

Reader’s Note: This post references CockroachDB Serverless and/or CockroachDB Dedicated which, as of September 26 2024, have been renamed and incorporated within the new CockroachDB Cloud platform, which you can read more about here.
What is a foreign key? (TL;DR)
A foreign key is a column or columns in a database that (e.g. table_1.column_a) that are linked to a column in a different table (table_2.column_b).
The existence of a foreign key column establishes a foreign key constraint – a database rule that ensures that a value can be added or updated in column_a only if the same value already exists in column_b.

We can think about this like a “parent/child” relationship in programming. We can make a specific column in the “child” table a foreign key that references a specific column in the “parent” table, and the database will enforce that rule automatically – rows will only be added or updated in the child table if the value in the foreign key column of the row being updated matches an existing value in the referenced column of the parent table.
For example, a table of customer orders might have a user column with a foreign key attribute that links it to the user_id column in a users table (see above). This way, each row in the orders table can be associated with a specific user from the users table — and no orders can enter the system unless they’re connected to a valid, existing user.
In other words: foreign keys put the “relational” in “relational database” – they help define the relationships between tables. They allow developers to maintain referential integrity across their database. Foreign keys also help end-users by preventing errors and improving the performance of any operation that’s pulling data from tables linked by indexed foreign keys.
What are foreign key constraints?
This short video from Cockroach Labs, “What is a Foreign Key Constraint? Understanding Primary & Foreign Keys” will help broaden your understanding of foreign key constraints SQL.
How foreign keys work
Here’s an illustration of how a foreign key constraint works visually:
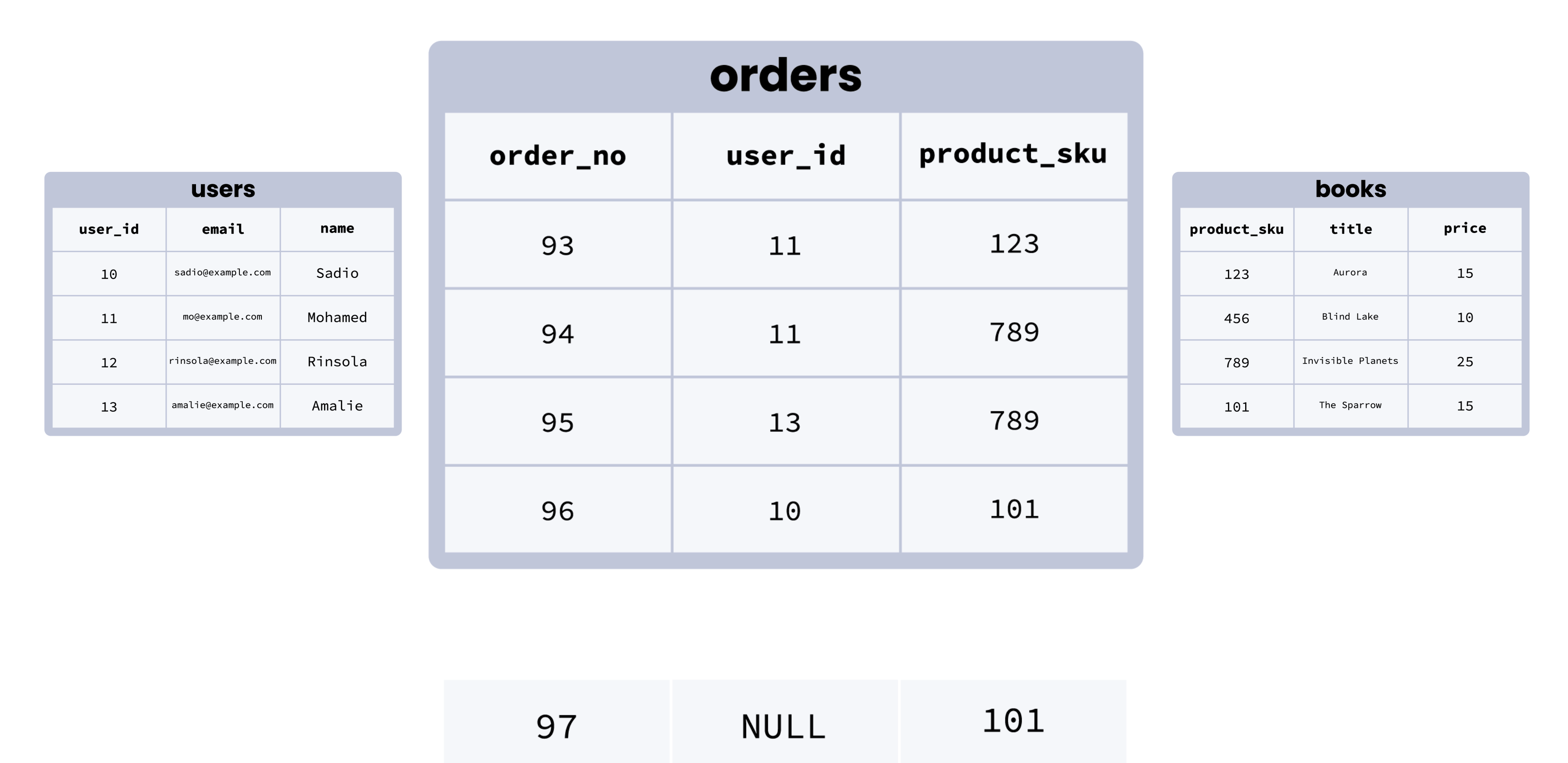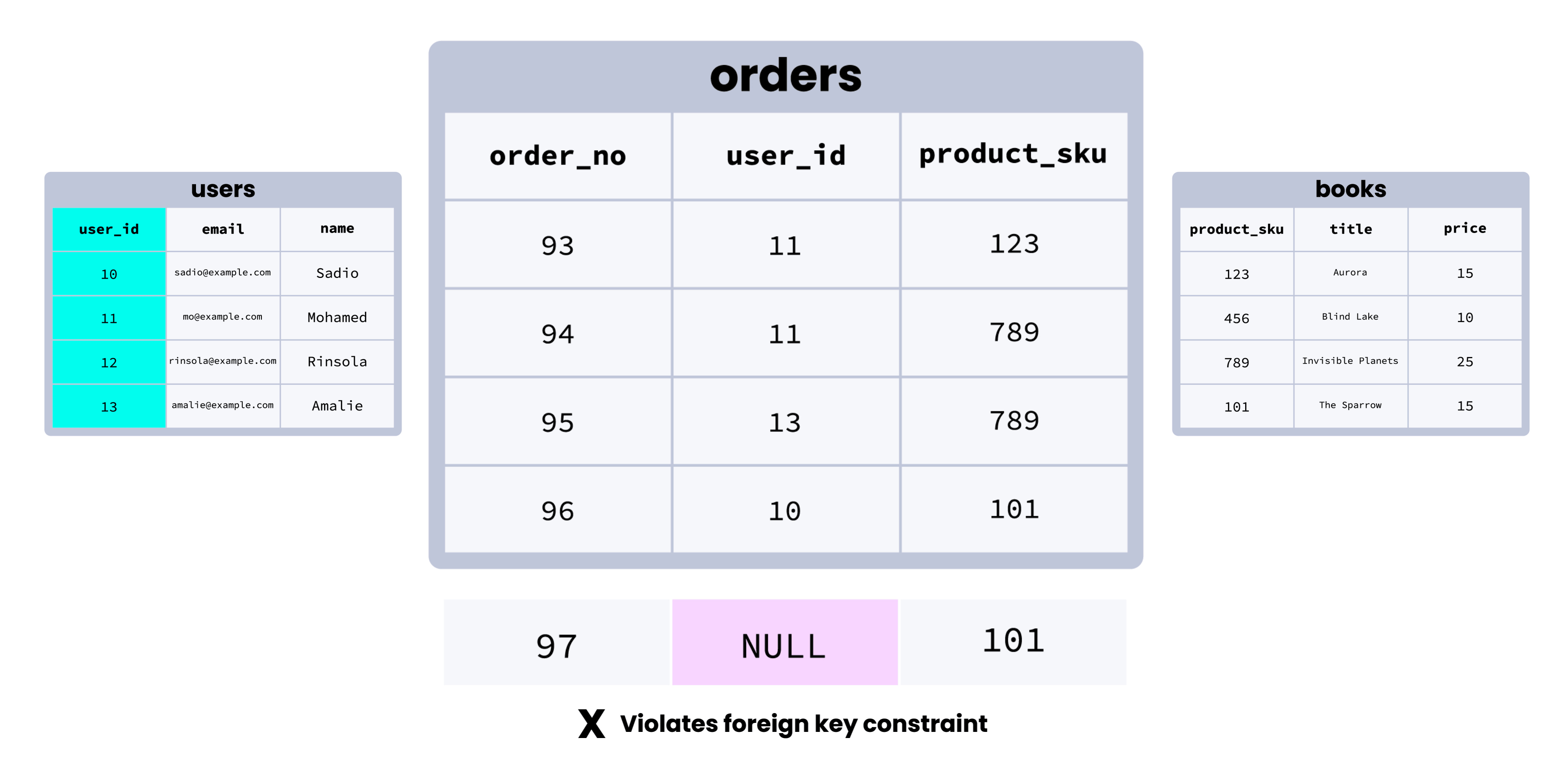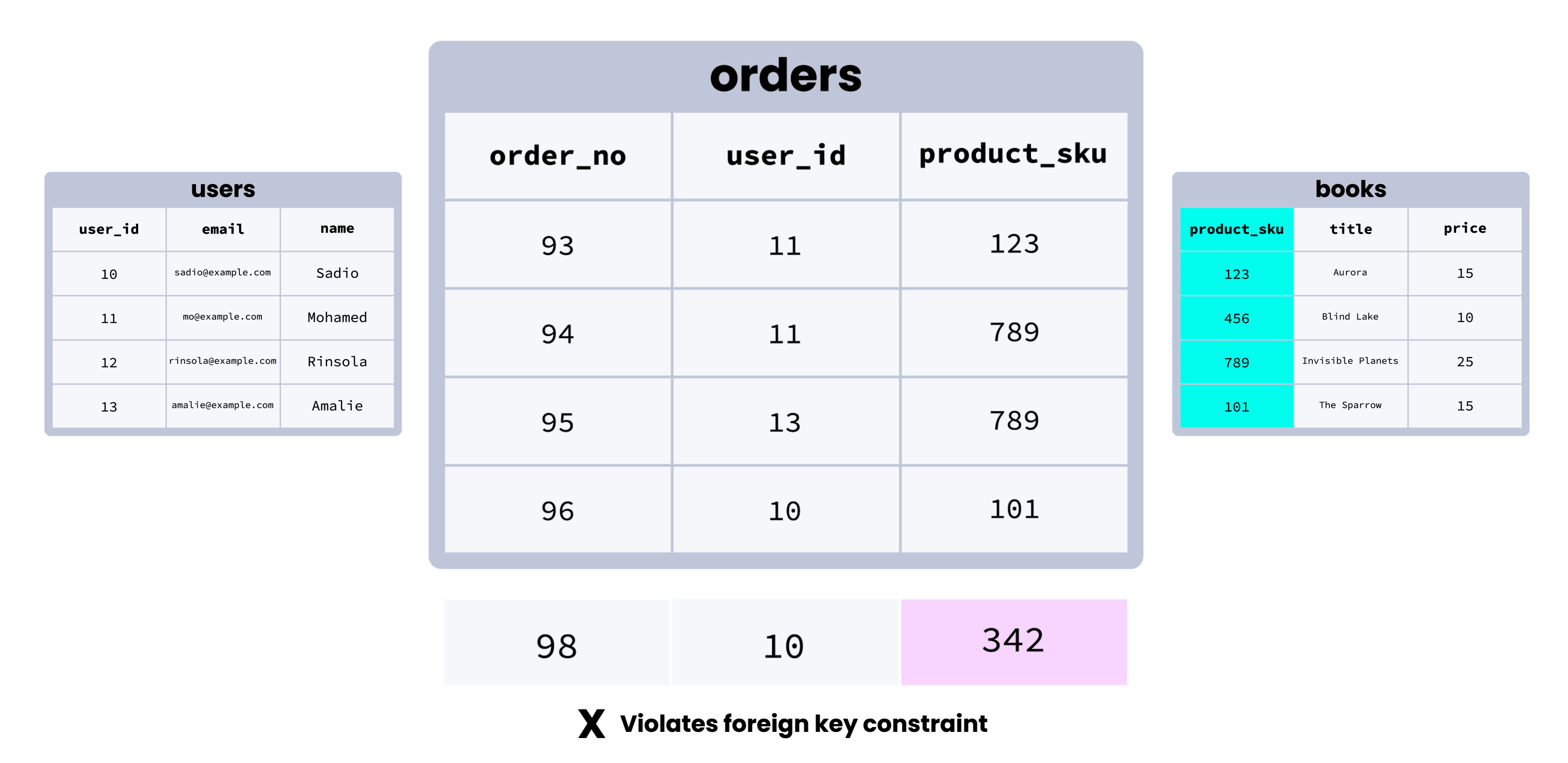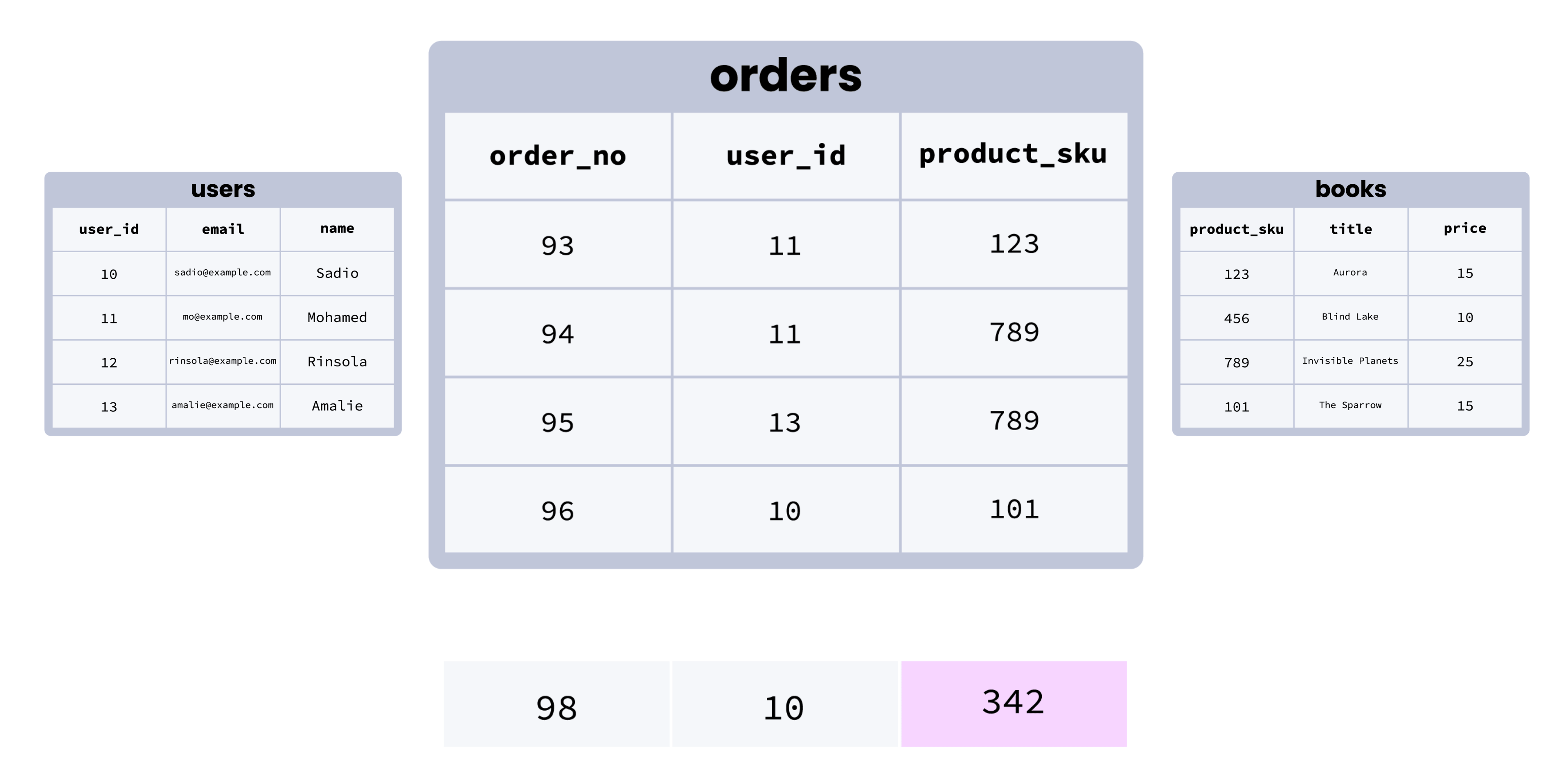
Although this is a simplified example, we can see how foreign key constraints help establish clear relationships between tables across a database, and promote consistency by making it impossible to (for example) add a row in an orders table with a user who doesn’t exist in the users table.
Note that foreign keys are not mandatory, and a table may have no foreign keys. Conversely, every column in a table may have a foreign key constraint. Where you use foreign keys depends on the specifics of the data you’re storing in your database, how different data points relate to each other, and how you’d like your data to be validated as rows are added, updated, or removed.
Why use foreign keys?
To understand why foreign keys are useful in relational databases, it’s helpful to first take a look at primary keys so that we can understand the differences, and how the two interact to enforce the rules and relationships between data (in other words, the database schema) in a database.
