
Editor's Note: This post was originally authored when CockroachDB was pre-1.0. CockroachDB's architecture has undergone many changes since then. One of the most significant, as it relates to this post which focuses on our previous "lockless" design, is that we now use more locking and lock-like structures to provide SERIALIZABLE isolation. For more current details about CockroachDB's transaction model, read our transaction layer architecture documentation.
---------------
Several months ago, I discussed how CockroachDB’s distributed transactions are executed atomically. However, that discussion was incomplete; it ignored the concept of concurrency, where multiple transactions are active on the same data set at the same time. CockroachDB, like all database systems, tries to allow as much concurrency as possible in order to maximize access to the data set.
Unfortunately, our atomicity guarantee is not sufficient to keep the database consistent in a world of concurrent transactions. Recall that guarantee:
For a group of database operations, either all of the operations are applied or none of them are applied.
What this does not address is the way that concurrent transactions may interleave. The individual operations (reads and writes) in a transaction do not happen simultaneously; there is time in between the individual operations. In a concurrent system, one transaction may commit during the execution window of a second transaction; even if the first transaction (T1) commits atomically, this can still allow operations later in the second transaction (T2) to see the results of T1, even though earlier operations on T2 did not see the results of T1. This interleaving can create a number of undesired anomalies, ultimately breaking the consistency of the database.
To protect against these anomalies, we require an Isolation guarantee:
For a group of atomic, concurrent transactions, the commit of one transaction may not interleave with the operations of another transaction.
Perfect isolation can be trivially achieved through serial execution: executing all transactions on the system one at a time, with no concurrency. This has terrible performance implications; fortunately, it is also unnecessary to achieve perfect isolation. Many concurrent databases, including CockroachDB, instead offer serializable execution, which is equivalent to serial execution while allowing a considerable level of concurrent transactions.
CockroachDB’s default isolation level is called Serializable Snapshot. It is an optimistic, multi-version, timestamp-ordered concurrency control system with the following properties:
Serializable: The resulting database state is equivalent to a serial execution of component transactions.
Recoverable: A set of database transactions is considered recoverable if aborted or abandoned transactions will have no effect on the database state. Our atomic commit system already guarantees that individual transactions are recoverable; our Isolation system uses strict scheduling to ensure that any combination of transactions is also recoverable.
Lockless: Operations execute without taking locks on resources. Correctness is enforced by aborting transactions which would violate either serializability or strict scheduling.
Distributed: There is no central oracle, coordinator or service involved in this system.
Providing Serializable Execution
CockroachDB uses a multi-version timestamp ordering to guarantee that its complete transaction commit history is serializable. The basic technique has been textbook material for three decades, but we will briefly go over how it works:
Serializability Graphs
To demonstrate the correctness of timestamp ordering, we look to serializability theory, and specifically one of its core concepts, the serializability graph. This graph is used to analyze a history of database transactions in terms of operation conflicts.
In the theory, a conflict occurs when two different transactions perform an operation on the same piece of data (one after the other), where at least one of the operations is a write. The second operation is said to be in conflict with the first operation. There are three types of conflicts:
Read-Write (RW) – Second operation overwrites a value that was read by the first operation.
Write-Read (WR) – Second operation reads a value that was written by the first operation.
Write-Write (WW) – Second operation overwrites a value that was written by first operation.
For any given transaction history, these conflicts can be used to create a serializability graph, which is a directed graph linking all transactions.
Transactions are nodes in the graph.
Whenever an operation conflicts with an operation from a different transaction, draw a directed edge from the conflicting operation to the conflicted operation.
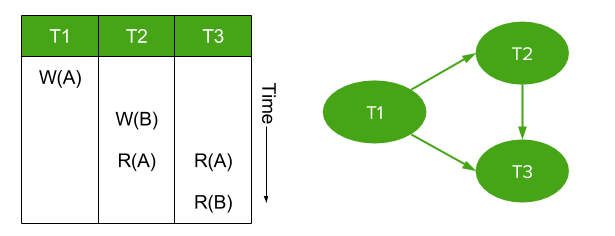
Figure 1: Example of a serializability graph for a simple transaction history.
And we now arrive at a key statement of this theory: a history is guaranteed to be serializable if (and only if) its serializability graph is acyclic. (Proof, for those interested).
