
CockroachDB was designed to be the open source database our founders wanted to use. It delivers consistent, scalable SQL in a distributed environment. Developers often have questions about how we've achieved this, and our short answer is this: Distributed SQL. Our long answer requires a deeper understanding of CockroachDB’s unique architecture.
You definitely don’t need to understand the underlying architecture of CockroachDB in order to use CockroachDB. This blog series on the architecture of CockroachDB gives serious users and database enthusiasts a high-level framework to explain what's happening under the hood.
Today, we’re exploring the lowest layers of CockroachDB: the key value (KV) store.
Why CockroachDB Converts SQL to a Distributed Key Value Store
At the highest level, CockroachDB converts clients' SQL statements into key-value data, which is distributed among nodes and written to disk. Our architecture is the process by which we accomplish that, which is manifested as a number of layers that interact with those directly above and below it as relatively opaque services.
The bottom layer of that architecture is a key-value store. More specifically, it’s a distributed, replicated, transactional key-value store, and we’ll go over all those terms in this post. But at the top layer, ultimately, CockroachDB is exposed as a relational database. It speaks SQL, the lingua franca of data, and is wire compatible with Postgres. (To better understand which standard SQL features CockroachDB supports, you can check out our documentation on CockroachDB’s SQL Feature Support.)
So: how do we get from SQL to a KV store? And why?
Is CockroachDB a Distributed SQL Database or a Distributed Key Value Store?
CockroachDB is a distributed SQL database that’s enabled by a distributed, replicated, transactional key value store. The key value layer is only available internally, because we want to be able to tailor it to the SQL layer that sits on top, and focus our energies on making the SQL experience exceptional.
In fact, the CockroachDB project began as a key-value store, and SQL layer came after the fact. We knew when starting that a distributed key-value API was not the endpoint we wanted to provide. We wanted a higher level structured data API that would support tables and indexes. After lots of soul searching, we embraced the inevitable and moved forward full-speed with SQL as the core of our structured data layer in 2015. Here’s what the underlying key-value store enables:
It facilitates efficient distribution of data within the database
It bakes in natural separation for distributed transactions
Atomic columns enable
It’s extendable, which lets us add functionality like
Ultimately, this allows CockroachDB to retain the efficiency of a KV store but gain the natural ability to distribute data, and still speak SQL.
A Tour of CockroachDB’s Key-value Store
As mentioned, the bottom layer of CockroachDB is a distributed, replicated transactional key-value store. Let’s go over that, term by term. A key-value store means that it contains keys and values. Keys and values are arbitrary strings. This means when you store data in a Cockroach table, CockroachDB stores that data as a key and a value. The key is the thing we want to sort things on, and then the value is each of the columns that we want to store for that particular key. Let’s go over an example.
Let’s say we want to create a DOGS table of all the office dogs at Cockroach Labs. In a traditional database, when we want to create a table, the SQL and subsequent table entry might look like this:
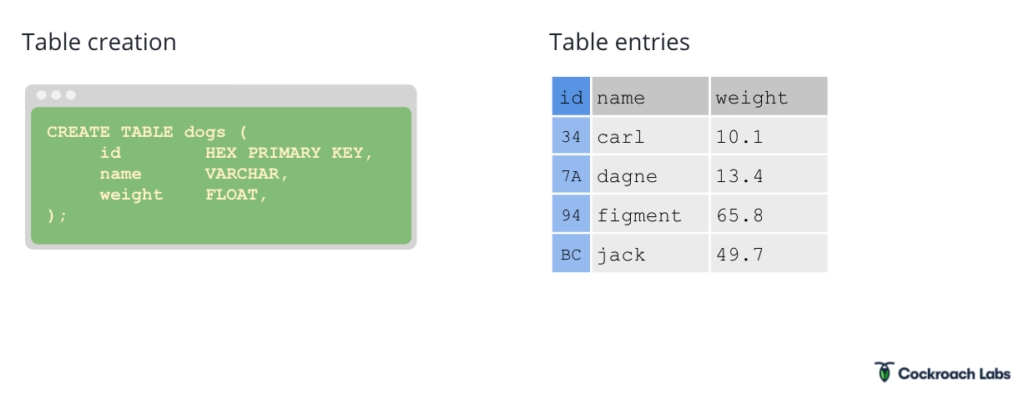
Our table entries have an ID--some random arbitrary unique ID--the dog’s name, their weight, and any other information we might want to store. In CockroachDB, this is still what it looks like to the end user. But under the hood, it’s doing something very different from a traditional SQL database. It’s storing tabular data in a monolithic sorted map of KV pairs, where every table has a primary key, there is one key/value pair per column, and keys and values are all strings:

Ultimately, much deeper encoding of the keys occurs within the database to:
Create massive efficiencies for access of data through sorting
Ensure against NULL values
Maintain integrity
We use multi-version concurrency control to process concurrent requests and guarantee consistency, which means that the keys and values are never updated in place. Instead, in order to update a value, you write a newer value and that shadows the older versions. Tombstone values are used to delete values. What this provides is a snapshot view of the system for transactions. We describe CockroachDB as having a model with the key space; that means there aren't separate key spaces used by different tables, it uses one big key space and we just do tricks with how we structure the keys.
