
In CockroachDB v21.2 we introduced a new admission control and resource allocation subsystem, and in our most recent release (v22.1) we’ve made substantial improvements. In this blog post, we’ll cover the improvements made to admission control, including a description of the generally applicable mechanisms we developed, which should be relevant for any distributed transactional database with multi-node transactions.
These mechanisms include hybrid token and slot based allocation mechanisms, and dynamic adjustment of slot and token counts, in order to control both CPU and storage resource allocation. The mechanisms include support for multi-tenant performance isolation and prioritization within a tenant, and priority adjustment to reduce inversion due to transactions holding locks (for transaction serializability). The multi-stage and distributed execution of transactions creates difficulties when dealing with transactions with aggressive deadlines, for which we have developed an epoch-LIFO (last in first out) mechanism.
CockroachDB is implemented in Go, and for that reason we’re unable to make CPU (goroutine) scheduler changes – in the blog we’ll discuss how we dealt with this limitation and shifted significant queueing from the goroutine scheduler to the admission control queues, while achieving high CPU utilization.
*Note: As a reminder, multi-threading does not obviate the need for judicious resource allocation, because when a resource is fully utilized, there will be queuing somewhere (e.g. for CPU, in the CPU scheduler).
Admission Control in CockroachDB
The admission control system decides when work submitted to a system begins executing, and is useful when there is some resource (e.g. CPU) that is fully utilized, and you need to decide how to allocate this fully utilized resource. Prior to adding admission control to CockroachDB we experienced various forms of bad behavior in cases of overload, which, in the extreme, could lead to node failures, due to nodes being unable to do the work to prove that they were alive. There was also a desire to make informed decisions that would allow (a) higher priority queries to not suffer degradation, and (b) in the case of the multi-tenant version of CockroachDB deployed for the CockroachDB Serverless, provide performance isolation between tenants.
The current implementation focuses on node-level admission control, for CPU and storage IO (specifically writes) as the bottleneck resources. The focus on node-level admission control is based on the observation that large scale distributed databases may be provisioned adequately at the aggregate level, but since they have stateful nodes, individual node hotspots can develop that can last for some time (until rebalancing). Such hotspots should not cause failures or degrade service for important work, or unfairly for tenants that are not responsible for the hotspot.
1. Bottleneck Resources and Work Ordering
We focus on two bottleneck resources at a node, CPU, and storage write throughput.
For CPU, the goal is to shift queueing from inside the CPU scheduler (Go’s goroutine scheduler), where there is no differentiation, into admission queues that can differentiate. This must be done while allowing the system to have high peak CPU utilization.
For storage, CockroachDB uses a log-structured merge tree (LSM) storage layer called Pebble that resembles RockDB and LevelDB in many ways. A write throughput bottleneck manifests itself as an increase in read amplification because the LSM is unable to compact fast enough. The goal is to limit the admission of write work such that we can maintain read amplification at or below some configurable threshold R_amp (default value is 20). We have previously observed overload situations where read amplification has reached 1000, which slows down reads significantly.
Admission queues use the tuple (tenant, priority, transaction start time), to order work that is waiting to be admitted. There is coarse-grained fair sharing of resources across tenants (for a shared multi-tenant cluster). Priority is used within a tenant, and allows for starvation, in that if higher priority work is always consuming all resources, the lower priority work will wait forever. The transaction start time is used within a priority, and typically gives preference to earlier transactions, i.e., it is FIFO (first in first out) based on transaction start time. We will later discuss LIFO (last in first out) in the context of the epoch-LIFO scheme.
2. System architecture
The following diagram shows an abstracted version of the system architecture. The distributed-SQL layer communicates via streams of messages with the same layer at other nodes – the layer on the top is acting as the root of the execution tree in this example. The distributed-SQL layer provides small units of work to the local or remote key-value (KV) layer, executed in a request-response manner. The KV layer executes read and write work against the storage layer, and there can be multiple stores on a node.
