
Change data capture (CDC) provides efficient, distributed, row-level changefeeds into a configurable sink for downstream processing such as reporting, caching, or full-text indexing.
What is change data capture?
While CockroachDB is an excellent system of record, it also needs to coexist with other systems. For example, you might want to keep your data mirrored in full-text indexes, analytics engines, or big data pipelines.
The main feature of CDC is the changefeed, which targets an allowlist of tables, called the "watched rows". There are two implementations of changefeeds:
| Core changefeeds | Enterprise changefeeds |
|---|---|
| Useful for prototyping or quick testing. | Recommended for production use. |
| Available in all products. | Available in CockroachDB Dedicated or with an Enterprise license in CockroachDB self-hosted or CockroachDB Serverless. |
| Streams indefinitely until underlying SQL connection is closed. | Maintains connection to configured sink. |
Create with EXPERIMENTAL CHANGEFEED FOR. |
Create with CREATE CHANGEFEED. |
| Watches one or multiple tables in a comma-separated list. Emits every change to a "watched" row as a record. | Watches one or multiple tables in a comma-separated list. Emits every change to a "watched" row as a record in a configurable format ( JSON or Avro) to a configurable sink (e.g., Kafka). |
CREATE changefeed and cancel by closing the connection. |
Manage changefeed with CREATE, PAUSE, RESUME, ALTER, and CANCEL, as well as monitor and debug. |
See Ordering Guarantees for detail on CockroachDB's at-least-once-delivery-guarantee as well as explanation on how rows are emitted.
How does an Enterprise changefeed work?
When an Enterprise changefeed is started on a node, that node becomes the coordinator for the changefeed job (Node 2 in the diagram). The coordinator node acts as an administrator: keeping track of all other nodes during job execution and the changefeed work as it completes. The changefeed job will run across all nodes in the cluster to access changed data in the watched table. Typically, the leaseholder for a particular range (or the range’s replica) determines which node emits the changefeed data.
