

CockroachDB debuted as the open source database that made it possible to build massive, reliable cloud applications without giving up SQL. Forward-thinking companies adopted it to hide the complexity of dealing with distributed scale, resilience, and consistency problems in the database layer. The promise was simple: keep your apps simple and your pagers silent. Over the last six months, we’ve welcomed Mesosphere as a customer and helped companies like Kindred and Baidu continue to migrate internet-scale workloads onto CockroachDB. We’ve also watched our distributed SQL database enable exciting new use cases, from a blockchain solution for certifying document authenticity to a system of record for tracking simulations that help optimize oil and gas exploration.
Since our 1.0 release, we’ve heard from our users that changes in everything from the countries where they do business to their users’ ever-growing requirements are causing them to rethink how they build and deploy applications. Developers have figured out how to design scalable and adaptable stateless services. However, many still rely on monolithic relational databases for application state. Whether deployed via a DBaaS or on-prem, these databases are stalling growth as applications ultimately depend on a hard-to-update, single point of failure that can’t take advantage of the nearly unlimited, on-demand resources available in the cloud.
In this post, we highlight how CockroachDB 2.0 enables your data layer to evolve with your business: JSON enables rapid iteration in response to changing customer requirements; major throughput and scalability improvements help you handle huge increases in user request volumes; and a groundbreaking toolkit for managing multi-regional workloads lets you deliver low-latency applications to customers anywhere in the world.
Adapting to changing requirements
First, we’ll cover CockroachDB 2.0’s native support for semi-structured data. Early in your company or project’s life, you need to quickly adjust to frequently changing customer requirements, tweaking your data model and prototyping new features to iterate your way to success. As your project grows, you’ll need to strike a balance between the need for updates and the need to minimize downtime. CockroachDB helps shift that balance back towards shipping by adding support for JSON.
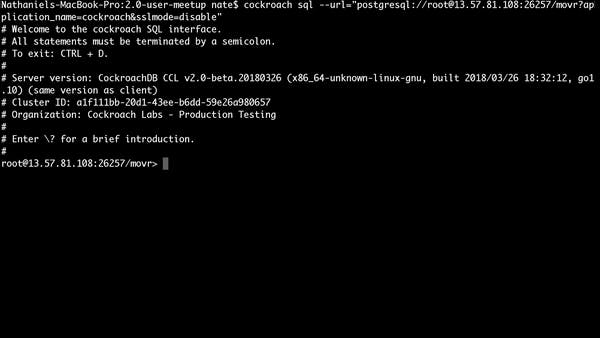
Querying JSON data using Postgres syntax.
JSON data types helped NoSQL databases become the top choice among many fast-moving teams that needed to avoid elaborate design planning and expensive schema migrations in order to adopt a more agile development approach. CockroachDB 2.0’s Postgres-compatible JSON implementation includes a slew of operators for doing in-place transformations and, importantly, inverted indices to speed up queries on giant volumes of data without having to map out the types of requests you want to process ahead of time.
When you combine JSON support with its capability for making zero-downtime schema changes, CockroachDB 2.0 becomes a powerful tool for supporting swift development and rapid prototyping, even for mission-critical systems.
Adapting to fast growth
Next, we review CockroachDB 2.0’s huge performance and scalability improvements. As a developer, fast growth can be a mixed blessing. On one hand, you’ve built something people genuinely want; on the other, this new level of demand is often accompanied by sleepless nights as the increased volume highlights the different ways your previously stable system breaks down at scale. Many cloud-native relational databases can scale to support certain types of queries by adding special servers that exclusively handle reads, while restricting all writes to a single, master node; if you ever need to scale writes, you must bring down your database while scaling up the master instance to a more powerful machine.
Since its 1.0 release, CockroachDB does something much different: to scale out, developers just add more nodes to the cluster. CockroachDB nodes self-organize to balance reads and writes while simultaneously guaranteeing the highest level of data integrity in the SQL standard. With our 2.0 release, we believe CockroachDB offers the best scalability and correctness tradeoffs available in any database. In a previous post, we showed how 2.0 increased our throughput and lowered latency on TPC-C, the industry standard for testing real-world transactional throughput. Today, we’re sharing the results of our first competitive benchmark.