RELATED
3 common foreign key mistakes
Our example database
It’s easier to understand these concepts with concrete examples to look at, so we’ve set up a sample database to work with, depicted in the image below. It represents the sales database of a fictional online bookshop.
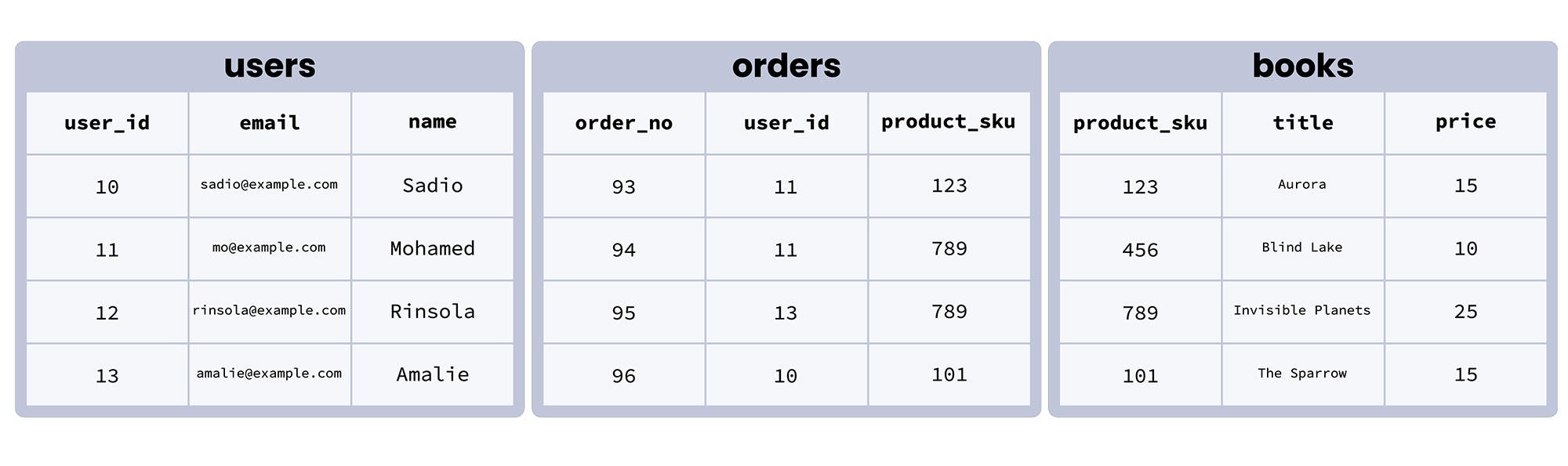
We can see that in this database, there are three tables:
userscontains data about users registered on the siteorderscontains data about specific orders placed through the sitebookscontains data about the books that are available for sale
Now that we’ve got that database in mind, let’s return to talking about the differences between primary keys and foreign keys.
What is a primary key?
A primary key is a column in a table that is used as a unique identifier for each row, and used in the table’s primary index. (Technically, a primary key can be made up of multiple columns, but for our purposes here let’s think of it as a single column).
In other words, a primary key is like a row’s ID number. Just as your government ID identifies you uniquely even if other people share your name or live at your address, a table’s primary key column identifies each row uniquely even if some of the other values in the row are shared with other rows.
A table’s primary key column thus must be unique, and it cannot be empty or NULL.
Consider the orders table in our example database. In this table, the primary key is order_no, a unique number that identifies each order individually.
In fact, in this table order_no is the only column that could be used as the primary key. user_id can contain duplicate data, since the same customer can place more than one order, and product_sku can also contain duplicate data, since two different customers might order the same product.