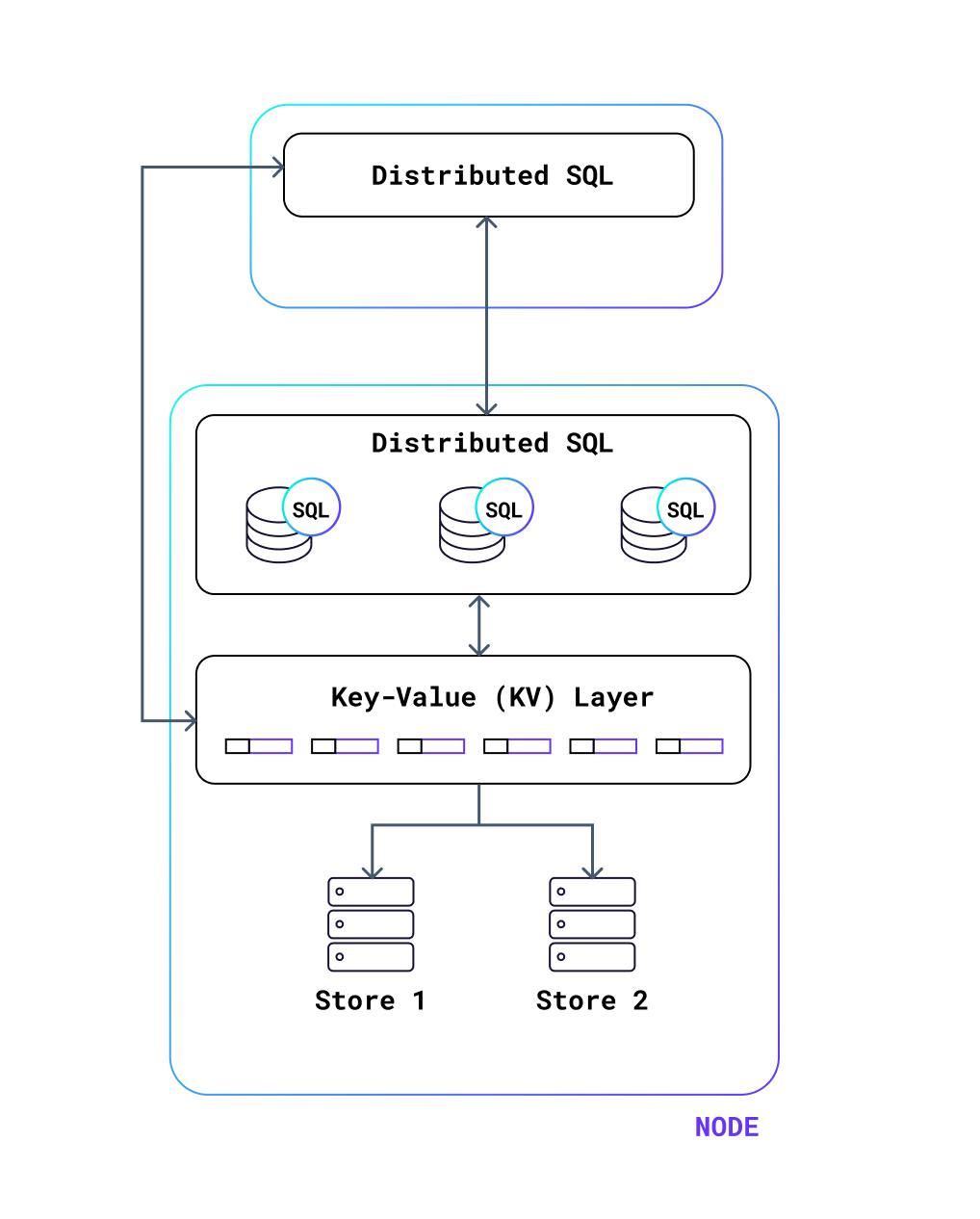
The request-response nature of the KV layer provides an entry-exit point for each piece of work. The response processing in the Distributed-SQL layer does not have an exit point: sometimes it may end with sending a message back to the root, and at other times it will do some processing and buffer the result. Where that processing ends can vary based on the operators involved in the SQL query. Both the KV and Distributed-SQL layers can consume substantial CPU, and which consumes more of the CPU depends on the mix of queries being executed by the system. Additionally, even though the size of work in processing a request at the KV layer or a response in the distributed-sql layer is small (roughly bounded by a few milliseconds), there is extreme heterogeneity in actual resource consumption.
