



Every business, from global SaaS service vendors to the tiniest brick-and-mortar retailer, has to deal with payment processing…With one very important difference: If their payment processing system goes down, that small town shop can simply accept cash from their customers. A large enterprise, however, can’t make any sales until service is restored.
These are the companies counting on always-on payment services But building a never-down system that can deal with payments efficiently and at scale is challenging indeed, due to some very complex requirements:
Temporary significance with long-term necessity: While an actual transaction might last only 60-90 seconds, the associated data needs to be preserved for years for purposes ranging from refunds to audits.
High-volume data management: Successful businesses generate a lot of payments data as they scale. Storing all of this data while keeping it available (and, in many countries, in compliance with data regulations) while also keeping application performance high is extremely challenging.
Critical accuracy and consistency: Customers (and auditors) are not forgiving when it comes to money.
High availability: Uptime is critical, since even a very small amount of downtime could equate to big expenses. Lost revenue is bad, but lost customer trust can be literally unrecoverable.

Imagine a payments system outage during halftime. Just a few minutes of downtime can easily mean a major loss of revenue.
Let’s take a look at how payments work, and how to build systems that can meet all of the above requirements. If you’d prefer to watch a video about payments systems architecture, you can check out this interview with FinTech engineering veteran Andy Kimball.
What are the core mechanics of a payments system? 
First, it’s worth taking a look at how payments actually work.

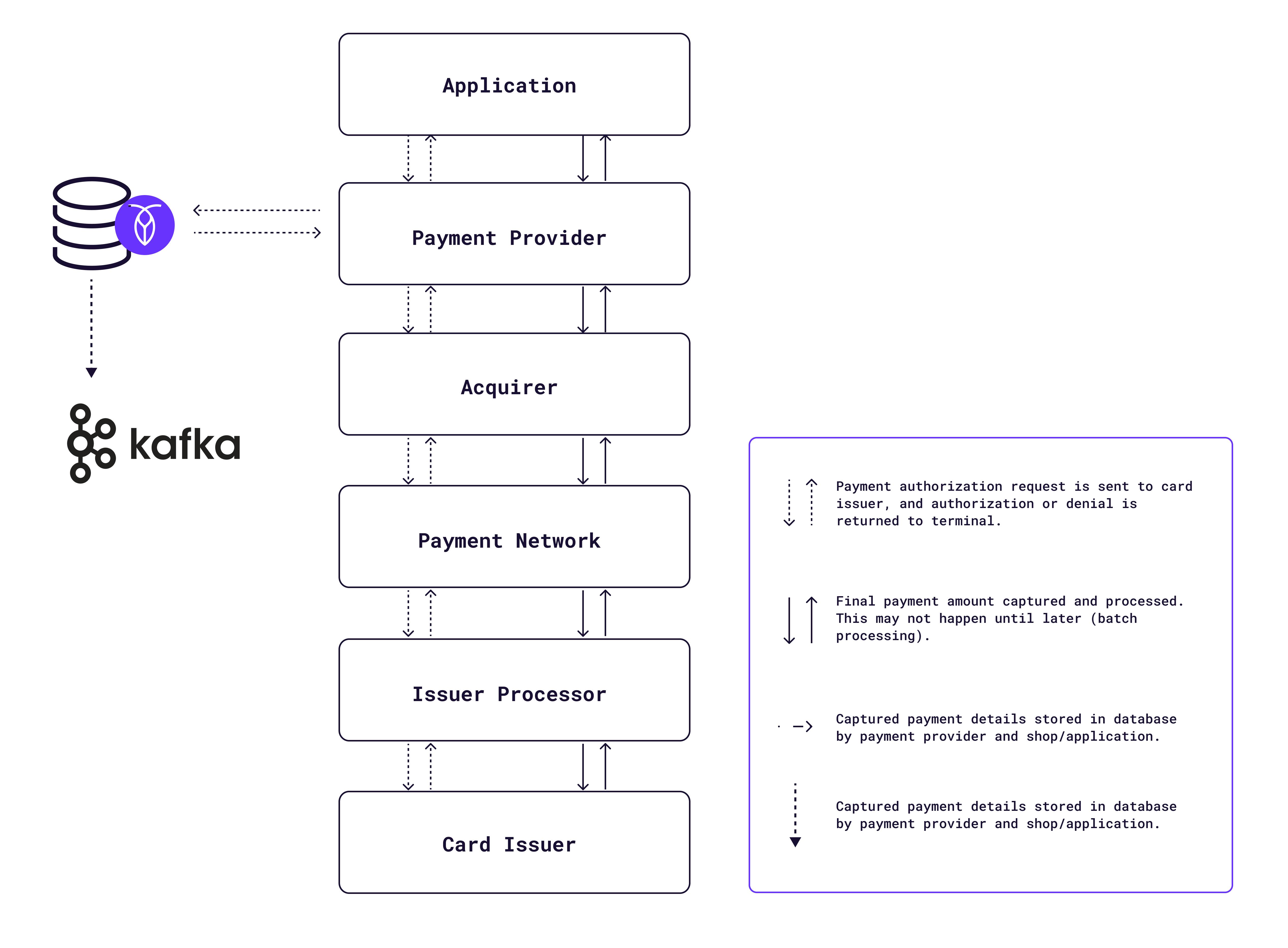
How payments are processed: Whether for an online or physical store, the payment process is fairly standard. A payment authorization request is made through the terminal to the payment provider and routed through to the customer's bank for approval. Post-approval, the information traverses back through the same chain to the terminal. Details of the transaction are logged in databases (and possibly data warehouses) using systems like Apache Kafka.
From authorization to capture: Once authorized, the terminal captures the payment. The captured amount may be different from the amount in the initial payment request in some cases (due to tips, etc.). The capture transaction follows the same path as the authorization request, but may not be as instantaneous: for efficiency, these transactions are often cached and then processed in bulk (for example, once per hour). Generally, both the originating SaaS application, retailer, etc., and the payment provider will also store the payment capture data in a transactional database.
