INSERT, UPDATE, DELETE) happen to the rows in . CockroachDB changefeeds have an at-least-once delivery guarantee as well as message ordering guarantees.
This page has reference information for the following changefeed message topics:
- Ordering and delivery guarantees: CockroachDB’s guarantees for a changefeed’s message ordering and delivery.
- Delete messages: The format of messages when a row is deleted.
- Resolved messages: The resolved timestamp option and how to configure it.
- Duplicate messages: The causes of duplicate messages from a changefeed.
- Schema changes: The effect of schema changes on a changefeed.
- Filtering changefeed messages: The settings and syntax to prevent and filter the messages that changefeeds emit.
- Message formats: The limitations and type mapping when creating a changefeed with different message formats.
- : the structure of each message. Include or exclude row data, payload schema definitions, and source metadata.
- Format: the available formats, such as JSON, CSV, and Avro.
Ordering and delivery guarantees
Changefeeds provide the following guarantees for message delivery to changefeed sinks:- Per-key ordering for the first emission of an event’s message.
- At-least-once delivery per event message.
Changefeeds do not support total message ordering or transactional ordering of messages.
Per-key ordering
Changefeeds provide a per-key ordering guarantee for the first emission of a message to the sink. Once the changefeed has emitted a row with a timestamp, the changefeed will not emit any previously unseen versions of that row with a lower timestamp. Therefore, you will never receive a new change for that row at an earlier timestamp. For example, a changefeed can emit updates to rowsA at timestamp T1, B at T2, and C at T3 in any order.
When there are updates to rows A at T1, B at T2, and A at T3, the changefeed will always emit A at T3 (for the first time) after emitting A at T1 (for the first time). However, A at T3 could precede or follow B at T2, because there is no timestamp ordering between keys.
Under some circumstances, a changefeed will emit duplicate messages of row updates. Changefeeds can emit duplicate messages in any order.
As an example, you run the following sequence of SQL statements to create a changefeed:
-
Create a table:
-
Create a changefeed targeting the
employeestable: -
Insert and update values in
employees:
In a , if a row is modified more than once in the same transaction, the changefeed will only emit the last change.
-
The sink will receive messages of the inserted rows emitted per timestamp:
The messages received at the sink are in order by timestamp for each key. Here, the update for key
[1]is emitted before the insertion of key[2]even though the timestamp for the update to key[1]is higher. That is, if you follow the sequence of updates for a particular key at the sink, they will be in the correct timestamp order. However, if a changefeed starts to re-emit messages after the last , it may not emit all duplicate messages between the first duplicate message and new updates to the table. For details on when changefeeds might re-emit messages, refer to Duplicate messages. Theupdatedoption adds anupdatedtimestamp to each emitted row. You can also use theresolvedoption to emit aresolvedtimestamp message to each Kafka partition, or to a separate file at a cloud storage sink. Aresolvedtimestamp guarantees that no (previously unseen) rows with a lower update timestamp will be emitted on that partition.
Depending on the workload, you can use resolved timestamp notifications on every Kafka partition to provide strong ordering and global consistency guarantees by buffering records in between timestamp closures. Use the
resolved timestamp to see every row that changed at a certain time. is subject to the same key ordering guarantee as other sinks. Therefore, as messages are batched, you will not receive two batches at the same time with overlapping keys. You may receive a single batch containing multiple messages about one key, because ordering is maintained for a single key within its batch.
Define a key column
Typically, changefeeds that emit to Kafka sinks shard rows between Kafka partitions using the row’s primary key, which is hashed. The resulting hash remains the same and ensures a row will always emit to the same Kafka partition. In some cases, you may want to specify another column in a table as the key by using the option, which will determine the partition your messages will emit to. However, if you implementkey_column with a changefeed, consider that other columns may have arbitrary values that change. As a result, the same row (i.e., by primary key) may emit to any partition at the sink based upon the column value. A changefeed with a key_column specified will still maintain per-key and at-least-once delivery guarantees.
