

This is part 1 of a 3-part blog series about how we’ve improved the way CockroachDB stores and modifies data in bulk. We went way down into the deepest layers of our storage system, then up to our SQL schema changes and their transaction timestamps - all without anybody noticing (or at least we hope!)
•••
Over the past nearly two years, several engineers across multiple teams have been working on a large project to change various layers of CockroachDB and how they write and delete large quantities of data. This work had to be carefully staged across multiple major releases as it changed even the lowest level, on-disk representation of some types of data as well as how higher level database operations such as schema changes or backups both read and write data, along with all the various layers in-between. The majority of this work was completed in v22.2 and will be enabled by default in v23.1, but if we did our jobs well it will hopefully go completely unnoticed by most users of CockroachDB.
A refresher on MVCC and versioned key-value storage
Before we dig into what we changed and why we had to change it, let’s briefly revisit how CockroachDB stores and modifies rows: As detailed in the architecture and design documentation, rows and their corresponding index entries are broken down into key-value pairs with keys derived from the primary key columns or indexed columns and the remainder of the columns encoded into the value.
When these key-value pairs are written to or updated in the distributed KV storage layer, that layer appends the time at which they are being written or updated to the keys before it actually writes to the on-disk storage layer, meaning each revision to a given key’s value is written as a new, distinct time-suffixed key-value pair in the storage layer, rather than ever overwriting a previous value. A deletion of a key in this scheme consists of writing a new revision with a special value marking it as deleted – known as a tombstone – similarly leaving the prior revisions of the deleted key in place just like any other update to its value.

This versioned-key storage is the central component in implementing the MVCC pattern, which is the basis of how CockroachDB’s KV layer implements correct, consistent, and transactional concurrent reads and writes; storing revisions rather than overwriting allows an earlier transaction to be sure it does not observe the effect of writes performed by a later transaction, since it can read “as of'' its timestamp and ignore any newer revisions of rows it reads written by the later transaction. Put another way, once a reader is reading as of a given time, the state of the world at that time does not change out from under them due to any other writers, meaning it has isolation.
Of course, for this to work correctly, it is vital that any later transactions actually write their revisions at later timestamps, rather than going back and writing at old timestamps that a reader may already have read, and ensuring this – the ordering of overlapping transactions and the times at which they read and write – is correctly enforced is the purpose of several significant components in the KV transaction layer of CockroachDB (intents, the timestamp cache and closed timestamps, latches, etc).
To prevent previous revisions of keys from accumulating indefinitely and using unbounded space, a “garbage collection” process finds and removes stale revisions of keys that are too old to be useful. For transaction-isolation purposes described above, that could be as soon as any ongoing transactions are no longer operating at those timestamps, which could be on the order of seconds or perhaps minutes, but it turns out once you have done all the work and put the systems in place to ensure that every mutation to every key-value is captured in such a versioned, time-stamped scheme, that persisted revision history can prove useful to other features beyond just powering transaction isolation. The ability to read “as of” a given timestamp can allow running queries at user-chosen historical timestamps, and the ability to iterate over the persisted revision history allows determining what has changed between two timestamps; this powers user-facing features such as changefeeds and incremental backups (described in more detail below), so long as the timestamps that need to be read ‘as of’ or ‘between’ remain within the retained window of MVCC history. Thus CockroachDB currently defaults to retaining approximately one day of revision history, although this is configurable and features such as incremental backups automatically adjust retention to ensure the history they are relying on reading is retained.
Bulk KV operations
These various components in the KV transaction layer, including those that exist expressly to ensure correct ordering and interaction of concurrent reading and writing transactions, do add some amount of non-trivial but necessary overhead to each and every key written via the normal, transactional APIs for writing or deleting keys. While this overhead is inherent in the routine cost of processing a SQL INSERT, UPDATE, or DELETE query, for larger bulk operations on an entire table or index even a small amount of per-key overhead can quickly add up to a very significant total cost.
