node5 hostname>Availability zone 2:
$ cockroach start --insecure --advertise-addr=<node3 hostname> --locality=az=us-2 \ --join=<node1 hostname>,<node3 hostname>,<node5 hostname> $ cockroach start --insecure --advertise-addr=<node4 hostname> --locality=az=us-2 \ --join=<node1 hostname>,<node3 hostname>,<node5 hostname>Availability zone 3:
$ cockroach start --insecure --advertise-addr=<node5 hostname> --locality=az=us-3 \ --join=<node1 hostname>,<node3 hostname>,<node5 hostname> $ cockroach start --insecure --advertise-addr=<node6 hostname> --locality=az=us-3 \ --join=<node1 hostname>,<node3 hostname>,<node5 hostname>Initialize the cluster:
$ cockroach init --insecure --host=<any node hostname>
There's no need to make zone configuration changes; by default, the cluster is configured to replicate data three times, and even without explicit constraints, the cluster will aim to diversify replicas across node localities.
Per-replica constraints to specific availability zones
Scenario:
- You have 5 nodes across 5 availability zones in 3 regions, 1 node in each availability zone.
- You want data replicated 3 times, with a quorum of replicas for a database holding West Coast data centered on the West Coast and a database for nation-wide data replicated across the entire country.
Approach:
Start each node with its region and availability zone location specified in the
--localityflag:Start the five nodes:
$ cockroach start --insecure --advertise-addr=<node1 hostname> --locality=region=us-west1,az=us-west1-a \ --join=<node1 hostname>,<node2 hostname>,<node3 hostname>,<node4 hostname>,<node5 hostname> $ cockroach start --insecure --advertise-addr=<node2 hostname> --locality=region=us-west1,az=us-west1-b \ --join=<node1 hostname>,<node2 hostname>,<node3 hostname>,<node4 hostname>,<node5 hostname> $ cockroach start --insecure --advertise-addr=<node3 hostname> --locality=region=us-central1,az=us-central1-a \ --join=<node1 hostname>,<node2 hostname>,<node3 hostname>,<node4 hostname>,<node5 hostname> $ cockroach start --insecure --advertise-addr=<node4 hostname> --locality=region=us-east1,az=us-east1-a \ --join=<node1 hostname>,<node2 hostname>,<node3 hostname>,<node4 hostname>,<node5 hostname> $ cockroach start --insecure --advertise-addr=<node5 hostname> --locality=region=us-east1,az=us-east1-b \ --join=<node1 hostname>,<node2 hostname>,<node3 hostname>,<node4 hostname>,<node5 hostname>Initialize the cluster:
$ cockroach init --insecure --host=<any node hostname>On any node, open the built-in SQL client:
$ cockroach sql --insecureCreate the database for the West Coast application:
> CREATE DATABASE west_app_db;Configure a replication zone for the database:
> ALTER DATABASE west_app_db CONFIGURE ZONE USING constraints = '{"+region=us-west1": 2, "+region=us-central1": 1}', num_replicas = 3;CONFIGURE ZONE 1View the replication zone:
> SHOW ZONE CONFIGURATION FOR DATABASE west_app_db;target | raw_config_sql +----------------------+--------------------------------------------------------------------+ DATABASE west_app_db | ALTER DATABASE west_app_db CONFIGURE ZONE USING | range_min_bytes = 134217728, | range_max_bytes = 536870912, | gc.ttlseconds = 90000, | num_replicas = 3, | constraints = '{+region=us-central1: 1, +region=us-west1: 2}', | lease_preferences = '[]' (1 row)Two of the database's three replicas will be put in
region=us-west1and its remaining replica will be put inregion=us-central1. This gives the application the resilience to survive the total failure of any one availability zone while providing low-latency reads and writes on the West Coast because a quorum of replicas are located there.No configuration is needed for the nation-wide database. The cluster is configured to replicate data 3 times and spread them as widely as possible by default. Because the first key-value pair specified in each node's locality is considered the most significant part of each node's locality, spreading data as widely as possible means putting one replica in each of the three different regions.
Multiple applications writing to different databases
Scenario:
- You have 2 independent applications connected to the same CockroachDB cluster, each application using a distinct database.
- You have 6 nodes across 2 availability zones, 3 nodes in each availability zone.
- You want the data for application 1 to be replicated 5 times, with replicas evenly balanced across both availability zones.
- You want the data for application 2 to be replicated 3 times, with all replicas in a single availability zone.
