

Most software projects start their lives linked to a simple, single-instance database. Something like Postgres or MySQL.
But as companies grow, their data needs grow, too. Sooner or later, a single instance just isn’t going to cut it.
That’s where data partitioning comes in.
What is database partitioning?
Database partitioning (also called data partitioning) refers to breaking the data in an application’s database into separate pieces, or partitions. These partitions can then be stored, accessed, and managed separately.
Partitioning your data can help make your application more scalable and performant, but it can also introduce significant complexities and challenges. In this article, we’ll take a look at the advantages and disadvantages of data partitioning, and look at some strategies for partitioning more effectively.
What are the advantages of partitioning your data?
Partitioning can have many advantages, but these are some of the most common reasons that developers and architects choose to partition their data:
Improve scalability
Improve availability
Improve performance
Data partitioning can improve scalability because running a database on a single piece of hardware is inherently limited. While it is possible to improve the capability of a single database server by upgrading its components — this is called vertical scaling — this approach has diminishing returns in terms of performance and inherent limitations in terms of networking (i.e., users located somewhere geographically far from the database will experience more latency). It also tends to be more expensive.
However, if data is partitioned, then the database can be scaled horizontally, meaning that additional servers can be added. This is often a more economical way to keep up with growing demand, and it also allows for the possibility of locating different partitions in different geographic areas, ensuring that users across the globe can enjoy a low-latency application experience.
Data partitioning can improve availability because running a database on a single piece of hardware means your database has a single point of failure. If the database server goes down, your entire database — and by extension, your application — is offline.
In contrast, spreading the data across multiple partitions allows each partition to be stored on a separate server. The same data can also be replicated onto multiple servers, allowing the entire database to remain available to your application (and its users) even if a server goes offline.
Data partitioning can improve performance in a variety of different ways depending on how you choose to deploy and configure your partitions. One common way that partitioning improves performance is by reducing contention — in other words, by spreading the load of user requests across multiple servers so that no single piece of hardware is being asked to do too much at once.
Or another example: you might choose to partition your data in different geographic regions based on user location so that the data that users access most frequently is located somewhere close to them. This would reduce the amount of latency they experience when using your application.
There are other potential advantages to data partitioning, but which specific advantages you might anticipate from partitioning your data will depend on the type of partitioning you choose, as well as the configuration options you select, the type of database you’re using, and more.
Let’s dig into some of those details further.
Types of database partitioning
Although there are other types of database partitioning, generally speaking, when people discuss partitioning their data, they’re referring to either vertical or horizontal partitioning.
In practice, partitioning is rarely quite as simple as splitting up a single table, but for illustration purposes here, we’ll use the example of a database with a single table to demonstrate the differences between these two types of partitioning. Here’s our example table:
Vertical partitioning
Vertical partitioning is when the table is split by columns, with different columns stored on different partitions.
In vertical partitioning, we might split the table above up into two partitions, one with the id, username, and city columns, and one with the id and balance columns, like so.
Partition 1
Partition 2
Generally speaking, the reason to partition the data vertically is that the data on the different partitions is used differently, and it thus makes sense to store it on different machines.
Here, for example, it might be the case that the balance column is updated very frequently, whereas the username and city columns are relatively static. In that case, it could make sense to partition the data vertically and locate Partition 2 on a high-performance, high-throughput server, while the slower-moving Partition 1 data could be stored on less performant machines with little impact on the user’s application experience.
Horizontal partitioning and sharding
Horizontal partitioning is when the table is split by rows, with different ranges of rows stored on different partitions.
To horizontally partition our example table, we might place the first 500 rows on the first partition and the rest of the rows on the second, like so:
Partition 1
Partition 2
Horizontal partitioning is typically chosen to improve performance and scalability. When running a database on a single machine, it can sometimes make sense to partition tables to (for example) improve the performance of specific, frequently used queries against that data.
Often, however, horizontal partitioning splits tables across multiple servers for the purposes of increasing scalability. This is called sharding.
Sharding
Sharding is a common approach employed by companies that need to scale a relational database. Vertical scaling — upgrading the hardware on the database server — can only go so far. At a certain point, adding additional machines becomes necessary. But splitting the database load between multiple servers means splitting the data itself between servers. Generally, this is accomplished by splitting the table into ranges of rows as illustrated above, and then spreading those ranges, called shards, across the different servers.
Since the load of requests can be spread across different shards depending on the data being queried, sharding the database can improve overall performance. As new data is added, new shards can be created — although this often involves significant manual work — to keep up with the increasing size of the workload coming from the application.