Interestingly, some of this overhead may not be entirely required in some operations, i.e. those where the tables or indexes being operated on are not in use by queries that will be relying on transactional semantics being enforced. For example, during a RESTORE of a table from a backup or during creation of a new index, the table or index does not actually exist yet, for the purposes of SQL queries, while the cluster is loading data into it, meaning there are no concurrent queries trying to read from or write to it. Similarly, when clearing data after a TRUNCATE or DROP, for the purposes of queries and their transactions the table has already been dropped and is unavailable by the time the data is cleared. In such cases, where typical transactional invariants are not required, skipping the various layers that provide them would significantly reduce the aggregate overhead incurred during these bulk operations and offer them a significant additional throughput of the overall operation.
This is what motivated the introduction, very early in the development of CockroachDB prior to v1.0, of a few “unsafe” and “non-transactional” bulk KV methods, tailor-made for use in these higher-level bulk operations, to allow them to write or delete large amounts of data in a way that bypassed many of these components of the KV layer that provide transactional semantics. The two most notable of these bulk KV operations are AddSSTable, used to bulk write data, and ClearRange, used to bulk delete data.
AddSSTable is a method in the KV API which allows an RPC client, i.e. a CockroachDB SQL server process, to send the KV layer a potentially large batch of key-value pairs (relative to usual transactional writes), pre-encoded in the form of a compressed SSTable file or “SST” for short. An SST is the raw file format used for on-disk storage by CockroachDB’s storage engine, Pebble. A client running a bulk ingestion operation can buffer hundreds of thousands or millions of key-value pairs it wishes to ingest, encode each of them with a timestamp suffix just as the KV-layer would if it were writing them to storage, and then assemble those encoded key-value pairs into an SST, compressing them and deriving all the typical metadata such as an index into the file, bloom filters of its contents and so forth. The client can then send this pre-built SST to the KV layer using the AddSSTable, where, since it is already encoded into the native storage format, the KV layer can then directly “link” the provided file into its on-disk storage’s manifest of files, incurring little to no per-key processing overhead or extra write amplification typically associated with traditional individual key-by-key writes. This method is used by RESTORE, IMPORT, CREATE INDEX, and other processes to quickly and cheaply push large amounts of data into the storage layer. As mentioned above, all of these operations take place on a new or offline table or a new index, meaning higher level coordination ensures no queries might be interacting with the table or index, which could otherwise expect transactional semantics usually provided by the layers being skipped by this low-level, direct file ingestion mechanism.

ClearRange is the other most notable Bulk KV API method. It is used by some schema changes, such as dropping a table or index or rolling back after a failed IMPORT or RESTORE. As the name suggests, the operation specifies a range of keys for the underlying storage engine to clear, deleting everything in that range immediately. As this is deleting the actual keys from the storage engine, this means it is deleting all of the time-stamped MVCC revisions of all rows in that range. While a normal transactional delete operation on a row would write a new revision of its key with a tombstone value, this operation in contrast simply destroys the revisions of all rows, as if they never existed. This would be unsafe if a concurrent, earlier transaction were still reading those earlier revisions at the same time, which is why it is only used to clear out a dropped table after it is dropped and queries are no longer running on it, or to remove data partially imported into an offline table before bringing it back online when the importing operation is canceled.
