

Cockroaches first evolved more than 300M years ago, and yet the O.G. is still recognizable. "Modern" cockroaches are about 200M years old; that they're still with us, largely unchanged, is quite impressive from an evolutionary perspective.
Like its namesake, CockroachDB embraces elegant evolution -- of your application and of your business. CockroachDB allows your business to evolve gracefully as it grows, without requiring a re-architecture or significant migration. It scales elastically using commodity resources, has integral high availability, can geographically replicate data for global access, and provides an industry-standard SQL API.
I've created a D3 simulation (scroll down) which illustrates how CockroachDB can be deployed as the central OLTP component of an application's data architecture. There are five stages of deployment shown here, from proof-of-concept to global scale.
How to use the demo
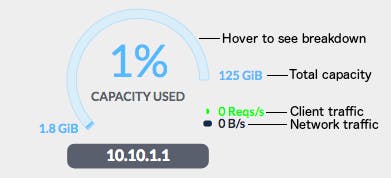
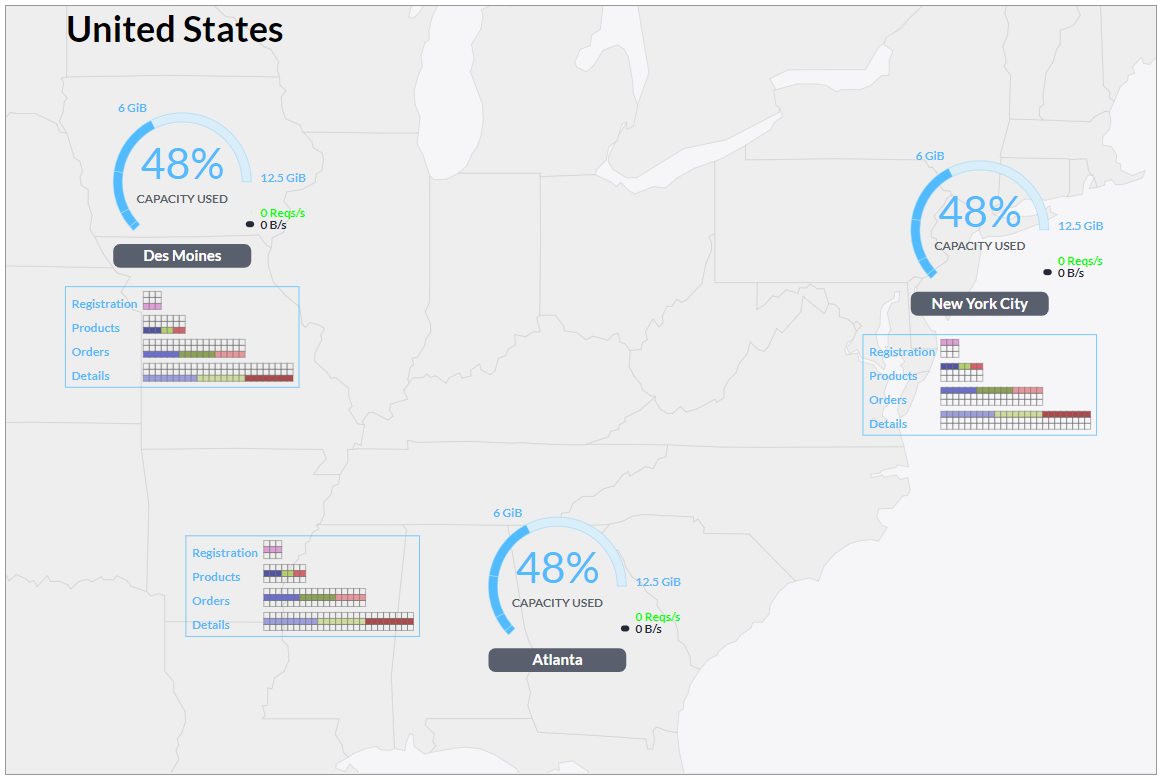
Circular figures represent either a single node or a collection of nodes
. If labeled as an internal IP address (e.g. \`10.10.1.1\`), they are a single node. Otherwise, they represent a collection of nodes, either as a facility (e.g. \`New York City\`) or even multiple facilities within a region (e.g. \`United States\`).
