

Competition is good. It focuses your energies. It keeps you sharp and pushes you to be better. At Cockroach Labs we welcome competition. It hasn’t escaped our notice that a new entrant in the database landscape is frequently comparing themselves against us, making claims about their performance and functionality vis-a-vis our own. We decided to take a closer look. This is our analysis of CockroachDB vs Yugabyte v2.0.0. All benchmark comparisons were done with CockroachDB v19.2.0.
TLDR: CockroachDB vs. Yugabyte
On Yugabyte’s custom benchmark we discovered an apples to oranges performance comparison due to the behavior of the benchmark and Yugabyte’s choice to use hash partitioning by default. We unpack why using hash partitioning by default is a dubious choice for a SQL database. After adjusting for these discoveries, CockroachDB outperforms Yugabyte on all of the workloads.
On Sysbench we discovered problems in Yugabyte with schema changes and batching. The schema change problems are architectural and will be challenging to solve. The performance problems with batching look to be solvable with a bit of elbow grease.
On Sysbench we discovered that Yugabyte returns transaction retry errors in situations that neither PostgreSQL or CockroachDB do. These transaction retry errors cause Sysbench to fail to complete on several workloads. We were only able to gather results for Yugabyte on 4 of the 9 Sysbench workloads. CockroachDB can successfully complete all 9 workloads.
On YCSB we compared Yugabyte’s SQL performance to CockroachDB and showed CockroachDB performance is better across all workloads.
We discovered that Yugabyte SQL tables have a maximum of 50 tablets.
We discovered that Yugabyte tablets do not split or merge which requires the operator to make an important upfront decision on their data schema.
We discovered that a Yugabyte range partitioned table is limited to a single tablet which limits the performance and scalability of such tables.
We discovered differences between CockroachDB’s distributed SQL execution which decomposes SQL queries in order to run them close to data, and Yugabyte’s SQL execution which moves data to a gateway node for centralized processing.
We discovered that without application-level coordination Yugabyte schema changes can easily lead to data inconsistencies.
An Initial Look at the Yugabyte Benchmark
Our first step in analyzing Yugabyte’s claims was to take a look at their custom benchmark. The Yugabyte defined benchmark comes with three different workloads:
SqlInserts: sample key-value app with concurrent writersSqlSecondaryIndex: sample key-value app with secondary indexSqlForeignKeysAndJoins: sample user orders app
We set up a 3-node cluster across multiple availability zones on AWS using the c5d.4xlarge machine type, with a 4th node running the benchmark itself (NOTE: this is the same setup we used for all of the benchmarking described in this analysis). When we ran the SqlInserts workload, we saw that Yugabyte’s throughput hovered around 58k qps while CockroachDB’s throughput hovered around 35k qps. Digging in, a quick look at CPU metrics show that Yugabyte is making full use of the 3 node cluster while 2 of the 3 Cockroach nodes are mostly idle. What causes this imbalance?
First off, what is the SqlInserts workload doing? We dove into the source code and found that it is inserting keys in sequential order. This is surprising, as the code specifically mentions that isn’t the case, but sometimes comments become out of date. Regardless, we determined that keys were being written in sequential order to the database, meaning that all writes were going to a single range in CockroachDB. This is a classic case of a write hotspot.
So how is Yugabyte getting such good performance? The short answer is that SQL tables in Yugabyte use "hash partitioning" by default: rows are spread evenly across a cluster by hashing each row key. By contrast, Cockroach uses what is known as "range partitioning": rows are clustered together in chunks that are sorted by key.
One way to think about hash vs range partitioning is that the key-value store in Cockroach is implemented as a distributed balanced tree (most closely resembling a B+ tree) and the key-value store in Yugabyte is implemented as a distributed hash map.
Defaulting to hash partitioning is a dubious choice, as it differs from the PostgreSQL default and the normal expectations for a SQL table. Many NoSQL systems use hash partitioning which is a primary factor in the difficulty of implementing full SQL on top of such systems. The performance difference between hash and range partitioning can vary from modest to significant depending on the workload. Hash partitioning transforms sequential inserts into random inserts, thus providing good load distribution. Reading of specific rows is also fast with hash partitioning. The big caveat to hash partitioning is that any sort of range scan will be very slow. We’ll see this come up in later benchmarks.
Load balancing and load hotspots are fairly common concerns in distributed systems. Even though distributed systems may scale horizontally in theory, developers still need to be careful to access them in ways that can be distributed. In a range partitioned system, load can become imbalanced if it focuses on a specific range of data. In a hash partitioned system, load can become imbalanced if it focuses on a specific hash bucket due to hash collisions. In the SqlInserts workload, we see that all the load is focused on a single range in CockroachDB because the workload was writing to sequential keys. This would be considered an anti-pattern in CockroachDB, and it’s why we recommend avoiding such access patterns in our documentation. CockroachDB offers convenient datatypes like UUIDs to avoid such issues.