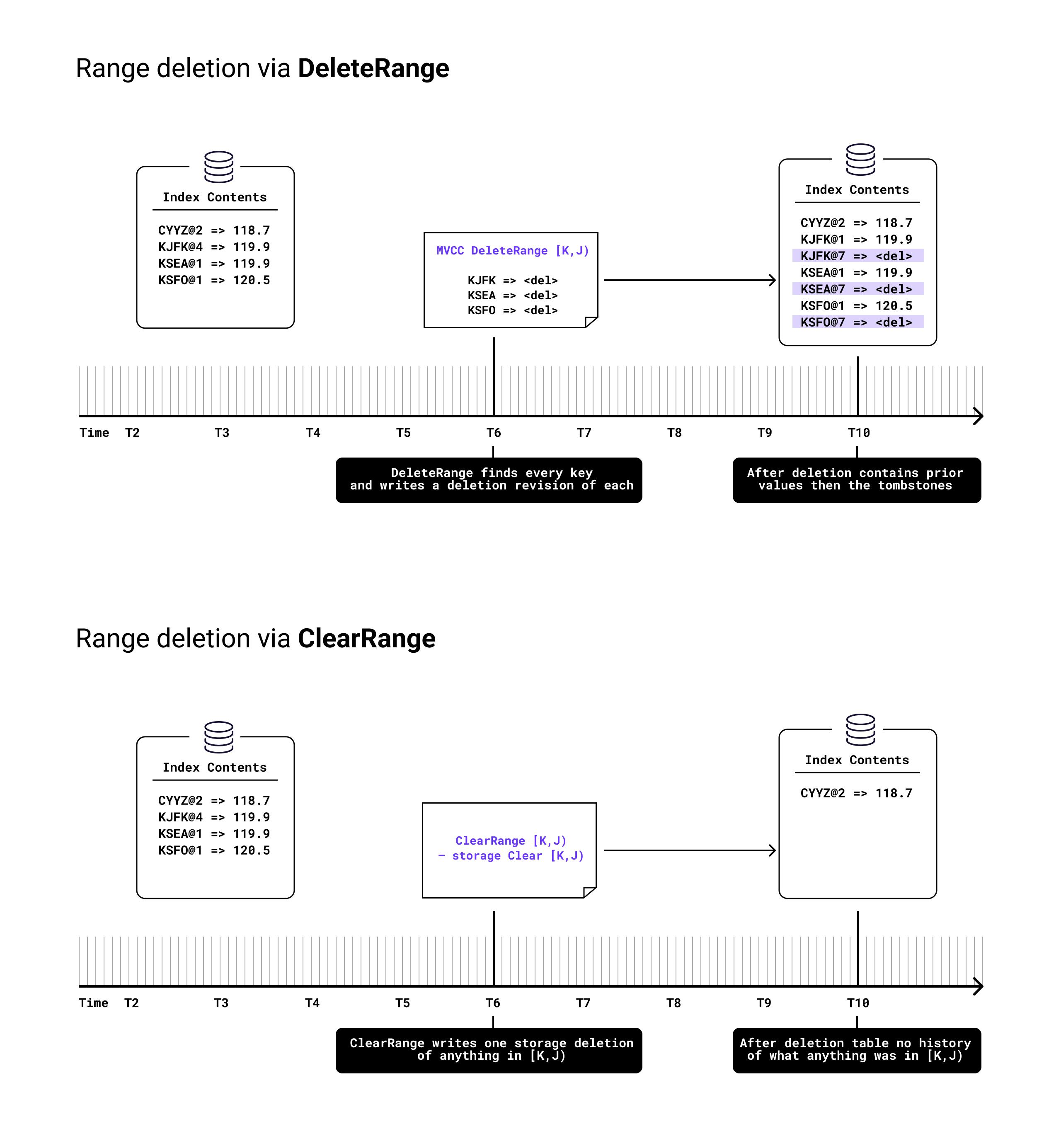
Bulk KV operations are “non-MVCC” operations
As mentioned above, these operations were both recognized, when we introduced them, as unsafe for use against any key spans where normal SQL queries or other operations expecting normal transactional semantics could be in use. In particular, since both these methods allow directly mutating the raw MVCC revisions, they can “rewrite history” by either writing rows at arbitrarily old timestamps via AddSSTable or deleting the old revisions of rows with ClearRange. Thus even though they offered significant performance advantages over transactional MVCC writes or delete, their use was strictly limited to bulk operations where the key-span in question was known to be offline and unavailable to other readers.
For the most part this approach worked well initially: it allowed IMPORT, RESTORE and CREATE INDEX to achieve much higher throughput than they could via the path used by transactional INSERTs or DELETEs, while overall correctness was not sacrificed thanks to limiting their use to only when it was safe to use them. However a key assumption on which this approach relied was that a span being offline to queries, e.g. if it was being restored or backfilled, that that was sufficient to assume that it implied it was offline with respect to all clients that might expect the traditional transactional semantics to hold. While this assumption was initially correct, upholding it over time as other features have developed which also require reading the contents of spans has proved a challenge.
BACKUP and cluster-to-cluster replication features require true MVCC history
BACKUP in CockroachDB works a little differently than it does in some other, non-distributed systems: to ensure that every row in a CockroachDB cluster is backed up, even when rows are moving around between nodes as they are backed up, the backup process operates by executing a logical scan of all rows and indexes to be backed up. It performs this scan as of a single timestamp, meaning the result is a single, consistent snapshot of every key-value pair in each table and each of those tables' indexes, all as of the same moment in logical time. This consistent snapshot is then written out to files in some external storage such as S3.
