
Syndication from What Does Write Skew Look Like by Justin Jaffray
This post is about gaining intuition for Write Skew, and, by extension, Snapshot Isolation. Snapshot Isolation is billed as a transaction isolation level that offers a good mix between performance and correctness, but the precise meaning of “correctness” here is often vague. In this post I want to break down and capture exactly when the thing called “write skew” can happen.
A quick primer on transactions
The unit of execution in a database is a transaction. A transaction is a collection of work that either completes in its entirety or doesn’t run at all. There are no half-run transactions. There are a number of guarantees typically provided around transactions, but we’re going to focus on isolation. Isolation is what allows users of a database to not be concerned with concurrency and it determines the extent to which a transaction appears as if it’s running alone in the database.
For example, if transaction A reads x = 5, then transaction B overwrites that to x = 8, if A reads again and sees x = 8, A’s isolation has been violated: it no longer can maintain the illusion that it’s the only process running in the database.
You can think of a transaction as a process which performs reads and writes in a database. Because of this, we often talk of the read set and write set of any given transaction. You can think of the read set as the set of memory locations read by the transaction, and the write set as the set of memory locations written to by the transaction.
Isolation levels in a database are concerned with which executions (also called “histories”) are allowed by the database and which are not. A lower isolation level will reject fewer histories, while a higher isolation level will reject more histories. For instance, a history in which a transaction reads a write from an aborted transaction is probably no good and should be blocked (somehow) by the database.
The classification of various possible isolation levels is an interesting topic, but here we’re going to focus on the relationship between just two of them: SERIALIZABLE and “Anomaly SERIALIZABLE” (sometimes known as SNAPSHOT).
SERIALIZABLE
In some sense, serializability is “perfect” isolation. This is what we get when it appears as if every transaction actually is run in the database all by itself, even though that’s probably not what’s going on under the hood (my server has lots of cores, I want to make use of them). If we were running every transaction all by itself, this would just be called “serialized”. Since it’s just equivalent to running them individually, it’s called serializable.
The clean definition of a serializable execution is, “one which is equivalent to some serial execution,” a serial execution being one in which we just run our transactions one at a time with no interleaving of operations due to concurrency.
We can think of serializability as a scheme in which every transaction logically does all of its work at a single, unique timestamp. Since every transaction, conceptually at least, happens instantaneously, there is no troublesome concurrency with which the user should be concerned.
As an aside, it’s worth noting that “the SERIALIZABLE isolation level” and “a serializable execution” are two distinct concepts. Most discussions I’ve seen conflate them, despite this leading to confusing questions such as “how does a transaction which is denoted ‘serializable’ interact with one which is not”?
Anomaly SERIALIZABLE (but actually SNAPSHOT)
Serializability is strange, being one of the few concepts in transactional theory that has a very simple and unambiguous definition and yet still somehow managed to have two completely different mainstream meanings.
Back in the day, when ANSI defined the SERIALIZABLE isolation level, their definition, while correct, could be interpreted to not preclude a lower isolation level now called “Snapshot Isolation”, and a handful of enterprising database vendors took advantage of this fact. The most well-known example of this is that if you ask Oracle for SERIALIZABLE, what you get is actually SNAPSHOT.
This entire post is in some sense about understanding what is the deal with Snapshot Isolation, so if you don’t get intuition for it immediately, don’t fret.
There are two main properties that characterize Snapshot Isolation:
A transaction in Snapshot Isolation has two significant timestamps: the one at which it performs its reads, and the one at which it performs its writes. The read timestamp defines the “consistent snapshot” of the database the transaction sees. If someone else commits writes at a point after a transaction T’s read timestamp, T will not see those changes (this is generally enforced using
. We’ll refer to a transaction named “x” as Tx and its read and write timestamps as Rx and Wx, respectively.
Two transactions are concurrent if the intervals during which they are executing overlap (R1 < W2 and W1 > R2). In Snapshot Isolation, the database enforces that two committed transactions which are concurrent have disjoint write sets (meaning they don’t write to any of the same memory locations). Any transaction whose commit would cause this restriction to be violated is forced to abort and be retried.
