Chaos Testing
What is Chaos Testing?
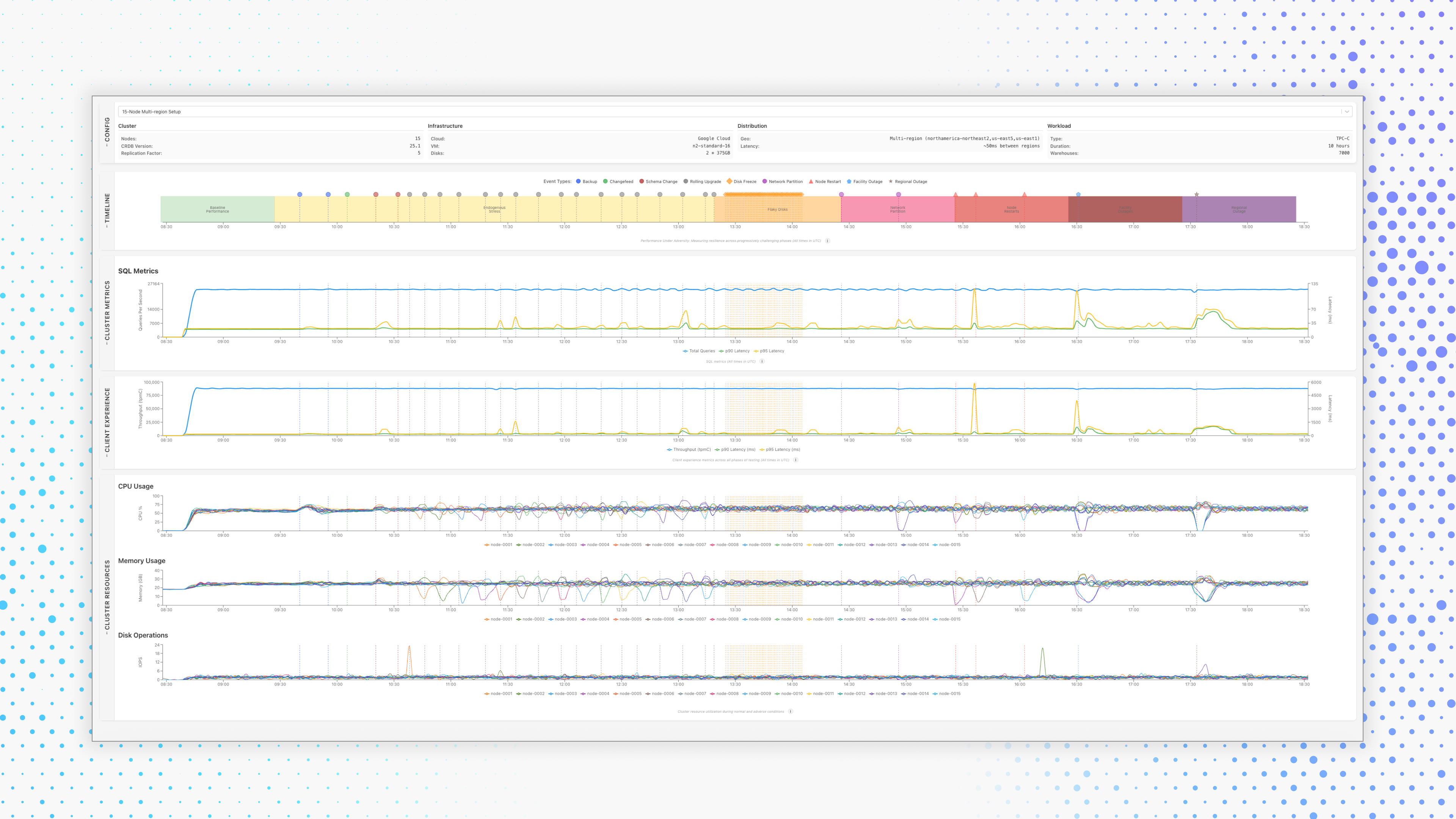
Chaos testing is a deliberate approach to fostering system resilience by introducing controlled disruptions to reveal weaknesses before they cause real-world outages. While chaos engineering focuses holistically on the full discipline — planning, automating, and analyzing experiments — chaos testing refers to the specific act of simulating faults (such as shutting down servers or injecting latency) in a system to evaluate how well it withstands different kinds of failures, including grey failures, and maintains its critical services.