Hash partitioning is easy to implement on top of range partitioning, so it’s straightforward to solve the hotspot issue in CockroachDB by prefixing the SQL primary key with a hash of the user-provided primary key (via a computed column). In addition to running CockroachDB in this "Hash" mode, we also configured and ran Yugabyte using range partitioning to allow comparisons of all of the apple varieties against each other. We ran this test and obtained the following results:
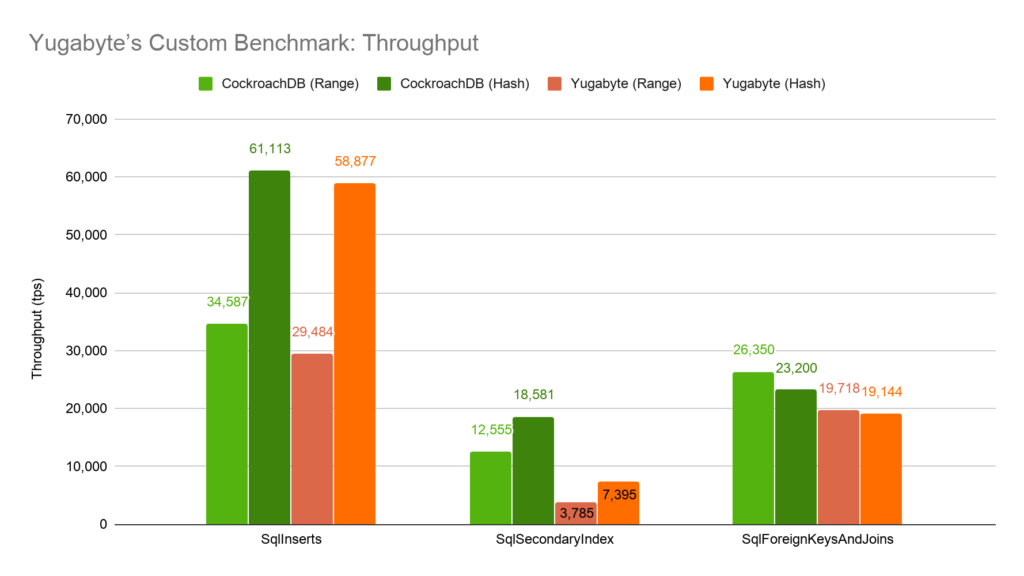
These numbers show that hash partitioning is a clear winner for the insert workloads, though range partitioning delivers the top performance for the SqlForeignKeysAndJoins workload. When comparing apples-to-apples configurations (Range vs Range or Hash vs Hash), CockroachDB outperforms Yugabyte in all three workloads.
Throughput is not the only measure of performance. We also have to consider latency. Latency and throughput are often correlated, though the relationship can become complicated. Higher latency generally corresponds with lower throughput, though a system which accommodates concurrency can upset that generalization. In the following benchmark, we measure average latency at peak throughput. The peak throughput for CockroachDB and Yugabyte depend on the concurrency of the workload. Once that peak throughput is reached, further increases to concurrency only increase latency without providing a corresponding improvement in throughput (in fact, throughput may decrease due to queueing overhead).
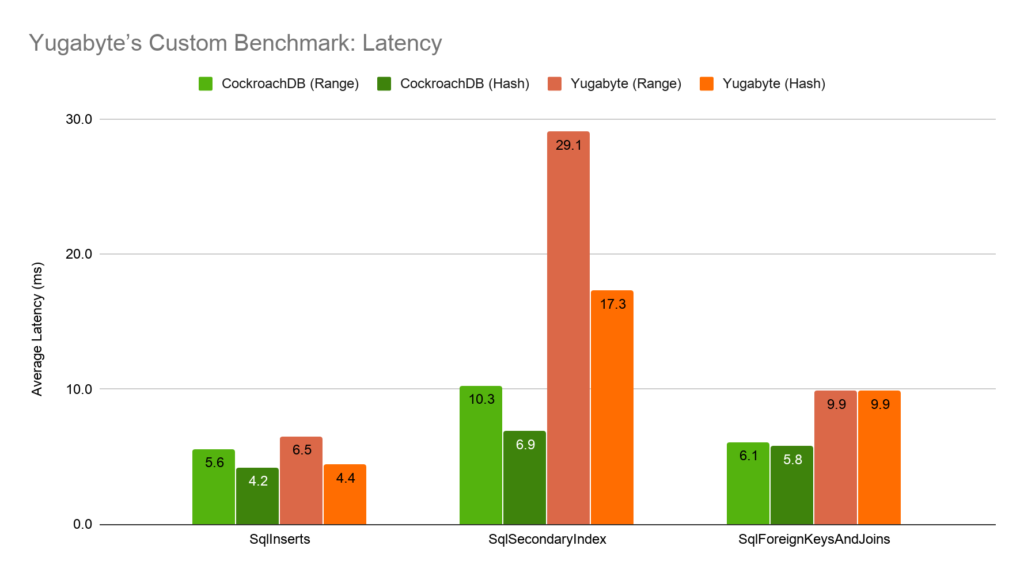
In our experimentation, both CockroachDB and Yugabyte achieved peak throughput on the SqlInserts workload with 192 concurrent workers for range partitioning and 256 concurrent workers for hash partitioning. For the other workloads, both systems achieved peak throughput with 128 concurrent workers. Again, CockroachDB outperforms Yugabyte in all three workloads.