3. Queues and servicing using tokens or slots
Since we are unable to make changes to Go’s CPU (goroutine) scheduler, we intercept CPU bound work with multiple queues in the following diagram: KV-Storage CPU, Response from KV, Response from DistSQL. Additionally, KV work that writes to the storage layer is intercepted in per-store write queues (shown in green), since the utilization of different stores can vary.
Note that a single transaction will submit many units of work to these queues over its lifetime. The number varies based on the number and complexity of statements in the transaction, and how much data it processes.

A key question is when can a unit of work in one of these queues be serviced. Token buckets provide a well understood scheme for servicing a queue based on a rate of replenishment of tokens. However deciding on an appropriate rate is hard when the size of the work is not known. In contrast, CPU schedulers allocate scheduling “slots” (with slots equal to the number of processors). For example, Go’s scheduler allocates a “P” to run code, where the number of P’s is equal to GOMAXPROCS. A CPU scheduler has visibility into when a thread/goroutine is no longer using a slot (because of IO), which allows for a slot to be reallocated.
We observe that a slot based mechanism has the benefit of being able to keep track of how much admitted work is still ongoing, which is beneficial in the absence of knowledge of work size. Hence for the KV-CPU queue we adopt a service model based on slot allocation. The number of slots are dynamically adjusted as described next. For the response queues gating Distributed-SQL work, we do not know when the processing is complete (no exit point), so we adopt a token scheme. For the store writes, the completion of the write does not indicate that the resource consumption caused by the write is complete, since flushing and compactions in a log-structured merge tree are delayed. Hence one wants to control the amount of work admitted over a time interval, i.e., a rate shaping mechanism, so we use tokens.
3.1 Dynamic slot calculation and coordination among CPU queues
Since KV work can result in IO, and can block due to transactional locks or latches, one cannot set the slot count to a fixed number derived from the number of provisioned CPUs for the node. Instead, we monitor the internal state of the goroutine scheduler for the number of runnable goroutines normalized by the CPU count, and use that to dynamically adjust the slot count, based on a threshold R of runnable goroutines. This monitoring occurs at 1ms granularity to allow for quick adjustments. Setting the threshold R to a high value will result in more queueing in the goroutine scheduler and is guaranteed to achieve high CPU utilization. A low R value transfers almost all the queueing delay to the admission queues, with the downside that the peak CPU utilization may be lower, since the backlog of admitted work in the scheduler is lower. In practice, we have found an R value of 32 runnable goroutines per CPU to be acceptable for most workloads. Additionally, a simple additive increase and decrease mechanism for slot counts has worked well.