Here’s how our database looks with the primary key columns for each table highlighted:
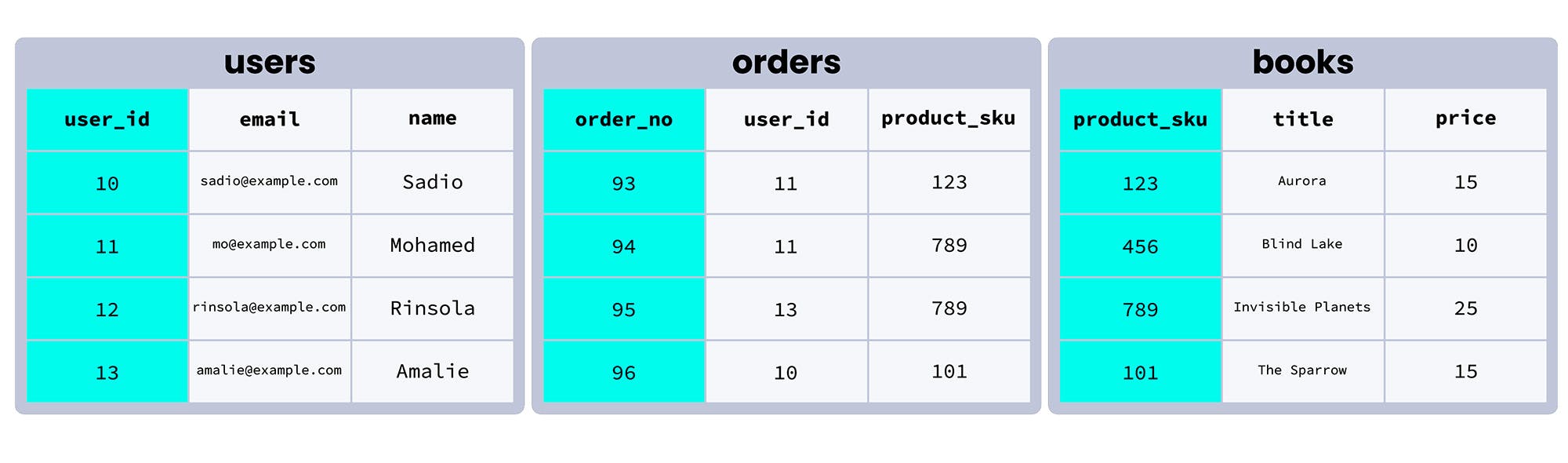
What is the difference between primary keys and foreign keys?
Let's explore primary key vs. foreign key. Primary keys serve as unique identifiers for each row in a database table. Foreign keys link data in one table to the data in another table. A foreign key column in a table points to a column with unique values in another table (often the primary key column) to create a way of cross-referencing the two tables. This is a crucial aspect of SQL keys that ensure data integrity and relationships between tables.
If a column is assigned a foreign key, each row of that column must contain a value that exists in the ‘foreign’ column it references. The referenced (i.e. “foreign”) column must contain only unique values – often it is the primary key of its table.
In short:
Primary keys are used to uniquely identify and index each row within a single table.
Foreign keys are used to link rows in two different tables such that a row can only be added or updated in
table_aif the value in its foreign key column exists in the relevant column oftable_b.
So what is the actual benefit of using foreign keys?
For a tangible example, let’s look at the orders table in our database. The user_id column here corresponds with the user_id column in the users table, and the product_sku column corresponds with the product_sku column in the books table.
When we’re setting up this table, it would make sense to add foreign key constraints to both orders.user_id and orders.product_sku:
orders.user_idshould referenceusers.user_idorders.product_skushould referencebooks.product_sku
Using these foreign keys saves us from having to store the same data repeatedly – we don’t have to store the user’s name in the orders table, because we can use orders.user_id to reference that user’s unique row in users.user_id to get their name and other information about them.
But the real purpose of foreign keys is that they add a restriction that helps establish and enforce consistent relationships within our data. Entries to the table with a foreign key must have a value that corresponds with the ‘foreign’ table column. This restriction is called a foreign key constraint.
For example, imagine we’ve set up our orders table with the foreign keys we laid out earlier: orders.user_id references users.user_id and orders.product_sku references books.product_sku. These rules mean that:
1. Any value entered into orders.user_id must already exist in users.user_id.
In other words, orders must be placed by a registered user – the orders table won’t accept a new row or a row update if the value in orders.user_id doesn’t already exist in users.user_id.
2. Any value entered into orders.product_sku must already exist in books.product_sku.
In other words, users can only order products that exist in the database – the orders table won’t accept a new row or a row update if the value in orders.product_sku doesn’t already exist in books.product_sku.
We can immediately see how even in this very simple example, foreign keys are helpful. When we look at orders in our database, we want to be able to see who ordered the items, and what items they ordered. If an order doesn’t have a valid user or product associated with it, there’s probably some kind of error, and we don’t want that invalid order to be entered into our database. The foreign keys we’ve established ensure that it won’t be – the foreign key constraints we’ve added mean that the database will reject any attempt to add or update rows in the orders table if they’re not valid. Understanding the types of keys in SQL is essential for creating relational databases that are both efficient and error-free.
How to use foreign keys in the real world
How do foreign keys actually work in practice? Let’s get practical, and learn more about foreign keys by looking at how they function in the context of a simple SQL database. Keys in SQL are not just about linking tables, but also about maintaining data consistency and integrity across the database.
