

We didn’t implement SELECT FOR UPDATE to ensure consistency. Unlike Amazon Aurora, CockroachDB already guarantees serializable isolation, the highest isolation level provided by the ANSI SQL standard. Contention happens. And application developers shouldn’t need to risk the integrity of their data when transactions contend. To combat this, CockroachDB must occasionally return errors prompting applications to retry transactions that would risk anomalies, such as write skews. This means that just like with PostgreSQL in serializable isolation, developers need to implement retry-loops for contended transactions. For developers accustomed to relational databases with lower isolation levels, this can be an unfamiliar pattern.
In CockroachDB 20.1, we simplified the handling of client-side transaction retry errors by enabling SELECT FOR UPDATE. This feature allows applications to take explicit control of row-level locking on a per-statement basis. By locking more aggressively while reading early on in a transaction, applications can avoid situations that lead to client-side transaction retry errors.
In this post, we’ll explore transaction retry errors and how SELECT FOR UPDATE comes into play. To wrap up, we'll share a series of tests, using highly contended workloads comparing performance with and without SELECT FOR UPDATE (between v19.2 and v20.1), to evidence performance boosts and fewer client-side transaction retry errors.
SELECT FOR UPDATE Demo
In the following gif, we demonstrate SELECT FOR UPDATE avoiding a client-side transaction retry error:
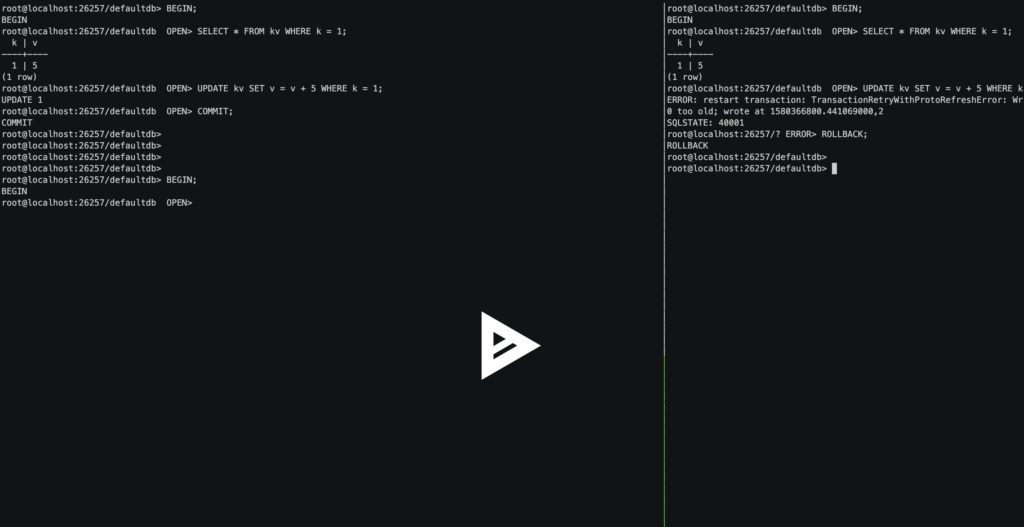
This example reveals the most common form of retry error--a transaction reads a row without acquiring a lock, it makes a modification to that row in the client, and then it attempts to write the modification back to the same row in the database. If a second concurrent transaction also modifies that row and commits between the first transaction’s read and write, the first transaction must retry. If it did not, it would risk writing the wrong updated value back to the row.
For example, imagine two increments on the same integer counter. If both increment transactions read the value 12 from the counter and both are later allowed to update it to 13, then the two writes will have “skewed” and the effect of one of the transactions will be lost. A database that provides serializable isolation cannot allow this to happen!
So on its own, the retry error is better than data corruption, but what if we don’t want to implement a client-side retry loop. That’s where SELECT FOR UPDATE comes in. By selecting the initial state of the row using SELECT FOR UPDATE in each transaction, we acquire an exclusive lock on the row earlier. If two concurrent transactions attempt to SELECT FOR UPDATE the same row, one will have to wait. This prevents us from ever getting into a situation where we have returned out-of-date information to the client about the value of the row, so we never need to revoke that information using a retry error.
