

Reader’s Note: This post references CockroachDB Serverless and/or CockroachDB Dedicated which, as of September 26 2024, have been renamed and incorporated within the new CockroachDB Cloud platform, which you can read more about here.
We recently announced general availability (GA) for Serverless, with support for change data capture (CDC), backup and restore, and a 99.99% uptime SLA. Read on to learn how CockroachDB Serverless works from the inside out, and why we can give it away for free – not free for some limited period, but free. It required some significant and fascinating engineering to get us there. I think you’ll enjoy reading about it in this blog or watching the recent presentation I gave with my colleague Emily Horing:
What is CockroachDB Serverless?
If you’ve created a database before, you probably had to estimate the size and number of servers to use based on the expected traffic. If you guessed too low, your database would fall over under load and cause an outage. If you guessed too high or if your traffic came in bursts, you’d waste money on servers that are just sitting idle. Could there be a better way?
Serverless means you don’t have to think about servers. Of course there are servers hard at work handling your application’s requests, but that’s our problem, not yours. We do all the hard work behind the scenes of allocating, configuring, and maintaining the servers. Instead of paying for servers, you pay for the requests that your application makes to the database and the storage that your data consumes.
You pay only for what you actually use, without needing to figure out up-front what that might be. If you use more, then we’ll automatically allocate more hardware to handle the increased load. If you use less, then you’ll pay less, or even nothing at all. And you’ll never be surprised by a bill, because you can set a guaranteed monthly resource limit. We’ll alert you as you approach that limit and give you options for how to respond.
With just a few clicks or an API call, you can create a fully-featured CockroachDB database in seconds. You get an “always on” database that survives data center failure and keeps multiple encrypted copies of your data so you don’t lose it to hackers or hardware failure. It automatically and transparently scales to meet your needs, no matter how big or small, with no changes to your application. It supports online schema migrations, Postgres compatibility, and gives you unrestricted access to Enterprise features.