Computing a token allocation rate for Distributed-SQL responses is hard given that the work sizes are unknown and because we don’t have an indication of when the work is done. We decided to sidestep the problem by not computing a token rate for these queues. Instead, we arrange the CPU queue in a hierarchy from lowest to highest layer: KV-Storage CPU, Response from KV, Response from DistSQL. Higher level queues only admit a queued item if the lower level queue is empty. This allows for a natural form of backpressure since delaying admission of higher level work also delays submission of new low-level work.
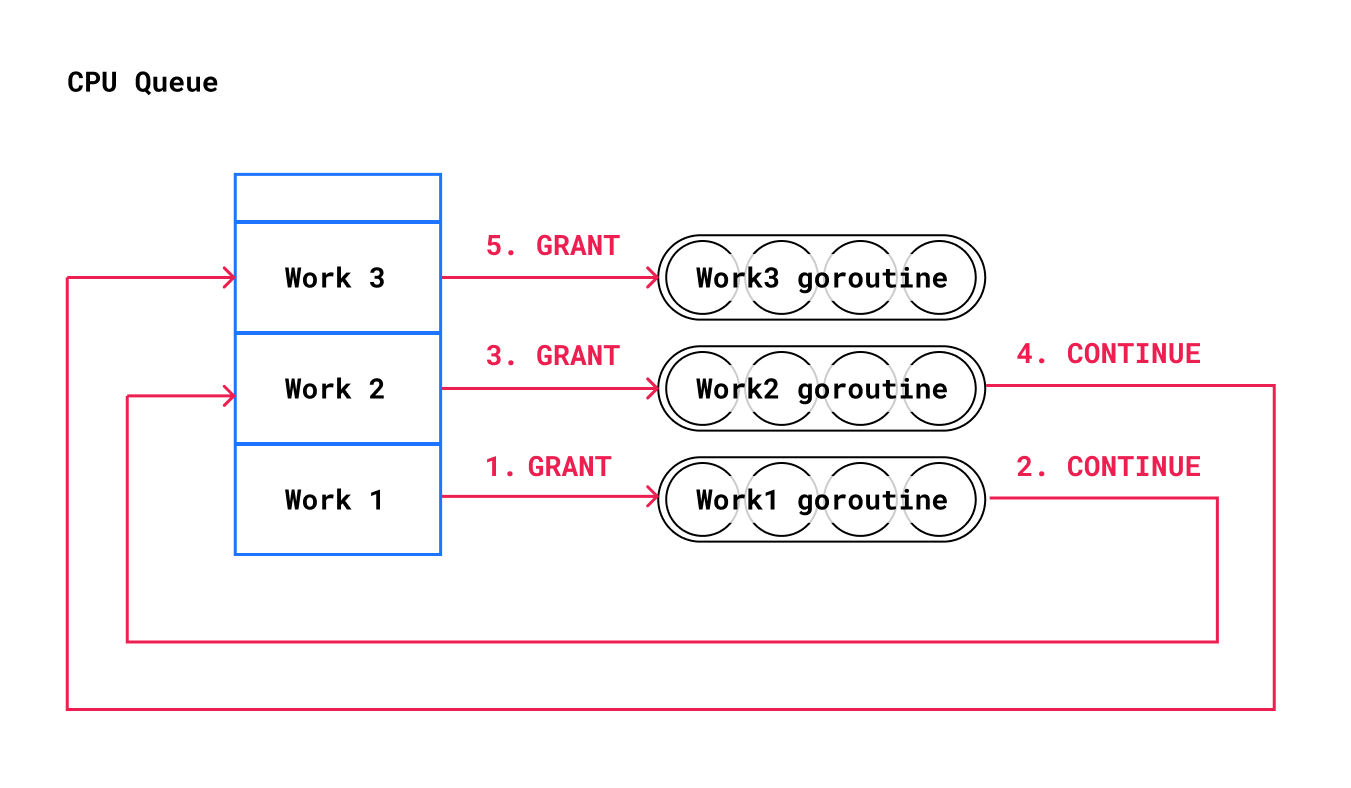
We found that despite this hierarchical coordination approach, there were large bursts of admitted entries, which caused too much queueing inside the goroutine scheduler. To prevent such bursts, we constructed a grant chaining mechanism that is able to use instantaneous scheduler state as shown in the diagram below. Instead of granting admission to Work1, Work2, Work3 in a tight loop, we grant admission to Work1, which has a corresponding thread of execution (goroutine) waiting for this grant. When that goroutine receives the grant, which requires it to be run by the scheduler, it calls back to continue the grant chain (before doing its work), which grants to Work2 and so on. This allows the scheduler to implicitly backpressure these grants based on how quickly it can schedule a goroutine. This is depicted in the following diagram
3.2 Dynamic token calculation for storage writes
Read amplification is an important metric of the health of a store that is constructed as a log-structured merge (LSM) tree. We use a read amplification threshold of R_amp to decide that we need to limit admission of write work. When there is a need to limit, we utilize metrics corresponding to bytes added to the system, and bytes compacted out of level 0 of the LSM, to compute a dynamic number of byte tokens that a work item consumes in order to be admitted.
3.3. Priority inversion and throughput
For serializability, transactions with writes acquire exclusive locks in CockroachDB. These get released when the transaction commits. Locking, using both shared and exclusive locks, is a common mechanism to achieve serializability in a database. For reads, CockroachDB has a kind of lockless optimistic concurrency control.
It is possible for work units of a transaction that is already holding locks to be waiting in an admission queue, while admitted work is waiting for those locks to be released. If the transaction that submitted the lock waiting work has higher priority than the transaction holding locks, we have the classic problem of priority inversion. Even when there isn’t priority inversion, delays in lock releasing can increase lock contention, and decrease throughput of contending transactions. Additionally, longer lock contention has the side effect of increasing resource usage in the system (e.g. to do distributed deadlock detection), which can decrease overall system throughput. We currently support a simple way of limiting both kinds of throughput degradation by bumping up the admission priority of transactions holding locks, so that these transactions can be admitted with less waiting.