Here’s a depiction of what the monolithic key-space looks like, divided into ranges:
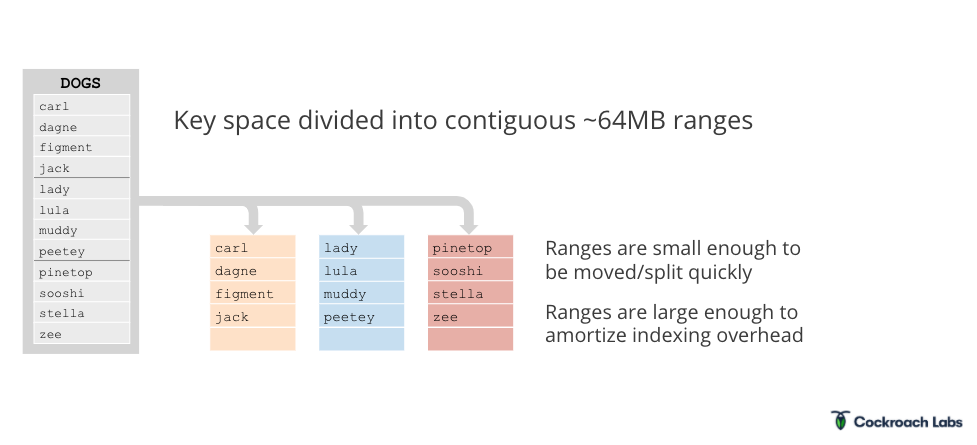
It's a monolithic key-space ordered by key and divided into 64-megabyte ranges. Sixty-four megabytes was chosen as an in-between size; it’s small enough for ranges to be moved around and split fairly quickly, but large enough to amortize an indexing overhead. As a side note, ranges don't occupy a fixed amount of space; they only occupy the space that they're consuming and they grow and they shrink as data is added to them and deleted from them.
Efficient Range Scans
Let’s say I want to do a range scan for the keys between muddy and stella in our DOGS table. Because the keys are ordered, we can do a really efficient range scan.

You might notice that this diagram looks very much like a B-tree. That’s part of what enables the speedy scans. You could imagine this range, the second range, and the third range are all living on different nodes within the cluster. If I want to do a range scan, I would have to go to every single node across the database. That's not very efficient. But with this architecture, we can actually do it just across these small ranges. Because everything is lexicographically ordered, we can do some very efficient range scans within CockroachDB.
Range Splitting: Automated Sharding
Transactions are used to insert and delete data into ranges. We’ll go into transaction details in another post, but for now, let’s use a simple example to show how they affect ranges. Let’s say a co-worker adopts a new dog named Sunny, and we need to add sunny to DOGS. If the Raft leader of the range indicates that there’s space for sunny, it’ll insert as expected. We go into the indexing structure, we see this corresponds to range three. We go to range three and we can insert the data, and then the insert is done.

But what if there’s not space in the 64 MB range? What if someone else adopts a dog, and there’s no space in the range for the new dog, rudy?
