
I ended an amazing internship this past fall on the KV (Key-Value) team at Cockroach Labs (responsible for the transaction, distribution and replication layers of CockroachDB). This blog post delves into my work on adding native support for creating hash sharded indexes in CockroachDB, as a way to significantly improve performance on sequential workloads.
CockroachDB uses range partitioning by default, as opposed to hash partitioning. As explained in our CTO Peter Mattis’s blog post, a key-value store with range partitioning resembles a distributed balanced tree whereas one with hash partitioning is closer to a distributed hash map. In particular, range partitioning outperforms hash partitioning for the most common SQL workloads like range scans. However, load under range partitioning can become imbalanced for access patterns that focus on a specific range of data, since all traffic is served by a small subset of all the ranges. Sequential insert traffic is a common example of such an access pattern and is much better suited to hash partitioning.
While it was possible to achieve hash partitioning in CockroachDB with a bit of SQL wrangling, it required relatively in-depth knowledge of how CockroachDB worked. Additionally, the syntax, when hashing multiple columns (of all the various SQL data types), gets unwieldy. Hash sharded indexes allow users to use hash partitioning for any table or index in CockroachDB.
Ranges
In order to understand why hash sharded indexes are important, it’s helpful to know how the KV layer (which handles distribution and replication of data) works in CockroachDB.
At the lowest level of CockroachDB lies a distributed, replicated, transactional key-value store. This key-value store holds a global key-space that all SQL tables and indexes are mapped to. Now this key space is divided into sorted contiguous chunks called “ranges”, with each range being a certain maximum size (which is configurable). A new CockroachDB cluster essentially starts off with a single range, which then splits/merges into more or less ranges as data is added/removed. These ranges are replicated and stored on nodes that are part of a CockroachDB cluster. Each range is a consensus group, based on the Raft protocol.
RELATED
How to build a payments system that scales to infinity (with examples)
When we create an index on a CockroachDB table, we essentially create a new set of ranges that hold the set of index columns and the set of primary key columns, ordered by the set of index columns. The latter allows CockroachDB to locate the range entry for the full row, given a set of values for its index columns. So, ranges of a SQL table are ordered by the set of primary key columns whereas ranges of a secondary index are ordered by the set of columns in the index.

Motivation
Due to the fact that ranges are ordered by keys, workloads with sequential keys will cause all traffic to hit one of the boundaries of a range.
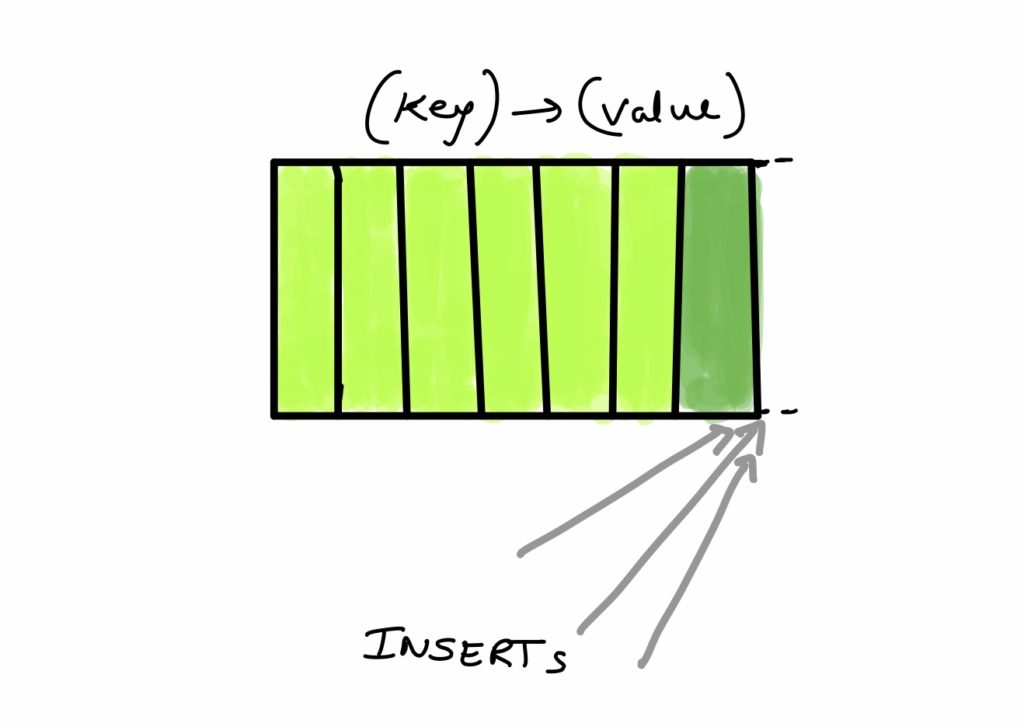
CockroachDB tries to split frequently accessed ranges into multiple smaller ranges (referred to as load-based splitting). It also tries to redistribute these ranges across the cluster based on load, in order to achieve an even load distribution in the cluster.