Oh, and please use your favorite language, SDK, or tooling in whatever application environment you choose; using CockroachDB Serverless does not mean you have to use a Serverless compute service like AWS Lambda or Google Cloud Functions (though, that’s a great tool too!).
How can we afford to give this away? Well, certainly we’re hoping that some of you will build successful apps that “go big” and you’ll become paying customers. But beyond that, we’ve created an innovative Serverless architecture that allows us to securely host thousands of virtualized CockroachDB database clusters on a single underlying physical CockroachDB database cluster. This means that a tiny database with a few kilobytes of storage and a handful of requests costs us almost nothing to run, because it’s running on just a small slice of the physical hardware. I’ll explain how all this works in more detail below, but here’s a diagram to get you thinking:
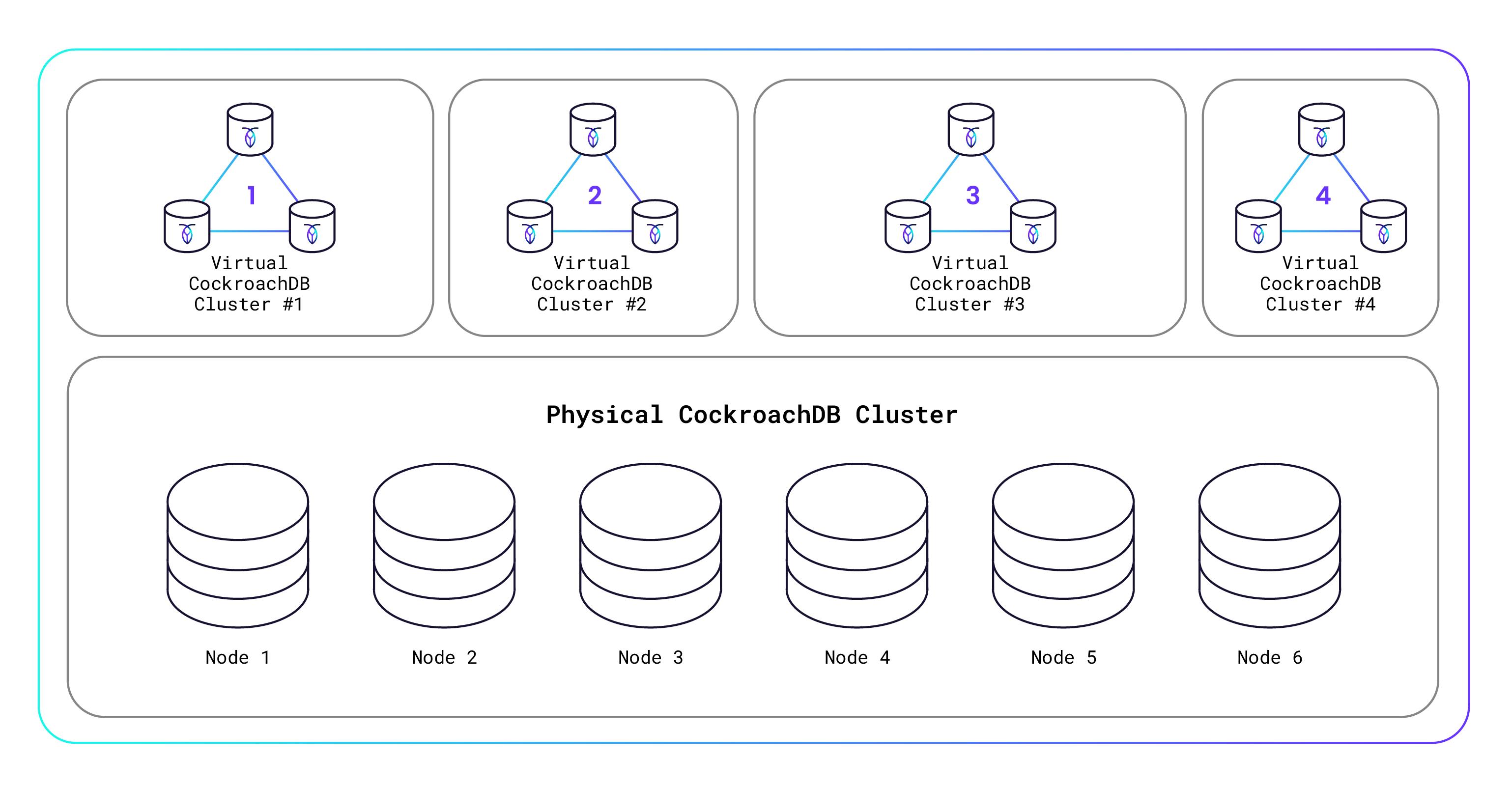
Single-Tenant Architecture
Before now, a single physical CockroachDB cluster was intended for dedicated use by a single user or organization. That is called single-tenancy. Over the past several CockroachDB releases, we’ve quietly been adding multi-tenancy support, which enables the physical CockroachDB cluster to be shared by multiple users or organizations (called “tenants”). Each tenant gets its own virtualized CockroachDB cluster that is hosted on the physical CockroachDB cluster and yet is secure and isolated from other tenants’ clusters. You’re probably familiar with how virtual machines (VMs) work, right? It’s kind of like that, only for database clusters.
Before I can meaningfully explain how multi-tenancy works, I need to review the single-tenant architecture. To start with, a single-tenant CockroachDB cluster consists of an arbitrary number of nodes. Each node is used for both data storage and computation, and is typically hosted on its own machine. Within a single node, CockroachDB has a layered architecture. At the highest level is the SQL layer, which parses, optimizes, and executes SQL statements. It does this by a clever translation of higher-level SQL statements to simple read and write requests that are sent to the underlying key-value (KV) layer.
