Motivation
At its foundation, CockroachDB depends on a key-value storage engine called Pebble. In CockroachDB v25.4, the storage team introduced value separation within Pebble: an optimization that improves compaction efficiency for many workloads. Value separation increases the throughput of the core of CockroachDB, the storage engine, by up to ~50%, depending on the workload, through algorithmic improvements. It reduces redundant I/O, reducing cost-to-serve at scale. We’ll look at how Pebble represents data today, what’s changed, and how that translates to database efficiency.
Background
The higher layers of CockroachDB write key-value (KV) pairs to Pebble, and the storage engine persists them durably while maintaining organization to efficiently service reads. Internally, Pebble implements a log-structured merge-tree (LSM): a data structure that organizes KV pairs into key-sorted runs. Asynchronous compactions continuously rewrite data in the background, sorting KVs to keep up with incoming writes.
During these compactions, a selection of input SSTables (SSTs) are read, merge-sorted by key, and written to new SSTs in sorted order. Compactions reduce the cost of reads by reducing the number of read I/O operations performed per logical read operation (called read amplification). But compactions come with tradeoffs. Namely, compactions consume CPU, read bandwidth, and substantial write bandwidth.
Workloads with large values (e.g. wide rows or JSONB documents) especially incur the overhead of compactions since these operations must read and rewrite substantial data. The sorting that compactions perform is a function of keys only; not values. Based on this observation, significant research (notably the WiscKey paper) has explored the concept of value separation, storing values out-of-band, physically separated from the corresponding keys, allowing compactions to sort keys without repeatedly rewriting values. This physical separation of keys and values provides additional flexibility in the tradeoff between read performance, space amplification, and write amplification.
In this blog post, we’ll examine the tradeoffs involved in value separation, the unique design of Pebble’s implementation, and the empirical benefits we’ve observed.
Impact
Cockroach Labs runs regular benchmarks of various workloads against nightly builds of CockroachDB to track the performance of the database over time and catch regressions early. The below graph plots the throughput of a simple workload upserting key-value pairs with small keys (BIGINT primary key) and 4 KiB values. Value separation was enabled in this benchmark at the end of June, resulting in a ~47% increase in throughput on the same hardware.
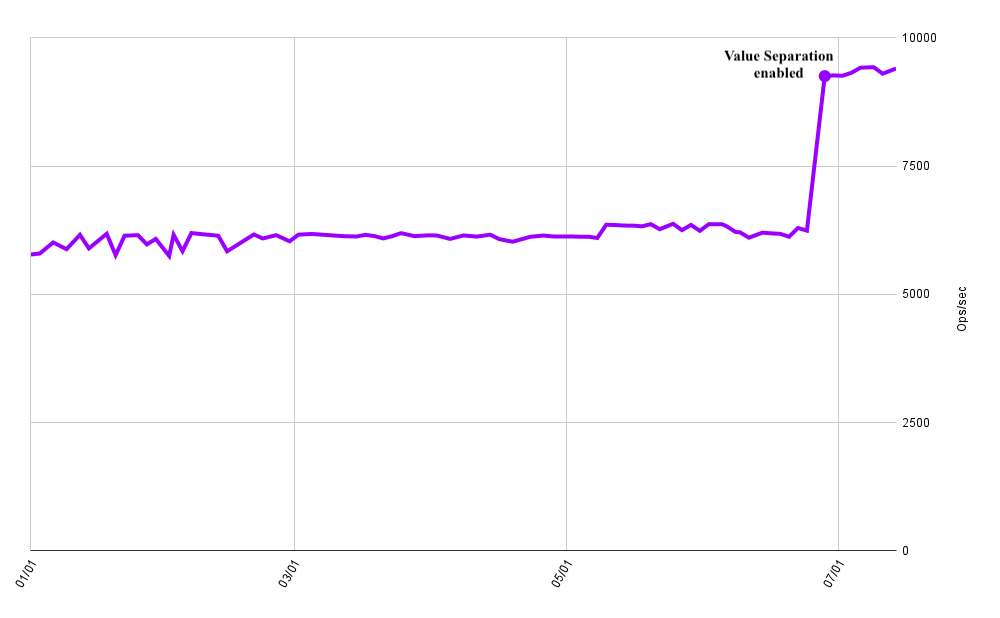
Image Caption: kv0/values=4096 benchmark throughput over time (2025)
This benchmark demonstrates this feature’s significant impact on efficiency and cost-to-serve. Workloads with smaller values see less pronounced impact. Various heuristics determine which values are physically separated and allow even small-valued workloads to benefit.
