
[As of February 23, 2017, CockroachDB Beta Passed Jespen Testing]
We at Cockroach Labs absolutely love Aphyr’s work. We are avid readers of the Jepsen series – which some know as a high quality review of the correctness and consistency claims of modern database systems, but which we really know as “Aphyr’s hunting tales about the highest profile bugs in our industry.” Most of us read each new blog entry with a mix of thrill, excitement, and curiosity about which new system will be eviscerated and which exotic error will be discovered next.
Aphyr’s Jepsen posts have changed the dialogue about distributed data stores, placing correctness on equal footing with scalability and performance. (Peter Mattis, Co-Founder of Cockroach Labs)
We are grateful for that.
That the Jepsen tool box is open source should be an inspiration to the entire industry. Additional gratitude is owed to Aphyr for his accompanying series on how to use Clojure, without which we would not have been able to appreciate how Clojure so elegantly simplifies writing the Jepsen event generators. Seriously, wow.

We’re looking forward to seeing CockroachDB put under Aphyr’s microscope one day, but for the time being we decided to apply the Jepsen testing tools ourselves.
We are completely aware of the shortcomings of self-testing the correctness of a system we built ourselves. We aren’t fooling ourselves thinking we could do this and announce afterwards to the world “Look! Aphyr’s magic wand hasn’t found any bugs!” That’s not really how things go in our industry, now, is it? Independent validation and all that, yet as we’ll see in this post we found value in running Jepsen tests.
And we learned so much in the process! It gave us both a boost in confidence and the opportunity to fix important issues in time for our Beta release.
Contents
First steps
Our first steps using Jepsen in January and February 2016 were embarrassing, though you might find them entertaining.
CockroachDB supports the same client protocol as PostgreSQL. Doing so allows us to use existing drivers written in almost every language. Unfortunately, our testing of these various drivers was not sufficient and, until two weeks ago, CockroachDB wasn’t smart enough to understand all the combinations of SQL and Postgres wire protocol messages generated by Clojure’s java.jdbc module. For example, we would try a straightforward JDBC connection set-up and send the most basic queries; even this code would bluntly fail with a server crash, a SQL error, obscure network issues, and all sorts of bugs.

We knew we would fix these errors (and we eventually did), but at that point we really wanted to get something working so that we could start doing consistency checks!
So in January we got an absolutely ugly kludge running: we sent all the SQL queries over SSH to our command-line client which resulted in rather verbose Jepsen clients.
Still, it worked! The latencies were not great, but it got us some results and provided motivation to improve our command-line SQL client.
That said, SQL-over-SSH got tiring pretty fast, so we ended up fixing the relevant CockroachDB bugs and rewriting our test code to use plain JDBC instead. And we even got JDBC working with SSL too!
Now our test framework supports running the same test queries against either a CockroachDB cluster, a single local CockroachDB instance, and even PostgreSQL to serve as reference.
Once that worked, setting up CockroachDB became rather trivial: fire up a cluster and create the test database.
What’s in a transaction? The ACID model
The ACID model requires transactions to be Atomic, Consistent, Isolated and Durable.
When you work on Jepsen, you usually only look at problems (like claims to serializability and linearizability) that involve a combination of A, C, and I in a distributed environment because you can assume the database engine already worked very hard on A, C, I, and D individually. After all, these engines have been around for a while and have plenty of users already who would have complained earlier if their transactions were not atomic or durable, or if they could see gross consistency anomalies.
In contrast, CockroachDB is still rather young, so a few more ACID checks were warranted. We figured we could learn how to use Jepsen by implementing a few simple tests first.
A simple consistency test: unique appends
CockroachDB allows programmers to perform updates to the database from different nodes on the same tables. It claims that the effects of a transaction committed on one node are automatically visible from the other nodes.
There are actually some underlying claims here:
That a committed transaction is only committed once (if the client added 1 row, we don’t end up adding 2 rows in storage). This is part of the A in ACID.;
That it actually remains committed, and its effects don’t get canceled. This is part of the D in ACID.
You could say that if a database doesn’t get these right, then it’s not much of a database, and you would be correct. But it’s not so obvious how to achieve this in a distributed environment: if the node that processes a transaction sends the updated data to other nodes, and there are network disturbances during this propagation, you want to ensure there’s consensus at the end. If nodes can decide that other nodes are really responsible for storing the data, then there must be at least one that takes the responsibility so you don’t lose any data.