It’s not obvious why, or even if, SNAPSHOT is distinct from SERIALIZABLE. It took a while before anyone figured out that it was. The anomaly that occurs in Snapshot Isolation was termed “write skew” (depending on who you ask, there is another variety, but I’m considering it a kind of write skew for simplicity), and the prototypical example of it looks like this:
Consider two transactions, P and Q. P copies the value in a register x to y, and Q copies the value in a register y to x. There are only two serial executions of these two, P, Q or Q, P. In either, the end result is that x = y. However, Snapshot Isolation allows for another outcome:
Transaction
PreadsxTransaction
QreadsyTransaction
Pwrites the value it read toyTransaction
Qwrites the value it read tox
This is valid in Snapshot Isolation: each transaction maintained a consistent view of the database and its write set didn’t overlap with any concurrent transaction’s write set. Despite this, x and y have been swapped, an outcome not possible in either serial execution.
Who cares?
It’s fair to ask why anyone should care if we’re just a little bit nonserializable. Snapshot feels…pretty close to serializable, right? What is lost by our transactions not being serializable? Ben Darnell has a good outline for real-world problems that can arise due to a lack of serializability in Real Transactions are Serializable. He references Warszawski and Bailis who explore security vulnerabilities in real-world applications due to a lack of serializability. I guess I’m not a pragmatic person; I find this empirical evidence convincing, but not particularly satisfying. Is there a more fundamental reason serializability should be considered the one true way? Why is serializable the meaningful level of isolation? After all, the classic isolation “anomalies” are only “anomalous” when viewed from the perspective of serializability-as-default. If your default mode of thinking is SNAPSHOT, write skew is just normal behaviour and SERIALIZABLE is throwing away perfectly good histories.
I think there are two main answers to this question. The first is simple: SERIALIZABLE is the only isolation level that “makes sense”. By “makes sense”, I mean “was conceived in a principled, meaningful way”. Consider the loss of formalism and generality when going from “every execution is equivalent to some serial execution” to “absence of these very specific phenomena whose definitions are biased towards the operations of SQL”.
This lack of formalism was eventually rectified by Atul Adya in his thesis “Weak Consistency: A Generalized Theory and Optimistic Implementations for Distributed Transactions”, but the definitions given for lower levels are still significantly more contrived and less elegant than the definition for serializable.
A more concrete reason than “nothing else makes sense” is a question of local vs. global reasoning. If a set of transactions must maintain some kind of invariant within the database (for instance, the sum of some set of fields is always greater than zero). In a database that guarantees serializability, it’s sufficient to verify that every individual transaction maintains this invariant on its own. With anything less than serializability, including Snapshot, one must consider the interactions between every transaction to ensure said invariants are upheld. This is a significant increase in the amount of work that must be done (though in reality, I think the situation is that people simply don’t do it), a point made by Alan Fekete in on isolation.
When is Snapshot not Serializable?
This brings us to our central question: in a database that provides Snapshot Isolation, can we characterize all the nonserializable behaviour? What can we say about anomalies in Snapshot Isolation in general? What must be done to eliminate them? Fekete, Liarokapis, O’Neil, O’Neil, and Shasha (FLOOS) provide a precise answer in Making Snapshot Isolation Serializable. I’m going to attempt to outline their analysis with a focus on building up intuition for Snapshot Isolation.
It’s interesting that this paper comes at this problem from a strange angle: it’s aimed at a DBA with access to all of the transactions being run against a database, and provides a procedure by which they can (by hand) statically analyze these transactions to verify that they will always execute serializably. I would be extraordinarily surprised if anyone besides the authors ever actually did this, but this work led the way for the Serializable Snapshot Isolation algorithm a couple years later.
To proceed, we need a little bit of formalism. We need to figure out how to talk about dependencies between transactions.
If Ta and Tb are transactions, we say Ta happens before Tb (written Ta → Tb) if one of the following is true:
Ta writes a value which Tb reads (a wr dependency),
Ta writes a value which Tb overwrites (a ww dependency), or
Ta reads a value which Tb overwrites (a rw dependency or anti-dependency).
