Before you begin
- Make sure you have already .
- For quick SQL testing or app development, consider instead.
- Note that running multiple nodes on a single host is useful for testing CockroachDB, but it’s not suitable for production. To run a physically distributed cluster, see or , and review the .
Step 1. Generate certificates
You can use either commands or to generate security certificates. This section features thecockroach cert commands.
-
Create two directories:
-
Create the CA (Certificate Authority) certificate and key pair:
-
Create the certificate and key pair for your nodes:
Because you’re running a local cluster and all nodes use the same hostname (
localhost), you only need a single node certificate. Note that this is different than running a production cluster, where you would need to generate a certificate and key for each node, issued to all common names and IP addresses you might use to refer to the node as well as to any load balancer instances. -
Create a client certificate and key pair for the
rootuser:
Step 2. Start the cluster
-
Use the command to start the first node:
You’ll see a message like the following:
-
Take a moment to understand the you used:
-
The
--certs-dirdirectory points to the directory holding certificates and keys. -
Since this is a purely local cluster,
--listen-addr=localhost:26257and--http-addr=localhost:8080tell the node to listen only onlocalhost, with port26257used for internal and client traffic and port8080used for HTTP requests from the DB Console. -
The
--storeflag indicates the location where the node’s data and logs are stored. -
The
--joinflag specifies the addresses and ports of the nodes that will initially comprise your cluster. You’ll use this exact--joinflag when starting other nodes as well. For a cluster in a single region, set 3-5--joinaddresses. Each starting node will attempt to contact one of the join hosts. In case a join host cannot be reached, the node will try another address on the list until it can join the gossip network.
-
The
-
In separate terminal windows, start two more nodes:
These commands are the same as before but with unique
--store,--listen-addr, and--http-addrflags. -
Use the command to perform a one-time initialization of the cluster, sending the request to any node on the
--joinlist:You’ll see the following message:At this point, each node also prints helpful to its log. For example, the following command retrieves node 1’s startup details:The output will look something like this:
Step 3. Use the built-in SQL client
Now that your cluster is live, you can use any node as a SQL gateway. To test this out, let’s use CockroachDB’s built-in SQL client.-
Run the command against node 1:
-
Run some basic :
-
Now exit the SQL shell on node 1 and open a new shell on node 2:
In a real deployment, all nodes would likely use the default port
26257, and so you wouldn’t need to set the port portion of --host.-
Run the same
SELECTquery as before:As you can see, node 1 and node 2 behaved identically as SQL gateways. -
Now , which you will need to access the DB Console:
-
Exit the SQL shell on node 2:
Step 4. Run a sample workload
CockroachDB also comes with a number of for simulating client traffic. Let’s run the workload based on CockroachDB’s sample vehicle-sharing application, .-
Load the initial dataset:
-
Run the workload for 5 minutes:
Step 5. Access the DB Console
The CockroachDB gives you insight into the overall health of your cluster as well as the performance of the client workload.-
On secure clusters, can only be accessed by
adminusers. Run the command against node 1: -
Assign
maxto theadminrole (you only need to do this once): -
Exit the SQL shell:
- Go to https://localhost:8080. Note that your browser will consider the CockroachDB-created certificate invalid; you’ll need to click through a warning message to get to the UI.