To illustrate this, we devised a simple test. We used a table with a single int column representing an integer set, and then we added different values via different nodes. What we wanted to see is that we could 1) retrieve all the values at the end (persistence) and 2) observe that all the values were still unique.
(This is the same sets-test that you can find in Aphyr’s code for testing Galera, RobustIRC and Percona; they were not written about on the blog, probably because they didn’t uncover anything unwieldy.)
We first define a sets-client in charge of creating the table, responding to add events by adding the specified value in the table, and responding to read events to read the final state.
Then we implemented a checker that verifies there are no duplicates and that no confirmed INSERT is missing from the final set. We also checked that we don’t see values that were never inserted.
Finally we implemented a test definition which generates add events, spreads them across clients to different nodes, and issues a final read event [1]. It uses our checker defined above but also Jepsen’s convenient performance analysis checker which can emit latency graphs.
As a final touch, CockroachDB indicates failure to commit a transaction as a SQL error, which is reported as an exception; a transaction may stall for a bit while resolving a conflict, and we’d rather let the test continue without waiting. So we wrap our client code in a try…catch block and a timeout checker to report these states properly when they occur.
We ran this test and were happy to see no error (yay!) and also this beautiful latency distribution:

This tells us that on this particular test, most requests were served in less than 6 milliseconds except for the final reads which took 40-60ms.
Notes
[1]The code actually issues 2 read events at the end and on each client, which may seem overkill at this point but is actually motivated by an unrelated issue which we describe later on.
Snapshot isolation: pseudo-banking
In our experience, programmers have a rather straightforward, simple, healthy, and usually correct expectation that transactions should be well isolated: while a complex transaction is ongoing, another transaction should not be able to observe an intermediate state of the database.
Historically, database engines tried (and often failed) to solve this via locking, and this gave us a nightmare of silly transaction levels in the SQL standard. Meanwhile, modern databases have learned to use things in addition to locking, like Multi-Version Concurrency Control (MVCC), which ensures that even the weakest isolation level at least caters to programmers’ basic expectations. Usually, this is called snapshot isolation, although that level is not part of the SQL standard.
CockroachDB implements snapshot isolation (SI). (It also implements, and defaults to, the stronger serializable snapshot isolation (SSI), but let’s make small steps here.)
We wanted to test snapshot isolation and verify that expected anomalies are found and unexpected ones are not. For this we reused a particular test from Aphyr’s previous experiments with Percona, Galera and Postgres RDS. Its model is a restricted, unrealistic [2] “bank” that maintains accounts on different rows of a table with a “balance” column. The clients issue money transfers from one account to another, and each transaction prevents itself from moving money if that leaves an account with a negative balance.
Each transaction contains two SELECTs and two UPDATEs behind a condition. Without a proper implementation of snapshot isolation, several invalid scenarios could occur, for example:
Account A starts at 50
Txn1 checks that 30 can be transferred from A to B, sees the transfer is possible
Txn2 checks that 30 can be transferred from A to C, sees the transfer is possible
Txn2 updates A and C to effect the transfer
Txn1 goes through and updates A and B, sees (incorrectly) the new data for A and makes A negative. Or, it (incorrectly) blindly overwrites Txn1’s previous write to A with its own computed value, leaving A positive but accidentally creating extra money!
We implemented this like in previous Jepsen tests. The client first instantiates a couple of accounts (rows) in the test table. Then it processes incoming read and transfer events using the model rules described above. Meanwhile, the event generator issues randomly distributed read and transfer events. We used only transfers between different accounts. Finally, the checker ensures that at every read operation, the sum of all balances is preserved and that no balance has turned negative [3].
We finished it by checking that no errors were detected (none were).
Here you could (and perhaps should) stop us and shout: “Wait!”
The code we wrote for this test’s client uses a macro with-txn which always uses the isolation level “serializable.” So even if “serializable” implies “snapshot,” we’re not really testing “snapshot”! Perhaps CockroachDB wouldn’t work properly if we ran the same test with transactions that use snapshot isolation explicitly?
Do not worry, we tested that too, but we couldn’t do so easily with Jepsen: even though our dialect of SQL allows “SNAPSHOT” in the syntax, Clojure’s java.jdbc driver doesn’t know how to use it. It only knows about the standard SQL levels, unfortunately… So we wrote a piece of Go code that talks to our database directly to test this [4], and there were no surprises.