To confirm that messages may emit the same row to different partitions when an arbitrary column is used, you must include the option:
At-least-once delivery
Changefeeds also provide an at-least-once delivery guarantee, which means that each version of a row will be emitted once. Under some infrequent conditions a changefeed will emit duplicate messages. This happens when the changefeed was not able to emit all messages before reaching a checkpoint. As a result, it may re-emit some or all of the messages starting from the previous checkpoint to ensure that every message is delivered at least once, which could lead to some messages being delivered more than once. Refer to Duplicate messages for causes of messages repeating at the sink. For example, the checkpoints and changefeed pauses marked in this output show how messages may be duplicated, but always delivered:The first time a message is delivered, it will be in the correct timestamp order, which follows the per-key ordering guarantee. However, when there are duplicate messages, the changefeed may not re-emit every row update. As a result, there may be gaps in a sequence of duplicate messages for a key.
updated timestamp. This works across anything in the same cluster (tables, nodes, etc.).
When you use the , if you require timestamps to order messages based on the change event’s commit time, then you must specify envelope=enriched, enriched_properties=source, updated when you create the changefeed, which will include "ts_hlc" and "ts_ns" in the field. (It is important to ignore the at the top level when you’re comparing changes for ordering.) For more details on configuring envelope fields, refer to the page.
The complexity with timestamps is necessary because CockroachDB supports transactions that can affect any part of the cluster, and it is not possible to horizontally divide the transaction log into independent changefeeds. For more information about this, read our blog post on CDC.
When changes happen to a column that is part of a composite , the changefeed will produce a delete message and then an insert message.
Delete messages
Deleting a row will result in a changefeed outputting the primary key of the deleted row and a null value. For example, with default options, deleting the row with primary key5 will output:
Resolved messages
When you create a changefeed with the , the changefeed will emit resolved timestamp messages in a format dependent on the connected . The resolved timestamp is the high-water mark that guarantees that no previously unseen rows with an earlier update timestamp will be emitted to the sink. That is, resolved timestamp messages do not emit until the changefeed job has reached a . When you specify theresolved option at changefeed creation, the will send the resolved timestamp to each endpoint at the sink. For example, each partition will receive a resolved timestamp message, or a will receive a resolved timestamp file.
There are three different ways to configure resolved timestamp messages:
-
If you do not specify the
resolvedoption at all, then the changefeed coordinator node will not send resolved timestamp messages. -
If you include
WITH resolvedin your changefeed creation statement without specifying a value, the coordinator node will emit resolved timestamps as the changefeed job checkpoints and the high-water mark advances. Note that new Kafka partitions may not receive resolved messages right away. -
If you specify a duration like
WITH resolved={duration}, the coordinator node will use the duration as the minimum amount of time that the changefeed’s high-water mark (overall resolved timestamp) must advance by before another resolved timestamp is emitted. The changefeed will only emit a resolved timestamp message if the timestamp has advanced (and by at least the optional duration, if set). For example:
Resolved timestamp frequency
The changefeed job’s coordinating node will emit resolved timestamp messages once the changefeed has reached a checkpoint. The frequency of the checkpoints determine how often the resolved timestamp messages emit to the sink. To configure how often the changefeed checkpoints, you can set the option and (if flushing is configurable for your sink). Themin_checkpoint_frequency option controls how often nodes flush their progress to the coordinating node. If you need resolved timestamp messages to emit from the changefeed more frequently than the 30s default, then you must set min_checkpoint_frequency to at least the desired resolved timestamp frequency. For example:
min_checkpoint_frequency and resolved options, there can be a tradeoff between changefeed message latency and cluster CPU usage.
- Lowering these options will cause the changefeed to checkpoint and send resolved timestamp messages more frequently, which can add overhead to CPU usage in the cluster.
- Raising these options will result in the changefeed checkpointing and sending resolved timestamp messages less frequently, which can cause latency in message delivery to the sink.
min_checkpoint_frequency and resolved to 0s so that the changefeed job checkpoints as frequently as possible and messages are sent immediately followed by the resolved timestamp. However, the frequent checkpointing will increase CPU usage in the cluster. If your application can tolerate a longer duration than 0s between checkpoints, this will help to reduce the overhead on the cluster.