As organizations shift toward cloud-native and distributed architectures, the importance of chaos testing continues to grow. Distributed systems deliver high availability and scale, but only if they’re designed and validated to handle unpredictable network partitions, hardware failures, or software bugs. Without careful resilience testing, a minor disruption can quickly snowball into a widespread outage with costly business impacts.
Why Chaos Testing Matters
In today's always-on digital world, real-world outages are on the rise, and conventional testing has to catch up with today's challenges. For instance, network partitions, server crashes, or cascading configuration errors can devastate systems if not anticipated. By simulating these events, chaos testing enables teams to:
Validate system reliability in the face of adverse conditions
Improve observability by revealing hidden points of failure and bottlenecks
Build organizational confidence that production systems can withstand the unexpected
Cockroach Labs, through its continuous and rigorous resilience innovations, demonstrates that investing in chaos testing can translate directly into enhancements in the ability to survive and recover from failures.
To learn more about chaos testing an enterprise-ready database, check out this video by Technical Evangelist, Rob Reid and see how CockroachDB survives pod failures, network partitions, corrupted data, restricted bandwidth, time faults, and so much more:
Key Concepts in Chaos Testing
Successful chaos testing is built on several foundational concepts:
Fault injection: Introducing failures such as CPU spikes, network blackholes, or node failures to observe real-world system behavior
Steady state: Defining what “normal operation” looks like, so deviations during experiments are readily captured
Blast radius: Controlling the scope of chaos to minimize risk, especially when starting with production experiments
Automation vs. manual experiments: Automated experiments (using tools) scale chaos testing and cover regression scenarios, but manual, targeted attacks can uncover edge cases or validate specific remediations
How Chaos Testing Works
Chaos testing comprises a few standard practices across organizations:
Industry tools like Chaos Monkey, Gremlin, LitmusChaos, and Chaos Mesh enable injection of failure scenarios
Staging vs. Development Environments: Early-stage chaos tests typically begin in development or staging environments but progress towards production-like environments, where the stakes and learnings are higher.
Key Metrics: Teams track vital signs—including latency, throughput, error rates, and system logs—seeking deviations from steady state that indicate real or latent failures.
Chaos Testing vs. Other Testing Methods
Traditional unit and integration testing validate components against known inputs and outputs, ensuring they function correctly under ideal conditions. Chaos testing intentionally breaks assumptions—introducing unpredictable failures to uncover issues that only manifest when things don’t go as planned. Together, these modes provide full-spectrum assurance: correctness in the small, resilience in the large.
Implementing Chaos Testing in a CI/CD Pipeline
To fully leverage chaos testing, organizations integrate it into their CI/CD pipeline:
Automate failure injection as part of regular test runs, catching regressions before they hit customers
Use “shift-left” approaches, ensuring chaos testing starts early in the development process rather than as an afterthought
Monitor for improvements over time
Modern Databases: Resilience by Default

CockroachDB was the first commercially available distributed SQL database and Cockroach Labs have been hard at work making it resilient by default. For example, CockroachDB automatically recovers from lost nodes, redistributing data and minimizing user impact. This is made possible thanks to CockroachDB’s distributed consensus, based on the Raft protocol. In addition, CockroachDB’s geo-distributed architecture allows it to survive regional outages, not just node or datacenter failures.
Chaos testing is not just a validation step, but a way Cockroach Labs hardens CockroachDB before it reaches customers, providing high availability, strong consistency, and unmatched fault tolerance.
What sets CockroachDB apart is its architecture—designed to minimize the number and severity of chaos events. Features like consensus-driven data replication, transparent node failover, and automatic recovery mean customers spend less time firefighting, and more time building.
To learn more about data resilience with CockroachDB, check out our docs.
Use Cases Across Industries
Chaos testing powers resilience in sectors where downtime is unacceptable:
Financial services: Ensuring transactional integrity despite hardware or network failures
eCommerce: Keeping storefronts available when traffic spikes or infrastructure degrades
Gaming: Maintaining state and session continuity for large, distributed player bases
Cockroach Labs’ customer success stories highlight how CockroachDB’s default resilience accelerates adoption in these markets.