Notes
[2] This “banking” test was designed by Aphyr so that it merely need snapshot isolation to maintain its model (positive balances, sum stays constant). This is not to say that snapshot isolation is sufficient to implement a real banking application! “Real” banking transactions usually require serializable isolation, for otherwise you cannot implement eg. correlated accounts (authorize transfer from one account only if the sum of this account and another is sufficient).
[3] We noticed that the Jepsen test code didn’t actually check for negative balances, contradicting what has been previously written about it, so we fixed that.
[4] Code left unpublished as an exercise to the reader.
Client-side retries
Let’s look at the latency distribution graph generated for the previous banking test:
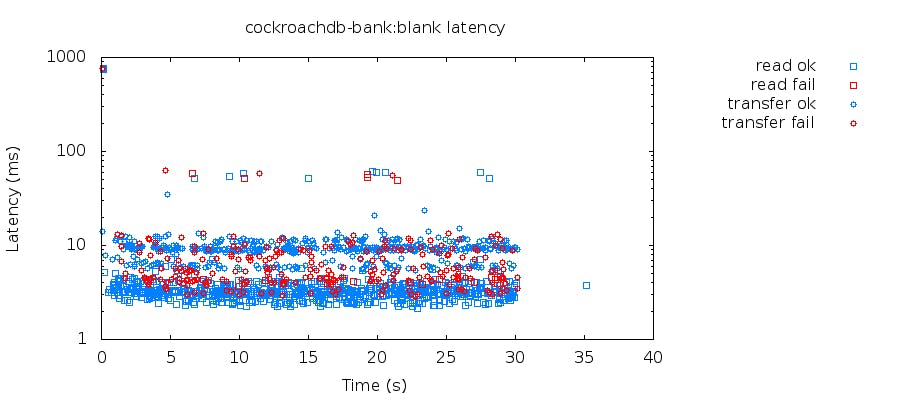
As you can see, there is some red in there. Errors? Uh-oh.
Looking at the query error log we can see the errors correspond to occurrences of the following messages:
ERROR: read at time 1456878225.401016975,0 encountered previous write with future timestamp 1456878225.401436392,33 within uncertainty interval
ERROR: retry txn "sql/executor.go:597 sql implicit: false" id=e3528ef3 key=/Table/51/1/120611882267213829/0 [...]
ERROR: txn aborted "sql/executor.go:597 sql implicit: false" id=693720a3 key=/Table/51/1/120611978022649859/2/1 [...]
ERROR: txn "sql/executor.go:597 sql implicit: false" id=45d793a1 key=/Table/51/1/120611888869081090/2/1 [...] failed to push "sql/executor.go:597 sql implicit: false" id=c880a706 key=/Table/51/1/120611888869081090/2/1 [...]
What does this mean? All are verbose ways CockroachDB tells us that a transaction could not be committed and that it should be retried.
The first error (“write with future timestamp”) means that we are trying to “read into the future” by reading data written by a transaction on a node that appears to be slightly ahead in time (see Spencer’s blog post on CockroachDB and time for an explanation). The second error means the transaction tried to write something, but encountered a conflict with another read transaction. The remaining two errors are similar but report on write-write conflict in which our transaction lost.
Clients must deal with these errors in real-world apps by retrying the transaction. In our Jepsen tests, we decided to do this as follows: First, we captured these specific cases using a handy wrapper macro. Then we implemented another macro that wraps a transaction and retries it, avoiding storms of transaction conflicts using exponential back-off. (CockroachDB’s documentation suggests there is a better approach, however we did not implement it here for simplicity.)
With this extra infrastructure in place, the latency distribution becomes much cleaner:
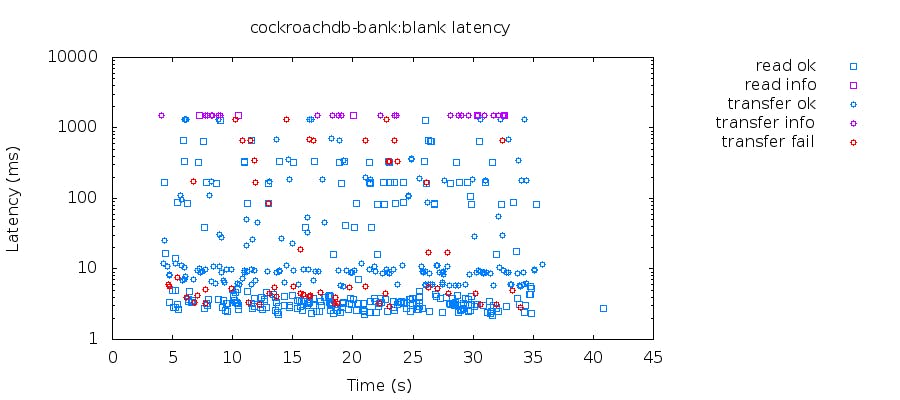
This reveals there are still “transfer failures,” but looking at the log, we see they are simply cases where a transfer would otherwise result in a negative balance, and are thus disallowed by the model.
