


Most enterprise AI teams have built an agent that was impressive; far fewer have shipped one without a production incident that made someone question the whole program.
The reason is almost never the model. Agentic AI is forcing every enterprise to solve distributed systems problems, whether they realize it or not. These are the six places where that becomes unavoidable:
memory state
thundering herd
agent identity
blast radius
observability
economics
Together, these challenges determine whether your agentic system survives contact with real users, real data, and real consequences. For teams moving from proof of concept to production, the real question is whether the AI agent infrastructure around the model can preserve state, enforce identity, absorb concurrency, support audits, and keep unit economics predictable.
The standard advice focuses on context engineering and guardrails. That's not wrong, but it's incomplete. Here's what actually separates systems that ship from systems that don't.
Related
The State of AI Infrastructure 2026
Based on new global research surveying 1,125 engineering leaders, this report reveals how close organizations are to hitting their infrastructure limits, and why AI scale is becoming a defining risk for reliability, performance, and cost in 2026.
Why Is AI Agent Memory a State Management Problem? 
Most conversations about agent memory focus on context windows and how much the model can see at once. That's a real constraint, but it's not the hard problem.
The hard problem is state management across a distributed system. An agent serving ten thousand concurrent users must maintain working memory, session history, and shared knowledge while handling node failures, concurrent updates, and infrastructure interruptions. While that looks like an AI problem on the surface, it’s actually a concurrency, consistency, and durability problem. When AI agent memory fails in production, the business impact shows up as duplicated work, inconsistent customer experiences, unresolved tasks, and incidents that are difficult to reconstruct after the fact.
Consider what happens when an agent is mid-task and the node handling its session fails:
Does the task restart from scratch?
Does it resume from a checkpoint?
Does it silently fail while the user waits?
These are routine distributed systems questions. The challenge is that many agent frameworks were designed for demos, not for environments where infrastructure failure is an expected condition.
The deeper issue is that different types of agent memory have different consistency requirements that most architectures conflate:
Agent memory requires more than semantic retrieval, since different memory types have different requirements for consistency, durability, and recovery. Treating them as a single problem is what leads to production incidents that are difficult to diagnose.
Before you ship externally, answer this question honestly: “If the node serving your agent's session dies mid-execution, what exactly happens to state, and can you prove it?”
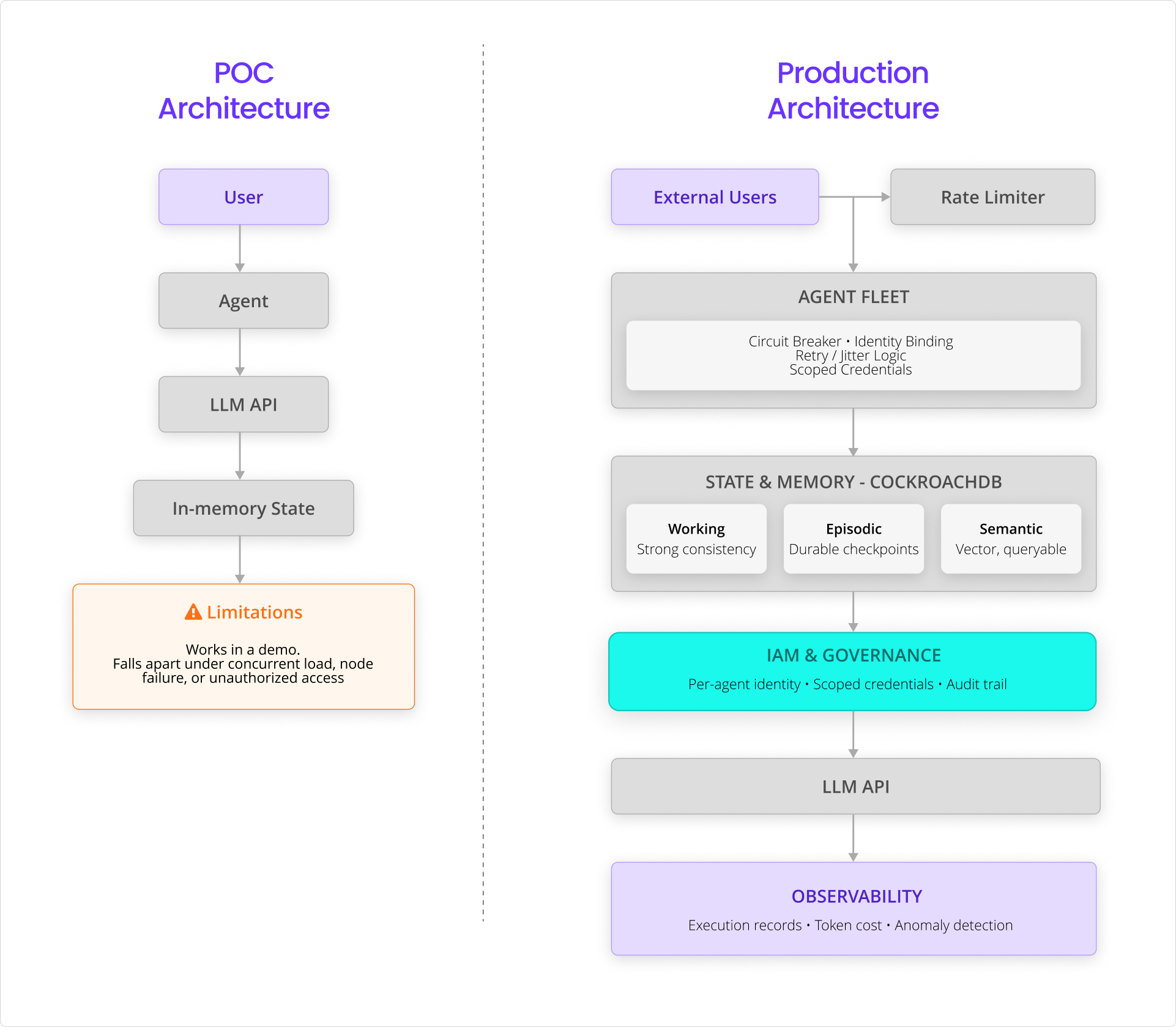
Moving from AI proof of concept to production requires durable state, governed identity, observability, and infrastructure designed for failure and scale.
