


When you are using CockroachDB for your mission-critical applications, resilience should be a top priority. Built with Raft replication, CockroachDB is designed to withstand failures by replicating data across nodes, availability zones, regions, or clouds while consistently serving traffic from each location. CockroachDB’s multi-active availability within a cluster means that operators can keep applications up and running with zero data loss (RPO) and downtime (RTO) – and all without any manual intervention needed.
While Raft is powerful, particularly when users configure clusters with 3+ regions and 3+ replicas, we’ve found that at times it doesn’t account for the practical constraints that some of our customers face:
Two Data-Center (2DC) deployment limitations: In an ideal world, you would have access to three data centers to achieve regional survivability through Raft. However, today, many of you might be running your applications on-premises with only two data centers, or are running in parts of the world where there are only two available regions. You shouldn’t have to compromise on regional survivability just because you only have access to 2DCs.
Application latency requirements: CockroachDB's Raft replication ensures strict data consistency across nodes through a quorum-based consensus algorithm. However, when nodes are distributed across regions, the roundtrip time between the client and cluster for nodes to acknowledge writes can introduce additional latency.
Cross-Cluster Replication for Optimizing Resiliency, Scalability, and Latency 
To address these challenges, we have invested in building two cross-cluster replication tools: physical cluster replication (PCR; Generally Available in 24.1) and logical data replication (LDR; Preview in 24.3). PCR and LDR replicate data between clusters, allowing each cluster to maintain CockroachDB’s resiliency, scalability, and strong consistency within its own cluster.
These cross-cluster replication tools will enable you to achieve regional resiliency, low single-region write latency, and survive entire cluster outages when deploying your applications on CockroachDB. Because both LDR and PCR are built into CockroachDB, both tools replicate your data between clusters in the background and leverage elastic admission control, allowing you to achieve data redundancy without impacting your primary application traffic.