TPC-C models a retailer with active warehouses that deliver orders, process payments, and monitor stock levels. This benchmark helps determine just how big a company’s database can get while maintaining max throughput before the system buckles (and fictional customers head to competitors). Take Amazon Aurora, for example: they maintain max throughput to 1,000 warehouses, but by the time they get to 10,000 warehouses, their reported throughput hits a wall, falling below even their 1,000 warehouse levels. CockroachDB maintains max throughput through 10,000 warehouses; that’s ten times Amazon Aurora’s highest reported limit!

CockroachDB outperforms Amazon Aurora by a wide margin on an industry-standard benchmark.
The TPC-C example shows how CockroachDB 2.0 helps you adapt to growth without altering your architecture. Because CockroachDB enables no-downtime scaling out to support huge increases in read and write traffic, you can start thinking about capacity planning as a just-in-time activity, rather than something that must be forecasted months or years in advance.
You can read more about CockroachDB’s performance characteristics and our benchmarking methodology in our performance whitepaper to be released next week.
Adapting to global user interest
Finally, let’s explore CockroachDB 2.0’s expanded capabilities for working with multi-regional data. Services are often launched with a relational database deployed to a single, high-powered VM located in a public cloud provider’s regional data center. However, as the breadth of the customer base grows, maybe from a US-only audience to a global one, operators experience a growing chorus of complaints about remote customers’ long wait times, as requests must travel from the customer all the way to their data, which may be an ocean away. Lowering end-to-end response times by liberating data from being locked into a single region requires resources and expertise that are prohibitively expensive for most companies. However, with CockroachDB 2.0 Enterprise, we’ve added two significant features that make it easy for teams of all sizes to adapt to multi-regional demand.
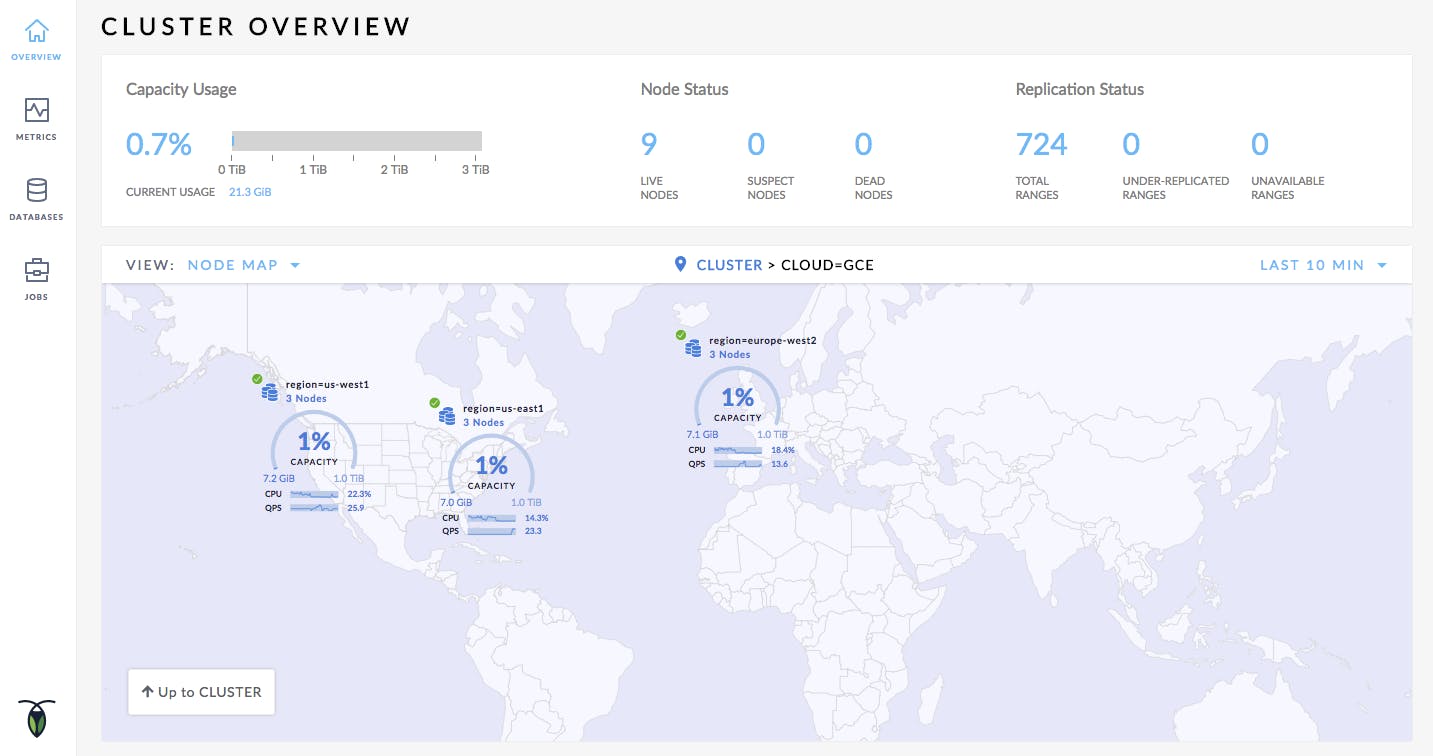
New visualization for geographically distributed clusters.
