
This post was originally published in 2018 by former CockroachDB engineer Matt Jibson, who owns goats and makes his own soap. It’s one of the most popular blogs we’ve ever published so we wanted to get it back up on the site for a new crop of blog readers.
What is sqlfmt?
sqlfmt is an online SQL formatter. It is pronounced sequel fumpt. Its purpose is to beautifully format SQL statements.
I built sqlfmt with my Cockroach Labs colleague Raphael “knz” Poss. In this post, I will describe how to use it and its features. In addition, I will argue for its need in light of the existing SQL formatters and describe its somewhat interesting implementation. But first, here’s a quick glimpse at what sqlfmt looks like:
Click here to try it for yourself
As we are dealing with code formatting here, there is much opinion, and this article will discuss mine. If you do not heartily ascribe to automated, opinionated (i.e., few or no options) choices in your code formatters, sqlfmt is not for you. sqlfmt is for those who think it is better to have no choice in the SQL formatting than it is to format it by hand.
Why format your SQL with sqlfmt?
A search for sql formatter uncovers lots of online and offline formatters. I tested six of the formatters from the first page of results with the query SELECT 1, 2, and all six of them formatted it onto two or three lines. While I understand why they do that, I was not satisfied with using them to automatically format my SQL. I wanted something that I could hook up to my text editor on save and it would always produce beautiful results. I believe that using available space is a requirement for that.
Those other formatters undoubtedly use a simpler algorithm for their formatting. This is fine and I’m happy they exist and have provided value. It makes sense that they have easy rules like “each term on its own line”.
However, I’ve recently been spoiled in my JavaScript (well, JSX) editing with prettier. It has been a complete game changer for me in terms of how I write fancy JS. As my code gets more complicated or more nested, I just love that it slowly adds newlines to break up functional hierarchy into visual blocks. I wanted a SQL formatter that acted in the same way. Not just something that puts new lines between all terms, but one that adapts to the functional depth of the statement by grouping blocks together.
Features of sqlfmt
sqlfmt’s goal is to beautifully format SQL statements. A beautifully formatted SQL statement is one in which the operation of the statement is understandable visually. It was designed to:
Understand all CockroachDB (mostly anything Postgres) syntax.
Attempt to use available horizontal space in the best way possible.
Always maintain visual alignment regardless of your editor configuration to use spaces or tabs at any tab width.
To demonstrate, let’s take, for example, a query SELECT a FROM t. Here are some possible renderings of this query:
SELECT a FROM t
SELECT a
FROM t
SELECT
a
FROM
t
Which one is the most understandable visually? For me, it is the first. This statement contains a mere four words that are instantly parseable by the mind. For me, the second and third renderings detract by using whitespace needlessly. Let us assume we had some 80 characters of width in which to work (an archaic, standard, if not small, editor size). The four lines used by the third rendering have wasted a maximum amount of screen space for zero additional benefit in terms of visual understanding. This feels like YAGNI applied to text formatting. Why use four lines when one will do?