Approach:
Start each node with its availability zone location specified in the
--localityflag:Availability zone 1:
$ cockroach start --insecure --advertise-addr=<node1 hostname> --locality=az=us-1 \ --join=<node1 hostname>,<node2 hostname>,<node3 hostname>,<node4 hostname>,<node5 hostname>,<node6 hostname> $ cockroach start --insecure --advertise-addr=<node2 hostname> --locality=az=us-1 \ --join=<node1 hostname>,<node2 hostname>,<node3 hostname>,<node4 hostname>,<node5 hostname>,<node6 hostname> $ cockroach start --insecure --advertise-addr=<node3 hostname> --locality=az=us-1 \ --join=<node1 hostname>,<node2 hostname>,<node3 hostname>,<node4 hostname>,<node5 hostname>,<node6 hostname>Availability zone 2:
$ cockroach start --insecure --advertise-addr=<node4 hostname> --locality=az=us-2 \ --join=<node1 hostname>,<node2 hostname>,<node3 hostname>,<node4 hostname>,<node5 hostname>,<node6 hostname> $ cockroach start --insecure --advertise-addr=<node5 hostname> --locality=az=us-2 \ --join=<node1 hostname>,<node2 hostname>,<node3 hostname>,<node4 hostname>,<node5 hostname>,<node6 hostname> $ cockroach start --insecure --advertise-addr=<node6 hostname> --locality=az=us-2 \ --join=<node1 hostname>,<node2 hostname>,<node3 hostname>,<node4 hostname>,<node5 hostname>,<node6 hostname>Initialize the cluster:
$ cockroach init --insecure --host=<any node hostname>On any node, open the built-in SQL client:
$ cockroach sql --insecureCreate the database for application 1:
> CREATE DATABASE app1_db;Configure a replication zone for the database used by application 1:
> ALTER DATABASE app1_db CONFIGURE ZONE USING num_replicas = 5;CONFIGURE ZONE 1View the replication zone:
> SHOW ZONE CONFIGURATION FOR DATABASE app1_db;target | raw_config_sql +------------------+---------------------------------------------+ DATABASE app1_db | ALTER DATABASE app1_db CONFIGURE ZONE USING | range_min_bytes = 134217728, | range_max_bytes = 536870912, | gc.ttlseconds = 90000, | num_replicas = 5, | constraints = '[]', | lease_preferences = '[]' (1 row)Nothing else is necessary for application 1's data. Since all nodes specify their availability zone locality, the cluster will aim to balance the data in the database used by application 1 between availability zones 1 and 2.
Still in the SQL client, create a database for application 2:
> CREATE DATABASE app2_db;Configure a replication zone for the database used by application 2:
> ALTER DATABASE app2_db CONFIGURE ZONE USING constraints = '[+az=us-2]';View the replication zone:
> SHOW ZONE CONFIGURATION FOR DATABASE app2_db;target | raw_config_sql +------------------+---------------------------------------------+ DATABASE app2_db | ALTER DATABASE app2_db CONFIGURE ZONE USING | range_min_bytes = 134217728, | range_max_bytes = 536870912, | gc.ttlseconds = 90000, | num_replicas = 3, | constraints = '[+az=us-2]', | lease_preferences = '[]' (1 row)The required constraint will force application 2's data to be replicated only within the
us-2availability zone.
Stricter replication for a table and its secondary indexes
Scenario:
- You have 7 nodes, 5 with SSD drives and 2 with HDD drives.
- You want data replicated 3 times by default.
- Speed and availability are important for a specific table and its indexes, which are queried very frequently, however, so you want the data in the table and secondary indexes to be replicated 5 times, preferably on nodes with SSD drives.
Approach:
Start each node with
ssdorhddspecified as store attributes:5 nodes with SSD storage:
$ cockroach start --insecure --advertise-addr=<node1 hostname> --store=path=node1,attrs=ssd \ --join=<node1 hostname>,<node2 hostname>,<node3 hostname> $ cockroach start --insecure --advertise-addr=<node2 hostname> --store=path=node2,attrs=ssd \ --join=<node1 hostname>,<node2 hostname>,<node3 hostname> $ cockroach start --insecure --advertise-addr=<node3 hostname> --store=path=node3,attrs=ssd \ --join=<node1 hostname>,<node2 hostname>,<node3 hostname> $ cockroach start --insecure --advertise-addr=<node4 hostname> --store=path=node4,attrs=ssd \ --join=<node1 hostname>,<node2 hostname>,<node3 hostname> $ cockroach start --insecure --advertise-addr=<node5 hostname> --store=path=node5,attrs=ssd \ --join=<node1 hostname>,<node2 hostname>,<node3 hostname>2 nodes with HDD storage:
$ cockroach start --insecure --advertise-addr=<node6 hostname> --store=path=node6,attrs=hdd \ --join=<node1 hostname>,<node2 hostname>,<node3 hostname> $ cockroach start --insecure --advertise-addr=<node7 hostname> --store=path=node7,attrs=hdd \ --join=<node1 hostname>,<node2 hostname>,<node3 hostname>Initialize the cluster:
$ cockroach init --insecure --host=<any node hostname>On any node, open the built-in SQL client:
$ cockroach sql --insecureCreate a database and table:
> CREATE DATABASE db;> CREATE TABLE db.important_table;Configure a replication zone for the table that must be replicated more strictly:
> ALTER TABLE db.important_table CONFIGURE ZONE USING num_replicas = 5, constraints = '[+ssd]'View the replication zone:
> SHOW ZONE CONFIGURATION FOR TABLE db.important_table;target | config_sql +-------------------------------+---------------------------------------------+ TABLE db.important_table | ALTER DATABASE app2_db CONFIGURE ZONE USING | range_min_bytes = 1048576, | range_max_bytes = 536870912, | gc.ttlseconds = 90000, | num_replicas = 5, | constraints = '[+ssd]', | lease_preferences = '[]' (1 row)The secondary indexes on the table will use the table's replication zone, so all data for the table will be replicated 5 times, and the required constraint will place the data on nodes with
ssddrives.