Why is scale the biggest challenge for payments databases?
The actual process of storing payment data in a database isn’t complex or particularly different from storing other types of data. For many businesses, meeting the consistency and accuracy requirements for payments can be managed with ACID-compliant SQL databases at smaller scales. At smaller scales, the consistency and correctness requirements for payments are easy enough to meet with the ACID transactional guarantees offered by most SQL databases.
However, as a company finds success and transaction volume increases, even robust databases like Postgres or MySQL can quickly become performance bottlenecks under the load of continuous high-volume transactions. A single Postgres or MySQL instance, for example, should perform very well for an application that’s only getting a few transactions per minute. But even a moderately successful business can quickly get to a point of dealing with hundreds of payments per minute on average, with much higher spikes during peak periods.
How can payment systems scale without sacrificing correctness?
Maintaining performance as your business grows requires finding a solution that allows you to scale up your payments database without sacrificing correctness or availability.
Manual sharding: the traditional approach
The traditional approach to scaling a relational database like (for example) MySQL is manual sharding. This makes it possible to scale horizontally – you simply break your payments table into multiple shards running on multiple machines, and configure your application logic to route payment requests to the relevant shard or shards in a way that spreads the load so that no single machine gets overworked and becomes a bottleneck. Over time, as the company scales, you simply add more machines and more shards.
This approach certainly works, and at first it can even present an interesting engineering challenge. However, sharding requires either a lot of direct manual work or a really sophisticated automation/ops setup (which itself requires a lot of manual work). Each time you need to scale the database up, that work becomes more complex, as you’re increasing the number of separate shards your application has to deal with…While paying for yet another database instance.
In short, sharding is bad for business.