If you are using Google Chrome, and you are getting an error about not being able to reach
localhost because its certificate has been revoked, go to chrome://flags/#allow-insecure-localhost, enable “Allow invalid certificates for resources loaded from localhost”, and then restart the browser. Enabling this Chrome feature degrades security for all sites running on localhost, not just CockroachDB’s DB Console, so be sure to enable the feature only temporarily.-
Log in with the username and password you created earlier (
max/roach). -
On the , notice that three nodes are live, with an identical replica count on each node:
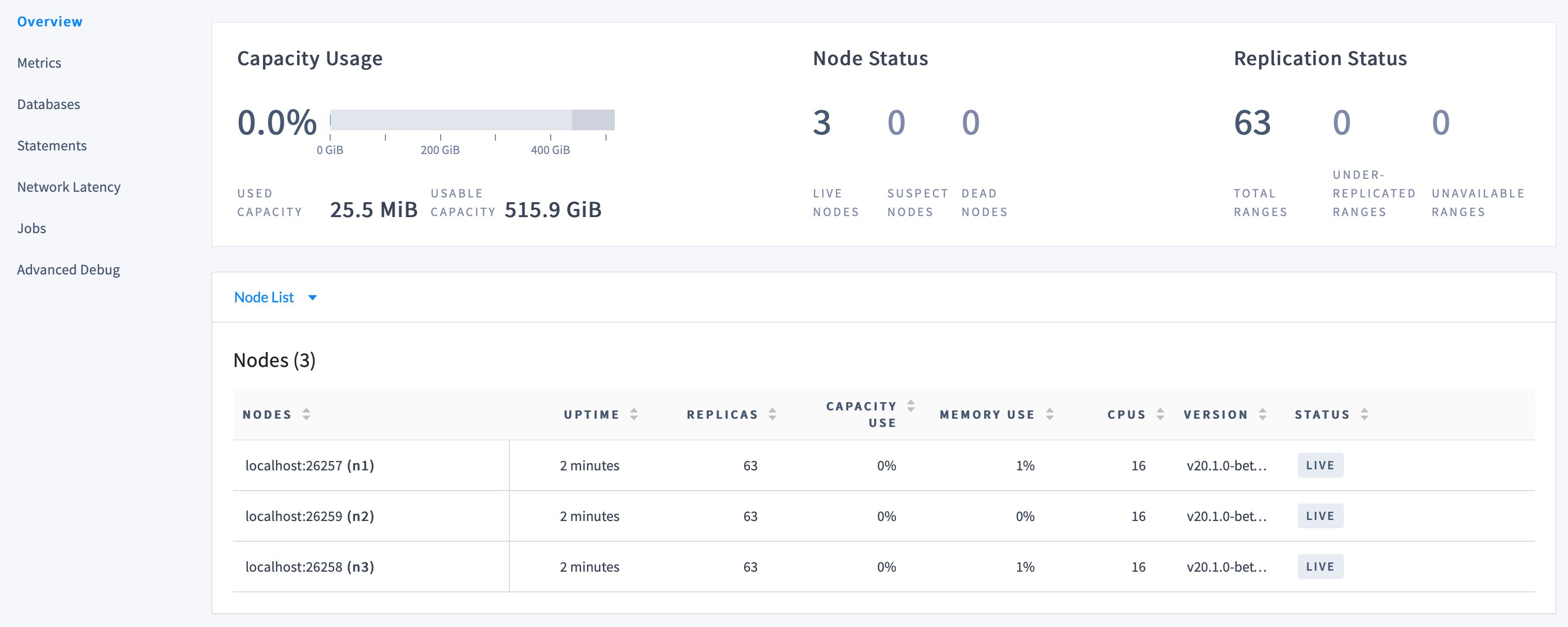
Capacity metrics can be incorrect when running multiple nodes on a single machine. For more details, refer to .
-