To remember what’s going on here, just think that in the “wr”, “ww”, “rw” shorthands, the letter on the left matches the transaction on the left of the →, and same with the right, so if Ta → Tb is brought about by an “rw” dependency, Ta reads and then Tb writes.
Here’s how you should think about each of these cases:
In a wr dependency, Ta writes a value and then Tb reads it, so Tb can’t come first, since the value it reads doesn’t exist until Ta runs.
In a ww dependency, since Tb overwrote Ta’s value, Tb has to come last, since its is the value that replaced Ta’s value.
In a rw dependency, Ta has to come before Tb because after Tb, the value Ta reads no longer exists.
It is a very important observation that an rw dependency is the only dependency that can occur between concurrent transactions in Snapshot Isolation. This is because
If a ww dependency occurred, it means the two transactions had intersecting write sets, which is not possible between concurrent Snapshot transactions.
If a wr dependency occurred, for the later transaction to view the former’s writes, it can’t have begun before the former had committed.
We can represent these relationships as a serialization graph. The vertices in this graph are transactions, and there’s an arc from Tx to Ty when Tx → Ty.
Say we had the following set of dependencies:
Ta → Tb (wr dependency)
Tb → Tc (rw dependency)
Tb → Td (ww dependency)
From this we get this serialization graph:
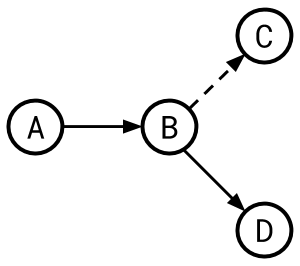
A dashed line indicates an anti- or rw-dependency. Here’s a set of dependencies that isn’t serializable:
Ta → Tb (wr dependency)
Tb → Tc (rw dependency)
Tc → Ta (rw dependency)
With the following serialization graph:
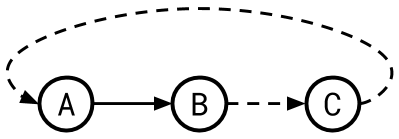
Here we have a cycle: a comes before b comes before c comes before a.
A history is serializable if and only if its serialization graph has no cycles. With this framework, it is “easy”, then, to guarantee serializable execution: when a transaction goes to commit, check if its commit would create a cycle in the serialization graph. If the answer is yes, the transaction must not be allowed to commit. This technique is called “Serialization Graph Testing”.
Finding and killing all cycles is not a perfect solution if we care about performance. Detecting cycles in a graph is expensive, especially when the graph is large. Worse, because transactions are constantly committing, the graph is constantly changing. This leads us then to another question: if we know the graph was produced in a database providing snapshot isolation (as many do), is there anything special we can say about the structure of a cycle in said graph that would allow us to detect it more easily? The answer is yes. From Theorem 2.1 of FLOOS: Suppose H is a multiversion history produced under Snapshot Isolation that is not serializable. Then there is at least one cycle in the serialization graph DSG(H), and we claim that in every cycle there are three consecutive transactions T1, T2, T3 (where it is possible that T1 and T3 are the same transaction) such that T1 and T2 are concurrent with an edge T1 → T2, and T2 and T3 are concurrent with an edge T2 → T3.
Remember that the only dependency that can occur between concurrent transactions in Snapshot Isolation is an rw dependency. Thus, what FLOOS is saying here is that if there is a cycle in the serialization graph of a Snapshot history, in that cycle, there are always two consecutive dashed (rw) arcs somewhere.
Theorem 2.1 is the basis of the “Serializable Snapshot Isolation” algorithm used today in Postgres: Running in Snapshot Isolation, every transaction tracks whether it is involved in a rw-dependency on either side, and if it is on both ends of an rw dependency, it (or its successor, or its predecessor) gets aborted. This conservatively aborts some transactions which are not involved in cycles, but definitely prevents all cycles. This approach is outlined in Serializable Isolation for Snapshot Databases.