The KV layer maintains a transactional, distributed, replicated key-value store. That’s a mouthful, so let me break it down. Each key is a unique string that maps to an arbitrary value, like in a dictionary. KV stores these key-value pairs in sorted order for fast lookup. Multiple key-value pairs are also grouped into ranges. Each range contains a contiguous, non-overlapping portion of the total key-value pairs, sorted by key. Ranges are distributed across the available nodes and are also replicated at least three times, for high-availability. Key-value pairs can be added, removed, and updated in all-or-nothing transactions. Here is a simplified example of how a higher-level SQL statement gets translated into a simple KV GET call:
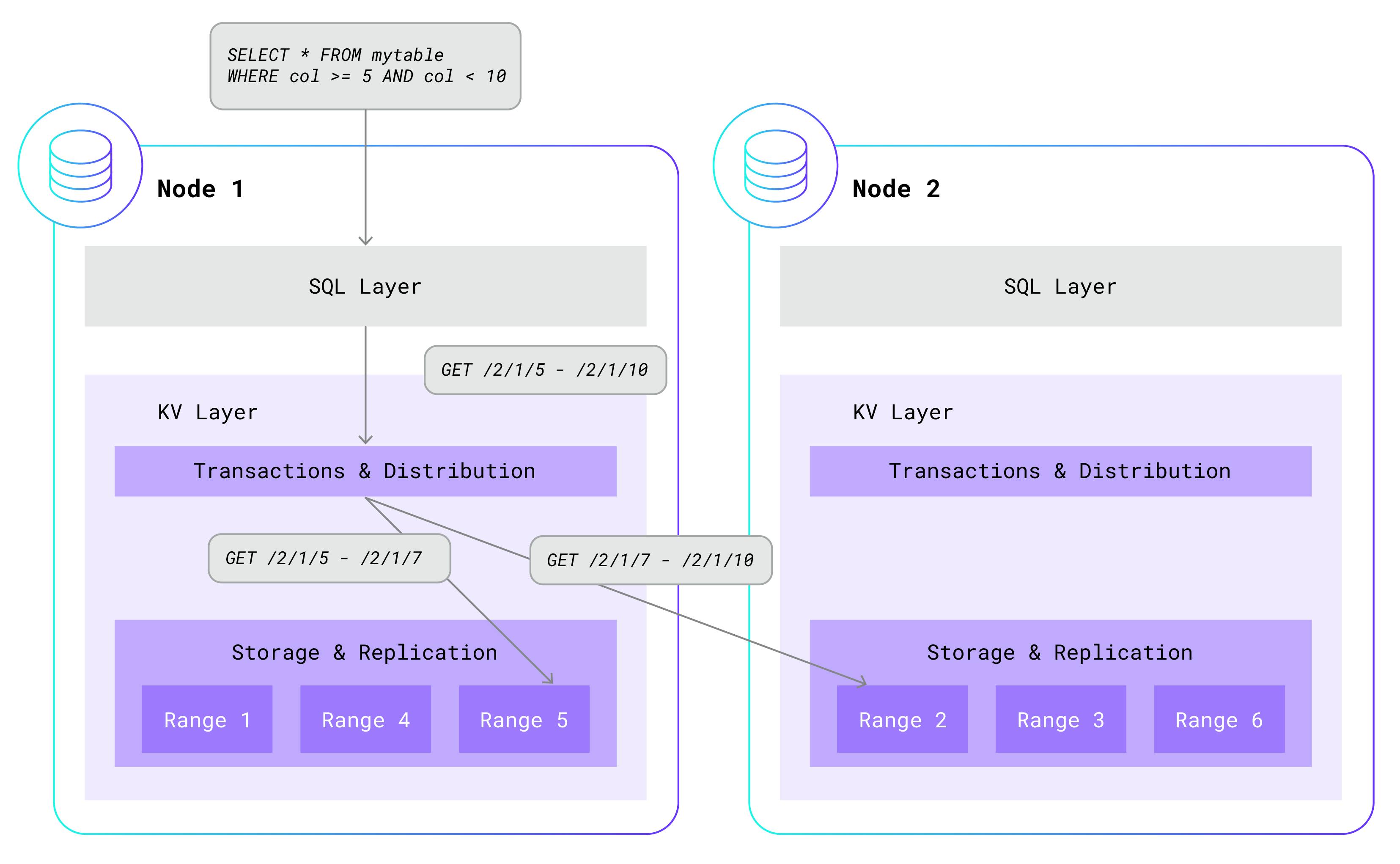
In single-tenant CockroachDB, the SQL layer is co-located with the KV layer on each node and in the same process. While the SQL layer always calls into the KV instance that runs on the same node, KV will often “fan-out” additional calls to other instances of KV running on other nodes. This is because the data needed by SQL is often located in ranges that are scattered across nodes in the cluster.