How to use primary and foreign keys with SQL
For a closer look at how to create tables with foreign keys in SQL, view this helpful video from CockroachDB:
Now that we understand what primary and foreign keys are and how they work, let’s take a quick look at how we can assign these values when we’re creating a table in our database.
Note: we’ll be using CockroachDB SQL syntax. Different flavors of SQL may approach these tasks slightly differently, but we’ll stick with Cockroach since it offers a free cloud database that’s excellent for any project!
To create the orders table from our database with foreign keys:
CREATE TABLE orders (
order _no INT PRIMARY KEY,
user_id INT REFERENCES users(user_id),
product_sku INT REFERENCES
books(product_sku),
);
In the code above, we’re setting the order_no column as the primary key, and then setting rules in the form of foreign key constraints for the other two columns:
user_idhasusers.user_idas its foreign key (i.e. any values inorders.user_idmust already exist inusers.user_id).product_skuhasbooks.product_skuas its foreign key (i.e. any values inorders.product_skumust already exist inbooks.product_sku).
You can check to see what foreign keys and other constraints already exist in a CockroachDB database like this:
SHOW CONSTRAINTS FROM orders;How to handle updates, deletions, and more with foreign keys
Foreign keys give us the power to define relationships between two or more tables. This is great, but it does mean that we need to think carefully about what happens when a value that’s linked across tables is changed or deleted.
For example, let’s say that Mohamed, one of our bookshop’s customers, has requested we delete his account and all data associated with it. We could run the following query to remove him from the users table:
DELETE FROM users WHERE user_id = 11;However, the way we set up our tables currently, that will only remove the relevant row in users. Two orders associated with this user exist in the orders table too, and those won’t be removed automatically; we’d have to remember to do that manually.
Thankfully, there’s a much easier way to handle this! When we’re adding foreign keys, we can also set rules for how our database should behave if a value that’s linked across tables is changed.
For example, with a CockroachDB database, we could create a table like this:
CREATE TABLE orders (
order _no INT PRIMARY KEY,
user_id INT NOT NULL REFERENCES users(user_id) ON DELETE CASCADE ON UPDATE CASCADE,
product_sku INT NOT NULL REFERENCES books(product_sku)ON DELETE CASCADE ON UPDATE CASCADE,
);In the code above, ON DELETE CASCADE and ON UPDATE CASCADE specify that when a row is deleted or a value is updated (respectively) in one table, the same operation should be performed on the linked value or row in other tables.
So, if we built our table like that and then ran the query DELETE FROM users WHERE user_id = 11;, the data associated with Mohamed (user 11) would be deleted from the user table and orders associated with his account would also be deleted from the orders table.
Similarly, we could run this query…
UPDATE users
SET user_id = 100
WHERE user_id = 11;…and Mohamed’s user_id value in users would be updated from 11 to 100, and the user_id value associated with his orders in the orders table would be updated, too.
Depending on the circumstances, we might prefer that our database do something different. For example, we could also use ON DELETE SET NULL to set the all columns of a referencing row to NULL if the row in the table it’s referencing is deleted. We can also specify that we want the database to take NO ACTION, although this isn’t strictly necessary, as this is the default rule the database will follow if we don’t specify another action for it to take.
The full range of actions we can use with foreign keys is detailed in the CockroachDB docs. You can also check out a quick walkthrough video below on how to change foreign keys without impacting users:
Test yourself: have you mastered foreign keys?