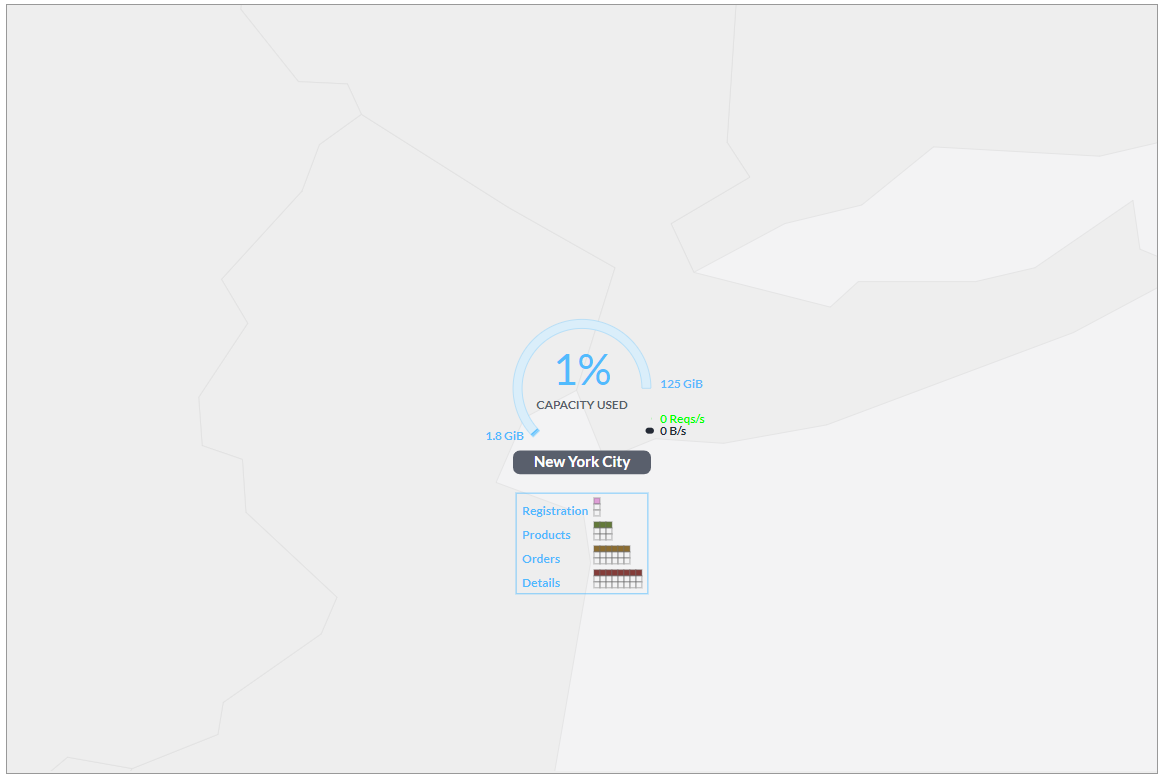
Facilities and regions may be clicked to expand the facilities or nodes they contain.
Use the escape key or the browser's back button to zoom back out.
Hover over the outside of the capacity gauge to expand it, showing a pie-chart with the breakdown of space used between four database tables: Registration, Products, Orders, and Details.
Hover over the direct center to see network links (note that this only works if there's more than one node shown).
Stage 1: Build.
You've got to start somewhere. And that's actually a significant problem with some cloud DBaaS offerings. CockroachDB is open source and runs on macOS, Linux, and Windows, so development on a laptop is simple and expedient. The quickest way to get started is to setup a free serverless database here.
Stage 2: Stand up a resilient service
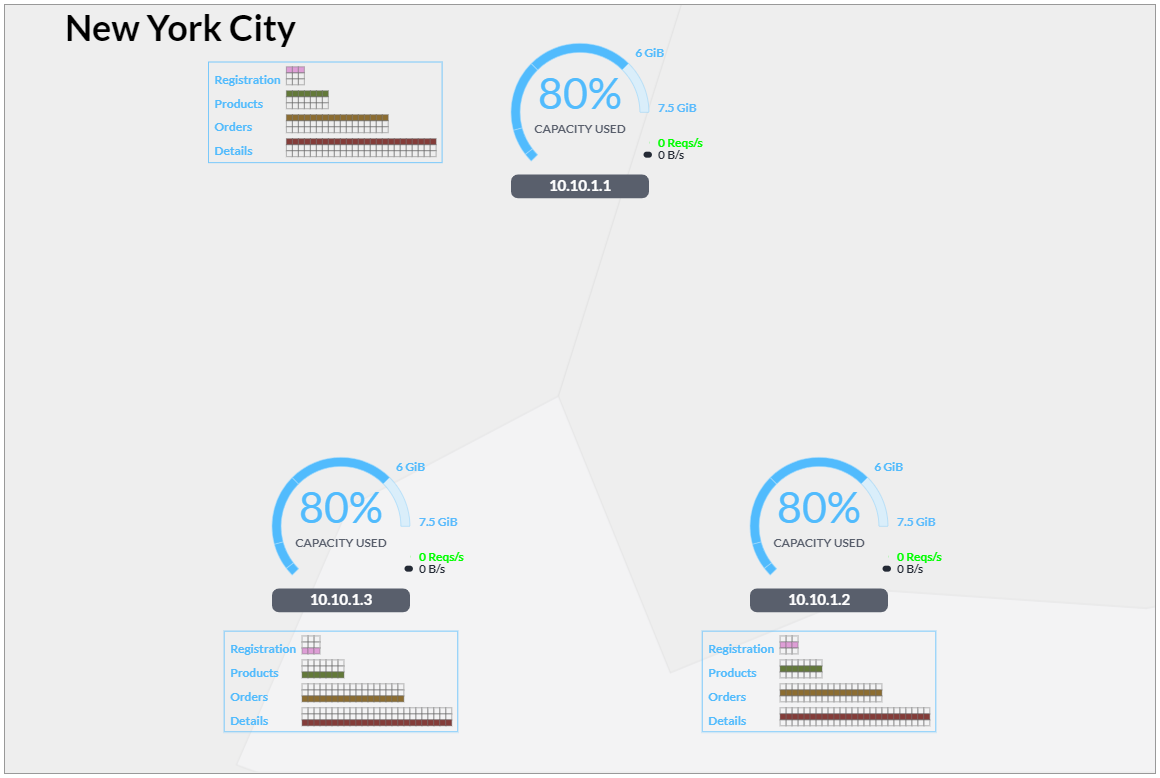
The first time CockroachDB is deployed to the cloud, it might be started as a single node. However, a crucial benefit of CockroachDB is that it's inherently highly available (HA), requiring no complex configuration or third-party failover mechanism to replicate and remain available in the event of node failure. It just needs additional nodes to join the cluster. But