Intermezzo: Clojure’s threading gave us a cold sweat
While testing bank transfers, we did see something that looked an awful lot like an anomaly: some transfers appeared to be incomplete, with money retrieved from one account but not deposited on another. That sounded really bad, and we spent a whole weekend investigating.
While looking at the trace of SQL queries arriving at the server nodes, we found something very odd: it appeared as if multiple transfers were occurring in the same transaction. It was as if the network between the clients and the server was messing with the traffic and mixing the streams from multiple clients together.

Obviously, TCP/IP is not that broken and we found the problem eventually: an open JDBC connection was being re-allocated to a new thread while the previous thread that was using it was still running.
How did this happen? We were catching timeouts using Aphyr’s Jepsen macro for reconnects, and we found it to be a little sketchy. In the JVM, threads only check their interrupt status during certain operations, so it is possible for a thread to continue for some time after being interrupted. We fixed this by ensuring the connection is closed and re-opened on each timeout [5].
Notes
[5] It would be possible, if the underlying JDBC driver checks the interruption status in all the right places, for the interrupted thread to rollback its transaction and then acknowledge the interrupt so the connection could be used again, but that’s tricky to get right, and also it is somewhat out of our hands.
From snapshot isolation to serializable isolation
As said above, CockroachDB also supports serializable isolation, which is one step up from snapshot isolation: transactions must appear to be processed in some order from the perspective of one client. This implies snapshot isolation (transactions cannot observe unfinished work) but also that write skews are not possible: concurrent transactions cannot appear to work starting from the same initial database state, perform disjoint updates, then achieve incompatible database states after they commit.
Aphyr’s pseudo-bank test we were using earlier is insufficient to stress serializable isolation: two transfers involving at least a common bank account would get a write-write conflict, which is already disallowed by snapshot isolation, but that would also prevent write skews without further attention from the database engine.
So we wrote another test. Our monotonic client uses a single table with an int column and initializes it with a single row with the value 0. It then responds to add events by reading the current max of all rows already in the table and adding a new row with the maximum + 1, and to read events by fetching all rows currently in the table. Meanwhile the event generator produces staggered add events during the test and a read event at the end.
If write skews were possible, then some transactions would start from the same current maximum and insert the value of this maximum + 1 twice in the table (disjoint updates). This is not possible if they appear to run one after the other, as required by serializable isolation. So when the test completes, our checker verifies, among other things, that the table doesn’t contain duplicates.
We ran this test in many configurations and didn’t find duplicates. The latency distribution looks like this:
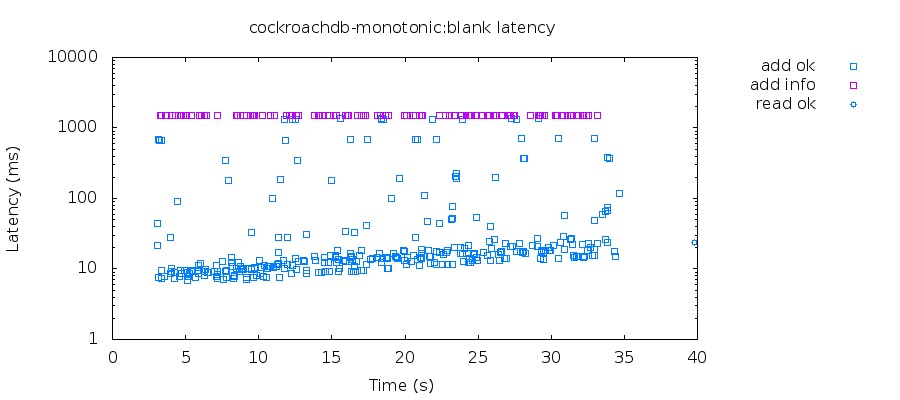
From serializability to linearizability
Perhaps surprisingly, the order of serializable transactions may appear to be different depending on which client observes it. For example, if a client A creates a user, and then creates a post for that user in successive transactions T1 and T2, it would be possible for client B to see the blog post before the user exists. This is possible because the commit timestamps assigned by the database are acausal.