Multi-Tenant Architecture
How do we extend that single-tenant architecture to support multiple tenants? Each tenant should feel like they have their own dedicated CockroachDB cluster, and should be isolated from other tenants in terms of performance and security. But that’s very difficult to achieve if we attempt to share the SQL layer across tenants. One tenant’s runaway SQL query could easily disrupt the performance of other tenants in the same process. In addition, sharing the same process would introduce many cross-tenant security threats that are difficult to reliably mitigate.
One possible solution to these problems would be to give each tenant its own set of isolated processes that run both the SQL and KV layers. However, that creates a different problem: we would be unable to share the key-value store across tenants. That eliminates one of the major benefits of a multi-tenant architecture: the ability to efficiently pack together the data of many tiny tenants in a shared storage layer.
After mulling over this problem, we realized that the dilemma can be elegantly solved by isolating some components and sharing other components. Given that the SQL layer is so difficult to share, we decided to isolate that in per-tenant processes, along with the transactional and distribution components from the KV layer. Meanwhile, the KV replication and storage components continue to run on storage nodes that are shared across all tenants. By making this separation, we get “the best of both worlds” – the security and isolation of per-tenant SQL processes and the efficiency of shared storage nodes. Here is an updated diagram showing two isolated per-tenant SQL nodes interacting with a shared storage layer:
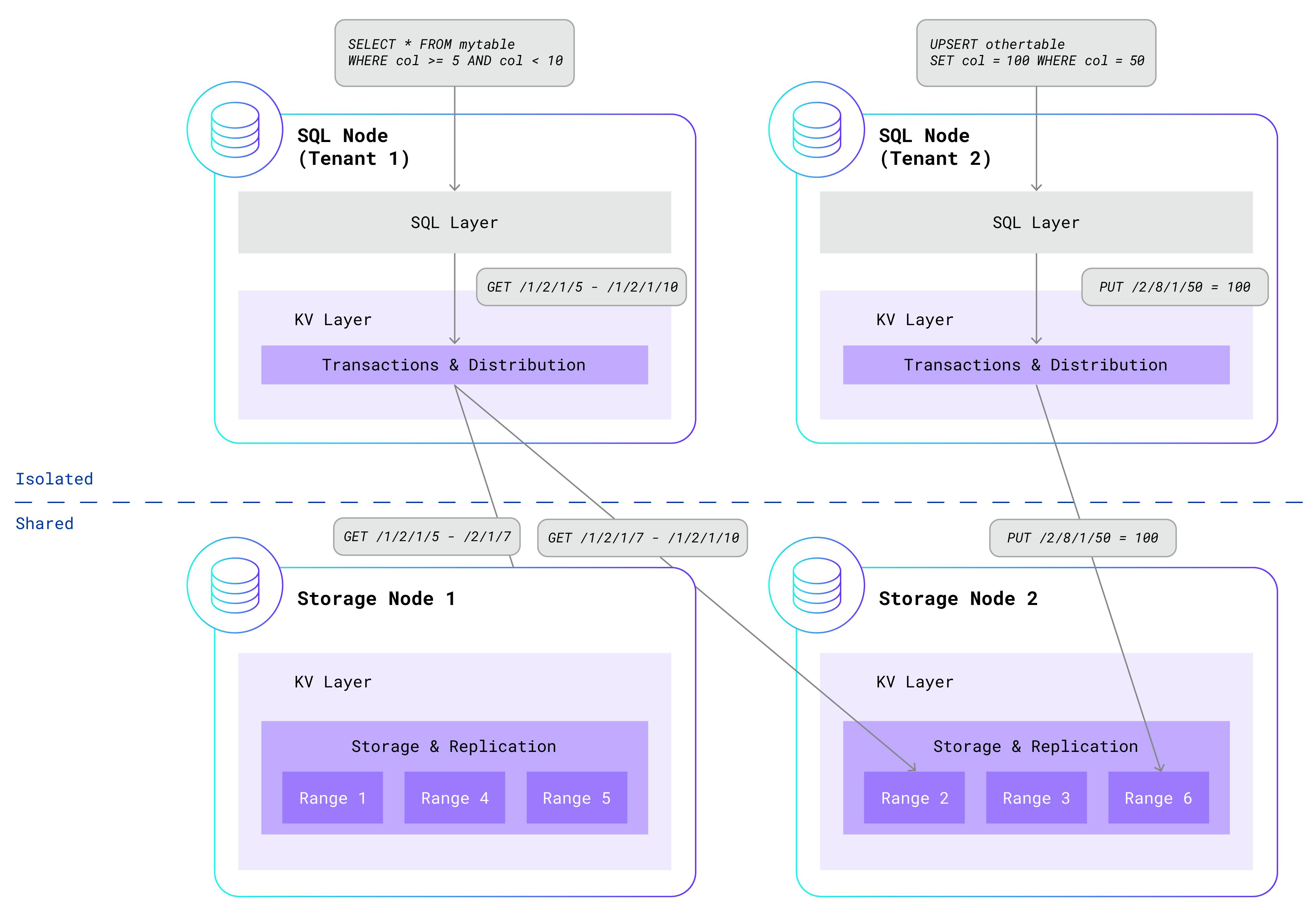
The storage nodes no longer run tenant SQL queries, but they still leverage the sophisticated infrastructure that powers single-tenant CockroachDB. Node failures are detected and repaired without impacting data availability. Leaseholders, which serve reads and coordinate writes for each range, move according to activity. Busy ranges are automatically split; quiet ranges are merged. Ranges are rebalanced across nodes based on load. The storage layer caches hot ranges in memory and pushes cold ones to disk. Three-way replication across availability zones ensures that your data is safely stored and highly available.
