

Reader’s Note: This post references CockroachDB Serverless and/or CockroachDB Dedicated which, as of September 26 2024, have been renamed and incorporated within the new CockroachDB Cloud platform, which you can read more about here.
Since its inception, CockroachDB has relied on RocksDB as its key-value storage engine. The choice of RocksDB has served us well. RocksDB is battle tested, highly performant, and comes with a rich feature set. We’re big fans of RocksDB and we frequently sing its praises when asked why we didn’t choose another storage engine.
Today we’re introducing Pebble.
What is Pebble?
Pebble is a RocksDB inspired and RocksDB compatible key-value store focused on the needs of CockroachDB. Pebble brings better performance and stability, avoids the challenges of traversing the Cgo boundary, and gives us more control over future enhancements tailored for CockroachDB’s needs. In our upcoming 20.2 release this fall, Pebble will replace RocksDB as the default storage engine. This is the story of why we’ve written Pebble, and how we changed such a foundational component of CockroachDB.
Motivation for building a new storage engine
The storage engine is a critical component of a database, providing the foundation for performance and stability. Traditional SQL and NoSQL databases have often been built with their own proprietary storage engines. MySQL uses InnoDB, Postgres comes with internal B-tree, hash and heap storage systems, Cassandra comes with an LSM tree implementation. Recently, some of these databases have added RocksDB backends (e.g. MyRocks and Rocksandra). From a distance, this gives the perception that RocksDB is eating the low-level storage ecosystem. A closer inspection reveals the RocksDB backends for these existing systems come with significant caveats.
When building any complex piece of software, it is impossible to build every component from scratch. Reusing existing components enables faster time to market, and often a better product as domain experts have taken the time to craft and tune the individual components. This was certainly true of our choice to use RocksDB, yet over time the calculation changed. RocksDB is used by many different systems. This wide usage implies significant testing and performance tuning, but it also means RocksDB is serving many masters. We can see the effect of this in RocksDB’s very large feature set and configuration surface area. The RocksDB code base has sprawled over time, growing from LevelDB’s original 30k lines of code to a current state of 350k+ lines of code. Lines of code is an inadequate metric, but these sizes do provide a rough feel for the relative complexities.
RocksDB has been a solid foundation for CockroachDB to build upon. Unfortunately, as CockroachDB has matured we’ve encountered serious bugs in RocksDB. For example, RocksDB had a bug in compaction related code that led to an infinite cycle of compactions for a particular sstable, starving other parts of the LSM tree from being compacted. While the absolute number of bugs we’ve encountered in RocksDB is modest, their severity is often high, and the urgency to fix them is frequently House Is On Fire. This has required Cockroach Labs engineers to dive deep into the RocksDB code base as part of bug investigations. Navigating 350k+ lines of foreign C++ code is doable (we’ve done it), yet hardly what could be described as a good time. CockroachDB is primarily a Go code base, and the Cockroach Labs engineers have developed broad expertise in Go. C++ expertise is much sparser, and the barrier between Go and C++ is psychologically real. The barrier prevents usage of the native Go profile tools from introspecting C++, or from seeing C++ stack traces. We’ve had to write significant amounts of logic in C++ in order to avoid the performance overhead of frequent crossings from Go to C++, at times duplicating logic that already existed in Go.
RocksDB is generally highly performant, but we’ve also encountered significant performance problems. CockroachDB was an early adopter of range deletions, but we were also early discoverers of some performance deficiencies in the first implementation. We upstreamed performance fixes for range deletions and aided in the design of the v2 implementation.
RocksDB is full featured, but sometimes the features have deficiencies. At times we have chosen to work around those deficiencies in CockroachDB code rather than fix them in RocksDB. These decisions were not necessarily made consciously (see above regarding the psychological barrier between Go and C++). An example of such a workaround is the CockroachDB Compactor. The Compactor is used to force compaction of a portion of the data in RocksDB which has recently been deleted via a DeleteRange operation. This allows the disk space to be recovered more quickly than if we did nothing. The need for the Compactor stems from RocksDB not taking range deletion operations into consideration in its compaction decisions. Stepping back from the low-level details, the takeaway is that the storage engine has a critical impact on the functionality and behavior of CockroachDB. Owning the storage layer allows CockroachDB more direct control of its destiny.