That’s where serializability differs from linearizability: with linearizability, you observe the same order from all clients.
By default, CockroachDB guarantees serializability in general for transactions, and guarantees linearizability only for special circumstances (technically, for all transactions that touch overlapping sets of nodes).
Side Note: The ACID model does not refer to serializability or linearizability. Why is that? Well, ACID was developed at a time when people were more concerned that transactions not see partial results from other transactions than anything else. Since database engines were mostly sequential, linearizability came for free with serializability, so there was no need to distinguish between them. Today, everything is different, which is why the ACID model is becoming insufficient to talk about distributed databases.
Given this claim, it’s interesting to evaluate CockroachDB’s limited linearizability guarantee and determine in which circumstances it breaks down to mere serializability.
Snapshot isolation over multiple ranges?
This is the moment where you could stop us and say: “Wait a minute! You said earlier you don’t need to make a lot of effort for isolation over small key ranges, because everything is resolved in chronological order at a single node, the range leader. But your banking test about snapshot isolation earlier uses only a few accounts, so they probably lie on the same key range. Wasn’t that a bit too easy?”
You would be right, of course. The banking test from earlier used a small enough amount of data for it all to fit on a single range and thus not stress the multi-range transaction implementation. In other words, we weren’t testing much.
We noticed this too and wrote another version of the banking test that uses a different table for each account (CockroachDB splits ranges at table boundaries). We haven’t found errors using that test either.
Linearizability on single ranges
One test Aphyr often uses to check linearizability is concurrent compare-and-set. The idea is to send concurrent read, write and compare-and-set (CAS) operations from multiple clients, collect the trace of observed results, then analyze these traces using the linearizability checker in Knossos. The checker validates that the trace is possible if the history was linearizable; if an invalid ordering is detected, it can conclude that the database does not guarantee linearizability.
CockroachDB implements linearizability on single key ranges. SQL rows are mapped to a set of keys in the data store, but it also guarantees that all keys in the same row will belong to the same range. In other words, as long as our CAS test uses a single row for each atomic register, we should observe only linearizable histories.
To do this, our Jepsen client initially sets up a table with two columns id and val. Each row represents a single atomic counter.
Meanwhile, we also took good note of Aphyr’s and Peter Alvaro’s recommendations in this recent blog entry by Aphyr about RethinkDB: “Tests of longer than ~100 seconds would bring the checker to its knees. Peter Alvaro suggested a key insight: we may not need to analyze a single register over the lifespan of the whole test. If linearizability violations occur on short timescales, we can operate over several distinct keys and analyze each one independently. Each key’s history is short enough to analyze, while the test as a whole encompasses tens to hundreds of times more operations–each one a chance for the system to fail.”
As in the RethinkDB tests, we use the independent/sequential-generator to construct operations over integer keys, and for each key, emitting a mix of reads, writes, and compare-and-set operations, one per second, for sixty events. Then sequential-generator begins anew with the next key.
Also, like Aphyr suggested, we used reserve to ensure there are always some threads running reads when all threads running writes and CAS operations are blocked, so that we can detect transient read anomalies if any.
We then handled in our client the fact that each operation may operate on different counters. On each operation we first looked at whether the row for the requested counter already existed then upon writes, depending on whether it existed or not, we either create it or update the existing row (CockroachDB does not yet support “upsert”). CAS operations are handled as simple updates, and one operation is known to have failed or succeeded depending on the updated row count returned for the UPDATE statement.
Soon enough it was time to run the test, which gave us the following:

Knossos did not find any linearizability errors in this history, which is good. Neither did it in many more histories.
Note: despite “CAS failures” being reported in red in the figure, they are expected occurrences in the test: if the compare part of compare-and-set doesn’t find the expected value, it registers as a fail, but the test generates CAS randomly so that’s bound to happen sometimes.
Woes with CockroachDB timestamps
We tried to determine cases where transactions have serializable behavior but not linearizable. To test this, we thought we could use something time-related, but while designing a test we ran into a serious issue.