RELATED
Why sharding is bad for business
While both vertical and horizontal partitioning, and particularly sharding, can offer some real advantages, they also bring significant costs. Let’s dive into the challenges of partitioning data in the real world, and look at some ways to address these challenges.
Data partitioning in the real world: Costs, challenges, and strategies
We’ve talked about the advantages of data partitioning, and there are many! However, breaking your data into parts and spreading it across different servers does add complexity, and that complexity comes with significant additional costs.
To understand how, let’s take a look at one of the most common real-world examples of data partitioning: sharding a SQL database to keep up with a growing userbase.
Sharding a legacy SQL database
Let’s imagine a pretty common scenario: a growing company that has a single-instance Postgres database linked to its production application, as well as a couple of backup copies that aren’t typically accessed by the application, but can be used to ensure no data is lost in the event that the primary database goes down.
As this company grows, it will eventually bump up against the inherent performance limitations of this kind of configuration. A single server, even a powerful one, is simply not powerful enough to handle the load of transactions coming in from their fast-growing userbase.
Engineers at the company foresee this problem, and begin making plans to shard the database before the load becomes heavy enough that users notice decreased performance. This decision alone may necessitate additional hires if the company doesn’t already have skilled, senior SRE and DevOps resources, but even with the right players already on staff, designing and testing the new system will require a significant amount of time.
For example, imagine that the team comes up with an initial plan to scale up by splitting the database into three active shards, each with two passive replica shards for backup. Before they can actually execute this plan, they also need to spend time designing a few more things:
An approach to splitting the data that will result in the workload being spread relatively evenly among the three active shards so that no single shard receives a disproportionate amount of queries from the application and becomes overloaded
Application code that routes queries from the application to the correct shard (keeping in mind that this will change over time as you add or remove shards)
Support code for all other systems that interact with the database (e.g., if a data pipeline or changefeed sends updates to an analytics database or other application services, that will likely need to be adapted to work with the new sharded design while minimizing the possibility of consistency issues)
Approaches to handling once-simple procedures that become complex when multiple shards are involved, such as reading a range of data that spans more than one shard, executing a transaction that updates rows on two different shards, etc.
Approaches to updating both the database software and the database schema
Designing these systems, writing the code, testing the changes, and migrating the workload onto the new, sharded system can take significant amounts of time and money. Maintaining all of the code required also requires significant engineering time and expertise. Your engineering team will have to write and maintain a lot of code for doing things you would expect the database to do on its own in a single-instance deployment.
RELATED
Distributed transactions: What, why, and how to build a distributed transactional application
Schema and database software updates, which are inevitable from time to time, also can also add engineering hours, and executing them often means taking the database (and by extension the application) entirely offline for at least a brief period.
