
The TTL dashboard lets you monitor the progress and performance of batch deleting expired data using Row-Level TTL from your cluster.
To view this dashboard, access the DB Console, click Metrics in the left-hand navigation, and select Dashboard > TTL.
Dashboard navigation
Use the Graph menu to display metrics for your entire cluster or for a specific node.
To the right of the Graph and Dashboard menus, a time interval selector allows you to filter the view for a predefined or custom time interval. Use the navigation buttons to move to the previous, next, or current time interval. When you select a time interval, the same interval is selected in the SQL Activity pages. However, if you select 10 or 30 minutes, the interval defaults to 1 hour in SQL Activity pages.
Hovering your mouse pointer over the graph title will display a tooltip with a description and the metrics used to create the graph.
When hovering on graphs, crosshair lines will appear at your mouse pointer. The series' values corresponding to the given time in the cross hairs are displayed in the legend under the graph. Hovering the mouse pointer on a given series displays the corresponding value near the mouse pointer and highlights the series line (graying out other series lines). Click anywhere within the graph to freeze the values in place. Click anywhere within the graph again to cause the values to change with your mouse movements once more.
In the legend, click on an individual series to isolate it on the graph. The other series will be hidden, while the hover will still work. Click the individual series again to make the other series visible. If there are many series, a scrollbar may appear on the right of the legend. This is to limit the size of the legend so that it does not get endlessly large, particularly on clusters with many nodes.
The TTL dashboard displays the following time series graphs:
Processing Rate
You can monitor the Processing Rate graph to see how many rows per second are being processed by TTL jobs.
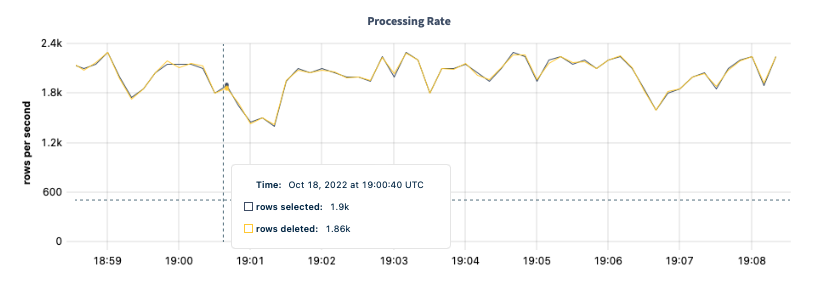
| Metric | Description |
|---|---|
| rows selected | The number of rows selected for deletion by the TTL job. |
| rows deleted | The number of rows deleted by the TTL job. |
Estimated Rows
Monitor the Estimated Rows graph to see approximately how many rows are on the TTL table.
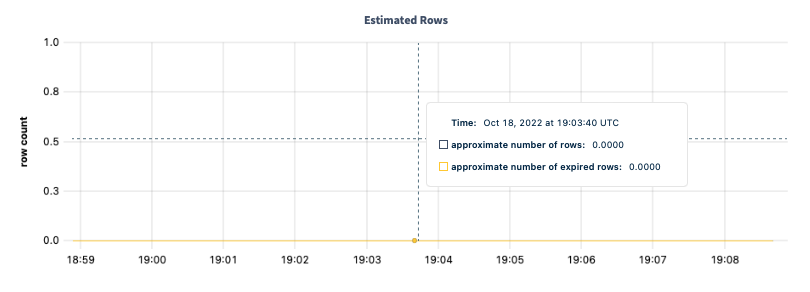
| Metric | Description |
|---|---|
| approximate number of rows | The number of rows in all tables with TTL settings. |
| approximate number of expired rows | The number of expired rows across all tables with TTL settings. |
Job Latency
Monitor the Job Latency graph to see the latency of scanning and deleting within your cluster's TTL jobs.
Ranges in Progress
Monitor the Ranges in Progress graph to see the number of ranges currently being processed by TTL jobs.
| Metric | Description |
|---|---|
| number of ranges being processed | How many ranges are currently being processed by TTL jobs. |
Summary and events
Summary panel
A Summary panel of key metrics is displayed to the right of the timeseries graphs.
| Metric | Description |
|---|---|
| Total Nodes | The total number of nodes in the cluster. Decommissioned nodes are not included in this count. |
| Capacity Used | The storage capacity used as a percentage of usable capacity allocated across all nodes. |
| Unavailable Ranges | The number of unavailable ranges in the cluster. A non-zero number indicates an unstable cluster. |
| Queries per second | The total number of SELECT, UPDATE, INSERT, and DELETE queries executed per second across the cluster. |
| P99 Latency | The 99th percentile of service latency. |
If you are testing your deployment locally with multiple CockroachDB nodes running on a single machine (this is not recommended in production), you must explicitly set the store size per node in order to display the correct capacity. Otherwise, the machine's actual disk capacity will be counted as a separate store for each node, thus inflating the computed capacity.
Events panel
Underneath the Summary panel, the Events panel lists the 5 most recent events logged for all nodes across the cluster. To list all events, click View all events.
The following types of events are listed:
- Database created
- Database dropped
- Table created
- Table dropped
- Table altered
- Index created
- Index dropped
- View created
- View dropped
- Schema change reversed
- Schema change finished
- Node joined
- Node decommissioned
- Node restarted
- Cluster setting changed