Duplicate messages
Under some circumstances, changefeeds will emit duplicate messages to ensure the sink is receiving each message at least once. The following can cause or increase duplicate messages:- The changefeed job encounters an error and pauses, or is manually paused.
- A node in the cluster restarts or fails.
- The changefeed job has the
min_checkpoint_frequencyoption set, which can potentially increase duplicate messages. - A target table undergoes a schema change. Schema changes may also cause the changefeed to emit the whole target table. Refer to Schema changes for detail on duplicates in this case.
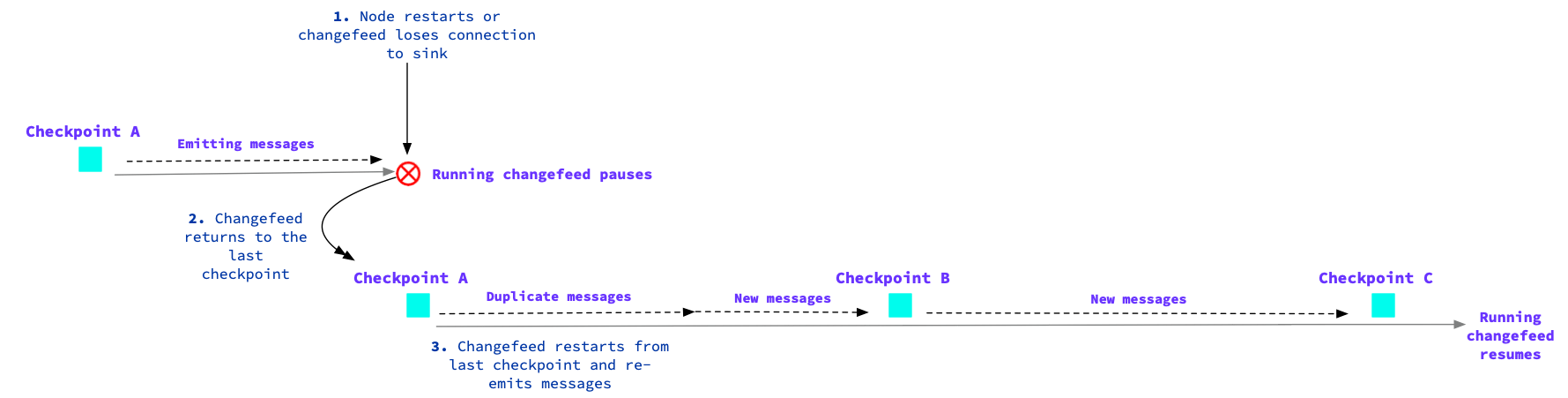
Changefeed encounters an error
By default, changefeeds treat errors as . When a changefeed encounters a retryable or non-retryable error, the job will pause until a successful retry or you resume the job once the error is solved. This can cause duplicate messages at the sink as the changefeed returns to the last checkpoint. We recommend monitoring for changefeed retry errors and failures. Refer to the page.A sink’s batching behavior can increase the number of duplicate messages. For example, if Kafka receives a batch of
N messages and successfully saves N-1 of them, the changefeed job only knows that the batch failed, not which message failed to commit. As a result, the changefeed job will resend the full batch of messages, which means all but one of the messages are duplicates. For Kafka sinks, reducing the batch size with may help to reduce the number of duplicate messages at the sink.Refer to the page for details on sink batching configuration.Node restarts
When a node restarts, the changefeed will emit duplicates since the last checkpoint. During a rolling restart of nodes, a changefeed can fall behind as it tries to catch up during each node restart. For example, as part of a rolling upgrade or cluster maintenance, a node may every 5 minutes and the changefeed job checkpoints every 5 minutes. To prevent the changefeed from falling too far behind, changefeed jobs before performing rolling node restarts.min_checkpoint_frequency option
The min_checkpoint_frequency option controls how often nodes flush their progress to the coordinating changefeed node. Therefore, changefeeds will wait for at least the min_checkpoint_frequency duration before flushing to the sink. If a changefeed pauses and then resumes, the min_checkpoint_frequency duration is the amount of time that the changefeed will need to catch up since its previous checkpoint. During this catch-up time, you could receive duplicate messages.