A critical reader may point out that several of the points above do not lead to the conclusion of reimplementing RocksDB. We could have instead chosen to build out internal expertise. We could have chosen to fork RocksDB, strip away the parts that we don’t need, and make enhancements tailored to the needs of CockroachDB. This latter approach was given serious consideration, but ultimately we came down in favor of reimplementing in Go as we believe removing the Go / C++ barrier will enable faster development long term.
A final alternative would be to use another storage engine, such as Badger or BoltDB (if we wanted to stick with Go). This alternative was not seriously considered for several reasons. These storage engines do not provide all the features we require, so we would have needed to make significant enhancements to them. The migration story for CockroachDB clusters running RocksDB would have become vastly more complex, making it likely that we’d need to support both storage engines for a considerable amount of time. Supporting multiple storage engines is itself a large endeavor: it dramatically increases the testing surface area, and the alternative storage engines often come with significant caveats (e.g. MyRocks does not support SAVEPOINTs). Lastly, various RocksDB-isms have slipped into the CockroachDB code base, such as the use of the sstable format for sending snapshots of data between nodes. Removing these RocksDB-isms, or providing adapters, would either be a large engineering effort, or impose unacceptable performance overhead.
Building Pebble
Replacing a component as large as RocksDB is a daunting task. We did have a few advantageous factors:
We understood CockroachDB’s usage of RocksDB intimately. Pebble does not aim to be a complete replacement for RocksDB, but only a replacement for the functionality in RocksDB used by CockroachDB. A ballpark estimate is that this reduces the scope of the replacement task by at least 50%. The Pebble code base currently weighs in at a bit over 45k lines of code and another 45k lines of tests. This is a fraction of the RocksDB code size, and a big reason for that is that we’re not replicating all of the RocksDB functionality.
We were not starting from scratch. A Go port of LevelDB was started a few years ago, but never completed. Very little of this starting point remains in Pebble, yet it did lay out the initial skeleton and provide the early code for reading and writing the low-level file formats.
We can refer to RocksDB’s code as an implementation template. For example, while the low-level RocksDB file formats are not formally specified, the RocksDB code provides more than adequate documentation of these formats. Reusing the RocksDB file formats removes a degree of freedom from the Pebble design, but this is not an onerous constraint. This point is about more than just file formats, though. We can take inspiration and ideas from all parts of the RocksDB code.
The API and internal structures of Pebble resemble RocksDB. Pebble is an LSM key-value store which provides Set, Merge, Delete, and DeleteRange operations. Operations can be grouped into atomic batches. Records can be read individually via Get, or iterated over in key order using an Iterator. Lightweight point in time read-only Snapshots provide a stable view of the DB. Internally, the data in Pebble is stored in a combination of Write Ahead Logs (WALs) and Sorted String Table (sstables). Recently written data is buffered in memory in a series of Memtables which are implemented under the hood by an arena-backed concurrent Skiplist. Memtables are flushed to disk to create sstables. Sstables are periodically compacted in the background. Both the compaction mechanics and heuristics in Pebble are similar to those present in RocksDB (at least for the configuration used by CockroachDB).
Anyone familiar with RocksDB internals will see many similarities in the Pebble code. There are also many differences. We’ve documented some of the bigger ones. For example, the range deletion implementation is quite different from the one in RocksDB which enables more optimizations to skip over swaths of deleted keys during iteration. The handling of indexed batches is completely different which enables the Pebble implementation to support indexing of all mutation operations, while RocksDB currently does not (e.g. RocksDB does not support indexing of range deletions in batches). These examples are not meant as a critique of RocksDB. We fully expect some of the good ideas in Pebble to be picked up by RocksDB, just as we’ll continue to pluck good ideas from RocksDB.
RocksDB vs Pebble
Pebble implements the subset of RocksDB functionality used by CockroachDB. We have no aspirations to eventually include every feature in RocksDB. In fact, quite the opposite is true. We intend to filter every feature addition and performance improvement through the criteria of whether it will be useful to CockroachDB. This is a harsh filter for a general purpose key-value storage engine, but that is not Pebble’s goal. So what functionality does Pebble include?