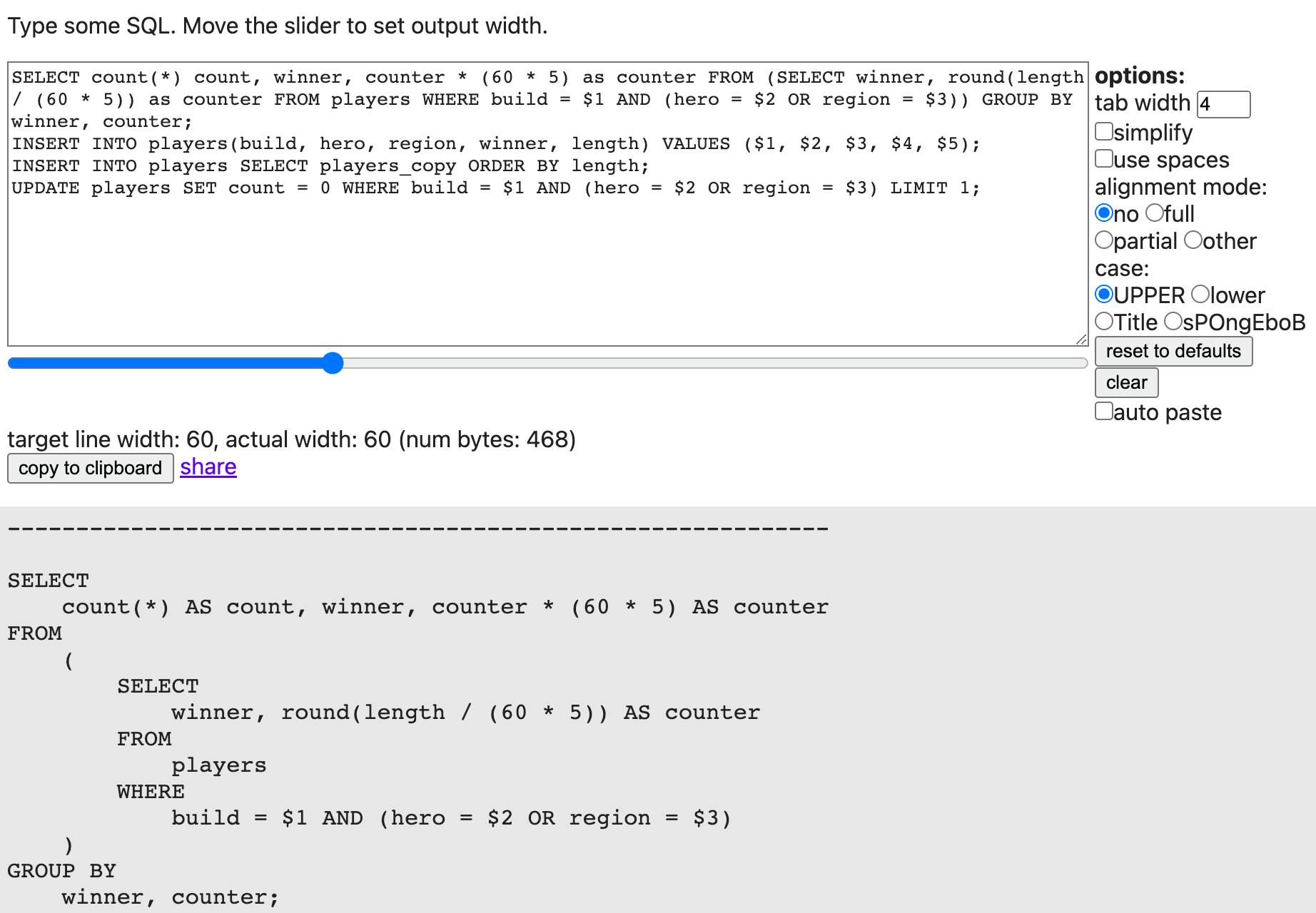
But let us now slowly increase the complexity of our query. What if we named many columns in it, many tables in the FROM, added filters and sorts, with subqueries and joins of varying depth? As a query gains complexity, it deserves more space. Indeed what we would like is for the query to use more lines of space and highlight subqueries and other blocks by clearly indenting them. Let’s take the first demonstration query from the website at a target width of 50:
SELECT
count(*) AS count,
winner,
counter * 60 * 5 AS counter
FROM
(
SELECT
winner,
round(length / (60 * 5)) AS counter
FROM
players
WHERE
build = $1
AND (hero = $2 OR region = $3)
)
GROUP BY
winner, counter
What is clear about this query? Immediately we see that we are getting back three result columns, as they are written each on their own line. We compare that to the two GROUP BY columns. Those are not written on their own line, nor need they be, since it’s just two words. In each case we maintain a high degree of visual understanding based on the available versus needed space. Continuing, the subselect in the FROM is clearly the only data source, and its inner query is clear to read. The WHERE clause nicely shows how its boolean operators will be processed.