a highly available database with a symmetric, shared-nothing architecture isn't just for resilience in the face of unplanned failures. It's a crucial enabler for automating prosaic administrative tasks like zero-downtime upgrades and VM rescheduling.
CockroachDB uses the Raft consensus protocol to consistently replicate data between nodes. Table data is split into segmenats of contiguous key space (ordered by primary key), internally called \`ranges\`. Each range runs its own Raft algorithm to replicate and repair the data it contains. If you'd like a more sophisticated explanation, there's more detail available here. In the simulations, each range is visually depicted by a vertical stack of three replicas (replicas are visually depicted as boxes).
Stage 3: Achieve significant scale
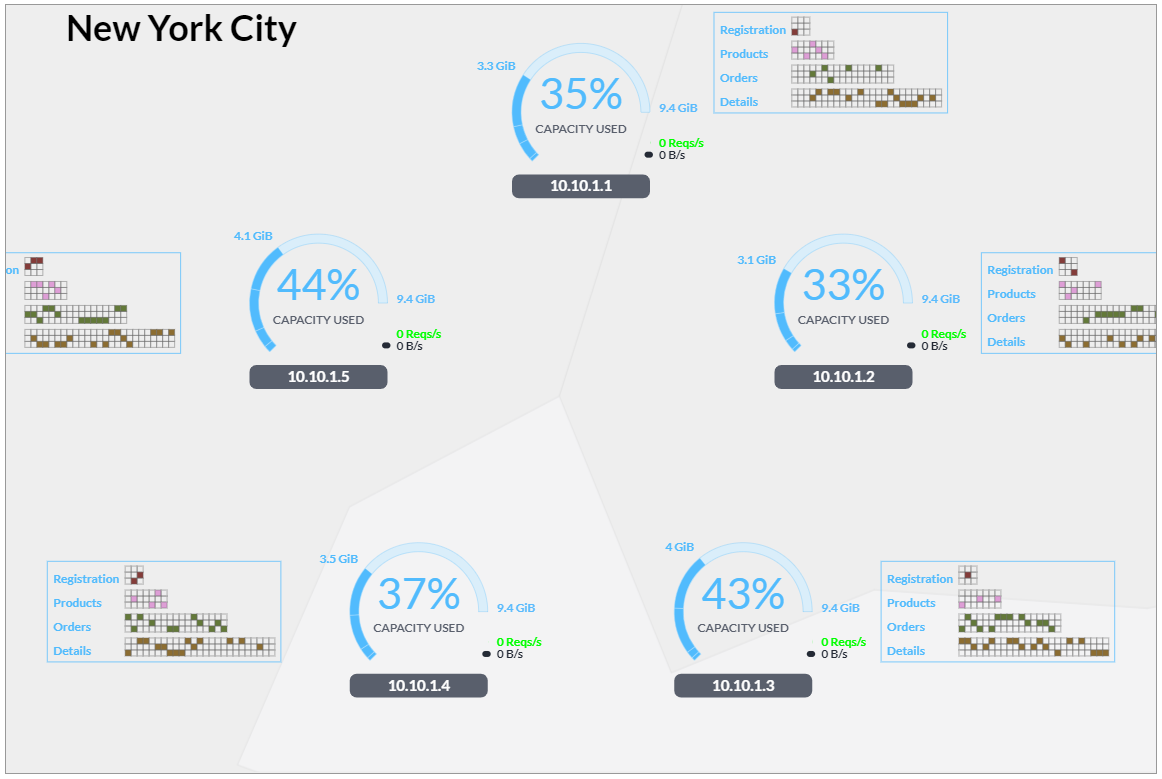
You can put a lot of data on a server these days, but big and monolithic is only the way people are used to running databases. You wouldn't deploy your application logic on a solitary, scaled-up server because you'd want to avoid a single point of failure, and you'd want the option to scale beyond even the largest monolithic server. You'd also want to minimize any disruption to client load in the event of node loss.