3.4 Result examples
The following graphs show a flavor of the change that happens when admission control is enabled in an overloaded system around 14:45:30: the CPU utilization stays high, while the queueing shifts out of the goroutine scheduler into admission queues where we can make informed decisions. This also causes a significant drop in the post-admission KV execution latency, which means lower latency for high priority work that will not be delayed by an admission queue.
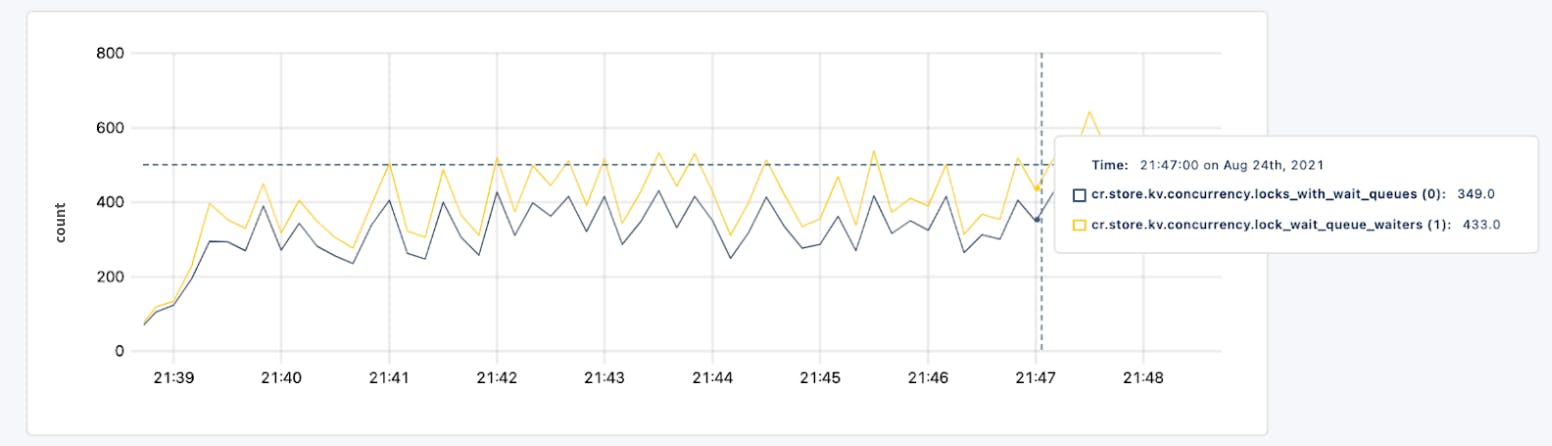
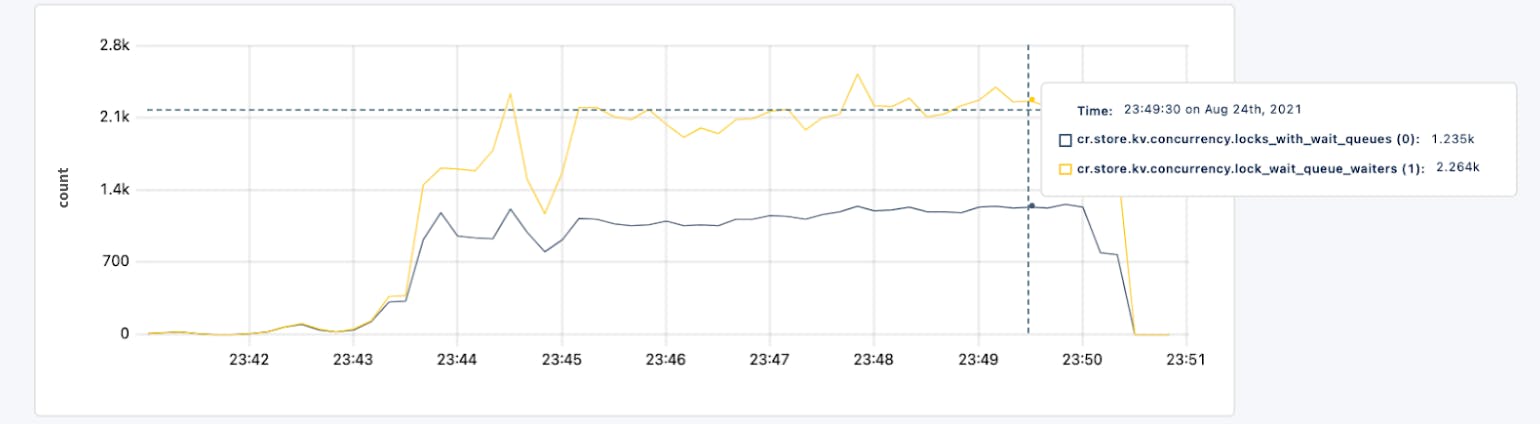
In a TPCC experiment with 3000 warehouses and a 3 node cluster, we see a significant reduction in waiting on locks as shown in the following graphs, where the first graph is with admission control and the second graph without admission control. With admission control, this experiment had a stable transaction throughput of approximately 1050 txn/s while without admission control it started at 1200 txn/s, but within 10min it had collapsed to 400 txn/s.
