


Before AI workloads entered production en masse, infrastructural resilience was already key to mission-critical applications. But in 2026, resilience alone won’t be enough. The real challenge, one that’s already reshaping engineering priorities and strategic business initiatives is resilience at scale.
Not the kind of scalability that you can forecast, but unprecedented, agentic scale. This past year, two major shifts defined the tech landscape: AI moved into production across industries, and mass failures surged. These weren’t unrelated trends.
Our new report, The State of AI Infrastructure 2026: Can Systems Withstand AI Scale?, offers a global snapshot of how engineering leaders are navigating this tension. Based on a survey of 1,125 senior cloud, infrastructure, and engineering executives, the findings are clear: AI workloads are growing faster than most systems can handle, and infrastructural failure is coming sooner than you think.
AI demand is up. Infrastructure isn’t ready.
The report reveals that AI workloads are accelerating faster than enterprise infrastructure can support, and there will be an urgent resilience crisis across global enterprises soon. Every company surveyed expects AI workloads to increase in the next year. Nearly two-thirds anticipate more than 20% growth.
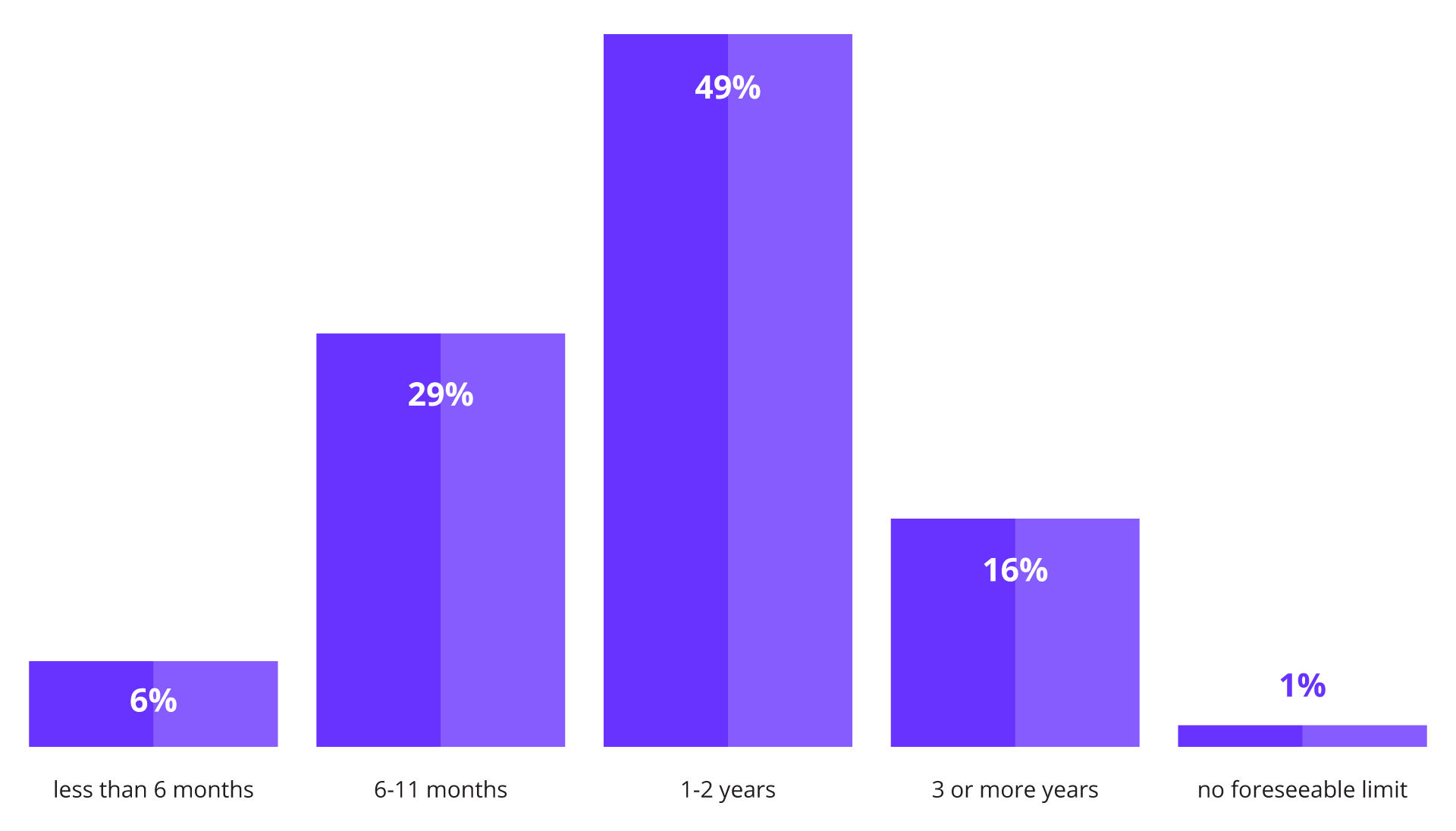
Image Caption: Response distribution to the question, "When do you expect your company's data infrastructure will hit its limit for supporting AI growth without major upgrades?"