The issue was discovered using another test described above already: the monotonic test which adds the current maximum + 1 on each client event. As a sanity check, we added a second timestamp column in that test’s table that would also capture the database’s perception of time on each insert. We figured that if the behavior were properly serializable, then each newly added maximum and its accompanying timestamp necessarily had to grow together.
Our first approach was to use NOW() as a measurement of time. Unfortunately, when we tested that, we observed the contrary: sometimes we would see the maximum value decrease over “time.” Uh-oh.
Well, the explanation is rather simple: NOW() uses each database node’s clock as a time source. If their clocks are slightly desynchronized, a transaction occurring earlier on node A in absolute time could pick a value for NOW() slightly larger than a transaction occurring later on node B.
This is really a fundamental lesson with distributed databases: unless the database engine makes an extra effort, there is no guarantee that NOW() is monotonic in transaction order.
We struggled for a while thinking about what to do about this. On the one hand, we had to acknowledge there is a user need for some function that evolves monotonically in transaction order. At least for our Jepsen experiments! We also argued a lot about whether SQL’s NOW() should fill this role, since the local physical time also has a use in many applications.
We iterated back and forth and eventually settled on creating a CockroachDB-specific function called clusterlogicaltimestamp() that provides this guarantee.
This Jepsen exercise helped us understand we had to be very careful about our understanding of time and what properties to advertise to users about our time functions.
Linearizability vs. serializability
Since linearizability and serializability seem so close to each other, we used the opportunity offered by the Jepsen tooling to distinguish them further here. We do this as follows. Our monotonic-multitable test defines multiple tables, each with columns (val int, ts int, client int).
It then instantiates multiple clients that share a single atomically increasing counter, and for each input event, each client inserts that counter’s value, the database’s time as per cluster_logical_timestamp(), and its client ID in a randomly selected table. The different tables increase the probability that transactions from the same client are processed on separate nodes with no common key range and no internal causality.
Since each client individually commits the previous transaction before starting the next one, we should see the same order for both columns val and ts. We implement this as a check that filters the sub-sequences of results for each client and checks the monotonicity on each sub-sequence.
Meanwhile, since the isolation level is serializable and not linearizable, the database may decide to effect the transactions in a different order than the order they were issued and thus the combined table contents as observed by another client may have conflicting orderings between both columns. We implement this as a result field that reports ordering anomalies on the combined table contents.
When running this test, we observe results like the following:
{...
:details {...
:valid? true,
:value-reorders-perclient
(() () () () () () () () () ()
() () () () () () () () () ()
() () () () () () () () () ()),
:value-reorders
(((22 14586953315945740430000000000N 3)
(21 14586953315962445260000000000N 0))
((40 14586953321193014420000000000N 13)
(39 14586953321264351870000000000N 27))
((94 14586953338036856600000000000N 9)
(93 14586953338081737300000000000N 17))
((114 14586953344009692430000000000N 9)
(113 14586953344034096610000000000N 22))
...
),
},
:valid? true
}
The empty lists for value-reorders-perclients indicate that no per-client sub-sequence contained ordering anomalies. In other words, each client’s transaction history is serializable.
Meanwhile, the field value-reorder shows that pairs of clients observe conflicting orderings. For example, client 0 has inserted value 21 before client 3 has inserted value 22 (the client-side atomic counter is guaranteed to increase monotonically), yet the database chose timestamps in the opposite order. This can happen when the client’s transactions are processed by nodes with separate physical clocks: separate clocks are always slightly desynchronized, even with NTP. At the end, to the client observing the database contents, the history appears as if client 3 has inserted before client 0, i.e. a different order. The global history is not serializable, ie. transactions are not linearizable.
Just as predicted!
To further drive the case in point, this is a good opportunity to reveal the existence of CockroachDB’s hidden database-wide “linearizable” flag. This flag, which can be set for a cluster globally, makes CockroachDB behave like Google’s Spanner database: each transaction waits some time before a successful commit is reported to the client, and this guarantees a global transaction ordering — i.e. linearizability. (The mechanism is described further in Spencer’s blog post on CockroachDB and time. We don’t advertise it yet because it makes the database very slow without a high-precision time source like TrueTime. However it is useful for testing.)
When we set the linearizable flag, the linearizability anomaly revealed by the test above disappears!

… except that it doesn’t, at least not always. In some test runs, linearizability anomalies still appear even when the database runs “linearizable.” There may be a bug in the implementation for the linearizable flag, we’re not sure yet. This is another reason why we do not advertise it in our documentation just yet. Until then, you should still get serializability per client, as advertised.
