

What is a database hotspot?
In a distributed database, a hotspot is an overworked node – in other words, a part of the database that’s processing a greater share of the total workload than it is meant to handle.
If left unchecked, database hotspots can lead to degraded application performance and even outages, so it’s important to understand what they are, what causes them, and how to detect and avoid them.
A quick visual will help illustrate how hotspots happen. Here, we have a basic three-node system, where the application distributes queries evenly between the three nodes:

But what if for some reason (we’ll get into the causes of hotspots in a moment) those queries aren’t distributed evenly, and most of them are instead routed to just one of the three available nodes?

Here, we have a hotspot. The overworked, red node is being asked to handle most of the workload, and this unexpected stress may lead to errors and processing delays that can impact the user experience of the application.
What causes database hotspots?
Quite a few different things can cause database hotspots, and they’re not necessarily the result of poor system design. In fact, you’re likely to encounter hotspots every now and then in any distributed database system, which is why being able to quickly identify them with monitoring tools is important.
Some of the common causes of database hotspots include:
Failure to follow best practices for your DBMS
Poorly-optimized SQL queries
Poorly-optimized routing layer
Unexpected application usage patterns and traffic spikes
Workload-specific edge cases
Hotspots can also sometimes occur just due to the realities of the DBMS you’ve chosen. Some “distributed” databases, for example, can still only serve writes on a single node, meaning that any write-heavy workload spike is likely to create a hotspot on that node.
How to avoid database hotspots
As we might expect given the variety of potential causes, it is difficult to entirely avoid database hotspots – that’s why being able to identify them accurately is so important.
However, we can eliminate some potential causes of hotspots fairly easily:
Choose the right DBMS: To avoid hotspots, ideally you’ll want a distributed database that can handle reads and writes on every node, and a database with a built-in intelligent query routing layer that’s already production-ready, so that you don’t have built, test, and maintain your own bespoke routing layer. CockroachDB is one example of a distributed SQL database that has these features.
Follow best practices. For example, in CockroachDB it’s a best practice to avoid sequential primary keys, due to the way the database distributes data behind the scenes. Multi-column primary keys and UUIDs are both better options and will reduce the chances of hotspots. While different DBMS have different recommendations, most of them will have guidelines like this that will help you avoid creating hotspots accidentally.
Most of the other causes are harder to anticipate and avoid, though. For example, it is likely that at some point in the lifespan of a production application, someone will write a suboptimal query. It is also likely that at some point you’ll encounter some kind of unexpected usage spike, or an unusual edge case you didn’t anticipate when designing the system.
This is why it’s critical that in addition to choosing the right tools and following best practices, you’ll also need a good way to identify and diagnose hotspots.
How to identify database hotspots
How you identify hotspots will vary depending on the DBMS you’ve chosen and how easy it is for you to access and monitor telemetry metrics such as the number of queries per second being processed in a particular range of data.
We can’t speak for all of the database management systems out there, but CockroachDB provides a robust set of tools designed to help our customers quickly identify and diagnose hotspots so that the problems can be fixed.
For example, the CockroachDB console includes a Hot Ranges page that provides information on specific data ranges that are receiving a high number of reads or writes (in other words, hotspots.) This data is also available via API, to facilitate automated monitoring of all of your clusters.
CockroachDB also now provides a customizable Key Visualizer to help drill down even further into what’s causing hotspots and other performance problems:

