

Transactions make up an important part of the database workload for most modern applications. And when it comes time to scale up operations for a growing business, distributing those workloads across multiple hardware systems for horizontal scalability, high availability, and fault tolerance is often an important part of the plan.
But how do database transactions get distributed, and what are some of the challenges and approaches involved in distributing transactional workloads?
We’ll get to that, but let’s start with a simpler question: what is a transaction in the context of databases? (If you already know this stuff, feel free to skip this section and start looking at the challenges of actually distributing your database transactions.)
What is a transaction (in databases)?
In databases, a transaction is a set of operations that we want to perform on our data. Typically, a transaction is an all-or-nothing affair — we want all of the operations to complete successfully, or if that’s not possible, to scrap the entire thing.
For a simple example, imagine a purchase from an online store. If a customer purchases something worth $20, we probably want to subtract $20 from their account (that’s one operation) and add $20 to our account (that’s another operation). But we don’t want one of those operations to complete and the other one to fail. So we package them together as a transaction, and our database will commit the changes only if both operations complete successfully.
What is a distributed transaction?
What is distributed transaction? A distributed transaction is a set of operations that we want to perform on our data, but it is committed to more than one piece of hardware. So, rather than writing the changes associated with our $20 transaction to the hard drive of a single-instance database, we’re writing those changes to several different database nodes. These nodes are generally in different locations and connected via a network.
Why use distributed transactions
Distributed transactions are generally used because there are significant advantages to distributing your database across multiple nodes, and potentially even across multiple regions. These advantages include:
Straightforward horizontal scaling.
To add more power to the database, you can simply add nodes rather than having to upgrade the hardware on a single machine. This is generally easier and it is often cheaper, too.
Higher availability.
If your database is distributed across multiple nodes and a single node goes down, generally the other nodes can continue to serve your workloads, allowing your application to continue unaffected. In contrast, if your entire database is on a single machine and that machine goes offline or encounters an error, your application will stop functioning until the machine has been fixed.
Better user experience.
Properly configured, a distributed database can often offer superior performance because there are multiple machines able to share the load. In multi-region configurations, data can also be located geographically close to the users who need it most, lowering the latency for users when they access the application.
In the context of a distributed transaction in microservices, this setup allows each service to handle specific tasks independently, improving fault tolerance and scalability. A distributed transaction in DBMS can also leverage similar benefits by distributing database tasks across multiple servers or nodes.
In fact, the advantages of distributing the database are so significant that beyond a certain point of scale, distributing the database is essentially a requirement.
However, distributing the database does add some complexity to the way transactions — an important part of mission-critical workloads for most companies — are handled.
Distributed transactions and consistency challenges
Distributed transactions are more complex than transactions on a single-instance database because we need some way to ensure that each database node is consistent with the others.
The diagram below illustrates one potential problem with distributed transactions. Imagine we have an application attempting to commit a transaction to three separate database nodes (perhaps the same data is replicated on all three nodes, or perhaps the transaction affects multiple rows, and the different rows are stored on different nodes). In the diagram, the transaction is successfully written to the first two nodes, but fails to write to the third — perhaps due to a network disconnection or an error on the node itself. This introduces a state of inconsistency — the first two nodes and the third node “disagree” about what data is correct.
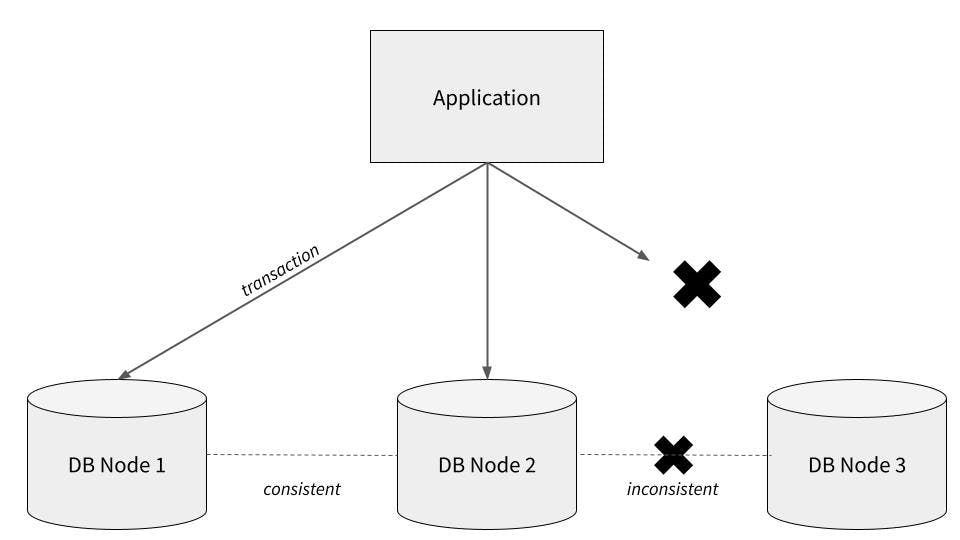
Needless to say, inconsistency in a database can cause all kinds of problems, particularly when it comes to the kinds of workloads that use transactions (payment processing systems, for example).
So, how can we ensure our database remains consistent even when it is partitioned across multiple nodes? There are a variety of approaches, each with its own advantages and disadvantages. Let’s take a look at some real-world examples of workable patterns for distributed transactions.
Distributed transaction patterns: Real-world examples
The two-phase commit pattern
We’ll start by looking at a very basic, no-frills approach.
The two-phase commit pattern works by syncing database nodes in two phases, in which each node must first prepare to commit and then execute the commit. Only if both stages complete successfully will the transaction be completed. Here’s a diagram of how it looks in a simple two-node configuration:
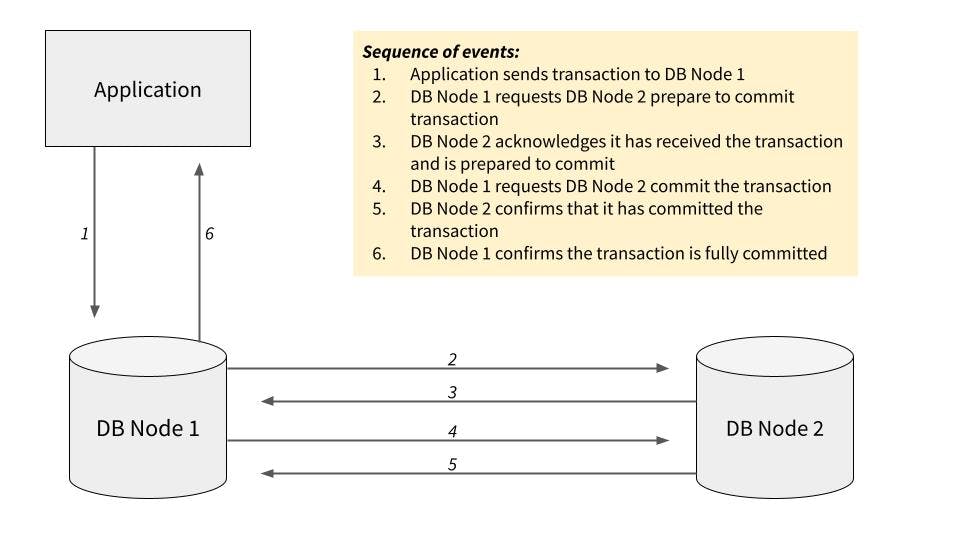
This approach is workable and will ensure that both database nodes remain consistent. However, it does have some significant disadvantages.
The first is that it requires locking resources on both nodes while the two phases complete. While those resources are locked, they’re inaccessible for other database operations, which can quickly become a performance bottleneck at scale.
The second is that it grows increasingly complex with each additional node added, and it’s not particularly fault-tolerant. If a single node goes down, the transaction will fail even if all of the other nodes are online and capable of committing the transaction. This negates one of the majors advantages of distributing your database, since the system will eventually be stuck anytime even one node goes down.
Active-passive replicas
Another approach to handling transactions in a distributed system is to use an active-passive setup, with a single node serving writes backed up by one or more read-only replicas.