Getting Started with Chaos Testing
Chaos testing is essential for building confidence and robustness in distributed systems. The engineering behind the product or service then enables faster recovery and fewer outages. With CockroachDB’s resilience-centric architecture you have a partner in building and maintaining mission-critical services.
Want to experience true resilience? Try CockroachDB for free, contact us, or explore our recent blogs or videos that highlight how our unique architecture makes high availability and survivability the norm, not the exception.
Chaos Testing FAQ
What is chaos testing?
Chaos testing is the practice of deliberately introducing faults or failures into a system to observe how it responds. The goal is to uncover weaknesses and ensure the system can maintain critical functions during disruptions—before real-world outages occur. Chaos testing often involves simulating network degradations and outages, hardware pressures and failures, and process terminations.
Why is chaos testing important for modern distributed systems?
Distributed, cloud-native systems are inherently complex and prone to rare, unpredictable failures. Traditional testing does not account for scenarios like network partitions, cascading errors, or node failures. Chaos testing helps teams identify and address these scenarios, improving reliability, observability, and confidence in production deployments.
Being single points of failure, we’ve historically babied our databases and applied hope as the primary resilience strategy. When they go down, the application goes down, so why subject them to failures? With distributed SQL databases, it’s safe (and encouraged) to test your databases just as you would any other part of your architecture.
What benefits does chaos testing provide?
Chaos testing enables organizations to:
Validate system reliability under adverse conditions
Reveal unexpected failure behavior
Build confidence that systems across the entire architecture will withstand outages
Continually improve system resilience by learning from controlled failures
What are the key concepts in chaos testing?
Several foundational concepts underpin chaos testing:
Fault injection: Intentionally introducing failures (CPU spikes, network drops, node kills)
Steady state hypothesis: Defining normal operation so anomalies are noticeable
Blast radius: Controlling the scope and reach of chaos experiments to limit risk
Automation vs. manual experiments: Automated tools scale testing; manual attacks target specific areas or edge cases
What common tools are used for chaos testing?
Popular chaos testing tools include Chaos Monkey, Gremlin, LitmusChaos, and Chaos Mesh. Organizations often develop their own internal tools to simulate particular failure modes in environments like Kubernetes. Cockroach Labs, for example, develop tool suites to simulate disk issues, pod failures, network disruptions, and more.
Where should chaos testing be done: staging or production?
Chaos testing often starts in staging or development environments to minimize risk. As confidence grows, experiments can move to production-like environments or production itself, using tight controls to ensure that learning does not come at the expense of service reliability.
What metrics should be monitored during chaos tests?
Teams typically monitor latency, throughput, database and application error rates, and system logs. Any unexpected deviation from the steady state may indicate issues needing attention.
How does chaos testing compare to unit or integration testing?
Unit and integration tests validate correctness on known inputs and outputs under expected conditions. Chaos testing, by contrast, exposes the system to unpredictable, real-world faults to assess resilience and fault tolerance. Both testing methods are critical: correctness tests verify functionality, while chaos tests provide assurance under failure.
What best practices and pitfalls should teams consider?
Start with non-critical systems as you build confidence in chaos testing.
Limit blast radius at first—target single nodes or services.
Gain organizational buy-in by sharing results and learnings widely; encouraging the use of chaos testing across teams.
Document findings to drive continuous improvement.
Which industries benefit most from chaos testing?
Chaos testing is critical for any modern business, but especially wherever downtime is not an option. For example, financial services must ensure transaction integrity. E-commerce companies need to keep storefronts online during spikes or failures. Gaming platforms must maintain state and player sessions at scale.
How should organizations get started with chaos testing?
Start small: introduce controlled failures in staging or with non-critical workloads, learn from each iteration, and expand the scope as confidence increases. Consider leveraging CockroachDB for its resilient baseline and explore Cockroach Labs’ resources for guidance and industry examples.
Why choose CockroachDB as a foundation for resilient systems?
CockroachDB’s architecture aligns naturally with chaos testing goals: it’s built to self-heal from failures, minimize downtime, and ensure transactional consistency—even under chaotic conditions. Combined with Cockroach Labs’ ongoing investment in resilience testing, it offers a robust platform for mission-critical applications.