



“Do you have any more of these? Can you check in the back?”
This customer query has been the bane of retail employees for almost as long as shopping has existed.
But what was a simple (if annoying) question to answer in the brick-and-mortar era has become quite a challenging one in the digital age. Knowing what inventory you have and where it’s located isn’t easy when you’ve got a mix of online and offline shoppers, pulling items off both retail and digital shelves all over the world in real time.
Even online-only ecommerce shops can struggle to build inventory management systems that remain accurate and effective even under heavy “Black Friday”-style loads.
Let’s take a look at what makes order and inventory management so challenging, and how to architect effective, resilient systems.
What are the technical challenges of inventory management?
Consistency
One of the biggest technical challenges of inventory management is keeping data consistent in real time, or as close to it as possible. Particularly with larger operations, this is vital to avoid “overselling” scenarios that can cost the company money or damage its reputation.
For example, if an item goes out of stock during a Black Friday sale and the company’s inventory system doesn’t reflect that immediately, it may be possible for dozens, hundreds, or thousands of customers to buy items that don’t exist.
Ensuring that doesn’t happen typically requires having a single source-of-truth database for inventory that can then sync with all of the various application services that require inventory data. Building and maintaining a system that is capable of selling inventory to zero but not past zero isn’t easy, especially when it has to remain highly performant even under heavy workloads. For example, DoorDash references this challenge in a recent engineering blog about using changefeeds to process real-time inventory changes.
Scalability
Retail trends aren’t always predictable (i.e. flash sales). But even when they are (i.e. holiday shopping season), maintaining performant infrastructure without overspending means being able to scale quickly up and down so that – for example – your system has the capacity to handle the Black Friday burst, but you’re not paying for “Black Friday” capacity on a random Tuesday in January.
Latency
To reduce latency and improve the customer experience, it makes sense to locate data relevant to the customer on a database that’s close to their geographical location. However, geographically partitioning your database can make it much harder to maintain consistency, depending on the tools you’re using (more on this later), since you now also have to maintain consistency between the various regional database partitions.
Product complexity
Although we’ve mostly used retail sales as an example up to this point, inventory management isn’t as simple as tracking whether an item has been sold or not. Items may move from warehouse to warehouse. Items may be lost or damaged. Some items may expire. There’s also the nebulous “item in cart” period where a particular piece of inventory isn’t quite sold, but also isn’t necessarily available. To maintain an accurate inventory, everything has to be tracked.
Ease of use
Solving all of the above problems is certainly possible, but many of the solutions are technically complex, requiring massive investments in engineering time, training, etc. That can create an entirely new set of problems, including delays and higher-than-expected costs.
What are the technical requirements for a modern inventory management system?
Given the above challenges – which are really just the tip of the iceberg – what should companies be looking for when selecting tooling and architecting their own inventory management solutions?
Among other things, such a system must have:
High availability: Having the system go offline at the wrong time, even if it’s only for a few minutes, can cost a company millions. Inventory management systems must be highly available, and resilient enough that data can never be lost.
Global consistency: An inventory management system must be able to track the truth about product stock and deliver that truth to any application services that require it in real-time, either directly or via solutions such as changefeeds.
Flexible scaling: All parts of any sort of retail back end, including inventory management, must be able to scale up and down easily to handle heavy loads during peak sales periods while minimizing costs by reducing infrastructure spend during the lulls.
Additionally, although they may not be strict requirements for every use case, the ideal inventory management system will also be:
Geographically scalable: Geolocating data allows for a better customer experience (and may also be a regulatory requirement in some circumstances).
(Relatively) easy to use: While inventory management is never easy, reducing system complexity and opting for managed services where possible can reduce the internal costs associated with building and managing the system.
Achieving these goals requires a combination of well-chosen tooling and thoughtful architecture.
Inventory management reference architecture – the big picture
So how do successful retailers accomplish inventory management? First, let’s look at a big-picture example. This anonymized diagram is based on the real architecture of an online and offline retailer with billions in yearly sales revenue:

In the diagram, the purple rectangles arranged horizontally across the center represent the actions of an online shopper from login to purchase. The cylinders represent databases, and there are four of them:
A customer database that stores information about users, including tables for storing their PII, their order history, their browsing history, etc.
An inventory database that stores all metadata related to product inventory, including tables with SKU descriptions, product availability, stock locations, etc. This is our source-of-truth database for inventory management.
An image database which stores product images that will be served on PDPs (product description pages), in customer search results, etc.
A product specs database or potentially API that serves PDPs with product specs. Often, this data comes from a third-party provider and isn’t tracked or maintained by the retailer itself.
Walking through the steps of a single user purchase:
The user logs in, requiring the application to query the customer database.
The user views a PDP, requiring the application to query the inventory database (for stock status, product description, etc.), the customer database (for recommendations and user-specific information on the page), the image database, and the product specs database.
The user puts an item into their cart. Here, it’s up to the system architect to decide how to treat the product, but one common approach is to mark the item as temporarily sold (reducing the available stock temporarily), pending either completion of the sale or the expiration of a timer. If the sale completes successfully before the timer expires, the item is permanently removed from inventory. If it does not complete, the item is removed from the user’s cart and marked as available again in the inventory database.
The user moves to check out, requiring the application to query the customer database to display the relevant user information.
The user completes or fails to complete a purchase, at which point the inventory database is permanently updated to reflect the change in stock, as detailed in step 3.
This sounds relatively straightforward, but achieving this sort of flow while maintaining consistency at scale requires choosing the right tools. In the case of the company described above, their initial solution involved a number of different Cassandra databases, but the lack of consistency at scale led to them occasionally overselling products, creating a poor customer experience.