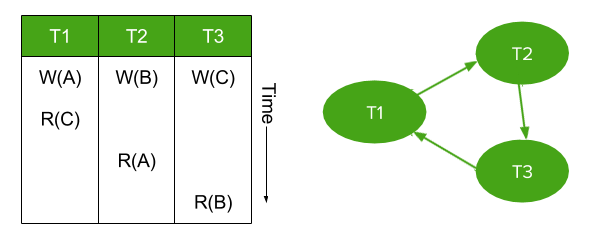
Figure 2: Example of a transaction history with a cyclic serializability graph. This history is not serializable.
CockroachDB’s timestamp ordering guarantees an acyclic serializability graph, and this is straightforward to demonstrate:
Every transaction is assigned a timestamp (from the node on which it starts) when it begins. All operations in that transaction take place at this same timestamp, for the duration of the transaction.
Individual operations can locally determine when they conflict with another operation,and what the transaction timestamp of the conflicted operation is.
Operations are only allowed to conflict with earlier timestamps; a transaction is not allowed to commit if doing so would create a conflict with a later timestamp.
By disallowing any conflicts that flow against the timestamp-ordered direction, cyclic serializability graphs are impossible. However, let’s explore in detail how CockroachDB actually goes about detecting and disallowing these conflicts.
Write-Read Conflicts – MVCC Database
This is where the “multi-version” aspect of our control mechanism comes into play. CockroachDB keys do not store a single value, but rather store multiple timestamped versions of that value. New writes do not overwrite old values, but rather create a new version with a later timestamp.
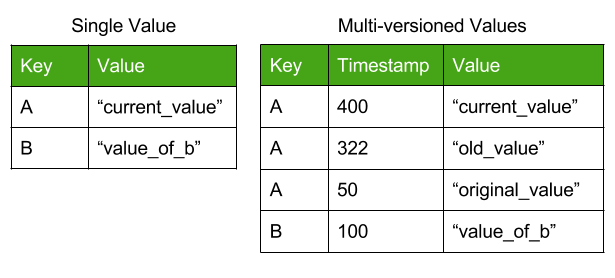
Figure 3: Comparison of multi-versioned value store with a single-value store. Note that the multi-version store is sorted by timestamp.
Read operations on a key return the most recent version with a lower timestamp than the operation:

Thus, it is not possible in CockroachDB to form WR conflicts with later transactions; read operations will never read a value with a later timestamp.
Note: This is the “Snapshot” in serializable snapshot; in-progress transactions essentially see a temporal snapshot of the database, ignoring anything committed later.
Read-Write Conflicts – Read Timestamp Cache
On any read operation, the timestamp of that read operation is recorded in a node-local timestamp cache. This cache will return the most recent timestamp at which the key was read.
All write operations consult the timestamp cache for the key they are writing; if the returned timestamp is greater than the operation timestamp, this indicates a RW conflict with a later timestamp. To disallow this, the operation (and its transaction) must be aborted and restarted with a later timestamp.
The timestamp cache is an interval cache, meaning that its keys are actually key ranges. If a read operation is actually a predicate operating over a range of keys (such as a scan), then the entire scanned key range is written to the timestamp cache. This prevents RW conflicts where the key being written was not present during the scan operation.
The timestamp cache is a size-limited, in-memory LRU (least recently used) data structure, with the oldest timestamps being evicted when the size limit is reached. To deal with keys not in the cache, we also maintain a “low water mark”, which is equivalent to the earliest read timestamp of any key that is present in the cache. If a write operation writes to a key not present in the cache, the “low water mark” is returned instead.
Write-Write Conflicts – Can only write the most recent version of a key
If a write operation attempts to write to a key, but that key already has a version with a later timestamp than the operation itself, allowing the operation would create a WW conflict with the later transaction. To ensure serializability, the operation (and its transaction) must be aborted and restarted with a later timestamp.
By choosing a timestamp-based ordering, and rejecting all conflicts which disagree with that ordering, CockroachDB’s Serializable Snapshot guarantees a serializable schedule.
Recoverable with Strict Scheduling
While the previous conflict rules are sufficient to guarantee a serializable history, a different concern arises when two uncommitted transactions have a conflict: even if that conflict is allowed by our timestamp ordering rules, additional rules are required to ensure that the transaction schedule remains recoverable.
The issue of can be explained with an example:
consider two transactions [T1, T2], where timestamp(T1) < timestamp(T2). T1 writes to a key ‘A’. Later, T2 reads from key ‘A’, before T1 has committed.
This conflict is allowed according to our timestamp ordering rules. However, what value should T2’s read retrieve from ‘A’?