However, in order to split a frequently accessed range, the system looks for a point in the range that would divide the incoming traffic roughly evenly. In case of a sequential workload hitting one of the boundaries of a range, there is no such split point. This leads to a single range hotspot. Data simply gets appended to the end of a range until it reaches its maximum size threshold and then to the end of a new range. This means we don’t get many of the benefits of a “distributed” database, as our query performance is bottlenecked by the performance of one single node (i.e. the Raft leader of the concerned range).
One way to alleviate these kinds of single range hotspots is to prefix the concerned primary or secondary index with a computed shard column. This would convert the incoming sequential traffic on a key into uniformly distributed traffic, which allows load-based splitting to split the concerned range at a point that divides the incoming traffic evenly.
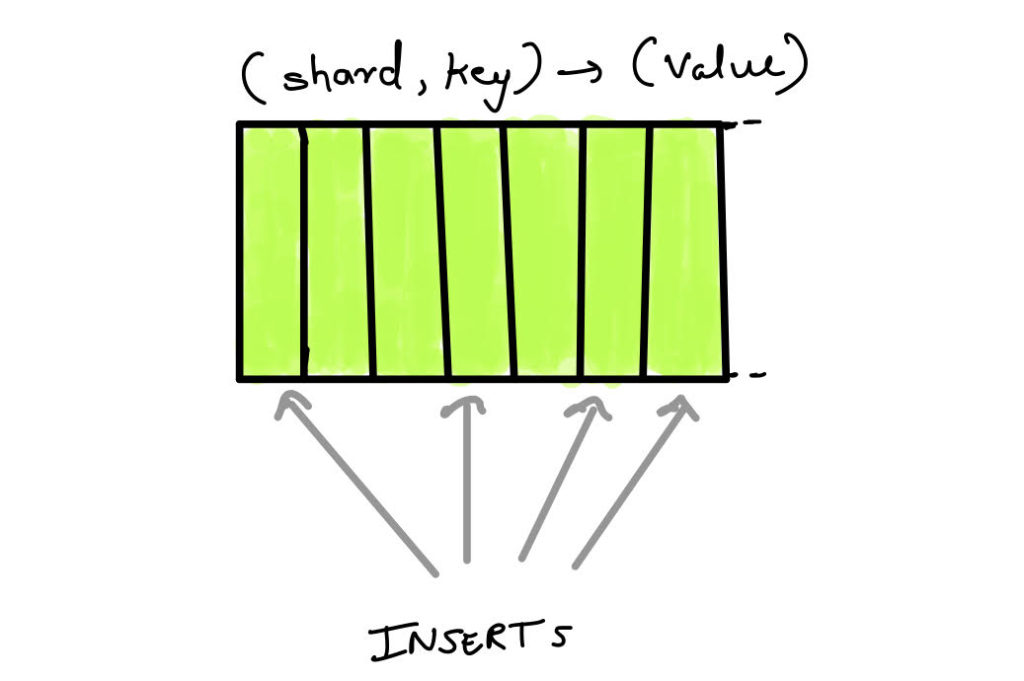
However, as mentioned before, this hash partitioning scheme was complicated to implement in CockroachDB.
Why do hash sharded indexes matter?
In order to demonstrate why single range hotspots are bad, and to show the performance implications of hash sharded indexes, we wrote a benchmarking tool that measures the maximum sustained throughput a given cluster can support while keeping the average latency below a specified threshold (which is 10ms for the following benchmarks).
Consider the following table:
CREATE TABLE kv (
k INT8 NOT NULL,
v BYTES NOT NULL,
PRIMARY KEY (k)
);
We look at how a sequential write workload performs on kv, across two types of schemas: one based on CockroachDB’s default range partitioning (“Unsharded”) and another based on hash partitioning (“Sharded”), where the primary key is sharded into 10 buckets. We show performance for increasingly larger clusters (5, 10 and 20 nodes, respectively) in order to demonstrate how we can unlock linear scaling for sequential workloads by using hash partitioning instead of the default:

Avoiding single range hotspots in sequential workloads allows CockroachDB’s various heuristics to spread the load out evenly across all the nodes in the cluster. This is further proven by the CockroachDB admin UI metrics:
For the unsharded schema:

This graph indicates that all traffic was served by a single node. The dips are caused when data from the benchmark run periodically exceeds the maximum range size threshold and all traffic has to go to a new range, and CockroachDB tries to colocate the range’s leaseholder and Raft leader, interfering with all write traffic on the index/table.