While PCR and LDR certainly have similarities, they enable different cluster architectures, have different primary use-cases, and have different tradeoffs.
PCR enables an active-passive architecture between clusters and is best used for a low-RPO, low-RTO failover as a part of your disaster recovery strategy.
LDR enables an active-active architecture between clusters and is best used to achieve high availability.
These clusters can be in different regions or even clouds, allowing for maximal fault tolerance and covering a variety of failure domains.
Using PCR for Disaster Recovery
PCR enables a continuous, uni-directional replication between two CockroachDB clusters.
In a PCR setup, one cluster is online and serves all application traffic (“primary”), and replicates into a standby cluster, which can receive application reads (available now in 24.3). Replication occurs at the cluster level, meaning that all DDL changes or changes to user permissions on the source cluster get seamlessly replicated to the standby cluster. This enables PCR to maintain transactional consistency while replicating; the standby cluster will always be a transactionally consistent copy of the primary cluster.
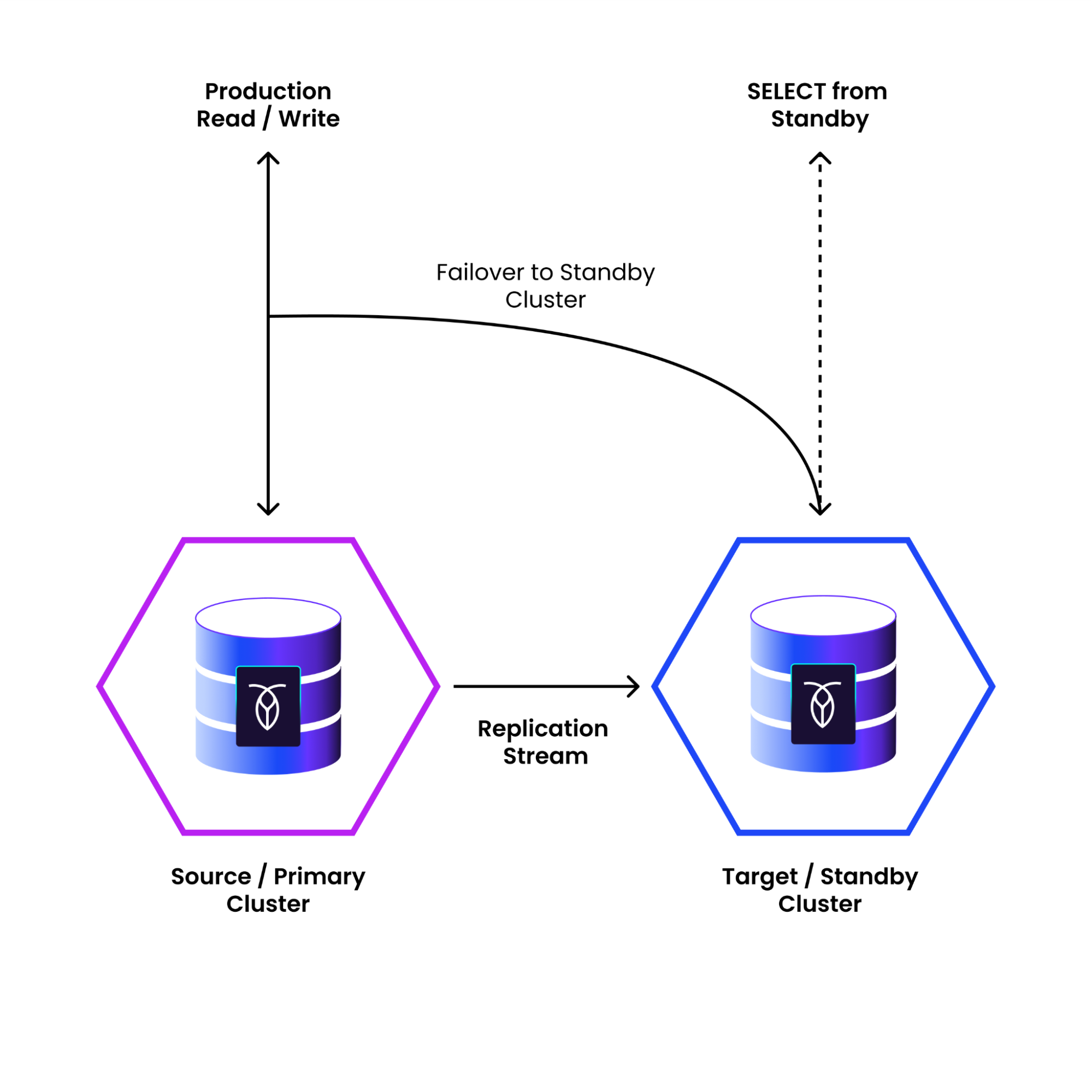
Say the worst-case scenario happens: the data-center or region that the primary cluster is in goes down. PCR allows you to failover to the standby cluster, making the standby cluster available to serve traffic within minutes (RTO), with data loss from the replication lag within seconds (RPO).
Using LDR for High Availability
LDR, on the other hand, enables continuous, bi-directional replication between two CockroachDB clusters.
In an LDR setup, both clusters are online and able to serve application traffic. Replication occurs at the table level, giving you flexibility to run different jobs (backups, CDC) on each cluster, and pick and choose which database objects you want to replicate. Because both clusters are “active” during LDR, this enables an “active-active” architecture with eventual consistency, as application writes get individually replicated between clusters.