Prior art
Value separation is a frequently examined topic in log-structured merge tree storage systems. Projects like WiscKey (Lu et al., FAST 2016) and LavaStore (Wang et al., VLDB 2024) demonstrated that significant reductions in write amplification are possible through storing values out-of-band. However, separation of values comes with its own tradeoffs, and none of these published implementations were appropriate for CockroachDB’s workloads.
Pebble sits at the core of CockroachDB’s storage layer where correctness, performance, and a reasonable cost-to-serve all have to coexist. Much of the complexity in external value separation lies within the heuristics of when to compact values to ensure reads remain performant, space amplification is minimal, while still realizing the write-amplification advantages.
Mechanics
Pebble’s implementation of value separation introduces a new type of file to the storage engine called a blob file. A blob file stores values that have been separated, independent from the corresponding key. Physically, a blob file consists of a series of value blocks, containing values, an index describing where the value blocks begin and end, and a footer of metadata.
Both index blocks and value blocks are encoded in Pebble’s columnar-block format (similar to PAX) allowing constant time lookup of a block by its block ID and a value by its value ID. When a key’s value is separated into a blob file, the SSTable KV encodes a concise value handle:
// Handle describes the location of a value stored within a blob file.
type Handle struct {
BlobFileID base.BlobFileID
ValueLen uint32
// BlockID identifies the block within the blob file containing the value.
BlockID BlockID
// ValueID identifies the value within the block identified by BlockID.
ValueID BlockValueID
}A value handle compactly describes where a reader should look to find the value. When a compaction encounters a separated value, most of the time it simply copies the value handle as-is to the new output SSTable. For large values, the value handle is orders of magnitude smaller than the value itself, and compactions that copy just the handle conserve read and write bandwidth.
When a reader needs to access a value, it uses the handle to load the identified file, block and finally value. This indirection introduces additional read I/O, so separating a value is a tradeoff. Infrequently retrieved values or large values are better candidates for separation. Iterators cache blob files and their blocks over the lifetime of an iterator to avoid duplicate lookups.
Tradeoffs
Locality
When CockroachDB rewrites blob files during flushes or compactions, the process initially establishes a simple relationship: each new blob file corresponds directly to a single output SSTable. However over time, as the LSM evolves through subsequent compactions, these once clean one-to-one relationships begin to fragment. A side effect of this is that the values referenced by SSTs become increasingly scattered across more and more blob files. This loss of locality slows scans, as caching of recently accessed blob file blocks becomes less effective.
In order to mitigate this effect, pebble maintains a per-SSTable property called the blob reference depth. The reference depth is the maximum number of blob files in the working set of a scan across an SST. For example an SST in which keys within the range [a,f) reference one blob file and keys within the range [f,z) reference a distinct blob file has a reference depth of 1. When a compaction’s output SSTables would have a large blob reference depth due to the increasing interleaving of blob file references, Pebble instead writes new blob files. Writing new blob files copies the referenced values to new files and results in output SSTs with a reference depth of 1 again. Bounding the reference depth bounds the overhead incurred by reads.
Space Amplification
The increasing fragmentation of references to blob files has another negative effect: space amplification. Compactions may eliminate keys that reference blob values. This occurs when a key is overwritten by a newer version or deleted by a tombstone. Additionally, when the reference depth heuristic triggers a compaction to write new blob files, the compaction eliminates references to many values in blob files at once. Over time, these effects accumulate. Each blob file increasingly consists of a mix of live data: values still referenced by SSTables in the current LSM version and dead data: values that have been logically deleted or superseded.