The fact the underlying storage is versioned also allows relatively straightforward incremental backups, which export and store only those key-value pairs that changed since some previous backup, by doing essentially the same thing as a regular backup except filtering the keys as they are scanned not only to ensure that they are less than or equal to the time as of which the span is being backed up, but also additionally that they are greater than the time previously backed up. Thus, by scanning for and exporting only keys with timestamps greater than the previous backup, an incremental backup is able to backup just what has changed since that previous backup.
This, however, means backups, and in particular incremental backups, are reliant on the fact that any revision to a key written after a previous backup reads that key must be written with a timestamp that is strictly greater than the time at which that backup read it. This is usually the case, when every change to the key writes a new revision at approximately the current time, which by nature of time passing is after any previous reads.
However a write using AddSSTable as described above may not have this property: a client might put a key into an SST where the key has timestamp T4, then finish constructing that SST at time T6 and send it in an AddSSTable request at T7. While the keys in the added SST have a timestamp of T4, they are not actually added to the table or index at any point prior to T7. If a backup runs and reads from the table any time before that SST was added it obviously would not observe the added keys, as they have not yet been added, and thus not include them. If a subsequent incremental backup then scans for only keys added since the previous backup, by scanning for keys with timestamps greater than T5, it will not include the keys added at T7 that used T4, since being added with timestamp T4 makes them appear to have been added before, rather than after, T5. These backdated writes violate the ordering assumptions made by the incremental backup, and thus would fail to be included in any backup, and subject to data loss, if spans where backdated writes are possible were ever backed up incrementally.

This interaction has been understood for several years and is why BACKUP carefully avoids backing up any tables or indexes of tables which are offline for bulk operations; BACKUP depends on MVCC semantics holding in the spans it backs up, while those operations do not uphold them in their spans, so it avoids backing up their spans.
At first glance, this approach appears reasonable, and indeed is the one that CockroachDB has taken to date: and backup’s job is to capture the state of the table(s), database, or cluster as of some point in time, so that it can be restored to that time, and a query run at the same time as is being backed up also cannot read from the new table or index yet. Thus, if a query on the backed up cluster when it was backed up could not have seen the (offline) new table or index, and a query on the restored cluster cannot see the new table or index (since it was not restored since it was not backed up), backup has technically done its job correctly be restoring to how it was as of that time and this approach is sound… right?
Unfortunately this approach has two significant downsides: first, it has proven difficult to implement correctly at times, with certain offline indexes or tables accidentally being backed up due to bugs in interpreting and tracking the states of tables or indexes when they change between incremental backups or interact with features like revision-history backups that capture every single change, including those before or after a table was offline. Second, and more fundamentally, we actually want to back up offline importing spans if we could do so correctly, in particular when used in incremental backups.
Predictable incremental backups and backup “debt”
Typically, most operators want to or need to maintain a recovery point that is both relatively recent and, often more importantly, predictable. The recovery point is the point in time to which one could recover from their most recently completed backup. Generally, the strategy to achieve this is to run frequent and quick incremental backups. Frequency is obviously important, as if you backup twice as often you can generally expect your most recent backup, and thus your recovery point, to be half as old. But how long each backup takes to run once it is started is also vitally important: say you run backups every hour on the hour, and they take 10 minutes each to complete: your recovery point is not an hour, despite backing up hourly: at the one hour mark, when you start that next backup, your most recent backup is already of a point an hour old, but it is another ten minutes before the next backup finishes, and during that time, your most recent backup is still that one from now over an hour ago, ticking up to peak of an hour and ten minutes before the next backup brings the recovery point back to ten minutes.