The same principles apply to your database, only more so. A typical disruption to a monolithic database is total (as experienced by connected clients), and can have long recovery time objectives, even with sophisticated failover mechanisms. Worse, monolithic architectures, even when configured with active/passive or active/active replication, can have a non-zero recovery point objective, meaning there could be data loss.
When a CockroachDB node experiences failure, the entire aggregate bandwidth of the cluster is used to up-replicate the missing data. This same mechanism is used to rebalance data as new nodes are added to a cluster. In the simulation, the original three node cluster is scaled by adding five additional nodes.
Note that the capacity of each node in this example has been reduced to more clearly illustrate relative fullness and iterative rebalancing.
Stage 4: Provide enterprise SLAs
You have a fast-growing business and CockroachDB has allowed you to scale within your primary datacenter (in this example, it's located in New York City). Whether your business is B2C and you've reached critical mass, or B2B and you've landed some big enterprise customers, at some point the pressures on your data architecture will again expand. This time, with more stringent requirements around service level agreements. In other words, you really can't allow the system to go down because of a facility outage.
To accomplish this, data must be replicated not just within a facility, but across facilities. You need some level of geo-replication. There is a cost to geo-replication, especially when done with quorum-based replication (like Raft). The cost you pay is latency, because for a write to become permanent, a majority of replication sites must acknowledge it. This means that writes have a minimum latency equal to the second slowest communication link between replication sites (in the case of three replicas). In practice, you want to choose facilities which are relatively close: within 30ms of each other, but probably not across the globe. However, you also want to balance proximity with geo-diversity, such that you minimize correlated failures (i.e. avoid doubling up on power sources or fiber backbones).
Stage 5: Serve global customers
Your business has grown to the point where you must service customers internationally. These days, this situation can just as easily apply to a fast-growing startup company as a multi-national enterprise. How do you solve the thorny issues around latency and data sovereignty? The old way of doing things was to run a primary facility on the East Coast of the United States, with a secondary facility ready as a hot standby. But customers, whether they're individual consumers of your online game, or other companies using your SaaS offering, are becoming less satisfied with the status quo. The two big challenges which need to be solved are service latency and customer data domiciling preferences.
With the EU's GDPR regulations coming into effect in May of 2018, and many other countries following suit, personal data privacy is an issue whose time has come. In particular, companies must get a very explicit consent from a customer when personal data will leave their jurisdiction for processing or storage. Companies that fail to provide for local data domiciling can expect hefty fines, the loss of their customers, or both.
One solution is to break up your global service into individual regional services, but this is expensive operationally and greatly compounds complexity for your application developers. Your customers likely still expect you to be providing a global service. They move, they interact with other customers across regions. These are difficult problems to solve at the application layer.
Geo-Partitioning
Enter geo-partioning. Database partioning isn't a new concept. RDBMSs like Oracle, SQLServer, and Postgres allow you to partition tables, mostly in order to manage the size of active data so that it can be quickly restored. CockroachDB has from the first version been able to replicate different databases or tables to different replication sites within a cluster. Geo-partitioning allows row-level control of replication. So, for example, a table might be partitioned based on its \`region\` column, containing values like \`us-ca\`, \`eu-de\`, \`eu-fr\`, and \`cn-bj\`. Any rows with region=\`eu-de\` might be replicated within a single facility in Germany, or across three facilities in Germany, whereas rows with region=\`cn-bj\` might be replicated to three facilities near Beijing, or even across China.
Now that you've seen what it can do, get started with CockroachDB instantly and for free.
Illustration by Zach Meyer