A takeaway from this initial analysis is that benchmarking is hard to do correctly. It is often easy to construct a benchmark which is not testing what you initially set out to test. Databases have particularly complex modes of operation and simple benchmarks are inadequate at best, and better avoided.
Left to their own devices, database vendors often select workloads that produce favorable numbers for their system. Yugabyte went a step beyond that, by creating their own custom, unvetted benchmark, rather than relying on any one of the standard, third-party benchmarks for database systems.
Sysbench
We next turned our attention to Sysbench, a standard benchmarking suite that contains a collection of simple SQL workloads. These workloads perform low-level SQL operations like running concurrent INSERT statements as fast as possible or UPDATE-ing rows as fast as possible.
The idea of the benchmark is primarily to get a picture of the capacity of a system under different access patterns. Unlike TPC-C, Sysbench does not attempt to model a real application, which makes it a poor benchmark for holistic database performance comparisons. However, its popularity makes it worthwhile to take a closer look.
Sysbench is split into the following workloads:
oltp_point_select: single-row point selectsoltp_insert: single-row insertsoltp_delete: single-row deletesoltp_update_index: single-row update on column that requires update to secondary indexoltp_update_non_index single-row: update on column that does not require update to secondary indexoltp_read_only: transactions that run collection of small scansoltp_read_write: transactions that run collection of small scans and writesoltp_write_only: transactions that run collection of writes
Sysbench: Data Loading
Running a sysbench workload is split into two stages. First, we create the schema and load a dataset into the cluster. Next, we run the workload. Each workload has slightly different data loading requirements. We started with oltp_point_select and loaded a dataset with 10 tables and 1,000,000 rows per table. On CockroachDB, the data loading finished in 30s.
On Yugabyte, we ran into problems. The first problem was a "Catalog Version Mismatch" error that we tracked down to being caused by performing multiple schema changes at the same time. To understand this problem we have to take a detour.
<< Watch now: Distributed SQL Architectures >>
CockroachDB and Yugabyte are both distributed SQL databases that strive for PostgreSQL compatibility, though they have taken different roads to that goal.
CockroachDB: Distributed SQL Execution
CockroachDB implements a fully-distributed SQL engine, including both optimization and execution. The SQL implementation has been architected and built from the ground up to work on top of CockroachDB’s internal distributed KV store. The from scratch implementation allows the execution of SQL to be distributed by decomposing a query into parts that can be executed anywhere in a cluster, usually as close to where the data is stored as possible. This enables CockroachDB to exploit the aggregate compute resources of the cluster for executing a single query. CockroachDB delivers a "code-shipping" instead of a “data-shipping” architecture. This is of vital importance in a distributed architecture.
Yugabyte: Monolithic SQL Execution on a Distributed KV Store
Yugabyte uses PostgreSQL for SQL optimization, and a portion of execution. The integration with PostgreSQL is done by adding a new LSM (Log-Structured Merge tree) access method to PostgreSQL, and replacing PostgreSQL’s normal heap storage system with Yugabyte-implemented routines. (Note that in this context, heap storage refers to the on-disk structure used to store table data, not to the in-process component for managing memory). Both the LSM access method and heap storage are implemented on top of Yugabyte’s DocDB distributed KV store. Yugabyte has modified PostgreSQL so that the normal BTREE and HASH access methods are redirected to the LSM access method. Using PostgreSQL in this manner allows Yugabyte to add SQL support without implementing distributed SQL. However, implementing a new access method for PostgreSQL is not a trivial task, and Yugabyte’s current implementation doesn’t yet provide the same semantics as the builtin Postgres access method. Rather than a distributed SQL database, Yugabyte can be more accurately described as a monolithic SQL database on top of a distributed KV database.
The "Catalog Version Mismatch" problem noted above is related to these architectural differences and is the result of schema change issues. It is a direct consequence of their decision to use the PostgreSQL frontend. Because PostgreSQL is not distributed, its only link to other concurrently running PostgreSQL frontend processes is through the LSM access method to the Yugabyte backend. There’s no coordination during schema changes, which leads to problems like the “Catalog Version Mismatch” error, and can also be demonstrated via a simple script which runs a schema change on one node and a concurrent operation on another node. Because there is no coordination, the two operations can conflict. Below is a simple script with two clients talking to two Postgres server instances that highlights this issue:
What happened? We created a table, added some data, and then added an index. While the index was being added, we concurrently inserted into the table on another node. The end result was an index that is out of sync with the main table data. Handling schema changes online is possible, though it requires significant engineering effort. With CockroachDB, the above script, and any other contrived example you can think of, perform correctly without locking any tables, using online schema changes.