4. Multi-tenancy
In the previous sections we have presented each queue as a totally ordered set of waiting work. This is a simplification from the actual implementation, that needs to maintain inter-tenant fairness of resource allocation.
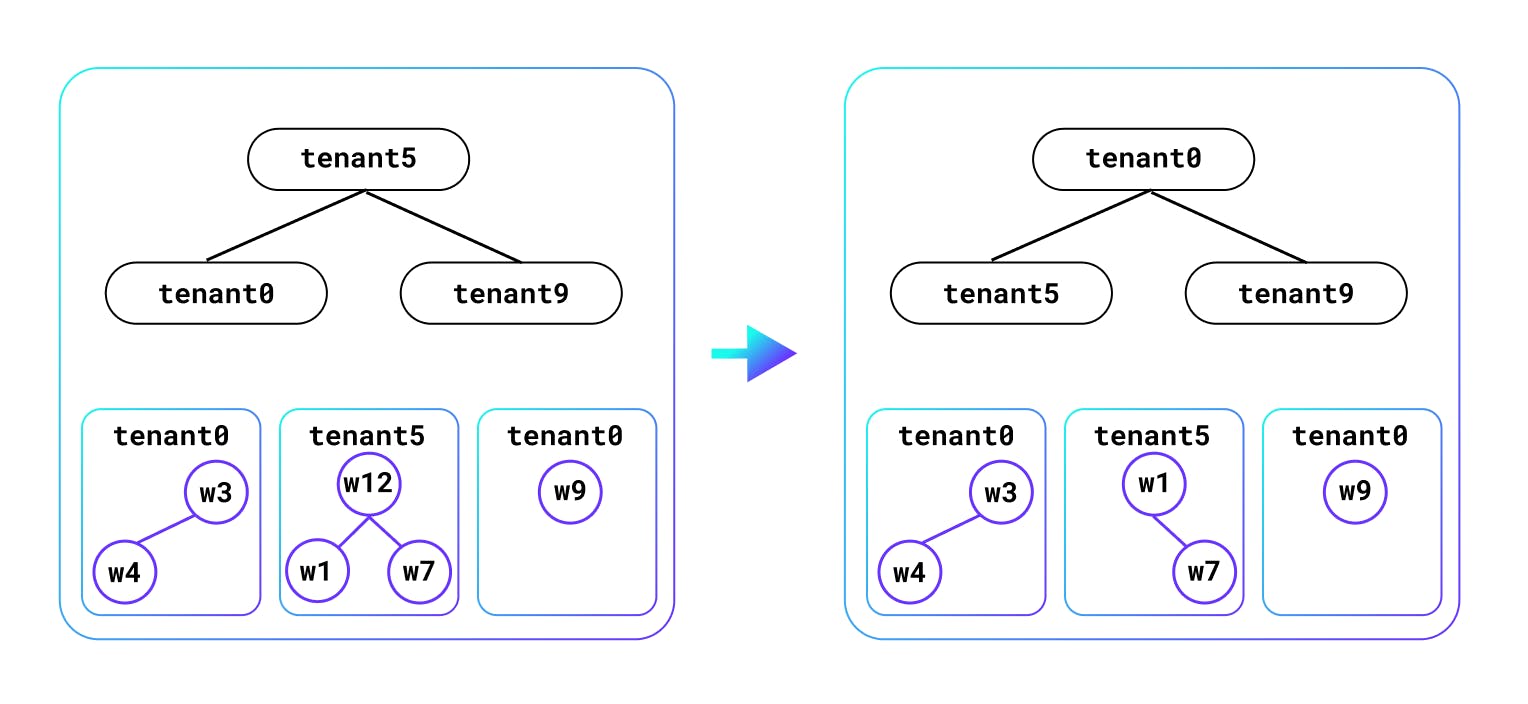
The left side of the following diagram shows the queue internals which consists of a top-level heap that orders the tenants with waiting work based on an increasing value of allocated slots (or allocated tokens for a certain duration). Additionally there is a heap per tenant that orders work based on the (priority, transaction start time) tuple. The next admitted work will be for tenant5, which means w12 will be admitted. After admission, the tenant heap is adjusted, since this tenant has been granted an additional slot/token, and the per-tenant heap is adjusted to remove the granted work. We see that tenant0 is now at the top. Heaps are used for O(log N) addition, removal, adjustment, and are cheap enough for the granularity of work being admitted. The CPU overhead of admission control is < 1%. Work items waiting in a queue can be canceled, say due to the work deadline being exceeded, and will be removed from the queue.