The diagram below depicts a company that has needed to shard its traditional SQL database at four separate points as the volume of transactions grew along with its business success in the marketplace:
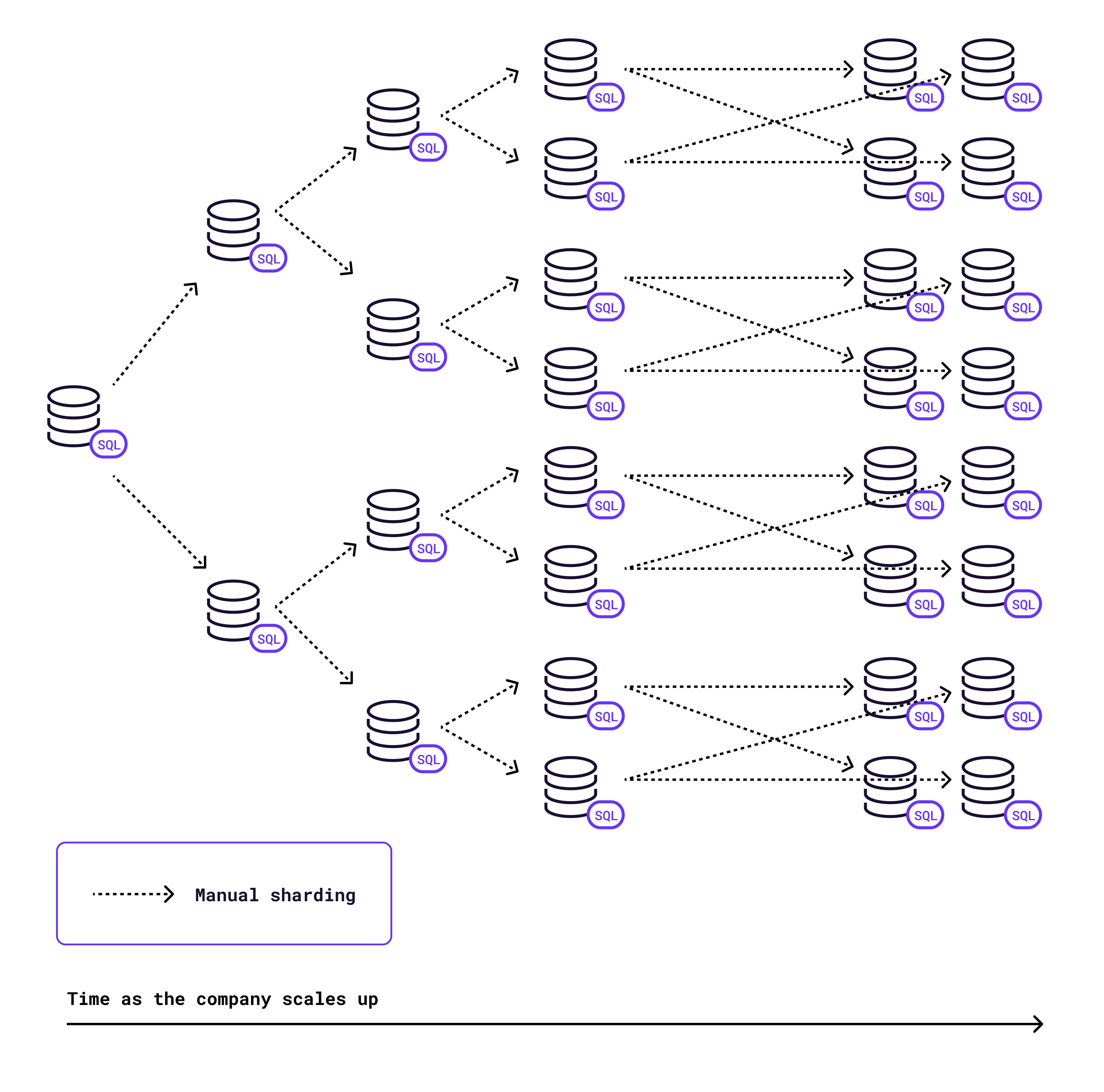
The company begins with a single SQL database. When their workloads overwhelmed that initial database, they split it into two instances…then four…then 8…then 16. Each time they shard the database, they are also doubling the complexity of their setup. And that’s just the beginning! A highly successful company might need 64 or more separate shards to be able to maintain performance.