Data Loading Redux
Given Yugabyte’s limitations with concurrent schema changes, we have two options in running Sysbench: we either a) load with a concurrency of 1 to side-step the issue or b) we abandon running across multiple tables (multiple tables are the norm for sysbench). Since the data load step would take too long to load with a concurrency of 1, we opted to run with only a single table. To maintain the same number of rows, we must increase to using 10,000,000 rows in the table. CockroachDB completed the data loading in 2m42s. After 30m, we cancelled the load with Yugabyte. We reduced the number of rows to 1,000,000. At 1,000,000 rows, CockroachDB’s load completed in 28s, Yugabyte’s in 39m.
What explains this significant performance difference in load times? During the loading phase, Sysbench issues INSERT statements with 2000 rows each. That is, there is a single INSERT statement specifying 2000 rows via a VALUES clause. On Yugabyte, the performance of the INSERT statement appears to slow down linearly with the batch size. We ran some experiments here and verified this by loading 1000 rows and 2000 rows with a concurrency of 1. After subtracting out the table creation time, the former took 9.3s and the latter took 16.2s.
The Yugabyte code (see ExecModifyTable) loops over the rows to be inserted and performs the inserts one at a time. There is no fundamental reason for this lack of batching; Yugabyte will likely address this with time, though this example serves to highlight the large performance surface area of a SQL database. Single row inserts can be fast, while multi-row inserts are comparatively slow. In CockroachDB, batching is performed whenever possible, as reducing network operations is a big part of optimizing performance in a distributed database.
For completeness, here are relative loading times we measured between the two systems.
To keep the loading times reasonable, we decided to run the Sysbench tests with very small tables containing only 100,000 rows.
Running Sysbench Workloads
For each workload, we wiped the clusters, loaded the data, ran the benchmark for a 2 minute warmup period to prime the system, and then ran for the official 2 minutes. We ran the benchmarks both with and without secondary indexes. Note that priming the system with a ramp period is important for a number of reasons: populating data caches, populating metadata caches, and in CRDB allows load-based splitting and rebalancing to occur.
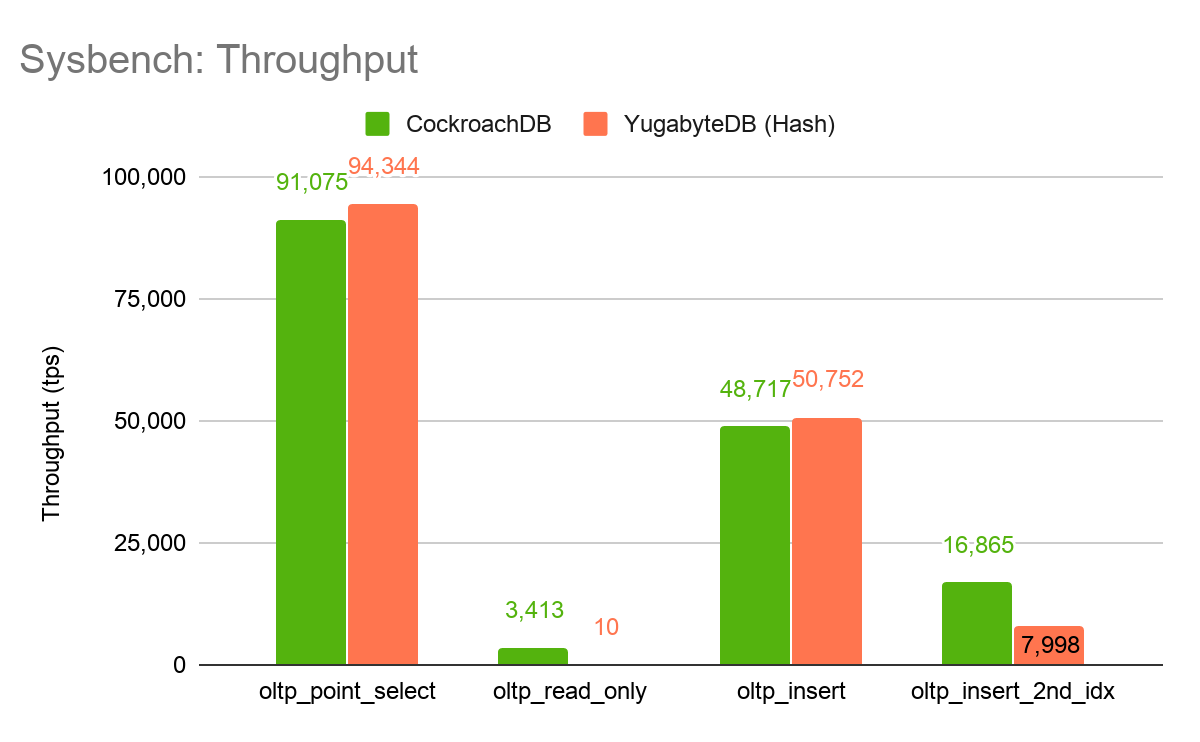
The first thing to notice is that this chart only lists 4 workloads, instead of the 9 mentioned earlier. The reason for this is because any Sysbench workload that runs UPDATE statements causes retryable errors to be returned from Yugabyte, even when these errors are hit in single-statement transactions. The PostgreSQL client used by Sysbench cannot handle these retryable errors. Also note, for the workloads we could run, we used snapshot isolation for Yugabyte as this is their default. We use serializable isolation for CockroachDB.