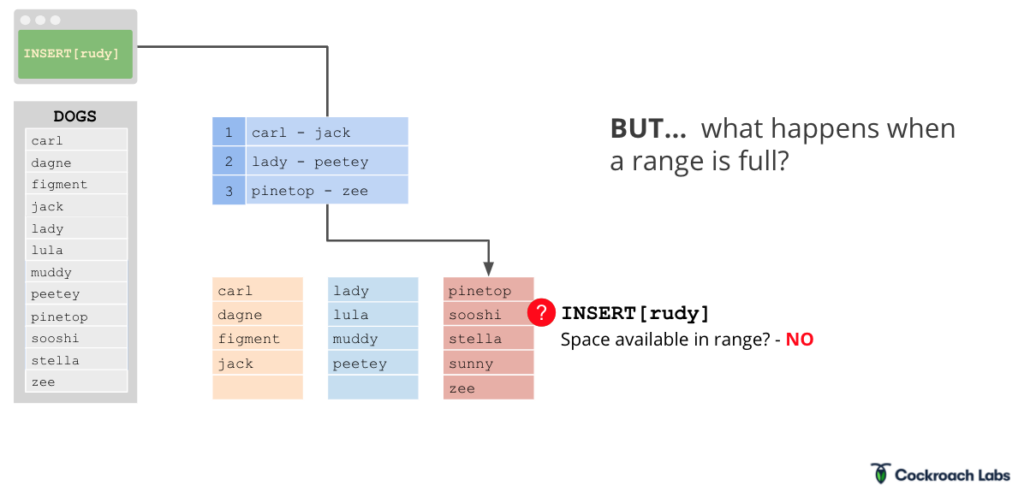
If this were a Postgres instance, we’d need to shard the database to solve this problem. But because Cockroach is a distributed SQL database built on a distributed key value store, it shards for you, creating a fourth range:
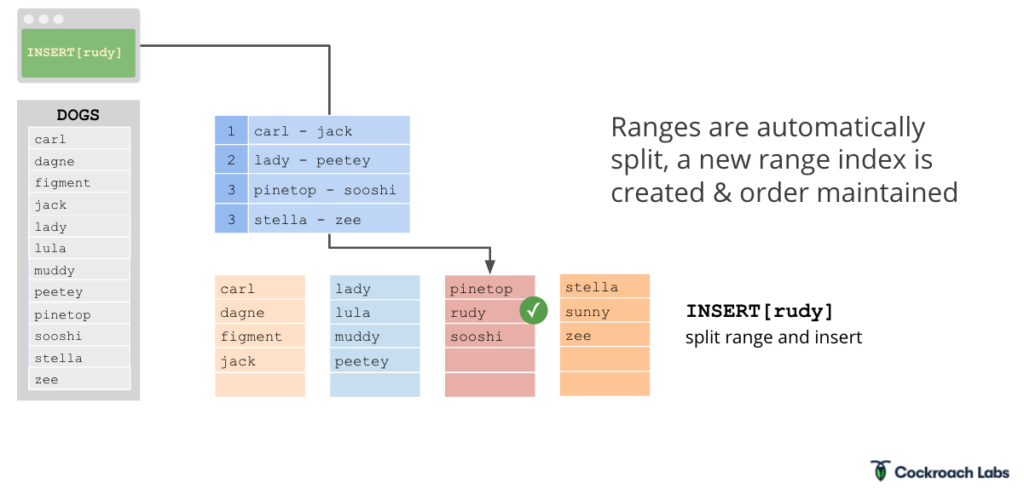
Splitting the range involves printing a new replica, a new range, moving approximately half the data from the old range into the new range, and then updating the indexing structure. The way this update is performed, it's using the exact same distributed transaction mechanism that we were using to insert data into range itself.
Where does key value data live in CockroachDB?
Another important thing to note about key-value data in CockroachDB: it's stored down on a local key-value store. We use Pebble for that purpose. The 20.1 release of CockroachDB last May introduced Pebble as an alternative storage engine to RocksDB. With the release of 20.2 this fall, Pebble will become CockroachDB’s default storage engine.
We’ll keep working our way up through the levels of CockroachDB in this blog series, but if you’d like to learn more about the architecture of CockroachDB, you can read our docs or watch the full webinar on the subject here.
Watch the Full webinar: The Architecture of a Distributed SQL Database