After seeing this architecture, you might be wondering about the security of the shared storage nodes. We spent significant time designing and implementing strong security measures to protect tenant data. Each tenant receives an isolated, protected portion of the KV keyspace. This is accomplished by prefixing every key generated by the SQL layer with the tenant’s unique identifier. Rather than generating a key like /<table-id>/<index-id>/<key>, SQL will generate a key like /<tenant-id>/<table-id>/<index-id>/<key>. This means that key-value pairs generated by different tenants are isolated in their own ranges. Furthermore, the storage nodes authenticate all communication from the SQL nodes and ensure that each tenant can only touch keys that are prefixed by its own tenant identifier.
Besides security, we were also concerned about ensuring basic quality of service across tenants. What happens if KV calls from multiple tenants threaten to overload a storage node? In that case, CockroachDB admission control kicks in. The admission control system integrates with the Go scheduler and maintains queues of work that ensure fairness across tenants. Each tenant’s GET, PUT, and DELETE requests are given a roughly equal allocation of CPU time and storage I/O. This ensures that a single tenant cannot monopolize resources on a storage node.
Serverless Architecture
Wait…wasn’t the last section about the Serverless architecture? Well, yes and no. As discussed, we’ve made significant upgrades to the core database architecture to support multi-tenancy. But that’s only half of the story. We also needed to make big enhancements in how we deploy and operate multi-tenant CockroachDB clusters in order to make Serverless possible.
Our managed cloud service uses Kubernetes (K8s) to operate Serverless clusters, including both shared storage nodes and per-tenant SQL nodes. Each node runs in its own K8s pod, which is not much more than a Docker container with a virtualized network and a bounded CPU and memory capacity. Dig down deeper, and you’ll discover a Linux cgroup that can reliably limit the CPU and memory consumption for the processes. This allows us to easily meter and limit SQL resource consumption on a per-tenant basis. It also minimizes interference between pods that are scheduled on the same machine, giving each tenant a high-quality experience even when other tenants are running heavy workloads.