Once you’ve identified a problem, CockroachDB’s console also includes robust tools for diagnosing the cause, allowing you to dig into the specifics of individual SQL statements and transactions to find (for example) poorly-optimized queries that might be doing something like running a full table scan.
Other DMBS will have different tools, and there are also third-party monitoring and management tools that can help with identifying and diagnosing the cause of hotspots.
Hotspots happen: real-world examples in streaming video
What do hotspots look like in the real world? Here’s a look at hotspots in the realm of streaming video, where content virality can lead to a lot of pressure getting put onto specific elements of the application architecture. This is sometimes called “the hot content problem.” Let’s take a closer look:
Video streaming application architecture reference
For reference, here’s a basic architecture of the sort that might be used by a major video streaming service:
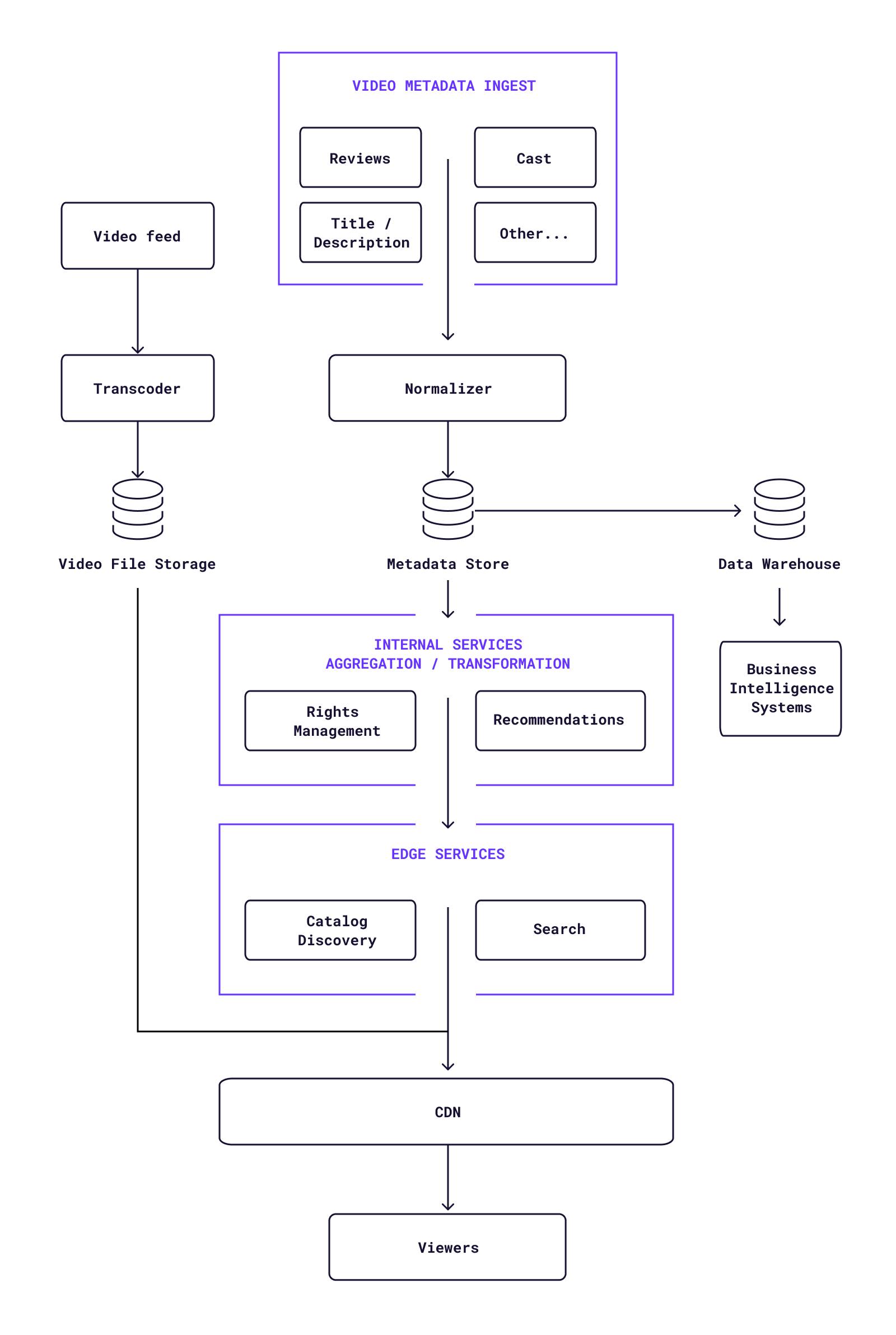
Looking at the above architecture, it’s clear that a lot relies on the metadata store at the center of the diagram. Among other things, that metadata is used to determine whether or not a viewer has access to a particular piece of content, so bugs or mistakes can mean subscribers don’t get access to the content they’re paying for.
The hot content problem
For a media streaming company, having a piece of content such as a new show go viral presents a massive business opportunity. But having hot content also presents an engineering challenge as your services are bombarded with requests for the same content. For example, caching systems are likely required to ensure that the metadata store itself isn’t overrun. But that introduces the potential for bugs related to outdated caches serving users the wrong content or no content at all.
RELATED
The history of databases at Netflix and how they use CockroachDB
One of the unseen challenges here is that what looks like a single piece of content on the front end can be quite a bit more complex in the back end. A single episode of television, for example, may have different versions and thus different metadata for different geographical regions. Users may need to be served slightly different versions of the content and its metadata depending on their subscription tier and other account settings. And users in different locations may need to be served different ads (based on their location or based on the user themselves) that must be interspersed throughout the content and timed perfectly to avoid interrupting it.
So when you’ve got a piece of hot content, you need to be aware of both:
How your system can handle the total volume, i.e. large numbers of people requesting the same content at the same time, and…
How your system handles the complexities of serving the right content and metadata versions to each user, and whether any of those systems could be compromised when the system comes under heavy load.
Building a layered caching system can help solve the problem #1, but then each layer of cache needs to be kept in close sync with your source of truth database or you’re likely to encounter issues related to problem #2. This can be particularly challenging when dealing with popular live-streamed events like breaking news, live sports, or popular streaming television and movie premieres, where even a brief moment of misalignment between the cache layers can lead to viewers missing some of the content they’re paying for.
Even when things go right, dealing with problem #2 can also involve a lot of manual work. For example, it may be necessary to build message queuing systems to communicate changes from the source-of-truth metadata store to the various caching layers. And best practices haven’t been followed, database hotspots can emerge and slow the whole system down.
A database that likes it hot
There’s no database on earth that can make operating a global-scale media streaming company easy. Choosing the right database can make a lot of the challenges associated with database hotspots and the hot content problem a bit easier.
CockroachDB is a next-generation distributed SQL database that combines the easy scalability of databases like Cassandra with the ironclad ACID guarantees of a relational database. It can be scaled infinitely (horizontally and geographically) without requiring any modification of your application, because it can always be treated as a single logical database.
And it can serve reads and writes from every node. That means that even if hot content catches you by surprise, the database can be scaled up to meet that demand instantly and it’ll distribute queries evenly between nodes, with no need to make any adjustments to your application logic.


