Summary
A race condition between MVCC garbage collection and range splits in CockroachDB can, under specific and unlikely circumstances, result in the deletion of live data. This issue affects CockroachDB v23.1 and later. Patches are available for all supported versions. Customers are encouraged to upgrade to a patched version or apply the mitigation described below. Most workloads are unlikely to be affected by this issue. The conditions that precipitate data loss are narrow and require a specific combination of data lifecycle patterns and timing. Details on how to assess your risk are provided in the Am I Affected? section below.Action Required
Upgrade to a patched version
The fix has been applied to maintenance releases of CockroachDB:- v23.2.29
- v24.1.26
- v24.3.27
- v25.2.13
- v25.4.5
- v26.1.0
Interim mitigation
If an upgrade cannot be performed immediately, the issue can be mitigated by disabling the ClearRange optimization:SET CLUSTER SETTING kv.gc.clear_range_min_keys = 0;
This setting causes garbage collection to use individual key deletions rather than range deletions, avoiding the race condition entirely. There is no significant performance impact for most workloads. This value should be reverted to the default after upgrading to a patched version.
Am I Affected?
This issue requires a specific combination of conditions to trigger. Most workloads will not meet all of these conditions. The following guidance can help you assess your risk level.Low-risk workloads
Tables with UUID or random primary keys
The issue requires a large contiguous span of at least 2,000 consecutive obsolete MVCC versions with no live data interspersed. Tables with UUID or other uniformly random primary keys are, for most practical purposes, not affected by this issue. If rows are deleted randomly, the probability of 2,000 or more consecutive deleted keys appearing with no live key between them is nearly zero. However, secondary indexes on the table could be affected. In this case we suggest using the steps in the Detection section to verify.Queue and outbox patterns
Queue-like workloads where rows are inserted, processed, and then deleted using sequential primary keys can generate the contiguous spans of obsolete keys required to trigger the race condition. However, because new writes in these workloads occur at the tail of the table, they do not overlap with older garbage-collection-eligible spans. Even if the race condition fires, it affects only already-deleted data and does not result in data loss.Higher-risk workloads
Workloads at higher risk combine two properties: (1) large volumes of deletes that create contiguous spans of obsolete keys, and (2) write patterns where new data lands within those spans rather than strictly appending. Examples include:- Time-series with late-arriving data: Tables keyed by timestamp or (entity_id, timestamp) where old data is aged out and new data occasionally backfills into older timestamp ranges. The backfilled data must arrive after the GC threshold (4 hours by default).
- Corrections or amendments to historical data. Systems that archive data, then insert corrections into the same key range. Common in financial transaction corrections, audit systems, and order management with historical amendments.
- Bulk delete followed by re-insert: Periodic purges of old data followed by re-processing or re-import that populates similar key ranges. Examples include ETL staging tables, data migration workflows, and cache tables that are cleared and repopulated.
- Secondary indexes with different clustering: Even if a table’s primary key follows a safe pattern (e.g., sequential), a secondary index may cluster data differently (by status, category, or timestamp). Writes can land in secondary index key ranges where deleted data once resided.
Required simultaneous preconditions
For data loss to occur, all of the following must be true simultaneously:- MVCC GC detects a consecutive run of 2,000 or more obsolete (or garbage collectible) MVCC versions spanning at least two user keys.
- The range on which GC is occurring undergoes a concurrent split.
- A new write arrives on the right-hand side of the split, within the bounds of the GC’d span, before the GC operation completes.
Detection
If you suspect this issue may have affected your cluster, the following methods can help detect data loss.Secondary index cross-referencing
For tables with secondary indexes, it is extremely unlikely that both the primary and secondary indexes are affected simultaneously. The indexes can therefore be compared to detect data loss. In CockroachDB v25.4+, tables with secondary indexes can be checked for internal consistency with the INSPECT command:Replica inconsistency
In some cases, the issue causes replicas to diverge. CockroachDB’s consistency checker will detect this and terminate the node hosting the divergent replica. If you have observed node terminations with the following log message, contact Cockroach Labs Support for analysis:This node is terminating because a replica inconsistency was detected
Note: Consistency check failures can also be caused by disk failures and other anomalies. Not all such failures represent data loss from this issue.