Linearizability vs. network partitions
Since CockroachDB also claims correctness in the face of adversity, we wanted to let Bad Things happen to our database and see how it responds. Like Aphyr often does, we started subjecting our 5-node database cluster to random network partitions while running the compare-and-set test. When we do so, we see the following happening:
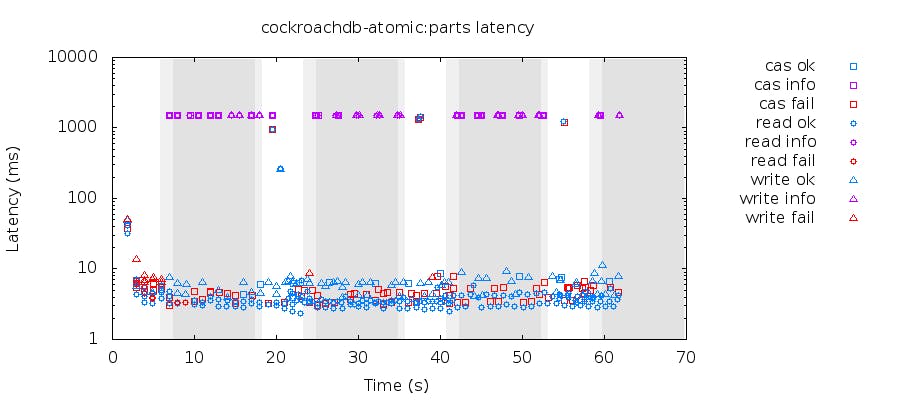
Still no linearizability errors detected by Knossos, but then we start seeing some (but not all!) operations timing out during a partition. What’s going on?
We can look at the history log for what happens soon after a partition starts:
:nemesis :info :start "Cut off {:n1l #{:n3l :n4l :n2l},
:n5l #{:n3l :n4l :n2l}, :n3l #{:n1l :n5l},
:n4l #{:n1l :n5l}, :n2l #{:n1l :n5l}}"
[...]
7 :info :read [:timeout :url "//n3l:26257/jepsen"]
2 :info :write [:timeout :url "//n3l:26257/jepsen"]
[...]
56 :info :read [:timeout :url "//n2l:26257/jepsen"]
51 :info :cas [:timeout :url "//n2l:26257/jepsen"]
[...]
58 :info :read [:timeout :url "//n4l:26257/jepsen"]
53 :info :cas [:timeout :url "//n4l:26257/jepsen"]
[...]
The first line indicates the nemesis has created two node groups {n1, n5} and {n2, n4, n3}. Following this, all transactions started on nodes n2, n3, and n4 fail and cause a reconnect — whereas any operation on n1 and n5 still succeeds. The reason for this is that a quorum is needed for updates. During the partition, n1 and n5 are in a replication group with one of the other 3 nodes (either n2, n4 or n3). When a transaction arrives on that 3rd node to modify data under responsibility of this replication group, it must wait until it obtains a quorum before it can resolve. Meanwhile, transactions arriving on n1 or n5 have their quorum and can succeed.
To summarize, CockroachDB successfully protects the consistency of the data during network partitions by stalling or aborting the queries until the partition resolves.
In a real-world application, clients can probabilistically avoid orphan nodes by reconnecting to the cluster via a load balancer when a timeout is detected.
Linearizability vs. clock skews

CockroachDB uses wall clock time to maintain ordering between transactions. We’ve written about that before. But this means it is particularly sensitive to time differences between nodes – with too much clock drift, nodes may start to have conflicting ideas about transaction order (e.g. a client might try to read data it just wrote and find it missing if the read is served through a node with a “slow” clock).
This warrants some extra testing. We ran multiple tests using Jepsen’s clock-scrambler generator which uses “date --set-time” to add random positive or negative offsets to the system clock on each node. What does that give?
For one, we started getting more read and write errors:

These errors are not retries any more:
storage/store.go:1399: Rejecting command with timestamp in the future: 1456997985090162004 (1.018244243s ahead)
This occurs when CockroachDB tries to propagate a transaction across multiple replicas and the RPC communication layer detects the clocks of the replicas have drifted too much (more than set via the –max-offset parameter, which defaults to 250ms).
But also as the drifts increase past a few seconds, CockroachDB really becomes confused about time and… we start seeing linearizability errors.