First, we’ve added support for new ways to visualize globally distributed clusters. As you move data from a monolithic server to distributed servers closer to your users, new types of operational considerations emerge. One example is the role physical distance between nodes plays in determining how quickly writes become durable via our distributed consensus algorithm. Our new cluster dashboard helps you quickly answer these questions, letting you drill down from regional summaries to individual nodes, getting hints on performance bottlenecks and stability problem areas along the way. This dashboard is an easier way to resolve production problems in global clusters, keeping your multi-regional cluster running smoothly, and your customer response times fast.
We’ve also added Geo-partitioning, an incredibly powerful feature that lets you control where your data lives at the individual record level. With geo-partitioning, you create policies that, for instance, pin a customer’s data in the closest datacenter to keep end-to-end latencies low. Another great use case for geo-partitioning is keeping all data associated with customers from a particular country (or countries) in data centers in that same region. This is a powerful building block that’s already helping Kindred build architectures that simplify EU GDPR compliance.
Below is a simulation highlighting how multi-regional data can self-organize with Geo-partitioning. You’ll find an interactive version of this demo here.
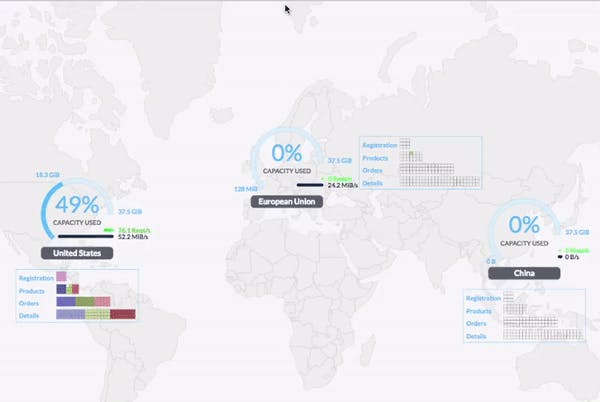
Geo-partitioning allows developers to control which records live in which regions.
CockroachDB 2.0 is the only database that provides fine grained control over, and visibility into, distributed, relational data without incurring downtime or re-architecture as your business grows. It’s the only relational database designed to serve a global customer base while remaining nimble enough to adapt to shifts in data domiciling requirements as they inevitably arise.
A more adaptive relational database
We built on CockroachDB 1.0’s promise of providing a distributed SQL database with stability and correctness as its core value proposition and made tremendous scalability and flexibility enhancements. CockroachDB 2.0 has the performance and functionality to help your team adapt to a changing customer base at every stage of your company’s growth.
CockroachDB 2.0 is an exciting leap forward in our mission to make data easy. It gives you the capabilities described above while working equally well in private, public, or hybrid cloud environments. CockroachDB’s shared-nothing, symmetric architecture makes it simple enough to deploy manually, and also a natural fit for orchestrated environments. We hope you’ll build the next great application with the time saved in architecture meetings, downtime planning, and middleware management – or maybe get just a little more sleep!
--
These are just a few highlights from our 2.0 release. You can the full list of updates in the release notes.
--
Illustration by Rebekka Dunlap.