Click to access a variety of time series dashboards, including graphs of SQL queries and service latency over time:
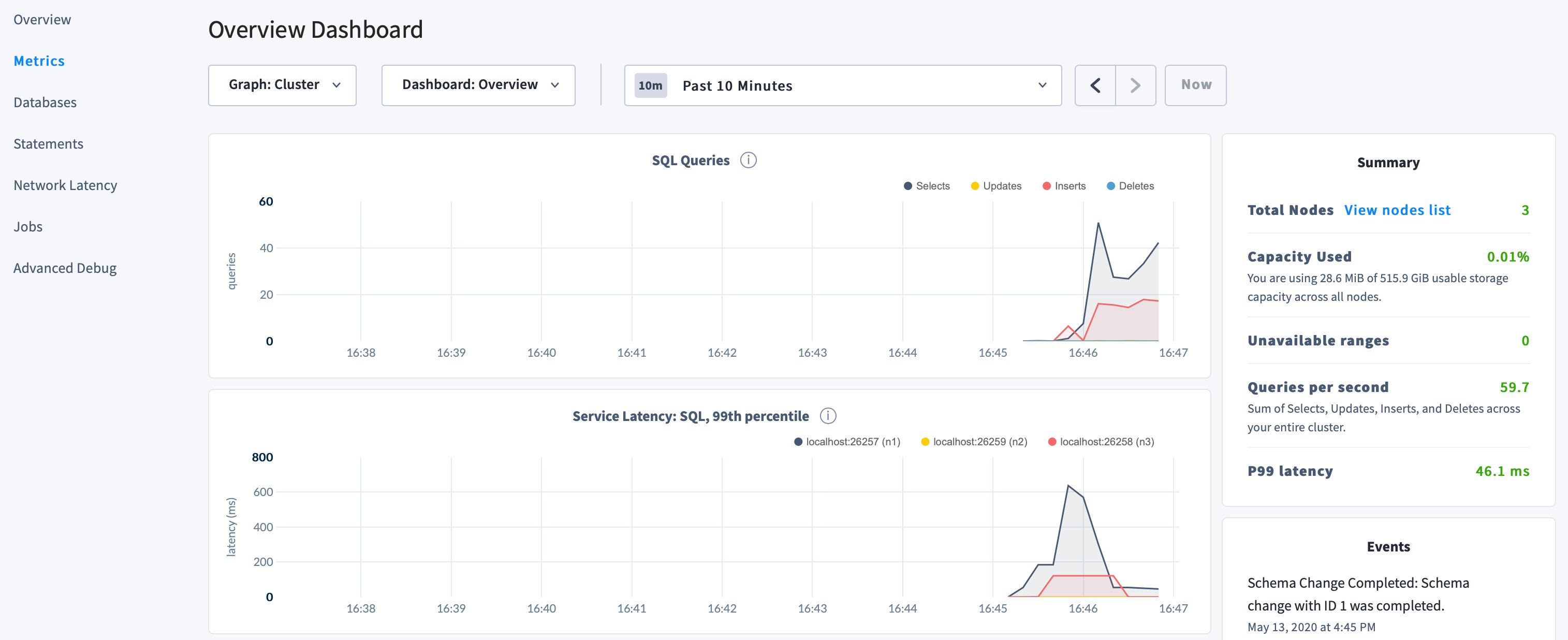
- Use the , , and pages to view details about your databases and tables, to assess the performance of specific queries, and to monitor the status of long-running operations like schema changes, respectively.
Step 6. Simulate node maintenance
-
In a new terminal, gracefully shut down a node. This is normally done prior to node maintenance:
Get the process IDs of the nodes:
Gracefully shut down node 3, specifying its process ID:
-
Back in the DB Console, despite one node being “suspect”, notice the continued SQL traffic:
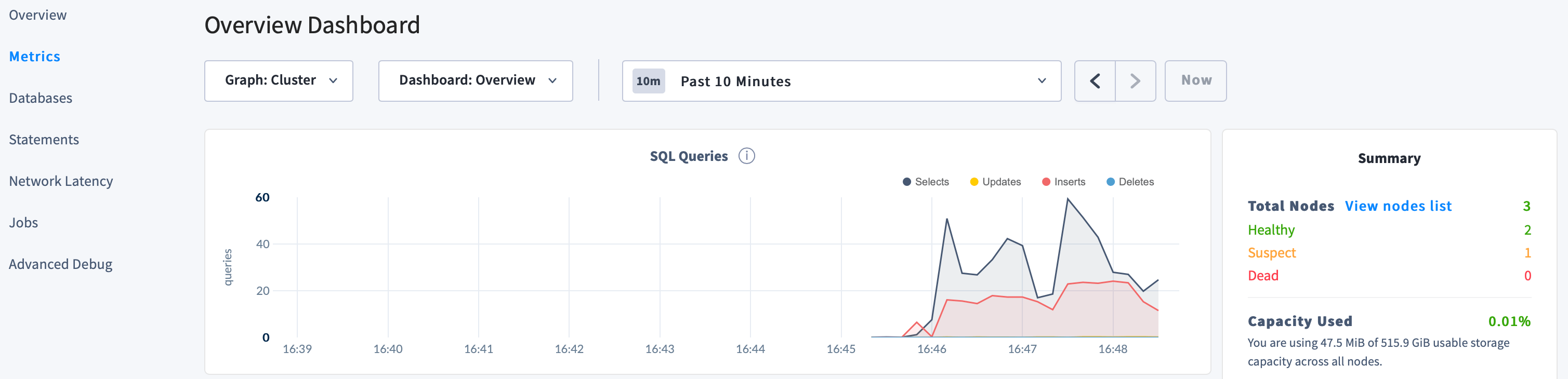
-
Restart node 3:
Step 7. Scale the cluster
Adding capacity is as simple as starting more nodes withcockroach start.