For the sharded schema:
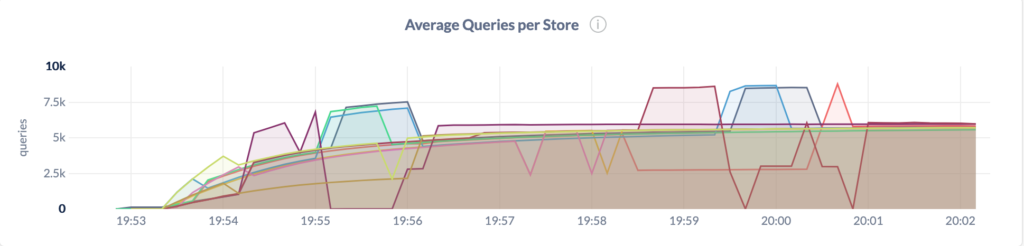
Notice how in this case, the incoming traffic evens out, over time, as the various heuristics in CockroachDB figure out a good distribution of the table’s ranges across the cluster’s nodes. Again, this is unlike the unsharded case where one of the nodes is serving all of the traffic.
Hash sharded indexes in an IoT use case
Now that we understand why hash sharded indexes are useful, let’s dive into how one would use them in CockroachDB. Consider the following use case:
Imagine we have an Internet-of-Things application where we are tracking a bunch of devices and each device creates events. Sometimes we want to know which devices published events in some time period. We might start with the following schema:
CREATE TABLE events (
product_id
INT8,
event_id
UUID,
ts
TIMESTAMP,
PRIMARY KEY (event_id),
INDEX (ts, event_id, product_id)
);
Given that new events occur roughly in the present, this schema would have a hotspot on INDEX (ts, event_id, product_id). At any point of time, all writes would go to the one range that happens to be responsible for the current set of timestamps. We can alleviate this hotspot by using hash partitioning for this time ordered index. Hash sharded indexes are meant precisely for situations like this.
In 20.1 (with new syntax):
In 20.1, CockroachDB will introduce the following syntax in order to natively support hash sharded indexes, in order to achieve hash partitioning. This syntax was inspired by SQLServer and Postgres:
USING HASH WITH BUCKET_COUNT = <number of buckets>
Thus, [1] the statement to create events with a sharded secondary index would look like:
CREATE TABLE events (
product_id UUID,
event_id UUID,
ts TIMESTAMP,
PRIMARY KEY (event_id),
INDEX (ts, event_id, product_id) USING HASH WITH BUCKET_COUNT = 8
)
In 19.2 and below (without the new syntax):
In order to achieve hash partitioning for a table like this in CockroachDB 19.2 and below, we would have to create a computed shard column (with a check constraint to aid the optimizer in creating better query plans) and then prefix the concerned index with this shard column [2]:
CREATE TABLE events (
product_id
UUID,
shard
INT8
AS (fnv32(
to_hex(product_id),
ts::STRING,
event_id::STRING
)
% 8) STORED
CHECK (shard IN (0, 1, 2, 3, 4, 5, 6, 7)),
event_id
UUID,
ts
TIMESTAMP,
PRIMARY KEY (event_id),
INDEX (shard, ts, event_id, product_id)
);
We can see that, even with a relatively simple table, this is already starting to get heavy and it’s not hard to imagine a case where the syntax would get gnarly when the index is based on more columns of heterogeneous SQL data types. Additionally, we would have to be careful not to use a slow hash function as this will negatively affect all INSERT performance on the table.
In 20.1 CockroachDB’s new hash sharded index syntax will transparently shoulder all of this burden of hashing, creating the computed shard column and installing a check constraint. It will also handle the management of these shard columns and check constraints as these sharded indexes are added or removed. New improvements to CockroachDB’s query optimizer allow the system to generate better constrained plans for tables with hash sharded indexes. Additionally, in 20.1, CockroachDB will also support altering primary keys so users will be able to shard a table’s primary key without having to create an entirely new table.
The new syntax used in statement [1] would create essentially the same schema as the one in statement [2]. The same syntax can also be used to shard primary keys or secondary indexes in a CREATE INDEX DDL statement.
Summary
To recap, CockroachDB uses range partitioning by default, which is a good default choice for many reasons, but results in single range hotspots in sequential workloads. The new syntax allows users to instead use hash partitioning for tables/indexes that expect this kind of workload. This unlocks linear throughput scaling by the number of nodes in the CockroachDB cluster.
Working at Cockroach Labs
My internship at Cockroach Labs has easily been my most educational one. The KV team had the most collaborative and open culture I’ve ever witnessed, which helped me gain a ton of insight into the competitive distributed database landscape. I owe a big thanks to my mentor Andrew and teammates Dan, Nathan and Rohan for answering my incessant questions and for their extremely detailed code reviews. It was an easy decision for me to come back full-time. If you’d like to work on interesting problems at the intersection of distributed systems and databases, we’re hiring!