Here is a high-level (simplified) representation of what a typical setup looks like:

What are those “proxy pods” doing in the K8s cluster? It turns out they’re pretty useful:
They allow many tenants to share the same IP address. When a new connection arrives, the proxy “sniffs” the incoming Postgres connection packets in order to find the tenant identifier in a SNI header or aPG connection option. Now it knows which SQL pods it should route that connection to.
They balance load across a tenant’s available SQL pods, using a “least connections” algorithm.
They detect and respond to suspected abuse of the service. This is one of the security measures we take for the protection of your data.
They automatically resume tenant clusters that have been paused due to inactivity. We’ll get into more detail on that in the Scaling section below.
After the cloud load balancer routes a new connection to one of the proxy pods, the proxy pod will in turn forward that connection to a SQL pod owned by the connecting tenant. Each SQL pod is dedicated to just one tenant, and multiple SQL pods can be owned by the same tenant. Network security rules prevent SQL pods from talking to one another, unless they are owned by the same tenant. Finally, the SQL pods communicate via the KV layer to access data managed by the shared storage pods, each of which stores that data in a cloud provider block storage system like AWS EBS or GCP PD.
One of the best things about Serverless clusters is how fast they can be created. A regular Dedicated cluster takes 20-30 minutes to launch, since it has to create a cloud provider project, spin up new VMs, attach block storage devices, allocate IP and DNS addresses, and more. By contrast, a Serverless cluster takes just a few seconds to create, since we only need to instruct K8s to create a new SQL pod on an existing VM that it is already managing.
Besides speed of creation, Serverless SQL pods also have a big cost advantage. They can be packed together on a VM, sharing the same OS as well as available CPU and memory. This substantially reduces the cost of running “long-tail” tenants that have minuscule workloads, since they can each use just a small slice of the hardware. Contrast this with a dedicated VM, which generally requires at least 1 vCPU and 1GB of memory to be reserved for it.
Scaling
As the amount of data owned by a tenant grows, and the frequency with which that data is accessed grows, the tenant’s data will be split into a growing number of KV ranges which will be spread across more shared storage pods. Data scaling of this kind is already well supported by CockroachDB, and operates in about the same way in multi-tenant clusters as it always has in single-tenant clusters. I won’t cover that kind of scaling in any more detail here.
Similarly, as the number of SQL queries and transactions run against a tenant’s data increases, the compute resources allocated to that tenant must grow proportionally. One tenant’s workload may need dozens or even hundreds of vCPUs to execute, while another tenant’s workload may just need a part-time fraction of a vCPU. In fact, we expect most tenants to not need any CPU at all. This is because a large proportion of developers who try CockroachDB Serverless are just “kicking the tires”. They’ll create a cluster, maybe run a few queries against it, and then abandon it, possibly for good. Even keeping a fraction of a vCPU idling for their cluster would be a tremendous waste of resources when multiplied by all inactive clusters. And even for tenants who regularly use their cluster, SQL traffic load is not constant; it may greatly fluctuate from day to day and hour to hour, or even second to second.
How does CockroachDB Serverless handle such a wide range of shifting resource needs? By dynamically allocating the right number of SQL pods to each tenant, based on its second-to-second traffic load. New capacity can be assigned instantly in the best case and within seconds in the worst case. This allows even extreme spikes in tenant traffic to be handled smoothly and with low latency. Similarly, as traffic falls, any SQL pod that is no longer needed can be shut down, with any remaining SQL connections transparently migrated to other pods for that tenant. If traffic falls to zero and no SQL connections remain, then all SQL pods owned by the now inactive tenant are terminated. As soon as new traffic arrives, a new SQL pod can be spun back up within a few hundred milliseconds. This allows a seldom-used CockroachDB Serverless cluster to still offer production-grade latencies for almost no cost to Cockroach Labs, and no cost at all to the user.