Thus, for a recent and predictable recovery point, it is generally ideal if each incremental backup has to do roughly the same small amount of work, ideally just exporting one interval’s worth of writes or updates. This, however, runs into a challenge when backups are forced to exclude these offline, importing tables or indexes as described in the previous section. A new table being imported might spend hours or even days offline, importing data at rates that can be hundreds of megabytes per node per second. By the time that table or index comes online, it could have grown to be many terabytes or larger. During that time however, even though incremental backups may have been running every 10 minutes or every hour, they were excluding backing it up, as outlined above, due to it using unsafe non-mvcc writes. When that backfill or import finally finishes however and the table comes online for both queries and backups, the next incremental backup must then capture and export it, in its entirety. This incremental backup might then be many orders of magnitude larger than the incremental backups that ran while it was importing, taking dramatically longer, thus causing a major spike in the age of the most recently backed up time, that is, the recovery point.
We would much prefer to have instead let each of the incremental backups that ran while it was importing have backed up some small portion of the imported data as it was imported, spreading that work over them the same way incremental backups normally just need to export whatever was actually written since the previous backup, but our exclusion of the offline span means we instead accumulate this large backup “debt” that comes due all at once for the first post-import backup.
Multi-tenancy and incremental backups
Starting in 2019 and 2020, CockroachDB began working on support for running multiple SQL clusters as “tenants” of a single shared KV storage cluster. This multi-tenant architecture is the basis of CockroachDB Serverless. In such clusters, the host cluster can back up its tenants by simply exporting all of their keys – every single key-value pair in their assigned key-span – as of some time out to external storage. However, when it does so, the host cluster exporting them only knows that they are keys, and does not know what tables they belong to, if those tables are being imported, or restored, or backfilling indexes, by some process running inside the guest tenant. To use the analogy of operating system virtualization, the host just backs up the raw block device, and does not know which blocks correspond to any higher level concepts mapped onto them by the guest OS, such as files or directories, let alone if those files are in its trash or in a temporary directory or anything of the sort. This means host backups of tenants are obliged to observe and capture spans in which IMPORTs are running and adding SSTables using AddSSTable.
In the first iteration of our multi-tenancy architecture, we recognized the correctness issue this implied for incremental backups and avoided it by always using full backups, which do not rely on being able to correctly determine what changed since some time from only the key-value timestamps, however this means backups of tenants are much more expensive to produce and retain than they would be if they could be performed incrementally (Note that this only applies to the backups that CockroachDB Serverless automatically takes of all hosted clusters, run by our host layer; any backups run by a user on a serverless cluster are run within their cluster and are thus run just like the backups described earlier above, in that they are backups of some set of individual tables, which can thus avoid any offline tables or indexes, so user-facing BACKUP supports incremental backups exactly the same on CockroachDB Serverless as it does in other deployments).
Cluster-to-cluster replication
Two years ago we started working on a new system to replicate every change to every key in an entire key span, byte-for-byte, from one cluster to another, to serve as the basis for building features such as low-downtime migration of serverless tenants between underlying clusters or for replicating every key in a cluster to a passive “warm standby” cluster for failover. Similar to incremental backups, such replication relies on the ability to find and read what data that has changed since a particular time; while in steady-state changes are noted and emitted as they are applied, whenever the process restarts after a node restart or network error or other event, it needs to be able to read from the MVCC history to pick up where it left off.
Thus, just as with incremental backups, cluster-to-cluster replication relies on the MVCC key timestamps in whatever spans is being replicated actually reflecting the time at which those keys were written or modified, i.e. that history is not rewritten in the span it is replicating. However, unlike incremental backups, which as mentioned above can pick and choose which table or index spans to backup so as to avoid those where any non-MVCC bulk operations are actively rewriting history, this replication feature will be run on an entire tenant’s key span or entire cluster’s key span, potentially indefinitely. This means it will be running and replicating while tables and indexes are created, imported into, and dropped within that span, and correctly replicate the results of those operations, rather than just excluding offline tables as backups did. This is what finally forced us to stop trying to work around the fact that bulk operations used non-MVCC writes and instead figure out how to make those operations actually comply with the MVCC invariant that later modifications write keys with later timestamps.
The necessity of making bulk operations MVCC-compliant
We explored a few options to resolve our inability to find keys which had changed since some time when their timestamps did not reflect that time. Initially we tried to see if there were any easy work-arounds or quick fixes.