5. Epoch LIFO (last in first out) Queueing
The admission queues described earlier order the work for a particular (tenant, priority) pair in increasing order of the transaction start time. This system-wide FIFO behavior has the benefit that transactions that started earlier will tend to complete earlier.
There is a known problem with such FIFO queueing: under extreme overload with an open loop workload, the queueing delay to get to the front of the queue increases without bound. Even if the workload is not truly open loop, one can encounter situations where the transaction has a deadline such that queueing delay increases to the point where every transaction has some of its work items executed before the deadline is exceeded. The effective throughput of such a system is zero. The solution to this problem is LIFO queueing, where in our case would be ordering work by decreasing transaction start time. LIFO queueing increases tail latency, hence schemes have been constructed that switch from FIFO to LIFO when queueing delay increases. An example is the adaptive LIFO scheme described in this article.
However, LIFO is not suitable in a setting where each transaction can fanout to multiple nodes, and can send work multiple times to the same node. The later work for a transaction will no longer be the latest seen by a node, so will not be preferred. This means LIFO will do some early work items from each transaction and starve the remaining work, so no transaction will complete. This is even worse than FIFO which at least prefers the same transactions until they are complete. To the best of our knowledge, the existing descriptions of LIFO in the literature only consider single self contained work requests.
We have designed and implemented an epoch based LIFO scheme, which relies on the deadline being significantly greater than transaction execution time under no load, and relies on partially synchronized clocks, but requires no explicit coordination. CockroachDB already makes this clock synchronization assumption to prevent stale reads, and we have observed excellent clock synchronization in production deployments.
Consider a case where transaction deadlines are 1s, and typical transaction execution times (under low load) of 10ms, and a configured 100ms epoch. Under epoch-LIFO, work submitted by a transaction with start time T is slotted into the epoch number with time interval [E, E+100ms) where T is contained in this interval. The work will start executing after the epoch is “closed”, at E+100ms+delta, where delta is a grace period, say with value 5ms. This increases transaction latency to at most 100ms + 5ms + 10ms. When the epoch closes, all nodes start executing the transactions in that epoch in LIFO order, and will implicitly have the same set of competing transactions. This set of competing transactions will stay unchanged until the next epoch closes. And by the time the next epoch closes, and the current epoch’s transactions are deprioritized, 100ms will have elapsed, which is enough time for most of these transactions that got admitted to have finished all their work.
The epoch-LIFO scheme dynamically monitors the queueing delay for each (tenant, priority) pair and switches between FIFO and LIFO queueing based on the maximum observed delay. Hence it adapts to resource bottlenecks.
The following graphs show the before and after effects of enabling epoch-LIFO admission control, where the latency is in nanoseconds. The p50 and p75 latencies drop from 671ms, 1s to 96ms, 184ms respectively. The p99 latency rises since we are making a tradeoff here to reduce the latency of a large fraction of the work, at the cost of higher latency for a small fraction.


6. Conclusion
Admission control and resource allocation in a highly scalable distributed SQL database is a hard problem. We have made a big step forward in the recent CockroachDB release, but there are many interesting problems remaining to be solved. If resource allocation problems interest you, we’d love for you to check out some of our open roles. Thanks for reading!