It turns out that even in Snapshot Isolation, there are so few ways two transactions can have a dependency, we can list them out explicitly. In each of these diagrams, time flows from left to right. We fix T1 as the transaction which has the earlier write timestamp. A line denotes a transaction, with its left tip denoting the point at which it performs its reads and its right tip denoting the point at which it performs its writes.
Case 1: T2 reads a write of T1 (wr)
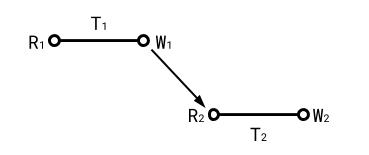
Case 2: T2 overwrites a write of T1 (ww)
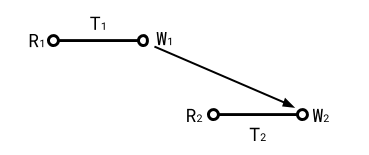
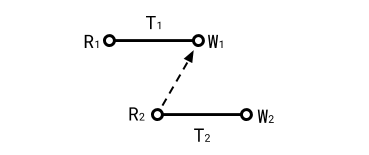
Case 3: T2 overwrites a read of T1 (rw)
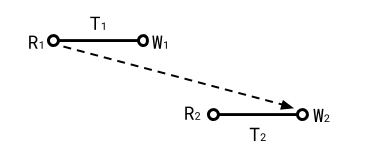
Case 4: T2 overwrites a read of T1, T1 and T2 concurrent (rw)
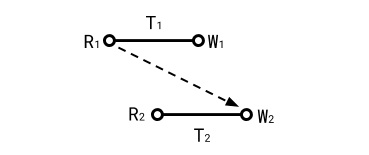
Case 5: T1 overwrites a read of T2, T1 and T2 concurrent (rw)
There’s also secret cases 4b and 5b where R2 comes before R1, but the differences are immaterial for our purposes, so we won’t consider them separately. Here’s the proof of the theorem (recall the theorem states that in any cycle there are two consecutive rw arcs somewhere):
Say we have a cycle in a Snapshot history. Consider the transaction in the cycle with the earliest write timestamp. Call this T3, its predecessor T2, and T2’s predecessor T1. Since T3 has the earliest write timestamp, the only way a transaction can come before it in the cycle is via case 5. So T2 is the predecessor of T3 and they are connected as in case 5.
Next, the read timestamp of T1 must come before the write timestamp of T2 or else there’s no way T1 could precede T2, so R1 < W2. Further, the write timestamp of T1 must come after the write timestamp of T3, since T3 by definition has the earliest such timestamp. So W1 > W3 > R2. So now we know R1 < W2 and W1 > R2, which means T1 is concurrent with T2. Since concurrent transactions can only have an rw dependency, we’re done.
Here’s what this looks like:
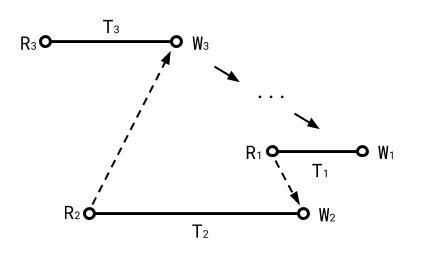
T2 is something of a “pivot” transaction that bridges the gap between the last transaction and the first.
And that’s it! It’s not too complex of an argument, but we’ve completely characterized how anomalies can occur in Snapshot Isolation. As a fun exercise, try to draw the diagrams for how this fits into the example posed at the beginning of this post (with x and y) and the read only anomaly.
Conclusion
If you’re running a mainstream database besides CockroachDB, odds are good that the isolation level you’re running at is SNAPSHOT, or even lower. Almost no other mainstream databases default to SERIALIZABLE, and many don’t provide it at all. Given the prevalence of SNAPSHOT, I think it’s important to understand what exactly that means.
As I hope you’ve been convinced, the commonly understood example of “write skew” is insufficient. If you’d like to learn more about this topic, I can’t speak highly enough of:
Thanks to Arjun Narayan, Ben Darnell, Sean Loiselle, Ilia Chtcherbakov, and Forte Shinko for reading this post and providing feedback.
Illustration by Jamie Jacob


