If you haven’t already, we recommend reading the .
Overview
To make all data in your cluster accessible from any node, CockroachDB stores data in a monolithic sorted map of key-value pairs. This key-space describes all of the data in your cluster, as well as its location, and is divided into what we call “ranges”, contiguous chunks of the key-space, so that every key can always be found in a single range. CockroachDB implements a sorted map to enable:- Simple lookups: Because we identify which nodes are responsible for certain portions of the data, queries are able to quickly locate where to find the data they want.
- Efficient scans: By defining the order of data, it’s easy to find data within a particular range during a scan.
Monolithic sorted map structure
The monolithic sorted map is comprised of two fundamental elements:- System data, which include meta ranges that describe the locations of data in your cluster (among many other cluster-wide and local data elements)
- User data, which store your cluster’s table data
Meta ranges
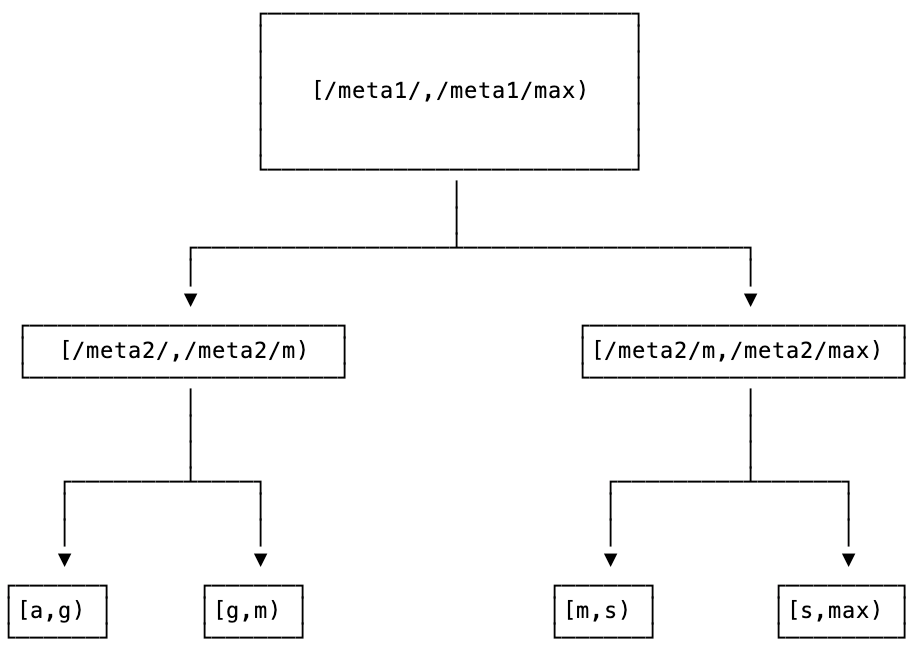
The locations of all ranges in your cluster are stored in a two-level index at the beginning of your key-space, known as meta ranges, where the first level (meta1) addresses the second, and the second (meta2) addresses data in the cluster.
This two-level index plus user data can be visualized as a tree, with the root at meta1, the second level at meta2, and the leaves of the tree made up of the ranges that hold user data.
meta1 range (known as its range descriptor, detailed below), and the range is never split.
This meta range structure lets us address up to 4EiB of user data by default: we can address 2^(18 + 18) = 2^36 ranges; each range addresses 2^26 B, and altogether we address 2^(36+26) B = 2^62 B = 4EiB. However, with larger range sizes, it’s possible to expand this capacity even further.
Meta ranges are treated mostly like normal ranges and are accessed and replicated just like other elements of your cluster’s KV data.
Each node caches values of the meta2 range it has accessed before, which optimizes access of that data in the future. Whenever a node discovers that its meta2 cache is invalid for a specific key, the cache is updated by performing a regular read on the meta2 range.