What may start as a fun technical challenge quickly turns into something frustratingly Sisyphean. As long as your company grows, you can’t solve the problem of manual sharding. You are doomed to return to it, again and again, each time more scale is needed.
Additionally, scaling geographically may ultimately require that specific data, such as customer data, be stored in specific locations for performance and/or regulatory reasons. These requirements add an additional layer of complexity to the sharding problem, and may require re-sharding to ensure that all data is stored in shards that are physically located in the right places.
RELATED
Banking resilience at global scale with Distributed SQL
How does distributed SQL enable automated scaling for payments?
Thankfully, that’s not the only approach! Modern distributed SQL databases can offer the same ACID guarantees as traditional relational DBMS together with the easy horizontal scaling of NoSQL.
For example, here’s how that same company’s scale-up process would look like for the same growth curve, but using CockroachDB:
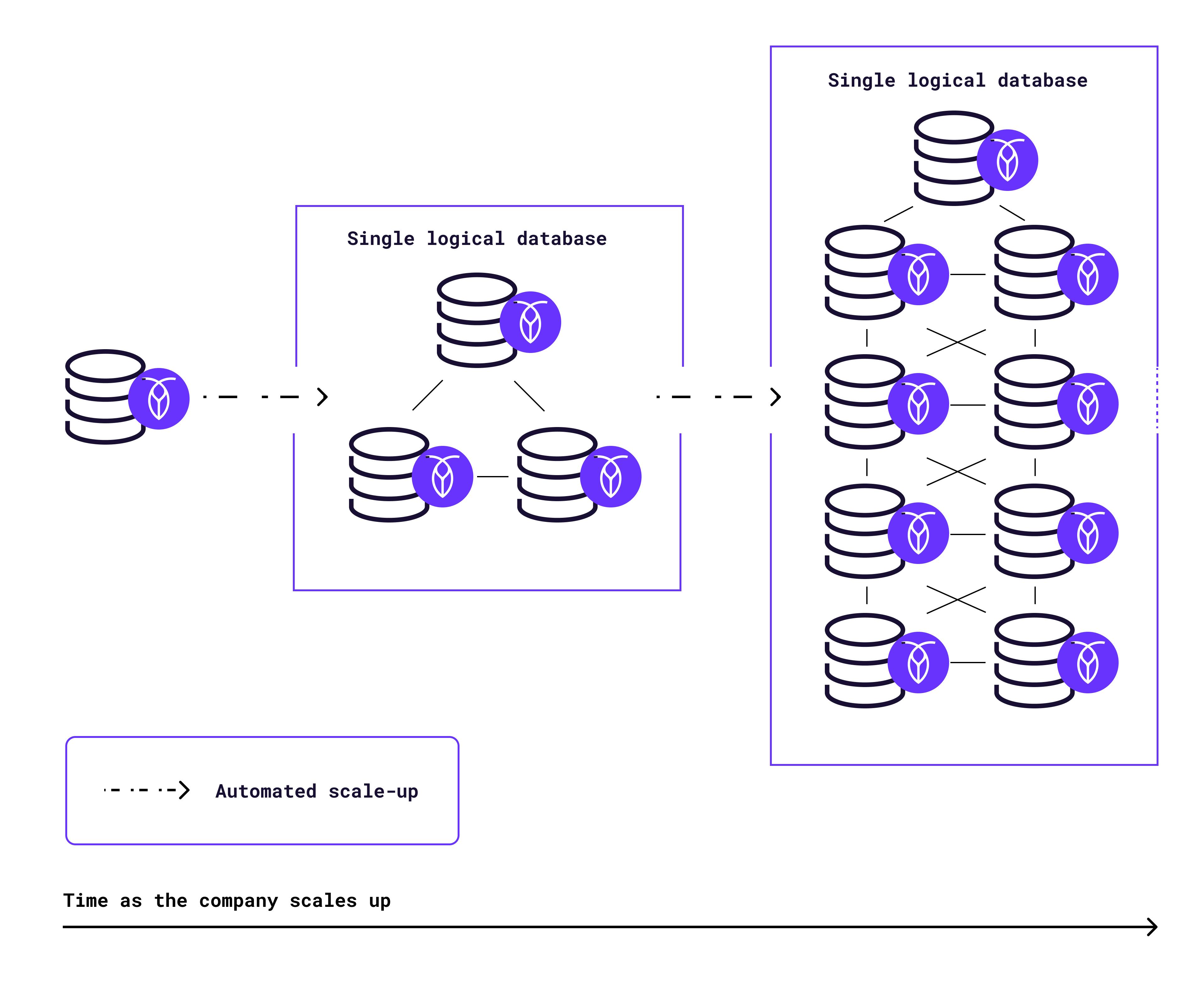
Note that in the diagram above, no manual work is required. Depending on the method of consumption, CockroachDB either scales entirely automatically based on your configuration,or by simply adding nodes — a process that takes less than a minute.
More importantly, regardless of the number of nodes your CockroachDB cluster is running on, nothing about your application logic has to change. With a sharded database where you’re creating multiple instances of the same table, developers have to manually intervene and write flows to ensure requests go to the right shard – which is both laboriously time consuming and can introduce errors. CockroachDB can always be treated as a single logical database.