Such responsive scaling is only possible because multi-tenant CockroachDB splits the SQL layer from the KV storage layer. Because SQL pods are stateless, they can be created and destroyed at will, without impacting the consistency or durability of tenant data. There is no need for complex coordination between pods, or for careful commissioning and decommissioning of pods, as we must do with the stateful storage pods to ensure that all data stays consistent and available. Unlike storage pods, which typically remain running for extended periods of time, SQL pods are ephemeral and may be shut down within minutes of starting up.
The Autoscaler
Let’s dig a little deeper into the mechanics of scaling. Within every Serverless cluster, there is an autoscaler component that is responsible for determining the ideal number of SQL pods that should be assigned to each tenant, whether that be one, many, or zero. The autoscaler monitors the CPU load on every SQL pod in the cluster, and calculates the number of SQL pods based on two metrics:
Average CPU usage over the last 5 minutes.
Peak CPU usage during the last 5 minutes.
Average CPU usage determines the “baseline” number of SQL pods that will be assigned to the tenant. The baseline deliberately over-provisions SQL pods so that there is spare CPU available in each pod for instant bursting. However, if peak CPU usage recently exceeded even the higher over-provisioned threshold, then the autoscaler accounts for that by increasing the number of SQL pods past the baseline. This algorithm combines the stability of a moving average with the responsiveness of an instantaneous maximum. The autoscaler avoids too-frequent scaling, but can still quickly detect and react to large spikes in load.
Once the autoscaler has derived the ideal number of SQL pods, it triggers a K8s reconciliation process that adds or removes pods in order to reach the ideal number. The following diagram shows the possible outcomes:
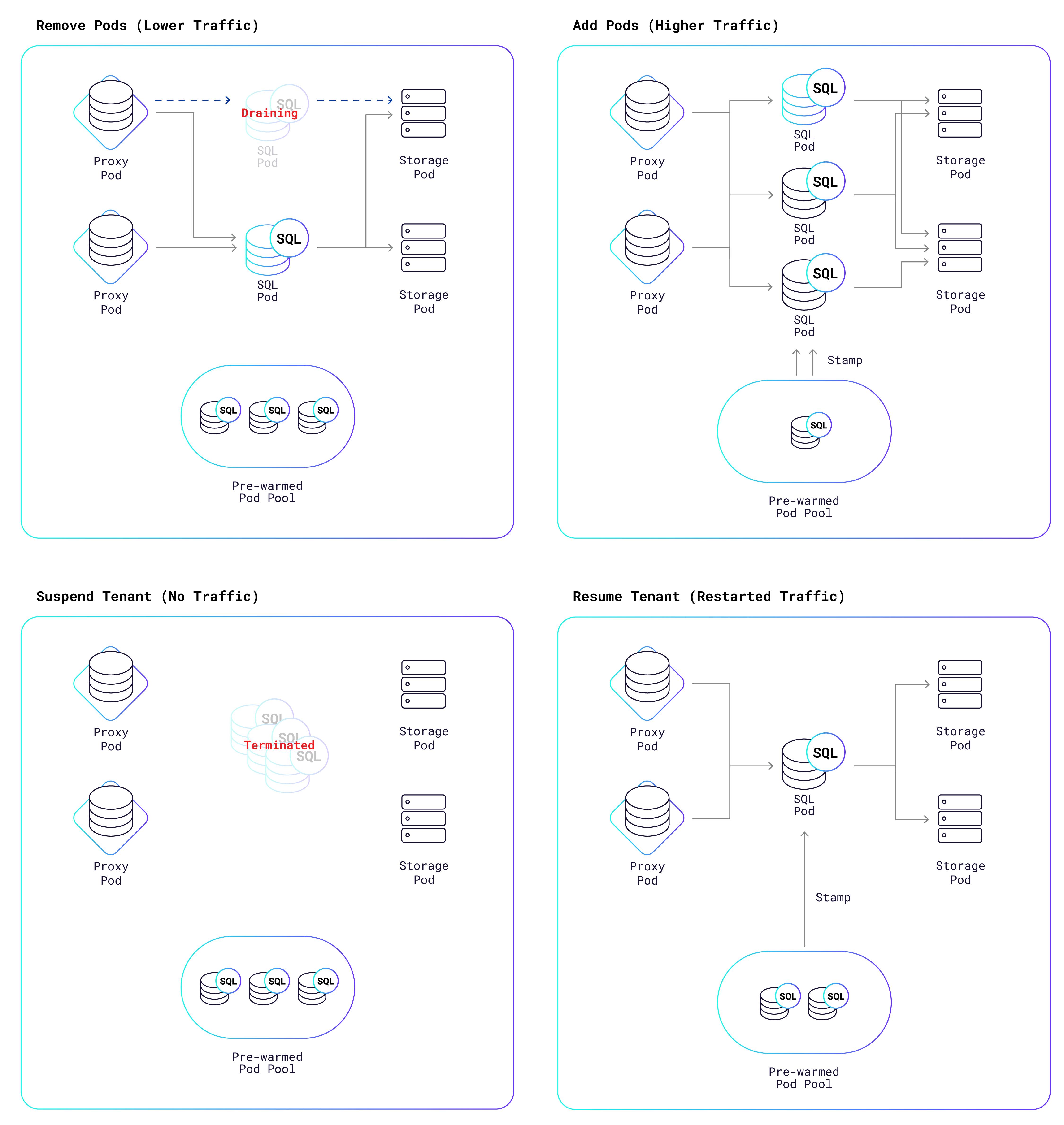
As the diagram shows, we maintain a pool of “prewarmed” pods that are ready to go at a moment’s notice; they just need to be “stamped” with the tenant’s identifier and security certificates. This takes a fraction of a second to do, versus the 20-30 seconds it takes for K8s to create a pod from scratch. If instead, pods need to be removed, they are not abruptly terminated, because that would also result in the rude termination of all