RELATED
How to build a payments system that scales to infinity
In most contexts, the goal of selling inventory is to sell to zero but never sell beyond zero – never allow customers to buy items you don’t actually have in stock. Achieving that at scale requires a database with ironclad consistency.
By switching to CockroachDB, the company in question was able to reduce their system’s complexity and take advantage of CockroachDB’s consistency without losing out on the scalability. CockroachDB’s multi-region support also enabled them to get the performance advantages associated with locating data close to their customers without adding complexity, since every CockroachDB database can be treated as a single logical database by the application, even though it is distributed (in this case) across multiple regions.
Serving real-time data without impacting database performance
Choosing the right database is certainly important, but inventory management isn’t just about the source-of-truth database. In all likelihood, when inventory changes, a variety of different application services will need to be notified about it, and having all of them constantly querying the inventory database for updates would quickly overload it.
For example, you may have an application service that needs real-time data to make recommendations or user behavior predictions. Or you may have an application service that requires real-time data to predict customer demand and flag “hot” items that are selling faster than expected. Having these kinds of services constantly querying the inventory and customer databases will negatively impact performance.
So how can you keep all of your application services in sync with accurate inventory information without overloading the primary databases? Below is one real-world approach to solving this problem, which comes from another CockroachDB customer that has an ecommerce operation generating billions in yearly revenue:
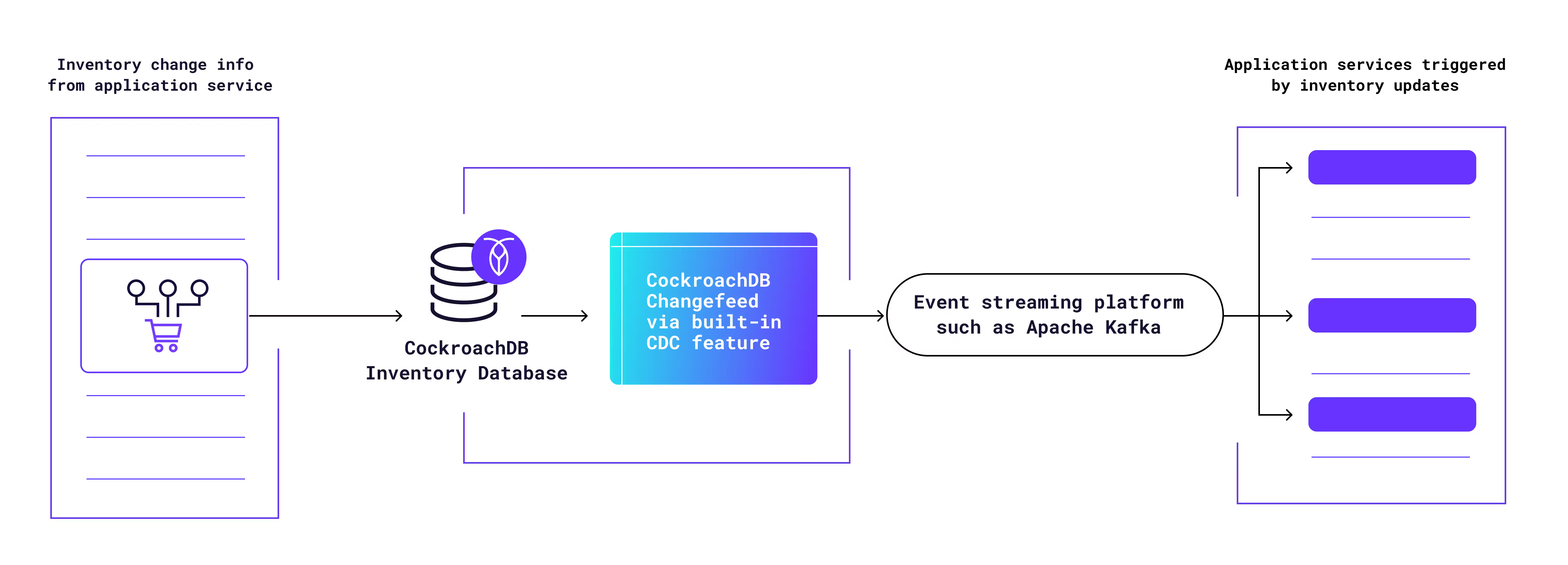
In the above example, an application microservice updates the CockroachDB table with an inventory change (for example, that a product has been sold). Since other services need that information too, this company takes advantage of CockroachDB’s CDC feature to generate a changefeed that sends the inventory update to Kafka, which then triggers other application services and workflows, based on the logic they’ve designed.
As a hypothetical example, imagine a product sells to zero. This information should be stored in the inventory database, but a company might also want it to trigger changes in their application such as removing the now-sold-out item from search results. This architecture makes that possible without requiring those application services to bog the database down by querying it for inventory status. Instead, the status comes to them via CockroachDB’s CDC feature piping the inventory change data to Kafka.
This kind of approach can be used to keep services in sync with any inventory database regardless of the specific technologies used. While CockroachDB’s CDC feature makes creating changefeeds simple, resilient, and scalable, it’s also possible to build this kind of service into a traditional SQL database using something like a transactional outbox, although that will require quite a bit more manual work and likely won’t scale as simply.
Ultimately, there’s no single architecture that’s going to work for all inventory management use cases and setups. However, any company looking to build a scalable, resilient, and consistent inventory management system would do well to learn from the examples in this article, as both come from massive brands with architecture that has been shaped and battle-tested over millions of millions of orders.
Is CockroachDB the right database for your order and inventory management or retail system? Find out how major ecommerce and retail firms are using CockroachDB.