Assume it ignores the uncommitted value written by T1, and retrieves the previous value instead. If T1 and T2 both commit, this will create a WR conflict with T2 (T1 will have overwritten a value read by T2). This violates our timestamp ordering guarantee, and thus serializability.
Assume it retrieves the value written by T1. If T2 commits, but T1 later aborts, this will have violated the atomicity of T1: T1 still will have had an effect on the database state, even though it aborted.
Thus, neither possibility can allowed: in this situation, there is no way that T2 can be safely committed before T1 while maintaining a recoverable schedule.
CockroachDB uses strict scheduling to handle this situation: operations are only allowed to read or overwrite committed values; operations are never allowed to act on an uncommitted value.
Enforcing Strict Scheduling
As established in our atomicity post, uncommitted data is staged in intents on each key, for the purpose of atomic commits. In an MVCC data store, the intent on a key (if present) is stored in a special value which sorts immediately before the most recent committed value:

In our previous post on atomicity, we assumed that any intent encountered by a transaction was the result of an abandoned transaction; however, in a concurrent environment, the intent might instead be from a concurrent transaction which is still running.
Strict scheduling actions are required in two situations: if a read operation encounters an intent with a lower timestamp, or if a write encounters any intent from another transaction (regardless of timestamp ordering). In these situations, there are two options available to CockroachDB:
If the second transaction has a higher timestamp, it can wait for the first transaction to commit or abort before completing the operation.
One of the two transactions can be aborted.
As an optimistic system (no waiting), CockroachDB always chooses to abort one of the transactions. The process of determining which transaction is as follows:
The second transaction (which is encountering an intent) looks up the first transaction’s transaction record, the location of which is present in the intent.
The transaction performs a “push” on the discovered transaction record. The push operation is as follows:
If the first transaction is already committed (the intent was not yet cleaned up), then the second transaction can clean up the intent and proceed as if the intent were a normal value.
Likewise, if the other transaction already aborted, the intent can be removed and the second transaction can proceed as if the intent were not present.
Otherwise, the surviving transaction is deterministic according to priority.
It is not optimal to always abort either the pusher or pushee; there are cases where both transactions will attempt to push the other, so “victory” must be deterministic between any transaction pair.
Each transaction record is thus assigned a
priority
; priority is an integer number. In a push operation, the transaction with the lowest priority is always aborted (if priority is equal, the transaction with the higher timestamp is aborted. In the extremely rare case where both are equal, the pushing transaction is aborted).
New transactions have a random priority. If a transaction is aborted by a push operation and is restarted, its new priority is
max(randomInt(), [priority of transaction that caused the restart] - 1]);this has the effect of probabilistically ratcheting up a transaction’s priority if it is restarted multiple times.
In this way, all conflicts between uncommitted transactions are immediately resolved by aborting one of the transactions, thus enforcing strict scheduling and guaranteeing that all transaction histories are recoverable.
Note on Abandoned Transactions
As mentioned earlier, in a concurrent environment we can no longer assume that unresolved write intents belong to abandoned transactions; we must deal with abandoned transactions in a different way. The priority system already aborts abandoned transactions probabilistically – transactions blocked by the abandoned transaction will eventually have a high enough priority to usurp it.
However, we additionally add a heartbeat timestamp to every transaction. While in progress, an active transaction is responsible for periodically updating the heartbeat timestamp on its central transaction record; if a push operation encounters a transaction with an expired heartbeat timestamp, then it is considered abandoned and can be aborted regardless of priority.
Wrap Up
We have now demonstrated how CockroachDB’s Isolation system is able to provide a serializable and recoverable transaction history in a completely distributed fashion. Combined with our atomic commit post, we have already described a fairly robust system for executing concurrent, distributed ACID transactions. That said, there are still many aspects to CockroachDB’s transaction system that we have not yet covered.
For example, CockroachDB offers another, more relaxed isolation level known as Snapshot (without the “serializable”). Like relaxed isolation levels in other database systems, this mode increases concurrency performance by allowing transactions to interleave in certain cases; for some applications, this is an acceptable tradeoff.
Another aspect is how CockroachDB provides linearizable access to its data. Linearizability is a property that can be difficult to provide in a distributed system. Spencer Kimball has already written this blog post demonstrating how CockroachDB deals with this in some detail (contrasting it with the way a similar system, Google’s Spanner, does the same); however, we may eventually write an additional linearizability blog post focused more directly on our transaction system.
Stay tuned, and please let us know if any of these potential topics are of particular interest.
And if distributed transactions are your jam, check out our open positions here.