MVCC statistics divergence
CockroachDB maintains statistics on the number of keys in each range. A mismatch of the LiveCount MVCC statistic may indicate that keys have been lost. The following regular expression can be used to search logs for such messages:delta of.*ContainsEstimates:0.*LiveCount:[1-9]+
Limitations of detection
In the rare case where all preconditions are met and the affected data is not covered by secondary indexes, the loss may not be detected by CockroachDB’s built-in consistency mechanisms. This is why we recommend upgrading to a patched version promptly.Affected Versions
The following CockroachDB versions are impacted by this issue:- v23.1.0 and later
- v23.2.0 through v23.2.28
- v24.1.0 through v24.1.25
- v24.3.0 through v24.3.26
- v25.2.0 through v25.2.12
- v25.3.0 and later
- v25.4.0 through v25.4.4
Appendix: Technical Details
This section provides a detailed technical explanation of the underlying issue for those who wish to understand the root cause. It is not required reading to assess risk or take action.Background
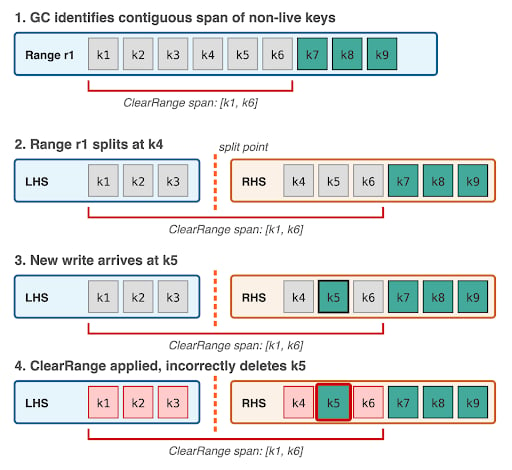
CockroachDB v23.1 added an optimization to the garbage collection process. When there is a contiguous span of at least 2,000 non-live (obsolete) keys in a range, the GC process writes a Pebble range tombstone using a ClearRange request to efficiently delete this span of data, rather than deleting each key individually.The race condition
When a range split occurs while the MVCC GC process is generating ClearRange requests, the generated request may incorrectly span key ranges outside of the post-split left-hand side (LHS) range boundaries. The ClearRange request header is set using bounds that were valid before the split but are no longer correct after it. The race proceeds as follows:- The GC process identifies a span of keys eligible for garbage collection using the ClearRange optimization (at least 2,000 consecutive obsolete keys).
- The range splits, with the split point falling within the identified span.
- The GC process produces a ClearRange request, but sets the request header using the post-split LHS boundaries. These boundaries do not strictly cover the ClearRange request, but the validation passes because the header matches the range.
- The ClearRange request is sent to the LHS range and is allowed to proceed.
- (Required for data loss) A new write arrives on the RHS range, within the bounds of the ClearRange. Because the latch for the ClearRange is held only in the LHS latch manager, the RHS accepts the write without knowledge of the pending GC operation.
- When the ClearRange applies on the LHS replicas, it deletes data in the RHS keyspace — including any live write from step 5.
Why this typically affects all replicas
Because all LHS replicas share the same underlying storage as the new RHS replicas and apply the same ClearRange operation, the deletion occurs consistently across all replicas. As a result, consistency checks will not detect the divergence. A variant exists where a replica of the RHS moves to a different node before the ClearRange is applied. In this case, the moved replica is unaffected, the remaining replicas diverge, and the consistency checker will eventually detect the inconsistency.What constitutes an obsolete MVCC version
Every INSERT, UPDATE, or DELETE produces a new MVCC version of a key. Examples of obsolete version counts:- INSERT A, DELETE A — obsolete run length is 2
- INSERT A, UPDATE A, DELETE A — obsolete run length is 3
- INSERT A — obsolete run length is 0 (key is live)