This gradual divergence between total blob file size and the volume of live data stored within it leads to blob file space amplification. Managing and mitigating this amplification efficiently is key to keeping storage utilization under control and maintaining predictable performance at scale. Notably, in workloads with high value homogeneity, this amplification is less pronounced because the resulting blob files and SSTables tend to compress more effectively.
Blob File Rewrites
To keep blob file space amplification in check, Pebble introduces a new compaction type: blob file rewrite compactions. Over time, as keys are overwritten or deleted, blob files accumulate a mix of live and dead values. These rewrite compactions reclaim that space by copying only still-referenced values into new blob files.
Each SSTable that points to external blob values carries a small blob-reference index block containing a run-length encoded bitmap per referenced blob file recording which values within a blob file are still live:
When Pebble’s heuristics decide to rewrite a blob file, Pebble collects all the SSTs that reference that file and unions their bitmaps together, OR-ing them into a single view of which values remain in use. Values not referenced by any SSTable are dropped during the rewrite.
Blob file rewrite compactions move and reorganize values that still have outstanding references, but they do not rewrite the referencing SSTables. Doing so would be expensive and reduce the write-bandwidth savings of value separation. Instead, Pebble’s value handles are designed to continue to identify the correct value across blob file rewrites through additional indirection:
The handle’s
BlobFileIDis a stable identifier for a logical blob file. The LSM maintains a mapping fromBlobFileIDto a physical blob file.The handle’s
BlockIDis an index into the original blob file’s value blocks. A blob file that is produced by a blob-file rewrite compaction includes a special column within the index block remapping the original blob file’sBlockIDto the index of the physical block in the rewritten blob file.The handle’s
ValueIDis an index into the original blob file’s value block. In order for the value index to remain correct within the rewritten blob file, we cannot remove values altogether, but we can replace them with empty values (effectively storing a single offset , typically 2 bytes per absent value). As an additional optimization, when re-mapping the aboveBlockID, we also include a value ID offset allowing us to avoid storing empty values for the first n empty values within the block.
Blob file rewrites allow Pebble to reclaim disk space storing garbage. They prevent unreferenced data from lingering indefinitely, keeping space amplification low while preserving the performance and efficiency benefits of separating values from keys.
CockroachDB separation heuristics
Workloads with large values reliably benefit from value separation and by default CockroachDB in v25.4+ will separate values 256 bytes and larger automatically. CockroachDB can realize benefits more broadly too. Some regions of the storage engine’s keyspace are rarely read and more latency tolerant (for example, the Raft log which is typically held in-memory until fully replicated). CockroachDB stores these values out-of-band too, even if they’re smaller than 256 bytes, thereby avoiding pulling them into compactions unnecessarily, reducing write amplification without affecting read-path latency where it matters.
CockroachDB uses multi-version concurrency control (MVCC) to negotiate concurrent transaction commits. MVCC preserves obsolete versions of rows for transaction isolation and powering AS OF SYSTEM TIME (AOST) queries. In practice, most queries execute at current timestamps and only read the most recent version of a row. CockroachDB eagerly separates the values corresponding to MVCC garbage, improving the locality for reads at recent timestamps and reducing the impact of compactions through value separation. However, some nuances higher in the system currently prevent CockroachDB from fully realizing this benefit.
Notably, CockroachDB's SQL optimizer issues a significant number of AS OF SYSTEM TIME queries to maintain accurate statistics, and these queries intentionally scan across MVCC history. As a result, these scans and their retrievals of separated values can dominate read bandwidth, offsetting much of the theoretical benefit of separating historical values. Balancing these competing behaviors – reducing unnecessary I/O while still supporting efficient AOST scans – will guide future work.
The concept of blob files could also allow us to explore the idea of enabling the automatic and cost-effective placement of data onto appropriate storage tiers. Less frequently accessed data could be moved to inexpensive storage tiers by classifying it based on data age, while maintaining frequently accessed data on fast, expensive storage.