Try this yourself. Start with a tiny query like SELECT a and slowly add and watch the output change and adapt as more complexity is added. Adjust the slider to see what things look like at different available widths. (Is there any other online SQL formatter that is as pleasant to use?)
How to use sqlfmt and SQL formatting options
sqlfmt is useable from its website at sqlfum.pt. There is a box in which to paste or type SQL statements. Multiple statements are supported by separating them with a semicolon (;). The slider below the box controls the desired maximum line width in characters. Various options on the side control tab/indentation width, the use of spaces or tabs, simplification, and alignment modes. Simplification causes the formatter to remove unneeded parentheses and words when the meaning will be the same without them.
There are four alignment modes.
The default, no, uses left alignment.
SELECT
a
FROM
t
WHERE
c
AND b
OR d
partial right aligns keywords at the width of the longest keyword at the beginning of all lines immediately below.
SELECT a
FROM t
WHERE c
AND b
OR d
full is the same as partial but the keywords AND and OR are de-indented, in a style similar to the sqlite tests.
SELECT a
FROM t
WHERE c
AND b
OR d
other is like partial but instead of de-indenting AND and OR, their arguments are instead indented.
SELECT a
FROM t
WHERE c
AND b
OR d
In addition to the website, the CockroachDB client has a new sqlfmt subcommand that can be used on your local computer. This can be made into a macro for whatever editor you are using. Run cockroach sqlfmt --help or check out this docs page to learn how it can be used.
How we built it: Haskell implementation converted into Go equivalent
sqlfmt is based on a paper that describes an algorithm to efficiently layout documents with multiple possible layouts. It includes a working implementation in Haskell, a functional language with a deep type system. The algorithm is a fairly small amount of code and is easy to understand. The most difficult part of it is the parsing (converting the original text file into an in-memory data structure), and then converting the parsed representation into one that describes the possible document outputs (this means things like “could be either a space or a newline here, whichever fits”).
Since sqlfmt needed to parse SQL (CockroachDB SQL, which is very similar to PostgeSQL, specifically), I thought it would be easier to use a language with an existing parser and port the pretty printing algorithm to it than porting the SQL parser to Haskell. The CockroachDB SQL parser is written in Go, so the algorithm had to be written in Go.
Haskell and Go are not related very much at all. They approach many concepts differently and have unique sets of optimized features. For example, Haskell is lazy-evaluated (things are evaluated only when needed and the result is cached). The algorithm took advantage of many of these features in Haskell in its implementation, and these needed to be converted into a Go equivalent.
For example, let’s look at how lazy evaluation with a cached result is done, using the iDoc method. It takes a few comparable parameters that can be used as a key in a Go map. If that key exists, its result is returned (which is safe because we guarantee that the same inputs always result in the same outputs). Otherwise a new instance is created. This allows for very fast recomputation of results during the algorithm that is trying to choose the best line layout based on many possible placements for a newline.
After the initial port was complete, a significant amount of additional work was done to add new features to the underlying algorithm. The paper describes how to beautify a document based on a few operators. These are things like a line of text, a new line, indentation, and combinations of those. There are some guarantees that these operators must meet in order to be used, and proofs describing why they each of them are safe. We wanted to add some other functionality (for example the alignment modes) that required new operators. These had to be constructed in a way that still met the guarantees required by the beautification algorithm. We were able to borrow work from others and do some ourselves that allowed us to implement new formatting rules. There are still more of these we’d like to do, so we expect sqlfmt to improve over time.
Conclusion
sqlfmt is an opinionated SQL formatter. It’s not designed to be completely customizable, and we hope to remove options over time as we decide what works best. Use it and stop thinking about how to format SQL.
Does tinkering on distributed SQL engines put a spring in your step? Then good news — we’re hiring! Check out our open positions here.
(Also published on Matt Jibson’s blog.)