Table data
After the node’s meta ranges is the KV data your cluster stores. Each table and its secondary indexes initially map to a single range, where each key-value pair in the range represents a single row in the table (also called the primary index because the table is sorted by the primary key) or a single row in a secondary index. As soon as a range reaches , it splits into two ranges. This process continues as a table and its indexes continue growing. Once a table is split across multiple ranges, it’s likely that the table and secondary indexes will be stored in separate ranges. However, a range can still contain data for both the table and a secondary index. The represents a sweet spot for us between a size that’s small enough to move quickly between nodes, but large enough to store a meaningfully contiguous set of data whose keys are more likely to be accessed together. These ranges are then shuffled around your cluster to ensure survivability. These table ranges are replicated (in the aptly named replication layer), and have the addresses of each replica stored in themeta2 range.
Using the monolithic sorted map
As described in the meta ranges section, the locations of all the ranges in a cluster are stored in a two-level index:- The first level (
meta1) addresses the second level. - The second level (
meta2) addresses user data.
meta1, the second level at meta2, and the leaves of the tree made up of the ranges that hold user data.
When a node receives a request, it looks up the location of the range(s) that include the keys in the request in a bottom-up fashion, starting with the leaves of this tree. This process works as follows:
-
For each key, the node looks up the location of the range containing the specified key in the second level of range metadata (
meta2). That information is cached for performance; if the range’s location is found in the cache, it is returned immediately. -
If the range’s location is not found in the cache, the node looks up the location of the range where the actual value of
meta2resides. This information is also cached; if the location of themeta2range is found in the cache, the node sends an RPC to themeta2range to get the location of the keys the request wants to operate on, and returns that information. -
Finally, if the location of the
meta2range is not found in the cache, the node looks up the location of the range where the actual value of the first level of range metadata (meta1) resides. This lookup always succeeds because the location ofmeta1is distributed among all the nodes in the cluster using a gossip protocol. The node then uses the information frommeta1to look up the location ofmeta2, and frommeta2it looks up the locations of the ranges that include the keys in the request.
DistSender machinery) in a BatchRequest.
Interactions with other layers
In relationship to other layers in CockroachDB, the distribution layer:- Receives requests from the transaction layer on the same node.
- Identifies which nodes should receive the request, and then sends the request to the proper node’s replication layer.
Technical details and components
gRPC
gRPC is the software nodes use to communicate with one another. Because the distribution layer is the first layer to communicate with other nodes, CockroachDB implements gRPC here. gRPC requires inputs and outputs to be formatted as protocol buffers (protobufs). To leverage gRPC, CockroachDB implements a protocol-buffer-based API. By default, the network timeout for RPC connections between nodes is , with a connection timeout of , in order to reduce unavailability and tail latencies during infrastructure outages. This can be changed via the environment variableCOCKROACH_NETWORK_TIMEOUT, which defaults to .
Note that the gRPC network timeouts described above are defined from the server’s point of view, not the client’s (the client is any other node that is trying to make an inbound connection). From the client, we send an additional RPC ping every to check that connections are alive. These pings have a fairly high timeout of (a multiple of the value of COCKROACH_NETWORK_TIMEOUT) because they are subject to contention with other RPC traffic; e.g., during a large they can be delayed by several seconds.
For more information about gRPC, see the official gRPC documentation.
BatchRequest
All KV operation requests are bundled into a protobuf, known as aBatchRequest. The destination of this batch is identified in the BatchRequest header, as well as a pointer to the request’s transaction record. (On the other side, when a node is replying to a BatchRequest, it uses a protobuf––BatchResponse.)
This BatchRequest is also what’s used to send requests between nodes using gRPC, which accepts and sends protocol buffers.
DistSender
The gateway/coordinating node’sDistSender receives BatchRequests from its own TxnCoordSender. DistSender is then responsible for breaking up BatchRequests and routing a new set of BatchRequests to the nodes it identifies contain the data using the system meta ranges. For a description of the process by which this lookup from a key to the node holding the key’s range is performed, see Using the monolithic sorted map.
It sends the BatchRequests to the replicas of a range, ordered in expectation of request latency. The leaseholder is tried first, if the request needs it. Requests received by a non-leaseholder may fail with an error pointing at the replica’s last known leaseholder. These requests are retried transparently with the updated lease by the gateway node and never reach the client.