Schema Changes
For some schema changes, changefeeds will not emit duplicate records for the table that is being altered. Instead, the changefeed will only emit a copy of the table using the new schema. Refer to Schema changes with column backfill for examples of this.Avro schema changes
To ensure that the Avro schemas that CockroachDB publishes will work with the schema compatibility rules used by the Confluent schema registry, CockroachDB emits all fields in Avro as nullable unions. This ensures that Avro and Confluent consider the schemas to be both backward- and forward-compatible, because the Confluent Schema Registry has a different set of rules than Avro for schemas to be backward- and forward-compatible. The original CockroachDB column definition is also included within a doc field__crdb__ in the schema. This allows CockroachDB to distinguish between a NOT NULL CockroachDB column and a NULL CockroachDB column.
Schema validation tools should ignore the
__crdb__ field. This is an internal CockroachDB schema type description that may change between CockroachDB versions.Schema changes with column backfill
When schema changes with column backfill (e.g., adding a column with a default, adding a , adding aNOT NULL column, dropping a column) are made to watched rows, CockroachDB emits a copy of the table using the new schema.
The following example demonstrates the messages you will receive after creating a changefeed and then applying a schema change to the watched table:
schema_change_policy = nobackfill option. In the preceding two output blocks, the new schema messages that include the "likes_treats" column will not emit.
Refer to the for detail on the schema_change_policy option. You can also use the schema_change_events option to define the type of schema change event that triggers the behavior specified in schema_change_policy.
As of v22.1, changefeeds filter out from events by default. This is a . To maintain the changefeed behavior in previous versions where values are emitted for virtual computed columns, see the option for more detail.
Filtering changefeed messages
There are several ways to define messages, filter different types of message, or prevent all changefeed messages from emitting to the sink. The following sections outline configurable settings and SQL syntax to handle different use cases.Prevent changefeeds from emitting row-level TTL deletes
Use thettl_disable_changefeed_replication table storage parameter to prevent changefeeds from sending DELETE messages issued by row-level TTL jobs for a table. Include the storage parameter when you create or alter the table. For example:
sql.ttl.changefeed_replication.disabled to true. This will prevent changefeeds from emitting deletes issued by all TTL jobs on a cluster.
If you want to have a changefeed ignore the storage parameter or cluster setting that disables changefeed replication, you can set the changefeed option ignore_disable_changefeed_replication to true:
Disable changefeeds from emitting messages
To prevent changefeeds from emitting messages for any changes (e.g.,INSERT, UPDATE) issued to watched tables during that session, set the disable_changefeed_replication to true.
Define the change data emitted to a sink
When you create a changefeed, use change data capture queries to define the change data emitted to your sink. For example:Specify a column as a Kafka header
Use theheaders_json_column_name option to specify a column that the changefeed emits as Kafka headers for each row’s change event. You can send metadata, such as routing or tracing information, at the protocol level in the header, separate from the message payload. This allows for Kafka brokers or routers to filter the metadata the header contains without deserializing the payload.
Headers enable efficient routing, filtering, and distributed tracing by intermediate systems, such as Kafka brokers, stream processors, or observability tools.
The
headers_json_column_name option is supported with changefeeds emitting to .kafka_meta column of type JSONB, used to store a trace ID and other metadata for the Kafka header:
kafka_meta column with the JSONB data. The changefeed will emit this column as Kafka headers alongside the row changes:
compliance_events table to Kafka and specify the kafka_meta column using the headers_json_column_name option:
kafka_meta data as Kafka headers, which Kafka brokers or stream processors can use to access the metadata without inspecting the payload.
The Kafka topic receives the message payload with the row-level change, excluding the specified header column (kafka_meta):
If you would like to filter the table columns that a changefeed emits, refer to the page. To customize the message envelope, refer to the page.