SQL connections to that pod. Rather, the pods are put into a draining state, which gives them a chance to shed their SQL connections more gracefully. Some connections might be closed by the application; other connections will be transparently migrated by the proxy from the draining pods to other pods that are still active.A draining pod is terminated once all connections are gone or once 10 minutes have passed, whichever comes first.
If application load falls to zero, then the autoscaler will eventually decide to suspend the tenant, which means that all of its SQL pods are removed. Once the tenant no longer owns any SQL pods, it does not consume any CPU, I/O, or bandwidth. The only cost is for storage of its data, which is relatively cheap compared to other resources. This is one of the reasons that we can offer free database clusters to all of you.
However, there is one problem left to solve. How can a tenant connect to its cluster if there are no SQL pods assigned to it? To answer that question, remember that a set of proxy pods runs in every Serverless cluster. Each SQL connection initiated by an external client is intercepted by a proxy pod and then forwarded to a SQL pod assigned to the tenant. However, if the proxy finds that there are currently no SQL pods assigned to the tenant, then it triggers the same K8s reconciliation process that the autoscaler uses for scaling. A new pod is pulled from the prewarmed pool of SQL pods and stamped, and is now available for connections. The entire resumption process takes a fraction of a second, and we’re actively working on bringing that time down further.
Conclusion
Now that you know how CockroachDB Serverless works, I encourage you to head on over to https://cockroachlabs.cloud/ and give it a try. If you have questions about any of this, please join us in our Community Slack channel and ask away. We’d also love to hear about your experience with CockroachDB Serverless and any positive or negative feedback. We’ll be working hard to improve it over the coming months, so sign up for an account and get updates on our progress. And if you’d love to help us take CockroachDB to the next level, we’re hiring.
Additional Resources
Bring us your feedback: Join our Slack community and let us know your thoughts!
We’re hiring! Join the team building CockroachDB. Remote-friendly, family-friendly, and taking on some of the biggest challenges in data and app development.


