

We’ve been planning a visit to Orange County, California, where I grew up, over the upcoming holidays. My favorite Mexican restaurant is there, in Placentia: Q-Tortas! I have frequent cravings for their carnitas burrito, so a visit there is obligatory (I promise this blog is about search).
The reason I mention the restaurant is because I’ve misspelled the name. Just now, looking it up, I see it’s actually called Q Tortas, without the hyphen. If I was building an app that incorporates the ability to find restaurants, I would have to factor in the harsh reality that users aren’t going to spell everything correctly. This reality, coupled with the availability of trigram-based indexes in CockroachDB 22.2(and my burrito craving), has me pondering some text search use cases which benefit from trigram indexes. Here are some use cases that immediately come to mind:
Looking for something which may or may not be hyphenated, as in my example here.
Transliterated names of people, places, etc.
Users make typos, either the users of the app or even those entering the data the app relies on.
Spelling variations, such as in names; e.g. “Megan”, “Meaghan”, “Meagan”.
*Full disclosure: I am a bit of a text search fanatic. In the past I’ve written about doing full text search with CockroachDB and Elastic. Before that I wrote about doing text indexing and search in CockroachDB 20.2 using GIN indexes. The support for trigram indexes is a huge improvement on what we had available at the time of those experiments.
Before you dive into my trigram indexes tutorial below you may want to watch this quick video tutorial built by my colleague Dikshant Adhikari:
Wait, what’s a trigram?
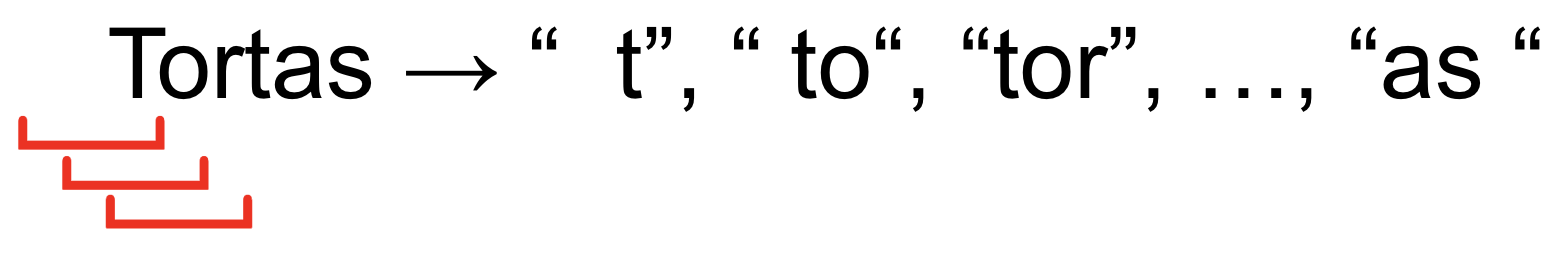
Imagine a sliding window, 3 characters wide, which is advanced across a word, 1 character at a time, yielding a three-character sequence at each position – this is a trigram. If I use one of the new built-in functions to extract the trigrams from this string value, here’s what I get:
defaultdb=> SELECT show_trgm('Q-Tortas');
show_trgm
-------------------------------------------------
{" q"," t"," q "," to","as ",ort,rta,tas,tor}
(1 row)Some observations: (1) the string has been converted to lowercase, (2) the hyphen has been replaced by a space, with the result that the string is considered to be two separate words. This yields the advantage of making the matching process case-insensitive and unaffected by punctuation so, in my case, misspelling this name by adding the hyphen is forgiven and I still find a match.
Worth mentioning is that, for a string of length N, the size of the resulting trigrams is 3*(*N*+1), so this wouldn’t be an ideal fit as an approach to full-text indexing. Also, for larger texts, this approach doesn’t perform very well at all, since the precision of the search approaches zero as the text length increases. The trigram approach does, however, perform very well for shorter text fields like the* name* column in the table used in the example below.
Steps for using trigram indexes to “fuzzy match”
In addition to that trigram generator, it seems like we need:
a way to index these generated trigrams so we can efficiently look up matching rows;
a set of operators which expose this capability within SQL queries;
some sense of ranking, so the best match occurs first in the list of results.