Benchmarking SELECT FOR UPDATE with the Yahoo! Cloud Serving Benchmark
YCSB (Yahoo! Cloud Serving Benchmark) is an industry standard. It simulates “realistic” internet-style workloads that cause hotspots and create contention. To validate performance with SELECT FOR UPDATE, we used v19.2 and v20.1 on a 3-node cluster of c5d.9xlarge machines (AWS) and applied workloads A and F of the YCSB benchmark suite.
For both workloads A and F, we tested with and without the YCSB column families optimization. This optimization uses a column family per column to avoid contention between writes to different columns within the same row.
Workload A tests implicit SELECT FOR UPDATE statements.
When sql.defaults.implicit_select_for_update.enabled cluster setting is enabled (it defaults to true), implicit SELECT FOR UPDATE uses the read-locking subsystem internally during UPDATE statements. An UPDATE statement is translated into a read and a write in CockroachDB. Implicit SELECT FOR UPDATE means that we use FOR UPDATE locking during the read portion of the UPDATE statement. This means your applications reap the benefits of implicit SELECT FOR UPDATE without any changes.
YCSB Workload A issues 50% SELECT statements and 50% UPDATE statements along this skewed distribution. This allowed us to test the implicit SELECT FOR UPDATE functionality because the UPDATE statements uses the read-locking subsystem to improve performance.
Workload F tests explicit SELECT .. FOR UPDATE statements.
YCSB Workload F issues 50% SELECT statements and 50% read-modify-write transactions i.e. BEGIN; SELECT; UPDATE; COMMIT;. This allowed us to test the explicit select for update functionality, as we can experiment with adding FOR UPDATE to the SELECT statement in the read-modify-write transaction.
Before and After CockroachDB 20.1 Results
We ran YCSB on CockroachDB versions 19.2 and 20.1 to see the difference.
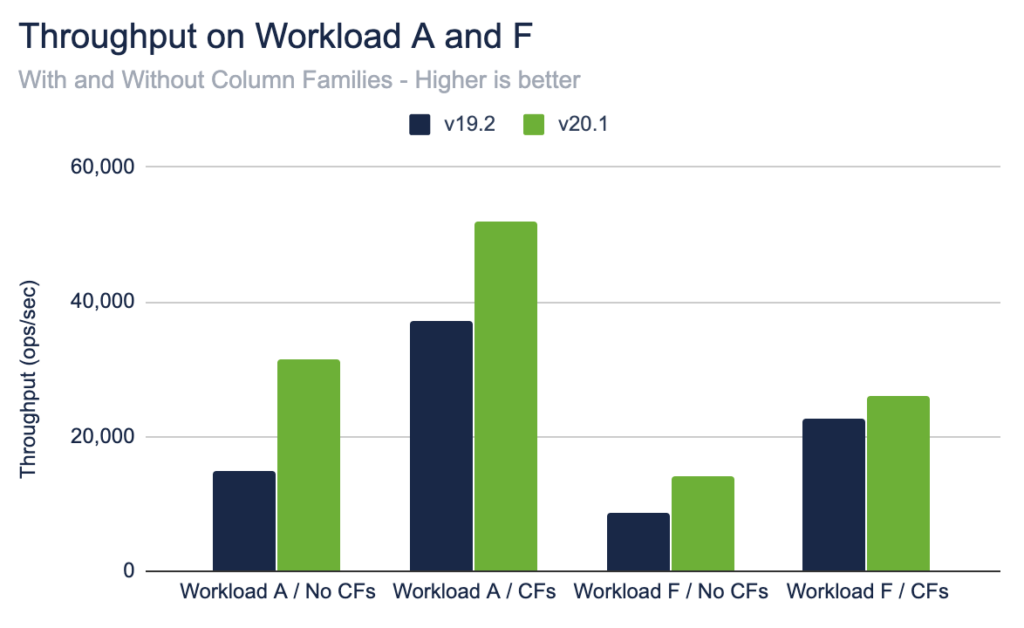
Throughput Between v19.2 and v20.1, YCSB throughput (operations/second) improved on all cases: workload A, workload F, with and without column families. The greater queueing responsiveness and reduced thrashing, due to transaction retries, and improved system throughput.