CockroachDB makes every effort to avoid returning retryable errors to the client when they can be retried transparently by the database. This is difficult for Yugabyte because they don’t have full control over their SQL engine (i.e. the PostgreSQL frontend). We saw errors with Yugabyte running the oltp_update_index, oltp_update_non_index, oltp_read_write, and oltp_write_only workloads so we’ve excluded them from the remainder of this analysis.
Ignoring those issues, we looked at each of the four workloads that Yugabyte can run. The first workload is oltp_point_select. This workload runs SQL statements that look like SELECT c FROM t WHERE id=?. Remember that because we’re running on such a small dataset, all of these lookups should hit RocksDB’s block cache in both databases. Yugabyte’s performance slightly edges out CockroachDB’s.
The oltp_insert workload runs SQL statements that look like INSERT INTO c VALUES (...). Again, Yugabyte’s throughput is slightly higher than CockroachDB’s. Overall, Yugabyte does an admirable job with these single row reads and writes.
The oltp_insert_2nd_idx workload is similar to the oltp_insert workload except that there is a secondary index on the table being inserted into. In both Yugabyte and CockroachDB, this results in the implicit transactions surrounding the INSERT statements becoming distributed transactions which voids the single-range/single-tablet transaction fast-path both systems contain. CockroachDB’s throughput in this workload is significantly higher than Yugabyte’s. This is evidence that CockroachDB’s transaction commit protocol is significantly more efficient for such cross-range/tablet transactions which has a significant impact on real world applications.
Finally, let’s take a look at oltp_read_only workload. This workload is one of three sysbench workloads that run multi-statement transactions (the other two hit retryable errors). The transactions in this workload are a combination of the following five statements:
SELECT c FROM t WHERE id=?
SELECT c FROM t WHERE id BETWEEN ? AND ?
SELECT SUM(k) FROM t WHERE id BETWEEN ? AND ?
SELECT c FROM t WHERE id BETWEEN ? AND ? ORDER BY c
SELECT DISTINCT c FROM t WHERE id BETWEEN ? AND ? ORDER BY c
CockroachDB’s performance is 340x higher than Yugabyte’s. Why is this? Well, this is where hash partitioning reveals its weakness. Due to the use of hash partitioning, simple range scans as performed by oltp_read_only turn into table scans.
To complete the picture, we hacked up some scripts so that we could use range partitioned tables in Yugabyte.
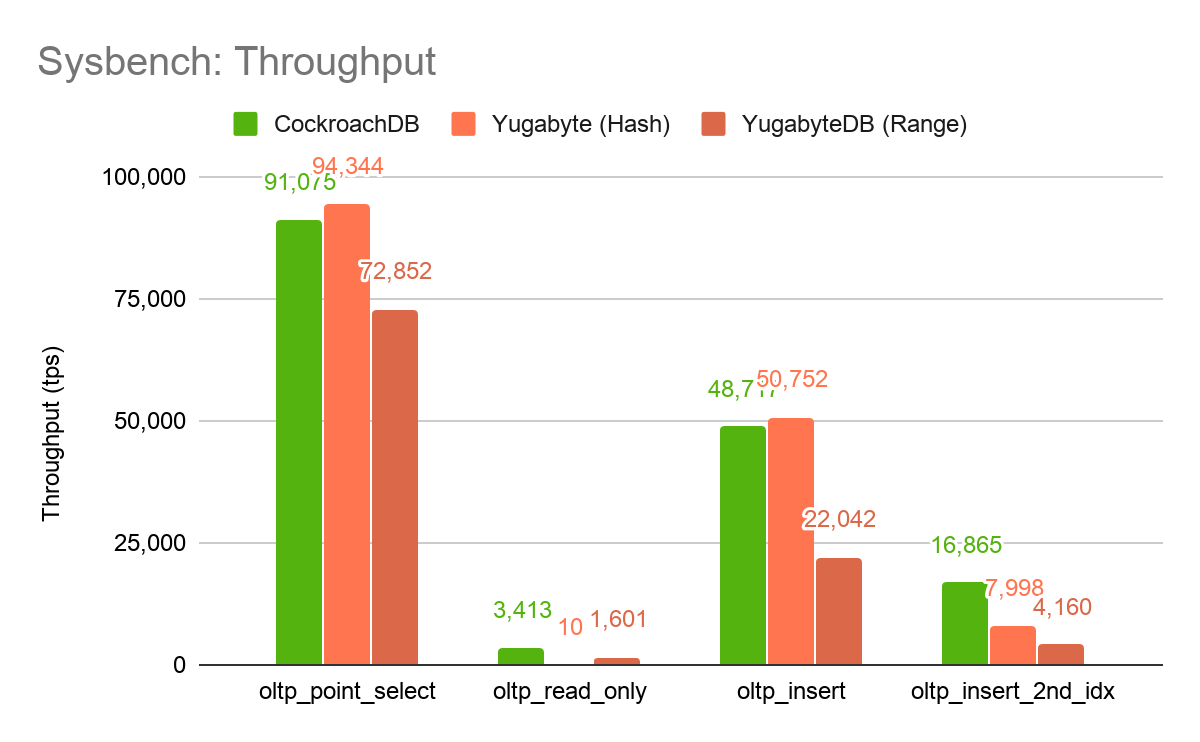

As expected, Yugabyte’s performance on oltp_read_only increased significantly because it could now take advantage of the ordered primary key index. Unfortunately, that improvement came at the price of significantly reduced performance on the other workloads. Again, when both systems are using range partitioning, CockroachDB exhibits significantly higher throughput across all workloads.