Refresh yourself with our imaginary database, and the foreign key constraints we added to the orders table earlier in this article (orders.user_id references users.user_id and orders.product_sku references books.product_sku):
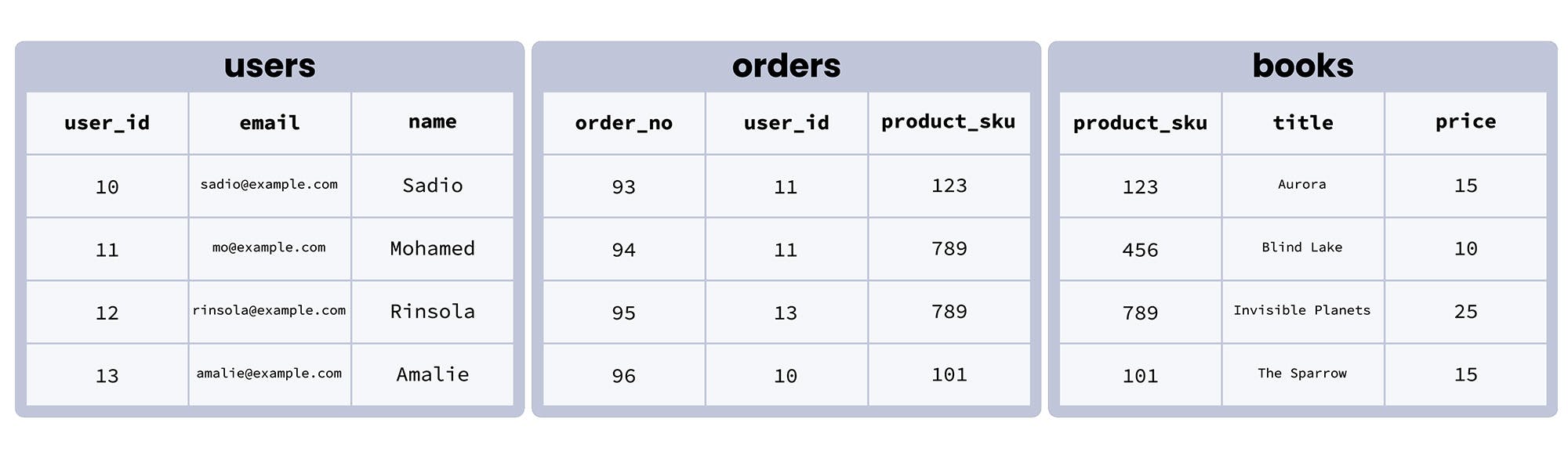
Now, see if you can answer the following questions:
- What are foreign keys in SQL?
- What are keys in SQL?
- What are primary keys in SQL (primary key SQL)?
Next, try this exercise:
What would be the result of running the following SQL command?
INSERT INTO orders (order_no, user_id, product_sku)
VALUES (97, 14, 456);Answer: It would result in an error and the row would not be inserted, because the user_id value 14 does not exist in users.user_id.
Does the books table have any foreign key constraints?
Answer: No, and in this case it doesn’t need any. Although the orders table references books.product_sku, none of the columns in the books table correspond with values in other tables in a way that would make adding a foreign key constraint beneficial.
What would be the result of running the following SQL command?
INSERT INTO orders (order_no, user_id, product_sku)
VALUES (412, 10, 101);Answer: It would result in a new row with those values being added to the orders table, because it meets all of the constraints that the primary and foreign keys impose on orders’s columns:
412is a unique value that doesn’t already exist inorder_no, and is thus valid (the primary key constraint)10is a user ID that corresponds with an existing user inusers.user_id, and is thus valid (a foreign key constraint)101is a product SKU that corresponds with an existing book inbooks.product_sku, and is thus valid (a foreign key constraint)
Go hands-on!
Want to build a little real-world experience with foreign keys and try working with this database for yourself in the cloud? Don’t worry, it’ll only take a few minutes!
Step 1: sign up for a free Cockroach Cloud account, and follow the instructions there to create a cluster.
Step 2: Follow the instructions here to install CockroachDB locally. If you’ve already installed it, you can skip this step.
Step 3: Download this .sql file, which contains the SQL queries needed to create the database pictured above. Run the following command in your terminal and the data and tables will be automatically added to your cluster’s defaultdb database.
(Note that you need to replace some of the details in the command below with details specific to your Cockroach Cloud account, and be sure you’ve specified the correct directories for your foreign_keys.sql and cc-ca.crt.)
cat foreign_keys.sql | cockroach sql --url 'postgres://username:password@free-tier.gcp-us-central1.cockroachlabs.cloud:26257/defaultdb?sslmode=verify-full&sslrootcert=cc-ca.crt&options=--cluster=cluster-name'
Step 4: Run the following command in your terminal to start up the CockroachDB SQL shell and connect to your CockroachDB Dedicated cluster:
cockroach sql --url 'postgres://username:password@free-tier.gcp-us-central1.cockroachlabs.cloud:26257/defaultdb?sslmode=verify-full&sslrootcert=cc-ca.crt&options=--cluster=cluster-name'
You’re in! Feel free to poke around. The CockroachDB docs on foreign keys will be a useful reference. Some questions to get you started:
What happens if you try to drop the
userstable?What would happen in
ordersif a user’s account was deleted? (Hint:SHOW CONSTRAINTS FROM orders;)Can you change the foreign key constraints in the orders table to perform a different action when a linked value is deleted?
Can you add new columns to these tables and link them with foreign keys?