Message formats
By default, changefeeds emit messages in JSON format. You can use a different format by with the option and specifying one of the following:jsoncsvavroparquetprotobuf
Avro
The following sections provide information on Avro usage with CockroachDB changefeeds. Creating a changefeed using Avro is available with the option.Avro limitations
Below are clarifications for particular SQL types and values for Avro changefeeds:- must have precision specified.
-
(or its aliases
BYTEAandBLOB) are often used to store machine-readable data. When you stream these types through a changefeed with , CockroachDB does not encode or change the data. However, Avro clients can often include escape sequences to present the data in a printable format, which can interfere with deserialization. A potential solution is to hex-encodeBYTESvalues when initially inserting them into CockroachDB. This will ensure that Avro clients can consistently decode the hexadecimal. Note that hex-encoding values at insertion will increase record size. -
and types are encoded as arrays of 64-bit integers.
For efficiency, CockroachDB encodes
BITandVARBITbitfield types as arrays of 64-bit integers. That is, base-2 (binary format)BITandVARBITdata types are converted to base 10 and stored in arrays. Encoding in CockroachDB is big-endian, therefore the last value may have many trailing zeroes. For this reason, the first value of each array is the number of bits that are used in the last value of the array. For instance, if the bitfield is 129 bits long, there will be 4 integers in the array. The first integer will be1; representing the number of bits in the last value, the second integer will be the first 64 bits, the third integer will be bits 65–128, and the last integer will either be0or9223372036854775808(i.e., the integer with only the first bit set, or1000000000000000000000000000000000000000000000000000000000000000when base 2). This example is base-10 encoded into an array as follows:For downstream processing, it is necessary to base-2 encode every element in the array (except for the first element). The first number in the array gives you the number of bits to take from the last base-2 number — that is, the most significant bits. So, in the example above this would be1. Finally, all the base-2 numbers can be appended together, which will result in the original number of bits, 129. In a different example of this process where the bitfield is 136 bits long, the array would be similar to the following when base-10 encoded:To then work with this data, you would convert each of the elements in the array to base-2 numbers, besides the first element. For the above array, this would convert to:Next, you use the first element in the array to take the number of bits from the last base-2 element,10111110. Finally, you append each of the base-2 numbers together — in the above array, the second, third, and truncated last element. This results in 136 bits, the original number of bits. - A changefeed in will not be able to serialize .
Avro types
Below is a mapping of CockroachDB types to Avro types:The
DECIMAL type is a union between Avro STRING and Avro DECIMAL types.CSV
You can use the option to emit CSV format messages from your changefeed. However, there are the following limitations with this option:- It only works in combination with the option.
- It does not work when used with the or options.
- A changefeed emitting will include
ASlabels in the message format when the changefeed serializes a .
EXPORT statement.
See for detail on using changefeeds to export data from CockroachDB.
The following shows example CSV format output:
JSON
To distinguish between JSONNULL values and SQL NULL values in changefeed messages, you can use the with . When you enable encode_json_value_null_as_object, JSON NULL values will emit as {"__crdb_json_null__": true}.
For example, the following test table has a primary key column and a column. The INSERT adds NULL values in each column. A changefeed without the option enabled will not distinguish between the SQL and JSON NULL values. With the encode_json_value_null_as_object option enabled, the changefeed emits the JSON NULL as {"__crdb_json_null__": true}:
NULL values in the emitted changefeed messages:
encode_json_value_null_as_object enabled, the changefeed will encode the JSON NULL value in the emitted messages:
encode_json_value_null_as_object is enabled, if the changefeed encounters the literal value {"__crdb_json_null__": true} in JSON, it will have the same representation as a JSON NULL value and a warning will be printed to the .
Protobuf
You can use the option to emit Protocol Buffer (protobuf) messages from your changefeed. Protobuf is a binary serialization format that can provide efficient integration with protobuf-native messaging infrastructure, such as Kafka-based streaming systems. The following sections provide information on protobuf usage with CockroachDB changefeeds.Protobuf limitations
The following changefeed option is not supported withformat=protobuf:
- : This option is specific to JSON format and does not work with protobuf messages.
format=protobuf: