
Even before the stay-at-home orders spiked the demand for digital learning platforms, MyMahi was architecting for scale. MyMahi, a New Zealand-based digital education company, built their student platform, which helps 8,000+ monthly active students track their learning journeys, with CockroachDB Core embedded in a technology stack that includes spot instances (e.g., AWS Fargate), serverless functions (e.g., AWS Lambda), and GraphQL (e.g., GraphQL.js, GraphQL Tools). Starting in 2018, MyMahi designed their new application to take advantage of technologies that allow them to scale out seamlessly in response to student activity.
In this blog post, we'll highlight MyMahi’s application architecture and discuss how different technologies like AWS Lambda interact with CockroachDB to provide a scalable, serverless backend for their application.
MyMahi Chose CockroachDB for Scalability, ACID transactions & Ease of Use
Across their entire tech stack, MyMahi wants to embrace cutting edge technology that sets their platform up for long term success and mirrors the innovation that their platform brings to the education system. While evaluating databases, MyMahi looked for a solution that was scalable and easy to maintain, could deliver ACID transaction semantics, and utilized the familiar PostgreSQL dialect.
MyMahi’s engineering team is small and intends to keep headcount down during this stage of their growth which means each engineer needs to spend as much time as possible adding value to the product. This is why they need a database that does not require engineers to spend time dealing with infrastructure. In addition, MyMahi wants their architecture to be able to handle their expected user growth without exploding in costs at the same time. On a more fine-grained level, the nature of MyMahi’s education product means that traffic is bursty -- during a single day there may be long periods of low usage activity followed by sudden spikes. They need a database that easily scales up and down with the ebb and flow of student traffic.
MyMahi chose the open source version of CockroachDB as their database because it meets each of those requirements.
Application architecture with AWS Lambda, AWS Fargate & CockroachDB
With a database chosen, MyMahi still had to decide how to design the rest of their architecture. This diagram shows the major components they use:
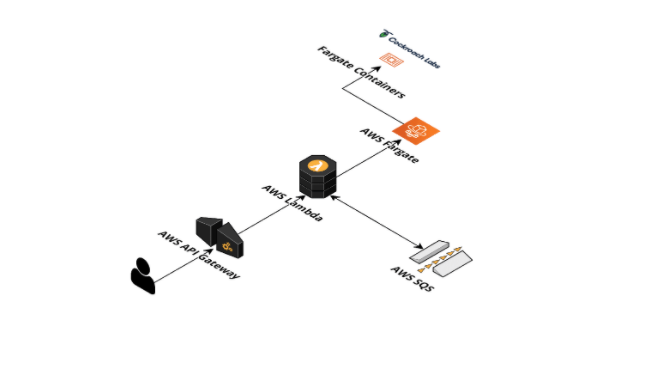
The platform is built in the AWS cloud. A user request comes in and is handled by Route53 DNS resolution. The request is sent to Cloudfront, which is the AWS content delivery network (CDN). Static content like image assets are delivered from an S3 bucket, while other requests are handled by API Gateway. Each API Gateway request is handled by Lambda, which is the serverless platform in AWS that can run stateless application code and take away the burden of having to think of where the code is running. These Lambdas have a 30-second timeout, so longer requests are sent to an SQS queue for processing by async Lambdas, which have a 15-minute timeout. Shorter requests are handled synchronously by fetching data and performing business logic. Some user content is in another S3 bucket, while other data is stored in a CockroachDB cluster.
Initially, MyMahi deployed CockroachDB onto dedicated EC2 instances. In order to lower costs for their database cluster, MyMahi switched to using AWS Fargate spot instances, which offers AWS spare capacity at a significant discount. Fargate is another serverless platform, except instead of just running small functions, it runs long-lived containers.
Today, MyMahi has 12 Fargate spot instances with 4 CPUS and 24GB RAM each. CockroachDB’s resiliency to node failure allows MyMahi to use spot instances which AWS can reclaim (i.e destroy) with only 2 minute notification. This approach carries a performance and availability penalty - if a node is reclaimed, the data that was stored on that node must be re-replicated in the rest of the cluster. During this period of replication if AWS reclaims another node, there is a risk of data loss and unavailability depending on the replication factor. With a replication factor of 3, the loss of two nodes causes irreversible damage and would require a full cluster restore from backup, and with a replication factor of 5, which is what MyMahi uses in production, this number is increased to three nodes.
In their experience, MyMahi has only had their spot instances reclaimed a few times. Each component of this architecture can respond to increases in traffic, and because they use usage-based pricing, costs can remain low.
Using AWS Lambda with Node.js for handling bursts of traffic
We’ll start with the Lambda functions, as they are the part of the architecture that has all the code for connecting to and querying CockroachDB. MyMahi implements their Lambda functions using Node.js. To talk to CockroachDB, the first step is for the Lambda to open a connection. Here’s a small snippet from the MyMahi code that shows how they use the node-postgres driver to do this. Since CockroachDB is a cluster of multiple machines, the connection configuration below is actually pointing to an AWS network load balancer (NLB) that distributes requests across all the nodes in the cluster.
import { Client, Pool, PoolConfig } from '#/pg';
const poolConfig: PoolConfig = {
database: 'mydb',
host: env.DB_HOST,
port: 26257,
ssl: Environment.IS_DEVELOPMENT
? undefined
:{
ca: env.DB_CA_CRT,
cert: env.DB_USER_CRT,
key: env.DB_USER_KEY,
rejectUnauthorized: false
},
user: 'appuser',
application_name: 'demo-api (GraphQL)'
};
const pool = new Pool(poolConfig);
const client = await pool.connect();
One detail to take note of in this code is that although it creates a connection pool, which would normally be used to keep long-lived connections, in practice the connection pool usually only exists for as long as a single invocation of the Lambda. The way Lambda works is that each time the API Gateway receives a request, it takes care of provisioning or finding the compute resources needed to run the code. AWS may sometimes decide to reuse previously completed Lambdas, as described in their FAQ, but in general Lambdas must be stateless, and one cannot rely on the connection pool to exist across different invocations of the Lambda. The advantage of this is that this architecture keeps costs down when there are few incoming requests, and can adapt quickly when a sudden burst of student traffic arrives. MyMahi has not yet had any problems with many short-lived connections being created in bursts, though finding a way to make the connections last longer may be a future optimization.
Using GraphQL to fetch exact data
To power their different UI components, MyMahi was attracted to using GraphQL APIs over the traditional REST APIs in order to fetch the exact data needed from CockroachDB. MyMahi built their GraphQL API server using both graphql and graphql-tools libraries. Within a Lambda function, the GraphQL API server handles queries and mutations (i.e writes) to CockroachDB.
Below is a sample GraphQL schema for a student’s Goal. Within the type Query map, GraphQL allows MyMahi to add additional queries to fetch a subset of a Goal fields without having to define REST endpoints on the server side. There are two things worth highlighting in the code sample below:
The
!indicates that a field cannot be nullA user can define custom types such as
CreateGoalPayloadto use as return values.
type Query {
goals(goalId: UUID): [Goal!]!
// additional queries can be defined here
}
type Mutation {
createGoal(input: CreateGoalInput!): CreateGoalPayload!
updateGoal(input: UpdateGoalInput!): UpdateGoalPayload!
deleteGoal(input: DeleteGoalInput!): DeleteGoalPayload!
}
type Goal {
id: UUID!
goalType: GoalType!
title: String!
information: String!
complete: Boolean!
dueAt: DateTime
color: String
tasks: [GoalTask!]!
notes: [GoalNote!]!
updatedAt: DateTime!
createdAt: DateTime!
}
enum GoalType {
DEVELOPING_ME
HEALTH_AND_WELLBEING
ACADEMIC
EXTRA_CURRICULAR
CAREER
}
type GoalTask {
id: UUID!
information: String!
complete: Boolean!
updatedAt: DateTime!
createdAt: DateTime!
}
type GoalNote {
id: UUID!
information: String!
updatedAt: DateTime!
createdAt: DateTime!
}
For each field of every type such as goals, a resolver function defines the logic for fetching data. MyMahi uses the node-postgres driver to query CockroachDB inside model.getGoals(), model.getTasksForGoal(), and model.getNotesForGoal functions.
{
Query: <ISchemaLevelResolvers>{
goals: async (_, { goalId }, context) => {
const model = context.container.get<GoalModel>(GoalModel);
return model.getGoals(goalId);
}
},
Goal: <IObjectTypeResolvers<IDBGoal>>{
tasks: async (goal, {}, context) => {
const model = context.container.get<GoalModel>(GoalModel);
return model.getTasksForGoal(goal.id);
},
notes: async (goal, {}, context) => {
const model = context.container.get<GoalModel>(GoalModel);
return model.getNotesForGoal(goal.id);
}
}
}
Here is the getGoals() function which uses a SQL builder library to construct the CockroachDB query.
public async getGoals(goalId?: string): Promise<IDBGoal[]> {
if (goalId != null) {
const query = DBGoal.select(DBGoal.star()).from(DBGoal).where(DBGoal.id.equals(goalId)).toQuery();
const goal = await executeTracedQuery<IDBGoal>(this.client, query).firstOrNull();
assertResult(goal, goalId);
return [goal];
} else {
const query = DBGoal.select(DBGoal.star()).from(DBGoal).order(DBGoal.createdAt.desc).toQuery();
return executeTracedQuery<IDBGoal>(this.client, query).results();
}
}
Retry Handling in CockroachDB
CockroachDB is an ACID-compliant database, meaning the GraphQL resolvers can use transactions that run concurrently as if they were isolated from each other -- that is, one transaction cannot see the operations of another concurrent transaction. CockroachDB runs at SERIALIZABLE isolation, which is the safest level of isolation and protects against data anomalies that can happen at lower isolation levels. One example is write skew, which happens when a transaction reads a value, then conditionally writes based on that value while that value has already changed. The extra bookkeeping of SERIALIZABLE isolation can lead to greater contention in the database. This means that when the database is unable to find a serializable ordering of transactions, it will pick a transaction to abort and ask the application to retry it. In order to make it easy to make changes to their GraphQL schema and resolvers, MyMahi abstracted this transaction retry logic into a single function, shown below.
export async function transactionWrap<T>(client: pg.ClientBase, operation: () => Promise<T>) {
// Used for keeping track of operation completion
let complete: boolean = false;
// Used for keeping track of operation result
let result: T;
try {
// Begin transaction with savepoint
await client.query('BEGIN; SAVEPOINT cockroach_restart');
// Loop until operation complete (rethrown errors break out of loop)
while (!complete) {
try {
// Try operation
result = await operation();
// Release savepoint
await client.query('RELEASE SAVEPOINT cockroach_restart');
// Mark operation as complete
complete = true;
} catch (e) {
// Error code 40001 means the transaction is retryable
if (e.code === '40001') {
// Rollback to savepoint at start of transaction
await client.query('ROLLBACK TO SAVEPOINT cockroach_restart');
} else {
// No retry so rethrow error
throw e;
}
}
}
// If we reach here then we have a result (rethrown error would bypass this code)
return result!;
} finally {
// If operation is complete then commit transaction, otherwise rollback transaction entirely
if (complete) {
await client.query('COMMIT');
} else {
await client.query('ROLLBACK');
}
}
}
This function makes use of the special cockroach_restart savepoint which is specifically meant to be used for transaction retry logic. Another option for dealing with transaction retries is to use a loop that begins a new transaction.
Conclusion
When MyMahi set out to design their new application architecture, they experimented and embraced new technologies that would allow them to scale out their student platform with a small engineering team. CockroachDB was the scalable, transactional database that supported their product goals and integrated well with spot instances, AWS Lambda, and GraphQL. With plans to