Trigram indexes tutorial
Since the inspiration for this is a Mexican restaurant in Orange County, the starting point is a small data set containing details on local restaurants (here is a copy of the data). Before going further, I should point out that all of this is being done using a single-node CockroachDB running on my MacBook Pro. CockroachDB can be found here, and the command I used to start it up is:
$ cockroach start-single-node --insecure --listen-addr=localhost:26257 --http-addr=localhost:8080 --background
Based on the structure of the data, this table seems appropriate:
CREATE TABLE restaurant
(
id UUID NOT NULL PRIMARY KEY DEFAULT gen_random_uuid()
, name TEXT
, address TEXT
, phone TEXT
, url TEXT
, stars VARCHAR(5)
, description TEXT
);Then we need the trigram index on the name column since that’s a central feature of this exercise:
CREATE INDEX restaurant_trgm_idx ON restaurant USING
GIST (name gist_trgm_ops);
Our next step is to load that pipe-separated data set into the table. Out of habit, I tend to use the psql CLI for a lot of my work, so that’s what’s shown below:
$ psql "postgres://root@localhost:26257/defaultdb" -c "COPY restaurant (name, address, phone, url, stars, description)
> FROM STDIN
> WITH DELIMITER '|' NULL E'';" < ./oc_restaurants.psv
Timing is on.
COPY 70
Time: 83.443 msLet’s have a quick look at the data:
defaultdb=> SELECT name, address, phone, url, stars FROM restaurant ORDER BY RANDOM() LIMIT 3;
name | address | phone | url | stars
------------------+---------------------------------------+--------------+---------------------------------+-------
Vaca | 695 Town Center Drive, Costa Mesa | 714-463-6060 | http://vacarestaurant.com/ | ★★★
Paradise Dynasty | 3333 Bristol St., Costa Mesa | 714-617-4630 | http://paradisegp.com/usa | ★★
Haven | 190 S. Glassell St., Orange | 714-221-0680 | http://havencraftkitchen.com/ | ★★
(3 rows)
Time: 3.653
ms
Since we have a mere 70 rows of real data, we’ll generate another 100k rows so we’ll be able to illustrate the effect of the trigram index:
defaultdb=> INSERT INTO restaurant (name, address, phone, url, stars, description)
SELECT SUBSTR(MD5(RANDOM()::TEXT), 0, 12), SUBSTR(MD5(RANDOM()::TEXT), 0, 32),
SUBSTR(MD5(RANDOM()::TEXT), 0, 12), SUBSTR(MD5(RANDOM()::TEXT), 0, 27),
SUBSTR(MD5(RANDOM()::TEXT), 0, 3), SUBSTR(MD5(RANDOM()::TEXT), 0, 32)
FROM GENERATE_SERIES(1, 1.0E+05);
INSERT 0 100000
Time: 41101.097 ms (00:41.101
)
So that the results of a query are returned in order of similarity, we can use the built-in ranking function:
defaultdb=> SELECT similarity('Q Torta', 'Q-Tortas');
similarity
------------
0.7
(1 row)Based on the two differences in these strings, the space vs. the hyphen and the missing ’s' on the end, we get a score of 0.7. The similarity computation is done like this: we count the number of shared trigrams in the strings, and divide by the number of non-shared trigrams. If I attempt to do this in SQL, it’s not pretty, but I can derive the same value:
defaultdb=> WITH b AS
(
WITH a AS (
SELECT UNNEST(SHOW_TRGM('Q Torta')) tg UNION ALL SELECT UNNEST(SHOW_TRGM('Q-Tortas')) tg
)
SELECT tg, COUNT(*) n
FROM a
GROUP BY tg
)
SELECT REGEXP_REPLACE(
((SELECT COUNT(*) FROM b WHERE n = 2)/((SELECT SUM(n) FROM b) - (SELECT COUNT(*) FROM b WHERE n = 2)))::TEXT,
E'0+$', E''
) similarity;
similarity
------------
0.7
(1 row
)
Ok. Now that we have a table with data, the trigram index, and an approach to scoring the results, let’s have a go at the query:
defaultdb=> \set name '''Q Torta'''
defaultdb=> SELECT name, address, phone, url, stars, SIMILARITY(:name, name)::NUMERIC(4, 3) sim
FROM restaurant
WHERE :name % name
ORDER BY sim DESC
LIMIT 5;
name | address | phone | url | stars | sim
----------+-------------------------------+--------------+---------------------------------------------------------+-------+-------