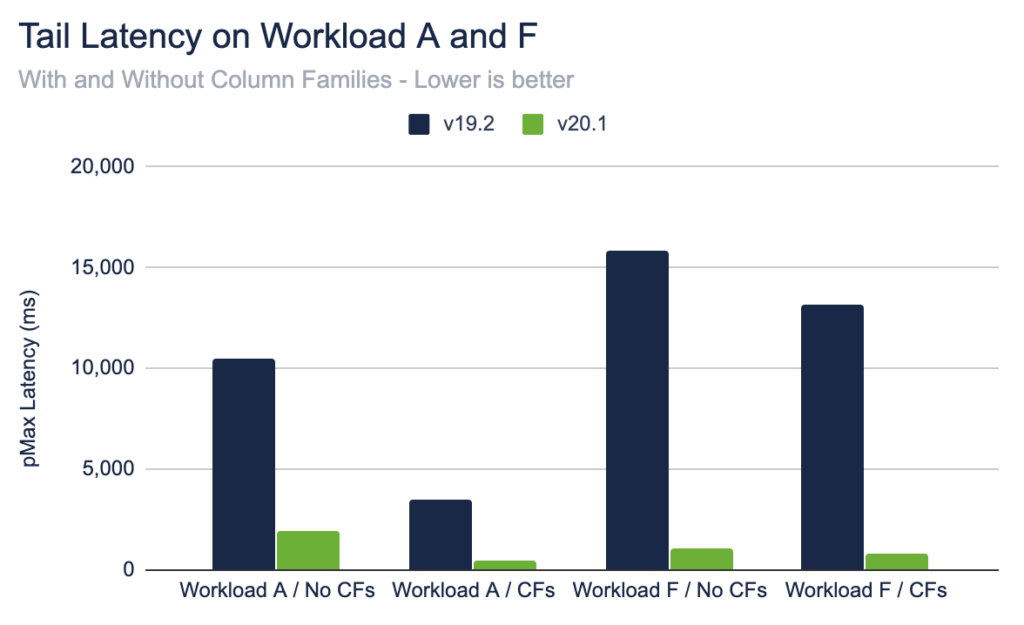
Tail Latency
Between v19.2 and v20.1, the maximum transaction latency dropped across all workloads and with and without column families. This demonstrates that the improved fairness characteristics of SELECT FOR UPDATE queueing translates to reduced tail latencies and more predictable performance.
Number of transaction errors
We returned to the inspiration for implementing SELECT FOR UPDATE by measuring the number of client-side transaction retries while running YCSB. YCSB’s Workload F performs multi-statement transactions (BEGIN; SELECT; UPDATE; COMMIT;) and is therefore susceptible to client-side retries.
The Admin UI reports the number of client-side transaction retries in the sql.restart_savepoint.rollback.count report:
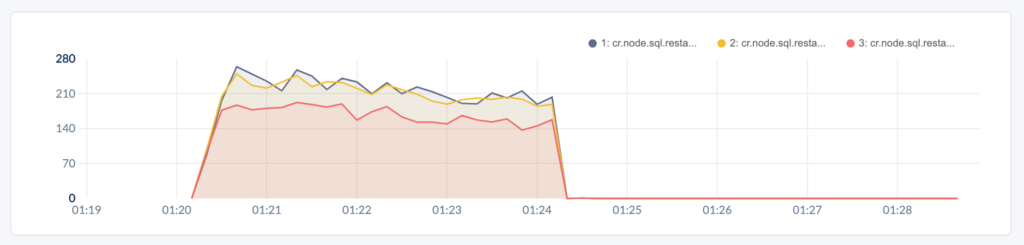
The test started by running the Workload F against Cockroach v19.2. Just after 01:24, Cockroach was upgraded to v20.1 to enable our implementation of SELECT FOR UPDATE - the moment of truth. The load generator started adding a FOR UPDATE suffix to the SELECT statement in the multi-statement transaction. Client-side retries disappeared. All retry conditions hit on the first statement in the transaction, allowing them to be retried transparently on the server.
Conclusion
In CockroachDB 20.1, tests demonstrate enabling SELECT FOR UPDATE improved CockroachDB in three ways:
Throughput
Tail latency
Number of transaction retry errors
For implicit UPDATE statements, this new feature is enabled by default in CockroachDB 20.1. But for explicit SELECT FOR UPDATE, you'll need to explicitly modify your queries to reap the benefits. To get started with SELECT FOR UPDATE, dive into our SELECT FOR UDPATE documentation.