Along with those relatively immediate costs, the complexity of managing a sharded database will scale up as the company scales. As shards or regions are added, significant portions of the system will need to be reworked — the application code governing query routing logic, for example, will need to take the new shards into account. The manual work involved here is significant, and it will be required each and every time the system is scaled up.
For example, here’s a reference architecture for a real-money gaming application with a sharded database and operations in three separate regions:
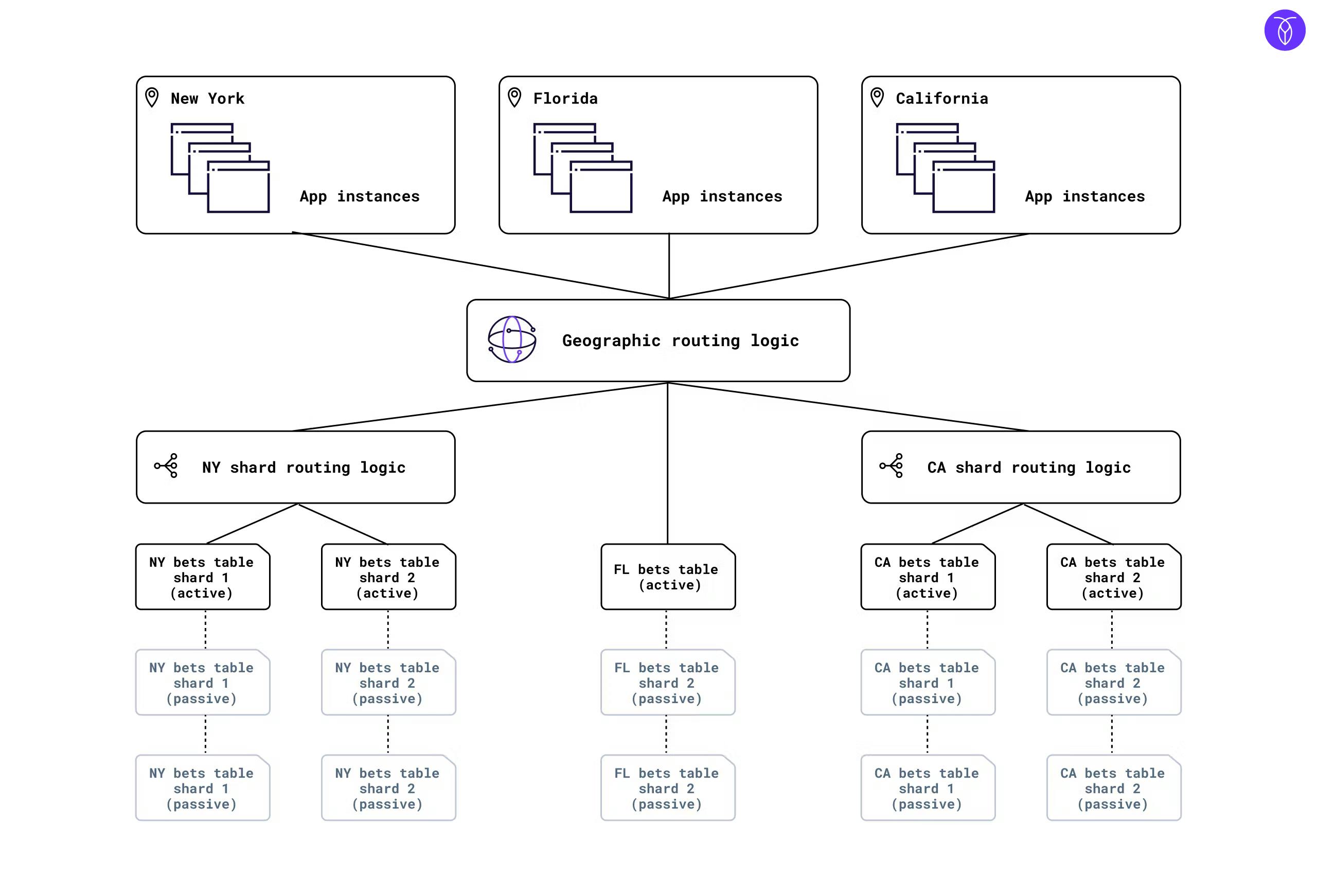
This kind of architecture creates a better application experience for users, but building and maintaining it is complex and expensive, and grows proportionally more complex and expensive as the company grows. If a new shard is added to California, the California shard routing logic will need to be reworked manually. When the company opens business in a new state, the geographic routing logic will require attention. Often, the data itself will need to be redistributed each time new shards are added, to reduce the chances of having particular servers handling disproportionate percentages of the overall workload as it increases.
Needless to say, as the system scales up and the complexity scales up, so do the costs. Given that a single SRE can cost well over $200,000 per year, the actual cost of running a system like this can quickly explode well beyond the apparent “sticker price” of cloud/hardware costs.
Once, there was little alternative to this approach. These costs were simply the price of entry for companies that needed transactional databases to be performant at scale.
Now, however, a new class of databases exists that can automate a lot of the complexity of sharding, providing developers with the familiar benefits of a single-instance relational database even at global scale, and eliminating much of the manual work that can make sharded systems so costly.
Distributed SQL databases and “invisible” sharding
A distributed SQL database is a next-generation SQL database that has been designed with data partitioning in mind. Distributed SQL databases partition and distribute data automatically, offering the automated elastic scalability and resilience of NoSQL databases without compromising on the ACID transactional guarantees that are required for many OLTP workloads.
How distributed SQL databases work is beyond the scope of this article, but from an architect or developer perspective, a distributed SQL database such as CockroachDB can be treated almost exactly like a single-instance Postgres database. Unlike with sharding, there’s no need to write application logic to handle data routing for partitions or specific geographies. The database itself handles all of that routing automatically. Challenges like maintaining consistency across database nodes are also handled automatically. And in the case of CockroachDB specifically, schema changes and software updates can be executed online, without downtime.
Compare the two diagrams below (traditional sharding on the left, CockroachDB on the right) and it’s easy to see how using a distributed SQL database can save significant amounts of both time and money for your team.

And where adding regions or shards results in significant additional manual work in a sharded approach (left), adding nodes in CockroachDB is as simple as clicking a button — and even that can be easily automated. Adding regions, too, is as easy as a single line of SQL:
ALTER database foo ADD region "europe-west1";Learn more about how to architect scalable distributed systems efficiently in this free O’Reilly guide.