Q-Tortas | 220 S Bradford Ave, Placentia | 714-993-3270 | https://www.facebook.com/profile.php?id=100070084074668 | ★★★ | 0.700
(1 row)
Time: 3.028
ms
We got one result, with the expected similarity value of 0.7, and it took about 3 ms. Note the use of the % operator there. That’s the handy “fuzzy search” operator which is accelerated by the trigram index. Let’s view the query plan to see how it was executed:
defaultdb=> EXPLAIN SELECT name, address, phone, url, stars, SIMILARITY(:name, name)::NUMERIC(4, 3) sim
FROM restaurant
WHERE :name % name
ORDER BY sim DESC
LIMIT 5;
info
-----------------------------------------------------------------------------------------------
distribution: local
vectorized: true
• top-k
│ estimated row count: 5
│ order: -sim
│ k: 5
│
└── • render
│
└── • filter
│ estimated row count: 3,723
│ filter: 'Q Torta' % name
│
└── • index join
│ estimated row count: 0
│ table: restaurant@restaurant_pkey
│
└── • inverted filter
│ estimated row count: 0
│ inverted column: name_inverted_key
│ num spans: 8
│
└── • scan
estimated row count: 0 (<0.01% of the table; stats collected 1 day ago)
table: restaurant@restaurant_trgm_idx
spans: 8 spans
(27 rows
)
Sure enough, the query ran efficiently by scanning only the trigram index! That’s ideal. Let’s make use of a new feature of CockroachDB which allows us to toggle the “visibility” of an index, and then re-run this query and its explain plan:
defaultdb=> ALTER INDEX restaurant_trgm_idx NOT VISIBLE;
ALTER INDEX
Time: 476.591 ms
defaultdb=> SELECT name, address, phone, url, stars, SIMILARITY(:name, name)::NUMERIC(4, 3) sim
FROM restaurant
WHERE :name % name
ORDER BY sim DESC
LIMIT 5;
name | address | phone | url | stars | sim
----------+-------------------------------+--------------+---------------------------------------------------------+-------+-------
Q-Tortas | 220 S Bradford Ave, Placentia | 714-993-3270 | https://www.facebook.com/profile.php?id=100070084074668 | ★★★ | 0.700
(1 row)
Time: 561.168 ms
defaultdb=> explain SELECT name, address, phone, url, stars, SIMILARITY(:name, name)::NUMERIC(4, 3) sim
FROM restaurant
WHERE :name % name
ORDER BY sim DESC
LIMIT 5;
info
-----------------------------------------------------------------------------------------------
distribution: local
vectorized: true
• top-k
│ estimated row count: 5
│ order: -sim
│ k: 5
│
└── • render
│
└── • filter
│ estimated row count: 33,357
│ filter: 'Q Torta' % name
│
└── • scan
estimated row count: 100,070 (100% of the table; stats collected 6 minutes ago)
table: restaurant@restaurant_pkey
spans: FULL SCAN
(18 rows
)
This time the query required a full table scan, resulting in a run time of 561 ms so, for this data set of 10700 rows, the speedup due to the trigram index was about 180x. Better not forget to restore the visibility of that index:
defaultdb=> ALTER INDEX restaurant_trgm_idx VISIBLE;
ALTER INDEX
Time: 439.067 msSome final trigram thoughts
As usual with CockroachDB, each release incorporates new features requested by members of the rapidly growing community of users. This trigram capability is another step in making CockroachDB an easier migration destination for Postgres users and I expect it will be welcomed by developers of apps across a broad spectrum of use cases, from hotel front desks to product catalogs. The other novel feature shown here, index visibility, is very handy when doing performance tuning. Please give these new features a try when you get a chance. If you want to learn more about the new capabilities in CockroachDB check out the 22.2 launch page.
Finally, thank you for taking the time to follow along!
References
QA plan for trigrams in CockroachDB
PostgreSQL pg_trgm documentation
Trigram similarity computation in CockroachDB
Notes
To preserve compatibility with Postgres, CockroachDB accepts the following command (but, within CockroachDB, it’s a no-op):
defaultdb=> CREATE EXTENSION pg_trgm;
CREATE EXTENSION
Time: 0.894
ms