What’s more, with this scale, today’s infrastructure lacks the necessary resilience and is cracking under the pressure:
34% of organizations believe their current infrastructure will fail under AI load within a year.
83% expect failure in less than 2 years.
Nearly one-third of respondents identified the database as the most likely point of failure, right after cloud infrastructure.
These aren’t hypothetical risks. They’re imminent challenges.
Agentic AI is changing the rules of scale, and architecture must keep up
Agentic AI introduces autonomous, persistent, machine-driven activity. Agents interacting with APIs, services, tools, and each other form recursive loops of continuous demand that never sleep, throttle, or pause for coffee. The result is a new kind of operational pressure: continuous, compounding load that exposes legacy backend assumptions almost instantly.
Legacy infrastructure, built around episodic human interaction, simply wasn’t designed for this kind of pressure. To handle the pace and unpredictability of AI, companies need more than performance upgrades. They need a fundamental shift in how systems are architected.
Distributed SQL is uniquely equipped to meet the demands of agentic AI because it combines the scalability of cloud-native architectures with the transactional integrity enterprises rely on. As autonomous agents drive continuous, machine-generated workloads across regions and systems, traditional databases struggle to coordinate at scale without introducing latency, inconsistency, or failure points. Distributed SQL changes that.
By distributing data and compute across multiple nodes—with strong consistency, built-in fault tolerance, and seamless horizontal scale—it ensures that even under relentless, concurrent AI activity, systems remain resilient, performant, and compliant. In short: it’s the only database architecture built to survive the pace and pressure of AI-native scale.
Downtime costs are rising
Last year, we saw more and more outages being publicized, from Cloudflare’s back-to-back failures to AWS, Microsoft, and Azure. The problem isn’t just that there seem to be more outages, but that agentic AI is also scaling the cost of downtime.
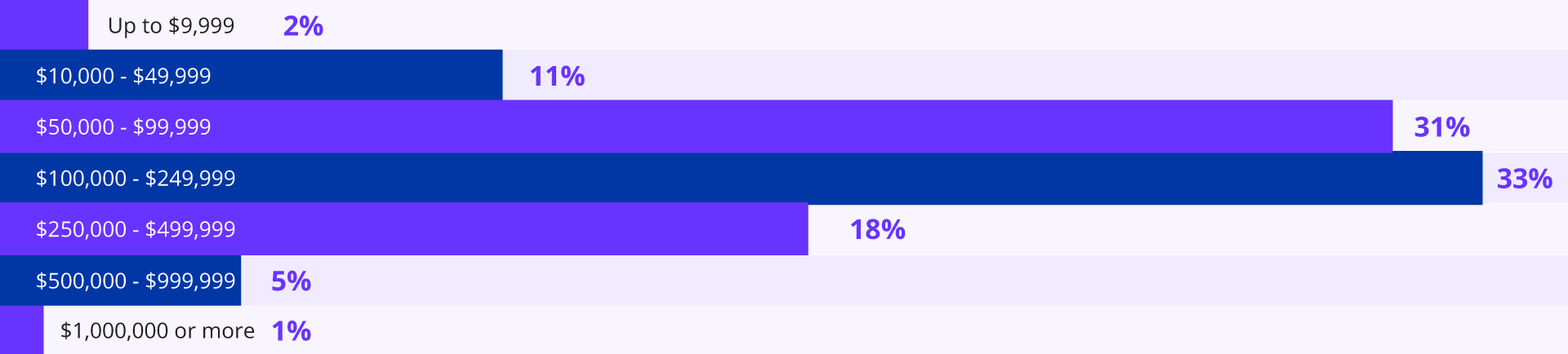
Image Caption: Response distribution to the question, "Roughly how much would one hour of AI-related downtime cost your organization?"
98% of respondents estimate that just one hour of AI-related downtime would cost at least $10,000. For two-thirds of companies, that number exceeds $100,000. Among enterprises with over 1,000 employees or $500M in annual revenue, 66% project downtime costs exceeding $100,000 per hour.
These are just the financial losses, not to mention the potential customer churn, and reputational damage that’s harder and harder to repair.
The majority of respondents are preparing accordingly. Nearly every company surveyed is investing in scaling and strengthening the systems that support AI, with the database layer getting special focus.
This shift isn’t about preparing for rare worst-case scenarios. It’s about surviving everyday operations and success.
What’s inside the report
The full report covers:
Which use cases are leading the rise in AI workloads
Where leaders believe systems will fail first if growth continues unchecked
Why downtime is no longer just a cost issue but a strategic risk
Why top teams should re-architect for scale and resilience with distributed systems
If 2025 brought AI to production, 2026 is the year resilience at scale becomes non-negotiable.