We’d like to defend this as not a serious bug in CockroachDB. We’ve always said that we only guarantee consistency when the maximum clock drift doesn’t exceed the MaxOffset parameter configured at database start-up. CockroachDB actively tries to estimate clock drift and nodes stop themselves if they detect that their own time is likely to have drifted in excess of MaxOffset. We are really doing our best: it is theoretically impossible to guarantee the detection of clock offsets in general. Our default tolerance of 250ms drifts is generous, and caters for everyone but the most terrible deployments. Most applications can reliably avoid drifts larger than 250ms by ensuring that database nodes synchronize their time with NTP.
That said, smaller clock skews are still possible even with NTP, if the query rate is high enough. This can happen due to VM migrations in clouds, or even on multi-core systems when the OS does not fully synchronize time counters between different cores (eg. in OS X).
So we had to look at smaller skews, too, to exercise CockroachDB’s MaxOffset tolerance. For this, we implemented our own scrambler that can introduce drifts of +/- 100 milliseconds, ramped up the request rate and we observed the results:

Actually this is pretty uneventful and the various errors are not any different than earlier.
We ran this test with this nemesis many times, and we didn’t find any linearizability errors.
More nemeses!
We found the Jepsen tools to be incredibly useful at making Bad Things happen. They support network partitions, majority rings, starting and stopping the database at unexpected moments, and many other nemesis scenarios. For example, besides the “big skews” nemesis already discussed above, we also added another one that would “violently” kill one or two servers (using Unix’ SIGKILL) and restart them randomly.
We wanted to test them all and even in combination, but writing a Jepsen test definition for each nemesis quickly proved tedious.
So we took some inspiration from the Jepsen code for MongoDB and RethinkDB and baked our own nemesis mix-and-match factory.
We did this by defining each nemesis using a name, a generator for nemesis events, and a client for nemesis events. For example we wrapped the random partition nemesis as follows:
(def parts
{:name "parts"
:generator nemesis-single-gen
:client (nemesis/partition-random-halves)})
For a single nemesis, the nemesis-single-gen generator simply generates start and stop events one after another with configurable delays. Using this pattern we wrapped several of Jepsen’s nemeses with some of our own.
When we compose two nemeses, we do so using another event generator that generates two sequences of start/stop events with overlapping intervals, and use that in our custom nemesis composition operator which returns a new nemesis definition with the same interface.
Finally, once all our nemeses had the same interface, we made them parameterizable in our tests then generated test definitions automatically for all combinations of interest to us! It works like this:
(defn check
[test nemesis]
(is (:valid? (:results (jepsen/run! (test nodes nemesis))))))
(defmacro def-tests
[base]
(let [name# (string/replace (name base) "cl/" "")]
`(do
(deftest ~(symbol name#) (check ~base cln/none))
(deftest ~(symbol (str name# "-parts")) (check ~base cln/parts))
(deftest ~(symbol (str name# "-skews")) (check ~base cln/skews))
...
(deftest ~(symbol (str name# "-parts-skews"))
(check ~base (cln/compose cln/parts cln/skews)))
...)))
(def-tests cl/atomic-test)
Using this, we can now run separately the check for atomic-test, atomic-test-parts, atomic-test-skews, atomic-test-parts-skews and so forth.
We hope this might be of interest to other Jepsen users.
Once this infrastructure was in place, we used it to check whether CockroachDB would get confused if we injected clock skews during a network partition, or vice-versa. It didn’t — at least not any more than determined earlier. We then automated the generation of a handy test result overview:

The red items reveal inconsistencies found with big clock jumps, as explained in the previous section.
A public instance of these tests results is available here. Note that since we only run these tests occasionally at significant development milestones, they may not reflect the latest published version of CockroachDB.
Wrapping up
The incentive to run the Jepsen tools compelled us to fix numerous limitations in our client wire protocol, which now provides pretty good support to Clojure (and Java) JDBC clients.
We had a lot of fun adding extensions to the Jepsen tool box, including a few bug fixes, additional utilities, and the ability to easily test all combinations of multiple tests and multiple nemeses without too much boilerplate.
And finally, thanks to Jepsen, we also found two consistency-related bugs in CockroachDB: #4884 and #4393. This is exactly the kind of discovery we had expected from the ordeal, and we are thrilled to join the club of Jepsen advocates!
Although, of course, we won’t forget…

Does building and stress-testing distributed SQL engines put a spring in your step? If so, we're hiring! Check out our open positions here.