As nodes begin replying to these commands, DistSender also aggregates the results in preparation for returning them to the client.
Meta range KV structure
Like all other data in your cluster, meta ranges are structured as KV pairs. Both meta ranges have a similar structure:
Here’s an example:
node1 is the leaseholder, and nodes 2 and 3 also contain replicas.
Example
Let’s imagine we have an alphabetically sorted column, which we use for lookups. Here are what the meta ranges would approximately look like:-
meta1contains the address for the nodes containing themeta2replicas. -
meta2contains addresses for the nodes containing the replicas of each range in the cluster:
Table data KV structure
Key-value data, which represents the data in your tables using the following structure:index_id of 1 for its PRIMARY KEY columns, with the rest of the columns in the table considered as stored/covered columns.
Range descriptors
Each range in CockroachDB contains metadata, known as a range descriptor. A range descriptor is comprised of the following:- A sequential RangeID
- The keyspace (i.e., the set of keys) the range contains; for example, the first and last
<indexed column valuesin the table data KV structure above. This determines themeta2range’s keys. - The addresses of nodes containing replicas of the range. This determines the
meta2range’s key’s values.
meta2 range, each node’s meta2 cache also stores range descriptors.
Range descriptors are updated whenever there are:
- Membership changes to a range’s Raft group (discussed in more detail in the )
- Range splits
- Range merges
meta2 range.
Range splits
By default, CockroachDB attempts to keep ranges/replicas at . Once a range reaches that limit, we split it into two smaller ranges (composed of contiguous key spaces). During this range split, the node creates a new Raft group containing all of the same members as the range that was split. The fact that there are now two ranges also means that there is a transaction that updatesmeta2 with the new keyspace boundaries, as well as the addresses of the nodes using the range descriptor.
Range merges
By default, CockroachDB automatically merges small ranges of data together to form fewer, larger ranges (up to ). This can improve both query latency and cluster survivability.How range merges work
As described above, CockroachDB splits your cluster’s data into many ranges. For example, your cluster might have a range for customers whose IDs are between[1000, 2000). If that range grows beyond the default range size, the range is split into two smaller ranges.
However, as you delete data from your cluster, a range might contain far less data than the default range size. Over the lifetime of a cluster, this could lead to a number of small ranges.
To reduce the number of small ranges, your cluster can have any range below a certain size threshold try to merge with its “right-hand neighbor”, i.e., the range that starts where the current range ends. Using our example above, this range’s right-hand neighbor might be the range for customers whose IDs are between [2000, 3000).
If the combined size of the small range and its neighbor is less than the maximum range size, the ranges merge into a single range. In our example, this will create a new range of keys [1000, 3000).
When ranges merge, the left-hand-side (LHS) range consumes the right-hand-side (RHS) range.
Why range merges improve performance
Query latency
Queries in CockroachDB must contact a replica of each range involved in the query. This creates the following issues for clusters with many small ranges:- Queries incur a fixed overhead in terms of processing time for each range they must coordinate with.
- Having many small ranges can increase the number of machines your query must coordinate with. This exposes your query to a greater likelihood of running into issues like network latency or overloaded nodes.
Survivability
CockroachDB automatically rebalances the distribution of ranges in your cluster whenever nodes come online or go offline. During rebalancing, it’s better to replicate a few larger ranges across nodes than many smaller ranges. Replicating larger ranges requires less coordination and often completes more quickly. By merging smaller ranges together, your cluster needs to rebalance fewer total ranges. This ultimately improves your cluster’s performance, especially in the face of availability events like node outages.Technical interactions with other layers
Distribution and transaction layer
The distribution layer’sDistSender receives BatchRequests from its own node’s TxnCoordSender, housed in the transaction layer.
Distribution and replication layer
The distribution layer routesBatchRequests to nodes containing ranges of data, which is ultimately routed to the Raft group leader and leaseholder, which are handled in the replication layer.