Basic operations: Set, Get, Merge, Delete, Single Delete, Range Delete
Batches
Indexed batches
Write-only batches
Block-based sstables
Table-level bloom filters
Prefix bloom filters
Checkpoints
Iterators
Iterator options (lower/upper bound, table filter)
Prefix iteration
Reverse iteration
Level-based compaction
Concurrent compactions
Manual compaction
Intra-L0 compaction
SSTable ingestion
Snapshots
RocksDB functionality Pebble does not include:
Backups
Column families
Delete files in range
FIFO compaction style
Forward iterator / tailing iterator
Hash table format
Memtable bloom filter
Persistent cache
Pin iterator key / value
Plain table format
SSTable ingest-behind
Sub-compactions
Transactions
Universal compaction style
Some of the items above might cause raised eyebrows. How does Pebble not include support for Backups or Transactions given that CockroachDB provides support for both? CockroachDB’s implementation of Backups and Transactions have never used the Backup and Transaction facilities in RocksDB. Transactions on a local key-value store are not needed to implement distributed transactions. Rather, CockroachDB uses Batches, which provide atomicity for a set of operations, as the base upon which to build distributed transactions.
Bidirectional Compatibility
We decided early on for Pebble to target bidirectional compatibility with RocksDB for the initial release of Pebble. More precisely, Pebble is currently bidirectionally compatible with RocksDB 6.2.1 (the version of RocksDB currently used by CockroachDB) for the subset of RocksDB functionality used by CockroachDB. Bidirectional compatibility means that Pebble can read a RocksDB generated DB, and RocksDB can read a Pebble generated DB. Compatibility with RocksDB enables a seamless migration to Pebble, simply requiring a Cockroach node to be restarted with a new command line flag: --storage-engine=pebble. Bidirectional compatibility enables an additional level of safety: if a problem is encountered when using Pebble, we can switch back to using RocksDB. Bidirectional compatibility also enables an additional level of strictness in testing which is discussed more in the Testing section.
Note that bidirectional compatibility with RocksDB will disappear at some point. Maintaining such compatibility forever is at odds with our desire to enhance Pebble in the service of CockroachDB. Maintaining compatibility with new RocksDB functionality would be an enormous ongoing burden.
Testing a storage engine
The storage engine is the component of a database that is tasked with durably writing data to disk. Bugs in the storage engine tend to be severe, such as data corruption, and data unavailability. Testing of the storage engine needs to be robust.
Testing of Pebble would best be described as layered. The current testing layers are:
Pebble unit tests
Randomized tests (a.k.a metamorphic tests)
Bidirectional compatibility tests
CockroachDB unit tests
CockroachDB nightly tests (a.k.a. roachtests)
Unit Tests
The first layer of testing is a large number of Pebble unit tests. These unit tests aim to test all of the normal cases and the corner cases. Listing out all of the corner cases is a challenging exercise. Even a diligent engineer can miss a corner case. Even more problematic is that small changes to the code can introduce new corner cases. It would be nice to believe we’d identify those new corner cases when making any change, but our experience suggests otherwise.
Randomized Testing
Randomized testing is a solution to the corner case problem that has been embraced in recent years. Fuzz testing is an example of randomized testing that is often used to check parsers and protocol decoders. For Pebble, rather than trying to explicitly enumerate all of the corner cases, we can instead write a test which randomly generates operations. The natural question arises: how do we know if the results of the operations are correct? With fuzz testing we simply look for program crashes. This is also the first line of checks in Pebble’s randomized testing which we further enhance with invariant checks for certain critical internal data structures. Simply looking for crashes and invariant violations is a bit unsatisfying. We’d like to know if the results of the operations are actually correct. Maintaining a separate model for the expected result of the operations is a daunting task as the data model implemented by Pebble is much more than just an ordered map of keys and values due to the presence of snapshots (both implicit and explicit) and range deletions. The solution is metamorphic testing. We randomly generate a series of operations, and then execute those operations multiple times against different configurations of Pebble. The output of the different runs is compared and any differences are a cause for concern. The Pebble configuration knobs that we tweak include the size of the block cache, the size of the memtable, and the target size of sstables. Changing these configuration operations causes different internal code paths inside Pebble to be executed. For example, changing the target size of sstables causes different scenarios in the handling of range deletions. At the time of writing, each instance of the metamorphic test is run against 19 predefined configurations and 10 randomly generated configurations.