Each layer addresses a failure mode discussed below.
Why Do AI Agents Create Thundering Herd Problems?
Solving state management is only the first challenge. Once thousands of agents share that state simultaneously, load becomes the next problem, because agentic workloads behave differently from human-driven traffic. Humans create natural pauses between requests, but agents don’t.
A single user request can trigger dozens or hundreds of downstream calls to tools, APIs, databases, and other agents. Multiplied across thousands of concurrent sessions, those fan-out patterns create load profiles that traditional web architectures were never designed to handle. In production, that can turn a successful launch into degraded service, delayed workflows, or an outage that affects customers before the team can isolate the source.
This is the thundering herd problem applied to agentic systems. It shows up in three specific ways worth understanding before they catch you.
Cache stampedes happen when cached context or tool results expire simultaneously across many agent sessions, causing all of them to fall back to the underlying data source at the same moment. A database or API that handles steady-state load comfortably can get crushed by this kind of synchronized demand spike.
Retry storms happen when a downstream service becomes temporarily unavailable and thousands of concurrent agents begin retrying simultaneously, turning a brief outage into a sustained one. Exponential backoff with jitter helps, but it requires explicit implementation in every integration layer. Most agentic frameworks don't do this by default.
Write and read hotspots are the subtler version. When a coordinating agent dispatches subtasks to ten specialized agents in parallel and all ten complete at nearly the same moment, results converge back to the coordinator in a synchronized burst. Writes to a shared state store create a write hotspot. Reads from a shared knowledge base create a read hotspot. Most pipeline architectures don't account for this because they were designed for sequential workflows, not true parallelism.
The fix isn't exotic. It's applying distributed systems patterns the engineering community has developed over decades: connection pooling, adaptive rate limiting, jitter in retry logic, and write patterns designed to avoid hotspots. The challenge is that most agentic teams were built by ML practitioners, not distributed systems engineers. Closing that gap before external launch isn't optional.
Why Does AI Agent Security Start With Identity?
Managing concurrency prevents infrastructure failures, but it doesn't answer who those agents are allowed to act as. Most enterprise security models assume humans are the actors in the system. Agentic systems break that assumption.
They're autonomous software processes that take actions on behalf of humans, sometimes with more speed and broader scope than any human user would. Treating them as a generic service account, which is what most teams do initially, creates a significant new risk category.
AI agent security starts with treating every autonomous agent as a first-class identity, with credentials and permissions that can be scoped, rotated, monitored, and audited.
An agent that needs to access customer data to complete a task requires credentials. Those credentials can't live in the agent's context window, however, because context windows are readable by the model and potentially leakable through tool outputs. They can't be hard-coded, because hard-coded credentials can't be rotated without redeployment. They also can't be overly broad, because an agent with read access to your entire customer database has a significantly bigger blast radius than one scoped solely to the current task’s requirements.
The harder problem is identity chaining in multi-agent systems. When an orchestrating agent delegates a task to a specialized sub-agent, whose identity governs the sub-agent's actions? If the answer is the orchestrator's identity, you have created a confused deputy: a lower-trust component can exercise higher-trust privileges just by routing through a trusted intermediary. This isn't a theoretical vulnerability, it's exploitable through prompt injection, where malicious content in the environment manipulates an agent into taking actions it was never supposed to take.
External production introduces regulatory requirements that make all of this non-negotiable. When an agent takes a customer-facing action, such as approving a credit limit or processing a return, there must be an auditable record of exactly what identity authorized that action, under what permissions, at what time, based on what inputs. That audit trail can't be retrofitted after the fact.
The teams that get this right treat every agent as a first-class identity: a unique identity, scoped credentials that expire and rotate, permission boundaries enforced at the data layer, and a complete audit trail of every action taken. It's more work upfront. It's the difference between a system you can certify for external production and one you can't.
How Does an AI Agent Blast Radius Change in Production?