This feature also makes scaling geographically much simpler. CockroachDB allows table- and row-level data homing, making it easy to assign rows to specific geographic regions. But developers don’t have to think about this complexity and can still treat CockroachDB the same way they’d treat a single Postgres instance. The database handles the geographical distribution and data replication – all of that manual sharding work – automatically.
Visually, this is how a sharded MySQL database compares to CockroachDB. In the first illustration, requires complex manual data routing logic to read and write data to and from the appropriate locations. This means every time the database scales, at least part of the application needs to also be updated.
With CockroachDB, the application just communicates payment information to a single payments table, and the database automatically handles data partitioning, load balancing, and routing. No matter how many nodes are created, and no matter where they are located, the application stays the same.
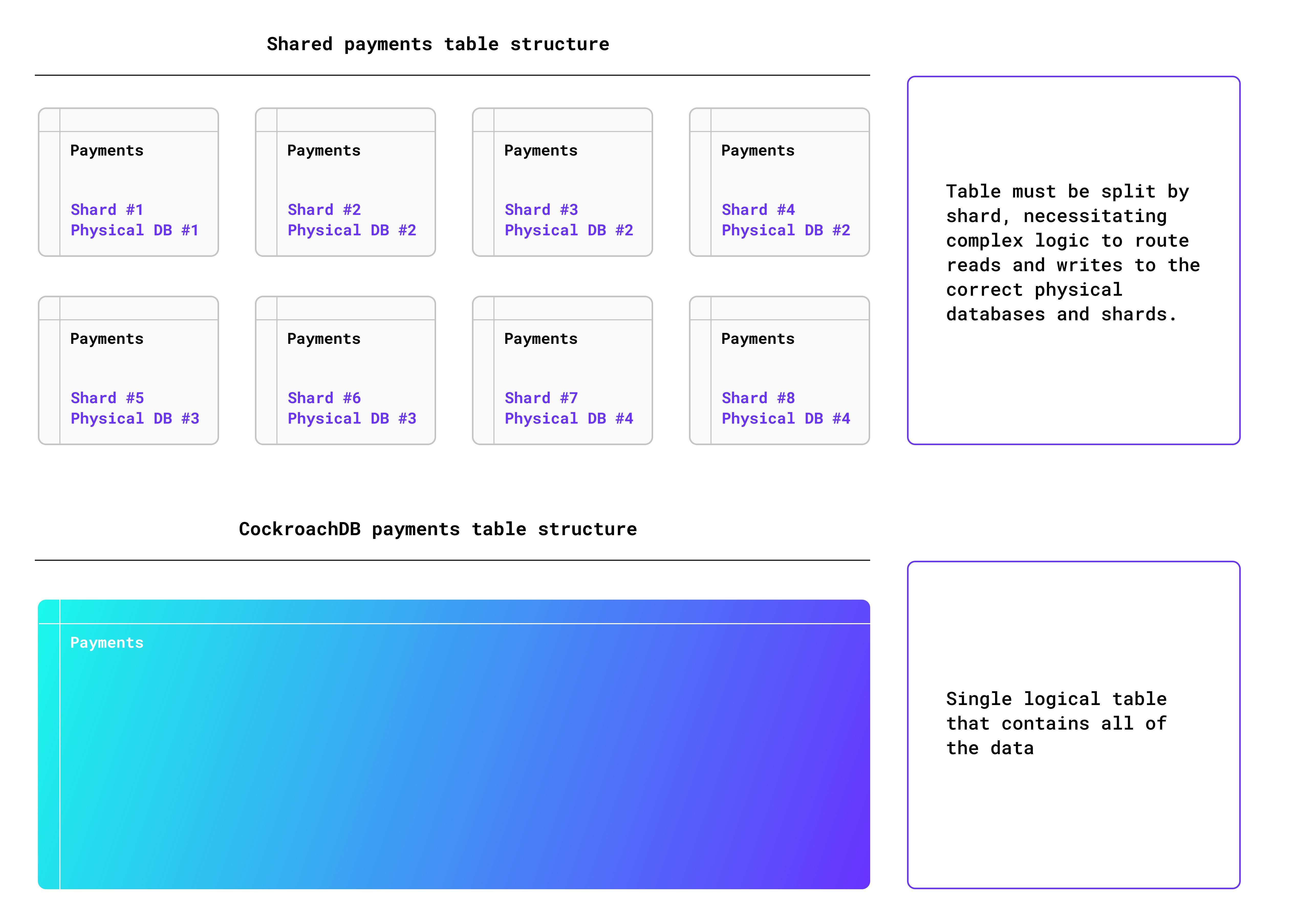
Regardless of your scale or node count, sending data from the application or running queries against this table works exactly the same whether you’re dealing with ten transactions a day or ten million. It also works the same whether you’ve got a single-region architecture or a multi-region setup with data homing.
This approach not only reduces the complexity seen in traditional sharding scenarios while enhancing your application’s ability to handle large volumes of transactions seamlessly.
What does a modern payment processing architecture look like?
Zooming back out, let’s take a look at where CockroachDB fits into the broader context of processing payments.
RELATED
Formed on a multi-cloud platform: Scalable, resilient payment technology
How does CockroachDB fit into a SaaS payments architecture?
For any “terminal” application such as a SaaS app or an online shop, CockroachDB serves as the primary transactional database, storing payment authorization request data and capture data when it’s returned from the payment processor. If desired, this data can also be easily synced to Apache Kafka or similar services via CockroachDB’s built-in change data capture (CDC) feature.

How does CockroachDB support payment provider architectures?
Payment providers themselves also need to store their payments data, and CockroachDB thus occupies a similar position as the primary transactional database in a payment service’s architecture.
If you're interested in learning more about how CockroachDB is a fit for payments use cases, visit our Payments use case page. You can also watch this short use case video about building scalable payments infrastructure from our customer: Spreedly
Charlie Custer is a former teacher, tech journalist, and filmmaker who’s now combined those three professions into writing and making videos about databases and application development (and occasionally messing with NLP and Python to create weird things in his spare time).
Michelle Gienow is a recovering journalist turned front end developer based in Baltimore, MD. She creates content around her central obsessions: Jamstack, distributed architecture and developing a cloud native mindset.