We’ve actually implemented two different versions of metamorphic tests. The first operates purely on Pebble APIs and only tests Pebble against itself. You might be thinking: why not also test against RocksDB? We had that same thought. Unfortunately, the Pebble API’s have some slight differences and generalizations in comparison to RocksDB that made this challenging. Instead, we implemented a second metamorphic test that works at the integration layer of Pebble/RocksDB within CockroachDB. This second metamorphic test verifies not only that Pebble and RocksDB produce identical results, but also that the Pebble and RocksDB specific glue code inside CockroachDB produces identical results. The metamorphic tests have proved incredibly useful in finding existing bugs, and quickly catching regressions when new functionality has been introduced.
Crash Testing
A key attribute of a storage engine is to durably write data to disk. In order to provide a useful foundation for higher levels to build on, Pebble and RocksDB allow a write operation to be “synced” to disk, and when the operation completes the caller can know that the data will be present even if the process or machine crashes. Testing crash recovery is an interesting challenge. In Pebble, we’ve integrated crash testing with the metamorphic test. The random series of operations also includes a “restart” operation. When a “restart” operation is encountered, any data that has been written to the OS but not “synced” is discarded. Achieving this discard behavior was relatively straightforward because all filesystem operations in Pebble are performed through a filesystem interface. We merely had to add a new implementation of this interface which buffered unsynced data and discarded this buffered data when a “restart” occurred.
Bidirectional Compatibility Testing
As discussed earlier, Pebble targets bidirectional compatibility with RocksDB. In order to test this compatibility, the metamorphic test was again extended. The “restart” operation was changed to randomly switch between Pebble and RocksDB. This testing has caught several incompatibilities between Pebble and RocksDB, such as Pebble incorrectly setting a property on sstables that caused RocksDB to interpret those sstables differently from Pebble. In addition to compatibility testing in the metamorphic test, we also implemented a CockroachDB-level integration test which mimics what a user might do to verify bidirectional compatibility. This test starts up a CockroachDB cluster, and then randomly kills and restarts nodes in the cluster, switching the storage engine being used.
The types of bugs discovered in this testing varied from trivial differences to the most serious types of data corruption. An example of the latter was an extremely subtle difference in the hash function used by the bloom filter code: extending a signed 8-bit integer to 32-bits results in a different value than extending an unsigned 8-bit integer to 32-bits. This caused Pebble’s bloom filter hash function to produce different values than RocksDB’s bloom filter hash function for a subset of keys (i.e. keys containing a byte with the high-bit set). The origin of this bug is itself interesting. Pebble’s bloom filter hash function was inherited from go-leveldb which was inherited from LevelDB. The original implementation of LevelDB’s hash function had behavior that was dependent on whether the C char type was signed or unsigned (which is controllable via a flag for gcc/clang). That subtle dependency was fixed years ago in both LevelDB and RocksDB, but the dependency slipped back in somewhere in the translation to Go.
Leveraging CockroachDB Testing
The final layers of Pebble testing leverages the existing CockroachDB unit tests and nightly tests. We added an environment variable (COCKROACH_STORAGE_ENGINE) that controls whether CockroachDB unit tests use Pebble or RocksDB. We also implemented another storage engine for an additional level of testing. The Tee storage engine does as its name implies: it tees all write operations to both Pebble and RocksDB. Read operations are directed to both underlying storage engines and compared to ensure the same results are returned.
CockroachDB runs a suite of nightly integration tests known as roachtests. A roachtest spins up clusters on AWS or GCP and performs cluster-level testing. The same COCKROACH_STORAGE_ENGINE environment variable was used to allow running these tests on Pebble.
New Storage Engine Performance
No announcement of a new storage engine would be complete without a nod to performance. Replacing Pebble with RocksDB would be a non-starter if performance was significantly impacted. RocksDB is highly performant, and we had to spend significant effort to match or exceed its performance. The performance surface area of a storage engine is vast, and this post can only touch on a tiny fraction of it. Performance is not just about raw throughput and latency, but also resource consumption, such as CPU and memory usage. At the end of the day, what we care about most is the performance of Pebble vs RocksDB on CockroachDB level workloads.