Large Scans
We saw in the previous tests that the performance of ordered scans was dramatically impacted by the choice of partitioning scheme used in Yugabyte. Range partitioning resulted in significantly faster scans than hash partitioning. This is why CockroachDB chose range partitioning as its default scheme.
The oltp_read_only workload provides the ability to adjust the size of the scans that it performs through its --range_size flag. The flag defaults to 100 rows, but other sizes of scans are also of interest. Using the flag and variable table sizes, we re-ran the tests to get an understanding of how each partitioning scheme performs and scales across total table size and scan size. This resulted in the following output:
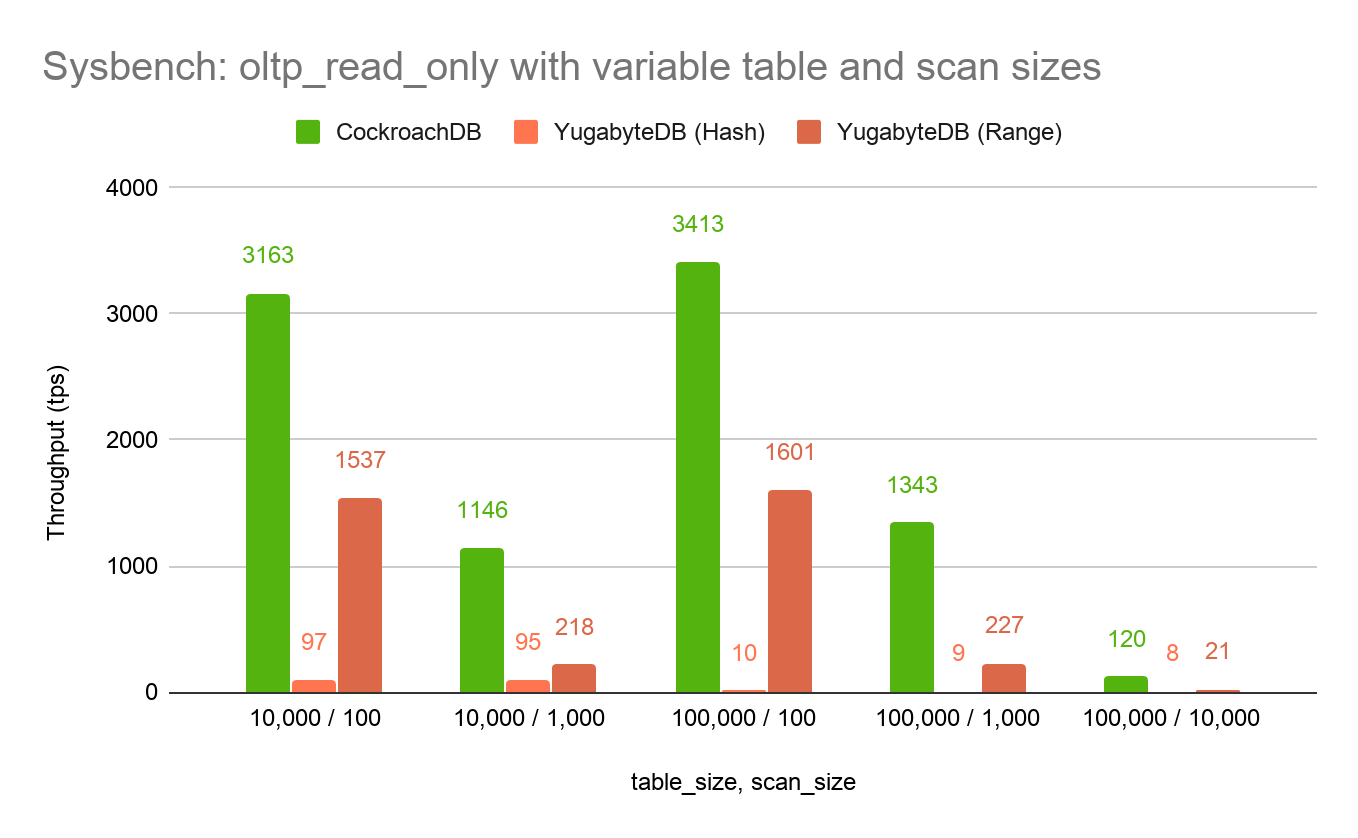
There are a few takeaways from this experiment:
Hash partitioning causes the cost of scans to scale linearly with respect to the size of the table. We can see this because the throughput is constant when using hash partitioning for a given table size. However, the throughput scales inversely proportional to the table size. Growing the table from 10k rows to 100k rows reduces throughput by 10x. This is what we would expect from a hashing structure, because even small scans need to scan every single row.