-
In separate terminal windows, start 2 more nodes:
Again, these commands are the same as before but with unique
--store,--listen-addr, and--http-addrflags. -
Back on the Cluster Overview in the DB Console, you’ll now see 5 nodes listed:
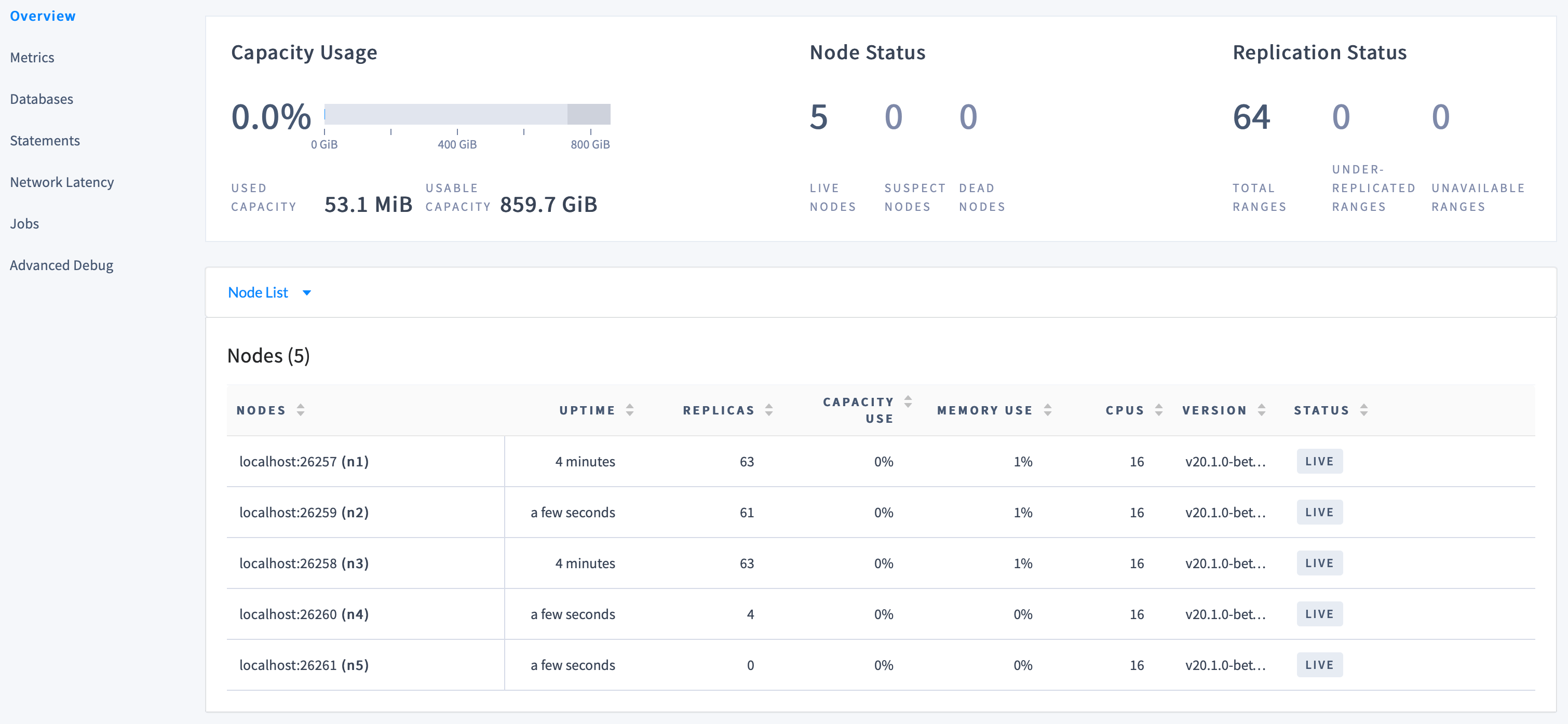
Step 8. Stop the cluster
-
When you’re done with your test cluster, stop the nodes.
Get the process IDs of the nodes:
Gracefully shut down each node, specifying its process ID:
For
node4 and node5, the shutdown process will take longer (about a minute each) and will eventually force the nodes to stop. Because only two of the five nodes are now running, the cluster has lost quorum and is no longer operational.-
To restart the cluster at a later time, run the same
cockroach startcommands as earlier from the directory containing the nodes’ data stores. -
If you do not plan to restart the cluster, you may want to remove the nodes’ data stores and the certificate directories:
What’s next?
- for your preferred language
- Learn more about and the
- Further explore CockroachDB capabilities like , , , and JSON support(/docs/v26.2/jsonb)