Identity determines what an agent is allowed to do. Blast radius determines how much damage it can do when something goes wrong.
Because agents execute autonomously and continuously, a configuration error or logic flaw can propagate across hundreds of executions before anyone notices. A pricing mistake affects every transaction the agent processes, while a permissions error impacts every resource the agent can access.
Autonomy at scale is what makes agents powerful, but it's also what makes their failures so hard to contain. The challenge isn't detecting that something went wrong; it's determining how many actions were affected before anyone noticed. Without durable, queryable execution records, even scoping an incident becomes difficult.
This is where AI agent governance becomes operational rather than theoretical. Teams need technical controls that limit what agents can do, record what they actually did, and make it possible to contain failures before they become customer-impacting events.
Circuit breakers are the most important tool here and the most consistently skipped. A circuit breaker detects when an agent is behaving outside expected parameters:
taking longer than a defined threshold
making more tool calls than expected for a given task type
producing outputs that fail validation
When those signals appear, they halt execution before the problem compounds. This isn't the same as error handling, which responds to explicit failures. Circuit breakers catch behavioral drift before it too becomes a failure.
Every externally-facing agent system needs a clear answer to three questions before it ships:
How will we detect that an agent has gone off-script?
How quickly will we detect it?
What does the system do automatically in the interval between detection and human intervention?
If you can't answer all three before launch, you're not ready to ship externally.
Why Is AI Agent Observability a Distributed Systems Problem?
Agent observability is fundamentally different from traditional application observability. Two identical inputs can produce different execution paths depending on tool selection, system state, and intermediate results. You can't reliably observe the model's reasoning. You can only measure the artifacts it produces.
AI agent observability is the practice of capturing an agent's external behavior across tools, data, permissions, timing, cost, and outcomes so teams can understand what happened, why it happened, and whether it stayed within expected boundaries.
That distinction matters for how you build. Standard logging captures what happened. Agent observability requires a structured execution record that captures why it happened and whether it stayed within bounds. That record should include tool usage, inputs, outputs, timing, cost, identity, and delegation history.
That artifact needs to be immutable, structured, and queryable. When an agent produces a wrong output, you need to retrieve every execution that followed a similar path and understand the pattern. When a compliance team asks, "Show me exactly what this agent did and prove it stayed within scope," a log file doesn't answer that question. A structured, queryable execution record stored durably does.
The engineering challenge that most teams underestimate: agents running at production scale generate execution records at high write volume. The infrastructure that stores those records needs to absorb that write volume while remaining queryable for investigations that happen months after the fact. Most logging systems weren't built for that combination. By the time most teams need the data, they can't query it.
Why Don’t AI Agent Economics Scale Like the PoC?
PoC economics rarely predict production economics.
An agent that costs a few cents per session in development can cost several dollars per session in production once conversation history grows, workflows become more complex, and usage scales. Multiply that by real user volume and the deployment economics can look very different from your original business case. If those costs are not modeled before launch, teams can end up throttling usage, narrowing the product experience, or delaying broader rollout after the system is already in customers' hands.
Persistent memory can reduce token costs by allowing agents to retrieve prior work rather than recompute it. Rate limiting and context management also help, but both require upfront engineering investment.
The organizations that ship without cost overruns model the unit economics before external launch, not after. That means knowing:
Cost per session under realistic usage patterns
How costs grow as conversation history gets longer
The infrastructure cost of memory and state management
What Separates Agentic AI Teams That Ship?
The AI model is rarely what fails in external production. What fails is the infrastructure around it:
state management that wasn't designed for distributed failure
identity architecture that wasn't designed for autonomous actors
concurrency patterns that weren't designed for machine-speed request generation
economics that weren't modeled at production load
Across production agentic deployments, the pattern is consistent: Every challenge discussed here eventually lands at the data layer:
durable agent state
audit-grade execution records
consistent reads across distributed sessions
identity chains that survive node failure
Production AI agent infrastructure depends on the data layer because agents need to read, write, recover, and audit state continuously while operating across distributed systems.
These requirements depend on a database that handles high write throughput and complex reads simultaneously, without sacrificing consistency. At Cockroach Labs, this is the problem we work on directly, alongside engineering teams shipping these systems. The posts below are built from that work.
Ready to go deeper?
My Cockroach Labs colleague Tushar Ghotikar's benchmarking work quantifies what agentic concurrency actually looks like against traditional database workloads and why the difference matters for your architecture choices.
The Memori Labs integration with CockroachDB shows what durable, queryable agent memory looks like when the memory, governance, and context retrieval patterns in this post are actually deployed.
Try CockroachDB Today
Spin up your first CockroachDB Cloud cluster in minutes. Start with $400 in free credits. Or get a free 30-day trial of CockroachDB Enterprise on self-hosted environments.
Quentin Packard is VP of Americas Sales at Cockroach Labs, where he works with engineering and infrastructure leaders building production-grade agentic AI systems. He previously helped build Splunk’s observability business and has worked across infrastructure automation, secrets management, and real-time data governance at HashiCorp and early stage startups. His writing draws on direct conversations with enterprise teams navigating AI and data architecture in production.