Range partitioning causes the performance of scans to scale linearly with respect to the size of the scan. We can see this because the throughput is roughly constant when using range partitioning for a given scan size. However, the throughput scales inversely proportional to the scan size. This is what we would expect from an ordered structure, where only the requested rows are scanned.
CockroachDB outperforms Yugabyte with either partitioning scheme across the board. This is especially true on large scans, where the difference grows to 6x the throughput.
YCSB

The Yahoo! Cloud Serving Benchmark is another industry standard benchmark that is interesting to look at. The benchmark, which was originally introduced with this paper, is often used to compare relative performance of NoSQL, but has grown to benchmark a wide range of database systems.
During this comparison, we used the YCSB implementation built into CockroachDB’s workload tool. The implementation has been built to mirror the official YCSB workload as faithfully as possible, but these results should be understood as not using the official YCSB workload tool.
Yugabyte has published YCSB numbers, but only when using their CQL (Cassandra Query Language) interface. We’ve restricted our analysis to SQL vs SQL in order to provide an apples-to-apples comparison.
SQL on top of KV
The only modification made specifically for CockroachDB was the option to configure the workload’s table with a column family per column. What is a column family?
In CockroachDB, by default a row in a SQL table becomes a single key/value record. The columns that are part of the primary key for the table are encoded into the KV-level key, and the remaining columns are encoded into the value. Column families can be specified at table creation time to group columns into separate key/value records which can be used to reduce contention, and to reduce write traffic if only a portion of a row is frequently modified. The default of a single key/value record per row provides better read performance in common workloads.
In Yugabyte, a row in a SQL table becomes N key/value records where N is the number of columns that are not part of the primary key. The columns that are part of the primary key are encoded into the prefix of the KV-level key, and the column’s ID is encoded as the suffix. The column value is stored in the KV-level value. Using N key/value records per row negatively impacts scan speed. Using a column family per column is the recommended way of running YCSB against CockroachDB. Doing so actually eliminates a difference between CockroachDB’s and Yugabyte’s defaults.
YCSB Results
As mentioned above, we configured CockroachDB to use column families. This is an important optimization for heavily contended workloads like YCSB’s workload A, where it can reduce interactions between transactions that operate on disjoint columns in a row. Without this configuration, CockroachDB’s performance on workload A drops roughly in half (\\\\\\\~14k). However, its performance increases on workloads C and D (\\\\\\\~90k on C and ~80k on D). This demonstrates some of the tradeoffs with using column families. Yugabyte doesn’t provide this configuration and always behaves as if every column is placed in its own column family.
TPC-C
With any benchmark, the composition of the workloads that are tested have a huge impact on the results. This is why self-created benchmarks are highly susceptible to tampering. In response to this, the database industry came together to create the Transaction Processing Council (TPC) benchmarks.
TPC, an industry consortium, created a benchmark specifically for OLTP workloads called TPC-C. Despite being created in 1992, it’s still the most mature and relevant industry standard measure for OLTP workloads. The TPC benchmarks are far more rigorous in their specification than other benchmarks, even YCSB and Sysbench which we used above. While TPC-C was developed years ago it has withstood the test of time.
"Good benchmarks are like good laws. They lay the foundation for civilized (fair) competition." - tpc.org
We run TPC-C nightly as part of our standard testing of CockroachDB, and we periodically test to see where our performance envelope lies. We’ve demonstrated steady progress, hitting 10k warehouses in March, 2018, then 50k warehouses in November, 2018. In our most recent measurement we reached 100k warehouses.
In TPC-C, higher performance numbers require scaling both the throughput and the dataset size while adhering to latency requirements. The cumulative effect is to stress multiple facets of a database. Unfortunately, running TPC-C is a complex endeavor. TPC-C is not actual software, but a specification for a benchmark with requirements on the operations to be performed, the size of the data, the randomness of the data, and the randomness of the operations.
CockroachDB’s implementation of TPC-C utilizes functionality not present in Yugabyte and we made a determination that porting it to work on Yugabyte and doing the requisite work to tune Yugabyte for TPC-C was beyond the effort we were willing to invest.
Architectural Differences
We’ve already highlighted a few architectural differences between CockroachDB and Yugabyte but we came across several more while performing the above benchmarks.