We started by analyzing the application of AddSSTable requests, to see if there was anything that could do, to persist a record of when the request was run and what it wrote. One evaluated option was to persist on every written key a second “written-time” timestamp, in addition to the MVCC timestamp. However writing this using the correct time on every key appeared just as difficult as just writing with a current MVCC timestamp. Another explored option was to maintain a separate log, recording when each non-MVCC operation was applied and the earliest MVCC timestamp at which it wrote. In theory, such a log could be consulted by a later incremental scan, for example one looking for keys changed between time T5 and T10, allowing it to discover an AddSSTable request run at wall-time T6 contained writes backdated to as early as T3. This information could allow it to expand the lower time-bound of its scan, from T5 down to T3, to ensure it indeed observed every key changed since T5, including those with timestamp T3 added at T6.
However practical concerns with these approaches were numerous: How do you structure such a log for retrieval by arbitrary intersecting spans? When can you truncate it? Even if we can accurately track how backdated every write was to adjust incremental scans to make them correct at the expense of being less selective, will arbitrarily old writes end up effectively deincrementalizing them entirely?
While evaluating these questions and trying to determine if they could be resolved or mitigated, we also evaluated the other non-MVCC command in question, ClearRange, to see if any proposed approaches would work for it as well. However, even if the practical concerns outlined above could be resolved, a much more fundamental problem exists for ClearRange, namely in that it destroys history, rather than just inserting into it after the fact. Thus, even if during an incremental scan, after a ClearRange, that ClearRange had run and cleared the history it is trying to scan, knowing that does not really help: unlike the out-of-order addition where we could simply change the scan bounds to find the additional history, in the clearing case the history is simply gone making scanning it impossible.
Thus, between the practical complications and fundamental limitations, it was clear the only real answer is to update these bulk operations so that they strictly appended to MVCC history as regular transactional writes would, preserving existing history for later incremental scans, with the only remaining questions being how to do so, without sacrificing the performance benefits that had motivated the switch to the non-MVCC-compliant operations in the first place.
Converting bulk operations to use MVCC operations
Given that the entire reason these non-MVCC operations were used at all in bulk operations was their superior performance, maintaining similar performance characteristics was a central concern when evaluating how to change the underlying KV operations to be MVCC-compliant.
For the case of writes, while our goal – that keys appear according to the encoded timestamps to have been written as of the time at which they were actually written – was clear enough but how to get there was less clear.
Since these files are constructed – including their keys and the timestamps within them – before being sent to the KV layer to be added, how could we possibly have the timestamp be the addition time? Would we need to deconstruct the file as it is being added to change each key’s time to the time it is actually being added? Would an O(n) step like this during addition be too slow? Did we need to construct the files instead with no timestamps in their keys at all or a placeholder, then just edit the footer of the file to record the timestamp of addition, in a single field, and then extend the readers of these files to inject that timestamp into each key they read to replace the placeholder?
Even as we started to explore these implementation questions, we realized a further challenge was that while the higher level operations had switched to these non-MVCC KV methods originally for performance, in the interim in at least the case of index creation, the higher level operation had become reliant for correctness on the actual non-MVCC nature of the method, relying on back-dating writes based on stale reads to avoid conflicting with more up-to-date writes from ongoing transactions, explicitly relying on exactly the functionality identified as a problem. Thus, in addition to the challenge of finding a performant implementation of an MVCC-compliant AddSSTable method, we also needed to significantly rearchitect the higher level operation to even be compatible with this new method. The details of this change to the index creation process, and how we changed AddSSTable itself to be MVCC-compliant, are explored in depth in part two of this post.
In part three, we dive into MVCC-compliant range deletion. As mentioned above, the distinguishing characteristic of ClearRange versus the normal deletion of a range of keys was that while normal deletions of a range were approximately linear cost for keys in that range – they had to find each key in the range and then write a tombstone revision over it – deletion via ClearRange was closer to constant, since it could apply a single range-deletion to the underlying storage engine regardless of how many keys or rows were in that range. To instead write a new MVCC revision for each key indicating that it is deleted, but to still do so with only a single write necessitated a new mechanism in our storage engine to persist and retrieve range keys and then integrating that into our KV layer’s resolution of the most current MVCC revision of any given key everywhere it scans revisions. The details of this project will be the subject of the third and final part of this blog post.