YCSB is a standard benchmark for examining storage engine performance. It runs six workloads:workload A is a mix of 50% reads and 50% updates. Workload B is a mix of 95% reads and 5% updates. Workload C is 100% reads. Workload D is 95% reads and 5% inserts. Workload E is 95% scans and 5% inserts. Workload F is 50% reads and 50% read-modify-writes. Pebble and RocksDB were configured with similar options (identical where there was overlap). The dataset sizes for all of the workloads fit in memory, though we’ve also performed testing of workloads with datasets that do not fit in cache.

Pebble meets or exceeds RocksDB on the 6 standard YCSB workloads. CockroachDB performance has bottlenecks outside of the storage engine. For a more direct comparison of the storage engine performance, we implemented a subset of the YCSB workloads directly on top of Pebble and RocksDB.
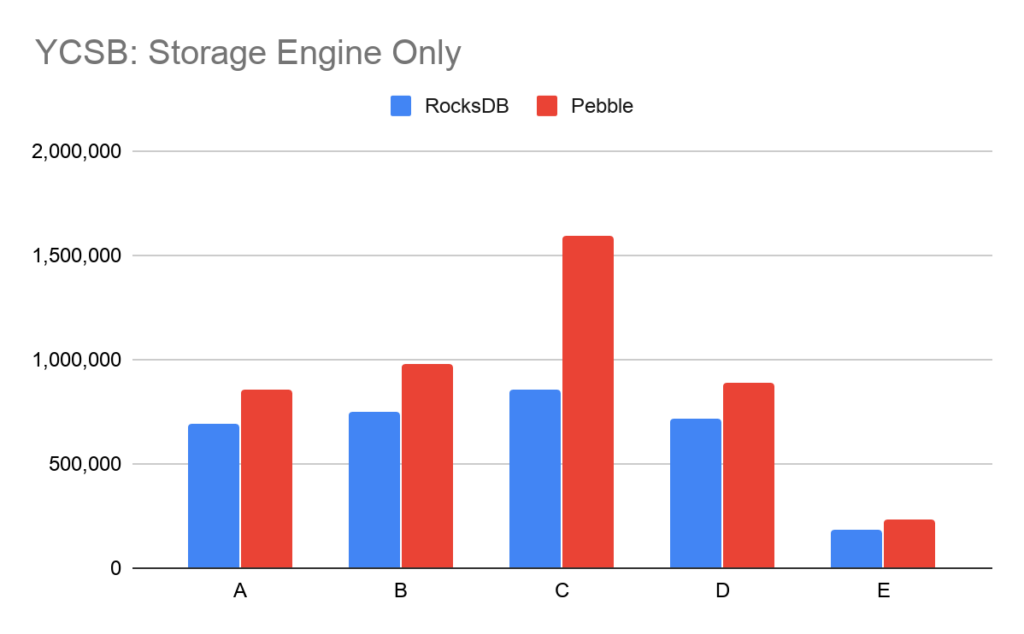
Note that workload F was not implemented in this storage engine only benchmark tool. The large delta seen on workload C is due to better concurrency in Pebble’s block and table cache structures. As can be seen from the CockroachDB-level comparison, the effect of this better concurrency becomes muted when the entire system is considered.
Conclusion and Future Work
The 20.1 release of CockroachDB last May introduced Pebble as an alternative storage engine to RocksDB. We were cautious in this introduction, not publicizing it widely and requiring users to specifically opt-in to using Pebble. We began testing Pebble on CockroachDB Dedicated clusters, first with internal test clusters, and recently with production clusters. We’re now confident in the stability and performance of Pebble. With the release of 20.2 this fall, Pebble will become CockroachDB’s default storage engine. RocksDB remains as an alternative storage engine in 20.2, but its days are numbered and we plan to fully remove it in a subsequent release.
The 20.2 release will also bring enhancements to Pebble. We’ve made improvements to the compaction heuristics and mechanics that significantly speed up IMPORT and RESTORE workloads which were bottlenecked by the storage engine. We’ve incorporated range deletions in the compaction heuristics which have allowed us to get rid of the Compactor workaround in CockroachDB mentioned earlier. These are only the tip of the iceberg for where we ultimately want to evolve Pebble. The storage engine is the foundation of performance and stability in CockroachDB and we plan to continue enhancing Pebble in pursuit of ever greater performance and stability.