SQL tables and indexes are broken down into ranges (CockroachDB) and tablets (Yugabyte). Ranges/tablets are replicated via Raft. Distributed transactions are provided across arbitrary ranges/tablets. Replicas of ranges/tablets store data in RocksDB (a single-node key-value store). (*Since this post was published, CockroachDB built their own open source KV store called Pebble. Pebble is inspired by RocksDB, but more closely aims at the distributed SQL needs of CockroachDB.)
CockroachDB is a single binary (cockroach) which acts as the SQL gateway, SQL execution engine, and KV storage system. Yugabyte is composed of 3 processes: postgres, yb-master, and yb-tserver (tablet server). The postgres process performs SQL execution, while the yb-master and yb-tserver processes implement the distributed, transactional KV store (DocDB). The yb-master process handles cluster wide metadata such as the location of tablets. The yb-tserver (a.k.a. yb-tablet-server) process handles tablet operations and replication.
Ranges vs. Tablets
In CockroachDB, ranges split, merge, and rebalance automatically throughout the cluster in order to adjust to the workload. A SQL table is composed of 1 or more ranges. Data within a table is range partitioned which means that adjacent rows in a table or index become adjacent records in the ranges. Ranges are indexed which allows tables and indexes to be scanned in the order defined by the indexed columns.
Yugabyte tablets rebalance automatically in the cluster in response to node outages, but they have no provision for splitting or merging. The number of tablets for a table is set at table creation time and is currently unalterable afterwards. The default number of tablets for a table is twice the number of tablet servers in the cluster, though this is configurable via extensions to the CREATE TABLE syntax. There is currently a maximum of 50 tablets per table, though it is unclear what the fundamental factors behind that limit are.
As noted above, Yugabyte defaults to hash partitioning for tables and indexes. With hash partitioning, logically adjacent rows in a table can map to different tablets. This default differs from the PostgreSQL default and may cause significant user surprise. Hash partitioned tables are fast for single key lookup, but extremely slow if a range scan is performed. A range partitioned table can be requested by indicating the sort direction for a column in an index (either ASC or DESC). Range partitioned tables improve range scan performance, but come with a large caveat at this time: range partitioned tables can only have a single tablet. This means that entire range partitioned table is stored on a single machine, limiting both the size and performance of the table.
As mentioned earlier, hash partitioning can be built on top of range partitioning, but the reverse is not true.
Transactions
Yugabyte’s DocDB provides support for distributed transactions. The functionality and limitations of the DocDB transactions are directly exposed to SQL. For example, DocDB transactions provide no pessimistic locks for either read or write operations. If two transactions conflict, one will be aborted. This behavior is similar to the original CockroachDB transaction support. Correctness is simple, but performance is problematic under contended workloads. Besides performance, aborting one of the transactions during conflicts requires the application to add retry loops to their application code. CockroachDB now has a pessimistic locking mechanism to improve the performance under contention and to reduce user-visible transaction restarts.
The general structure of distributed transactions in CockroachDB and Yugabyte is similar. Transactions have an associated transaction record stored in a KV record. Writes performed within the transaction add a marker to the written row (intent in CockroachDB, provisional write in Yugabyte). The transaction is committed via flipping the commit bit in the transaction record which can be done atomically via a Raft write. After the transaction record has been marked as committed, the intents / markers are cleaned up asynchronously.
The above transaction protocol is correct, but it suffers from multiple Raft consensus round-trips: one per statement in the transaction. CockroachDB’s current protocol has parallelized every step except the cleanup of intents. In CockroachDB 19.2, a multi-statement distributed transaction can be committed with the latency of a single Raft consensus round-trip (multiple Raft consensus operations are performed in parallel).
Database Schema Changes
In CockroachDB, schema changes are performed asynchronously via the same bulk loading mechanisms that are used for restore and import. Adding an index is done via a distributed operation which scans the rows of the table and builds up a series of RocksDB sstables which are ingested. Building sstables externally from RocksDB and then ingesting them is significantly faster than going through the front door and performing normal RocksDB write operations. In CockroachDB, schema changes are "online": data in the table can be manipulated (rows added or deleted) while the schema change is taking place. This is accomplished by carefully controlling the caching of table metadata on each node and decomposing a schema change into steps for which it is valid to have different versions of the metadata in use at the same time.
In Yugabyte, schema changes are performed via the normal PostgreSQL access method interface. For example, adding an index performs a scan on the PostgreSQL frontend of the existing rows in the table and for each row adding an entry to the index. The addition of each row is performed via an RPC to Yugabyte’s DocDB. In Yugabyte, schema changes need to be coordinated by the application. Concurrent addition of an index on one node and modifications to a table on another node can result in an inconsistent index.
Conclusion
CockroachDB is a production-ready, distributed SQL database, architected to provide high levels of performance, correctness, and stability. Yugabyte is a SQL database grafted onto a distributed KV database. The above analysis details performance of the two systems on a variety of benchmarks, unpacking Yugabyte’s claims and showing the architectural differences between the two systems.
Note: We will publish reproduction steps for the primary tests in this document and will update this post as soon as they are available.