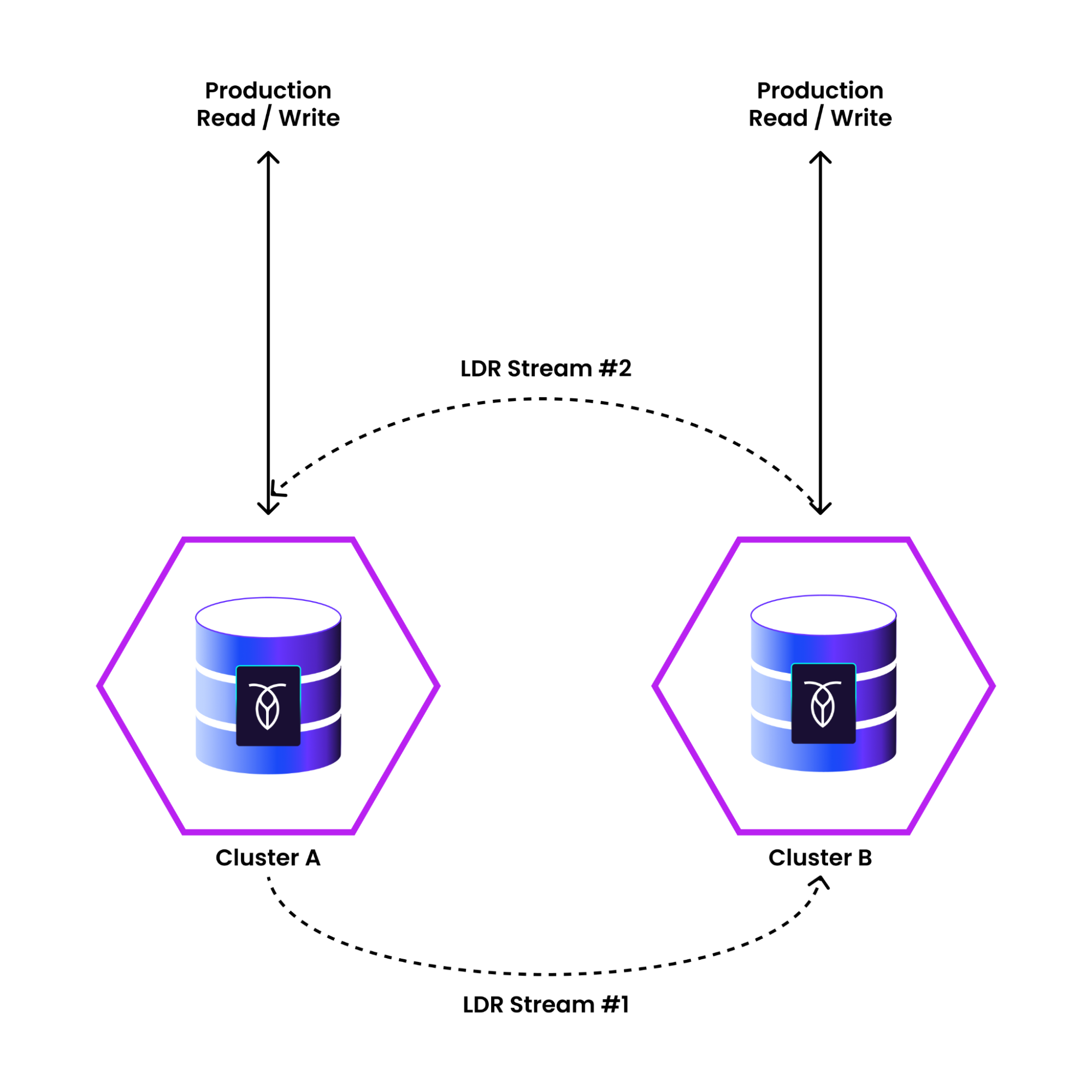
With LDR, if one of the clusters has an outage, you can redirect your application traffic to the surviving cluster. Because the other cluster is already online and able to serve application traffic, this allows LDR to be used as a tool for part of your high availability strategy.
Supporting Customers at Every Stage
While Raft replication provides unmatched resiliency within a cluster, there are use cases where Raft alone might not meet all your current requirements. In particular, customers with two data center setups are missing the critical third data center necessary for Raft regional resiliency, while other customers might find multi-region write latency too high for their low-latency application requirements.
To address these use cases, we have developed two cross-cluster replication tools – physical cluster replication and logical data replication. These tools enable resiliency even with two datacenter configurations while also providing additional low-latency architecture options for customers with demanding applications.
Check out the video below to learn more about LDR and PCR:
Get started today: https://cockroachlabs.cloud/signup.