Tweaking the replication of system ranges
Scenario:
- You have nodes spread across 7 availability zones.
- You want data replicated 5 times by default.
- For better performance, you want a copy of the meta ranges in all of the availability zones.
- To save disk space, you only want the internal timeseries data replicated 3 times by default.
Approach:
Start each node with a different locality attribute:
$ cockroach start --insecure --advertise-addr=<node1 hostname> --locality=az=us-1 \ --join=<node1 hostname>,<node2 hostname>,<node3 hostname> $ cockroach start --insecure --advertise-addr=<node2 hostname> --locality=az=us-2 \ --join=<node1 hostname>,<node2 hostname>,<node3 hostname> $ cockroach start --insecure --advertise-addr=<node3 hostname> --locality=az=us-3 \ --join=<node1 hostname>,<node2 hostname>,<node3 hostname> $ cockroach start --insecure --advertise-addr=<node4 hostname> --locality=az=us-4 \ --join=<node1 hostname>,<node2 hostname>,<node3 hostname> $ cockroach start --insecure --advertise-addr=<node5 hostname> --locality=az=us-5 \ --join=<node1 hostname>,<node2 hostname>,<node3 hostname> $ cockroach start --insecure --advertise-addr=<node6 hostname> --locality=az=us-6 \ --join=<node1 hostname>,<node2 hostname>,<node3 hostname> $ cockroach start --insecure --advertise-addr=<node7 hostname> --locality=az=us-7 \ --join=<node1 hostname>,<node2 hostname>,<node3 hostname>Initialize the cluster:
$ cockroach init --insecure --host=<any node hostname>On any node, open the built-in SQL client:
$ cockroach sql --insecureConfigure the default replication zone:
> ALTER RANGE default CONFIGURE ZONE USING num_replicas = 5;View the replication zone:
> SHOW ZONE CONFIGURATION FOR RANGE default;target | raw_config_sql +---------------+------------------------------------------+ RANGE default | ALTER RANGE default CONFIGURE ZONE USING | range_min_bytes = 134217728, | range_max_bytes = 536870912, | gc.ttlseconds = 90000, | num_replicas = 5, | constraints = '[]', | lease_preferences = '[]' (1 row)All data in the cluster will be replicated 5 times, including both SQL data and the internal system data.
Configure the
metareplication zone:> ALTER RANGE meta CONFIGURE ZONE USING num_replicas = 7;> SHOW ZONE CONFIGURATION FOR RANGE meta;target | raw_config_sql +------------+---------------------------------------+ RANGE meta | ALTER RANGE meta CONFIGURE ZONE USING | range_min_bytes = 134217728, | range_max_bytes = 536870912, | gc.ttlseconds = 3600, | num_replicas = 7, | constraints = '[]', | lease_preferences = '[]' (1 row)The
metaaddressing ranges will be replicated such that one copy is in all 7 availability zones, while all other data will be replicated 5 times.Configure the
timeseriesreplication zone:> ALTER RANGE timeseries CONFIGURE ZONE USING num_replicas = 3;> SHOW ZONE CONFIGURATION FOR RANGE timeseries;target | raw_config_sql +------------------+---------------------------------------------+ RANGE timeseries | ALTER RANGE timeseries CONFIGURE ZONE USING | range_min_bytes = 134217728, | range_max_bytes = 536870912, | gc.ttlseconds = 90000, | num_replicas = 3, | constraints = '[]', | lease_preferences = '[]' (1 row)The timeseries data will only be replicated 3 times without affecting the configuration of all other data.