This approach has some significant advantages over the two-phase pattern. For one, when properly configured it can be more fault-tolerant–if the active node goes down, one of the passive nodes can be switched to become the active node to allow for continued operations (the switchover generally does take time and might result in a short service outage, but it can be automated to minimize downtime).
However, this approach has some disadvantages too. Again, we are missing out on some of the reasons for using a distributed system in the first place. Write workloads cannot be shared between machines, they must all be handled by the active node. Thus, although (in the configuration above) the database has three nodes, its write performance is still bottlenecked by the performance limitations of the single active node.
It also may not be easy to scale. Adding additional passive nodes is relatively straightforward, but adding additional active nodes would require some kind of system for resolving consistency problems between the active nodes when they arise.
Let’s look at an example of a system that’s built to do exactly that.
Multi-active distributed transactions
Arguably the best approach to handling distributed transactions involves using a multi-active system, in which all database nodes are active and able to serve both reads and writes.

We’ll use CockroachDB as an example here, because systems capable of this are few and far between in the real world. In CockroachDB, all database nodes are active and can serve both reads and writes. The problem of consistency between active nodes is solved by the Raft consensus algorithm. In simplified terms, this allows transactions to be committed as long as a majority of nodes agree on them, which means that your database can remain operational even if a node (or depending on your configuration, multiple nodes, AZs, or even whole regions) goes down.
Importantly, the complexity of routing transactions to different nodes and ensuring consistency as nodes are added and removed is handled by the database software automatically. From the application developer’s perspective, CockroachDB can be mostly treated the same as a single-instance Postgres database.
The multi-active approach finally delivers on the true promise of a distributed database by allowing for easy horizontal scaling, high availability, and fault tolerance, all without having to sacrifice consistency. For this reason, multi-active systems using CockroachDB are found in the backend of applications such as DoorDash and Netflix, among many others.
The disadvantage of this approach is really just that implementing it yourself from scratch would be tremendously complex. Realistically, adopting a multi-active system means choosing or migrating to a database such as CockroachDB that was built from the ground up for this functionality. (However, CockroachDB is Postgres wire compatible, supports AWS DMS, and even offers an automated tool to facilitate converting schema from PostgreSQL, MySQL, Oracle, and Microsoft SQL Server databases for migration.)