Each node uses its aggregator processors to send back checkpoint progress to the coordinator, which gathers this information to update the high-water mark timestamp. The high-water mark acts as a checkpoint for the changefeed’s job progress, and guarantees that all changes before (or at) the timestamp have been emitted. In the unlikely event that the changefeed’s coordinating node were to fail during the job, that role will move to a different node and the changefeed will restart from the last checkpoint. If restarted, the changefeed will send duplicate messages starting at the high-water mark time to the current time. See Ordering Guarantees for detail on CockroachDB's at-least-once-delivery-guarantee as well as an explanation on how rows are emitted.
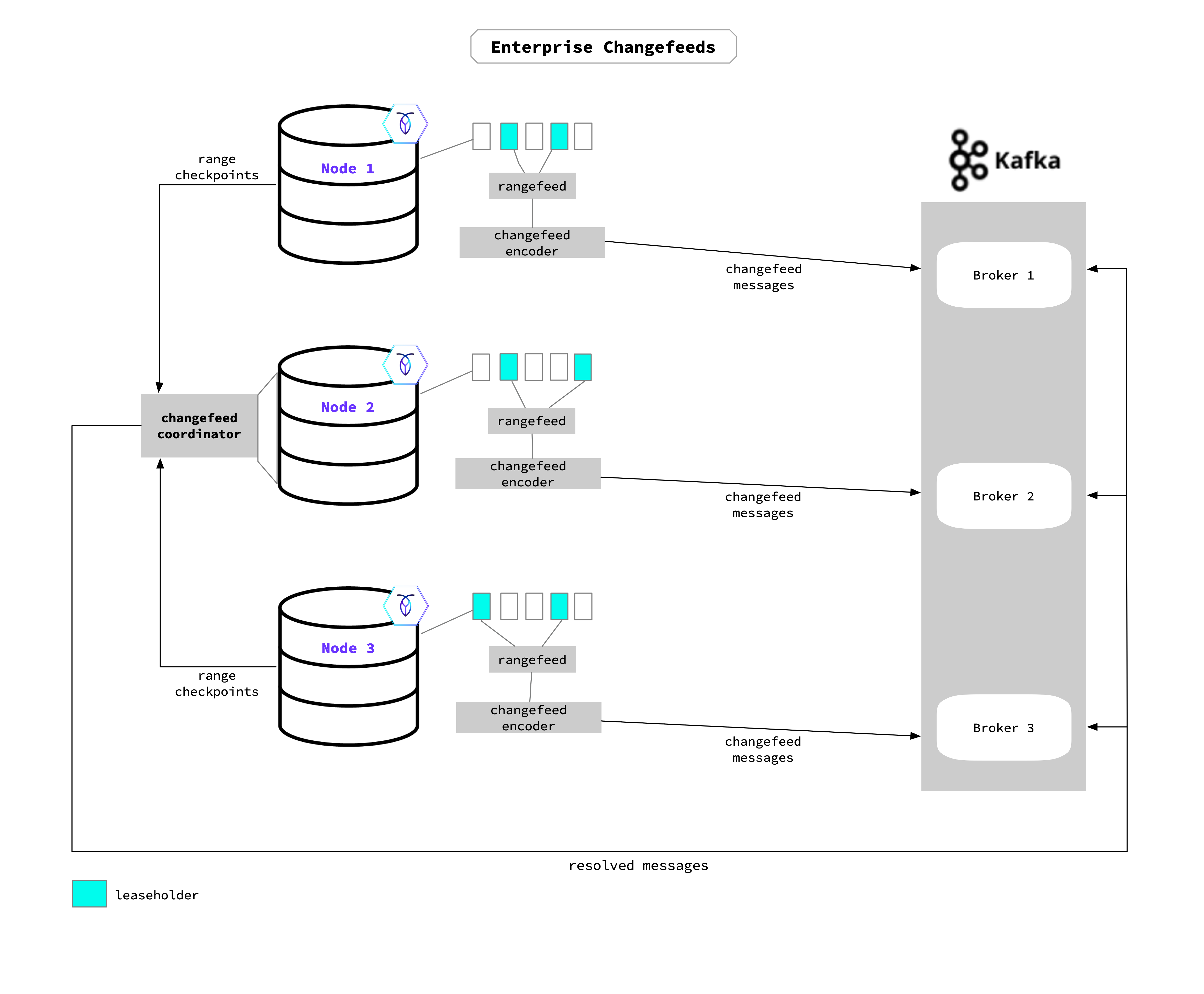
With resolved specified when a changefeed is started, the coordinator will send the resolved timestamp (i.e., the high-water mark) to each endpoint in the sink. For example, when using Kafka this will be sent as a message to each partition; for cloud storage, this will be emitted as a resolved timestamp file.
As rows are updated, added, and deleted in the targeted table(s), the node sends the row changes through the rangefeed mechanism to the changefeed encoder, which encodes these changes into the final message format. The message is emitted from the encoder to the sink—it can emit to any endpoint in the sink. In the diagram example, this means that the messages can emit to any Kafka Broker.
See the following for more detail on changefeed setup and use:
Known limitations
- Changefeeds cannot be backed up or restored. Tracking GitHub Issue
- Changefeed target options are limited to tables and column families. Tracking GitHub Issue
- Using a cloud storage sink only works with
JSONand emits newline-delimited json files. Tracking GitHub Issue - Webhook sinks only support HTTPS. Use the
insecure_tls_skip_verifyparameter when testing to disable certificate verification; however, this still requires HTTPS and certificates. Tracking GitHub Issue - Webhook sinks and Google Cloud Pub/Sub sinks only have support for emitting
JSON. Tracking GitHub Issue - There is no concurrency configurability for webhook sinks. Tracking GitHub Issue
- Using the
split_column_familiesandresolvedoptions on the same changefeed will cause an error when using the following sinks: Kafka and Google Cloud Pub/Sub. Instead, use the individualFAMILYkeyword to specify column families when creating a changefeed. Tracking GitHub Issue - There is no configuration for unordered messages for Google Cloud Pub/Sub sinks. You must specify the
regionparameter in the URI to maintain ordering guarantees. Tracking GitHub Issue
