
In this post we’re going to talk about one of the techniques that can be used in CockroachDB for getting good performance from databases accessed from multiple geographical regions: follower reads. These are operations presenting a slightly stale view of data, which can be served with local latencies from different regions.
By default, CockroachDB offers strongly consistent reads. Our consistency model can be summarized as “no stale reads”, meaning that database reads will return the most up-to-date data. CockroachDB automatically replicates all data at least 3-ways, but client applications are generally oblivious to this. A client can connect to any CockroachDB node and expect that a query will observe the effects of recent writes. For a lot of applications, this is crucial. For other applications though, or, more commonly, for particular parts of applications, strong consistency is not needed. “Stale” reads can be served with potentially much lower latency by not having to coordinate with concurrent writers. An application opts into these staleness semantics by running queries like SELECT * FROM my_table AS OF SYSTEM TIME now() - ‘5s’. This blog post describes the benefits and implementation of these stale reads, detailing how they can be served by any replica of the data. In contrast, strongly-consistent reads can only be served by one replica at a time.
This feature existed for over three years (it was introduced in CockroachDB 19.1), but much of its implementation changed as of CockroachDB 21.1 (we are now fast approaching CockroachDB 23.1). Another feature - Non-voting replicas - makes the use of follower reads more practical, so this is a good time to promote them more. Follower-reads and non-voting replicas serve as big infrastructure pieces for another new feature that we’re very excited about - Global Tables. These tables are the subject of another post we co-authored: Back from the future: Global Tables in CockroachDB.
What are Follower Reads aka Stale Reads?
Follower reads are CockroachDB’s implementation of stale reads. A follower read is served from a “follower” replica, as opposed to a strongly consistent read that’s served by a distinguished “leaseholder” replica. Serving from followers is useful in multi-region clusters because multiple regions can have followers and geographically diverse clients can route their request to a follower nearby - thus getting local latencies for their reads.
We’re generally going to use the terms follower reads and stale reads interchangeably, as the high-level discussion bleeds into the implementation details.

Image 1: CockroachDB cluster spanning across multiple continents, with clients in different geographies accessing local copies of the data through follower reads.
CockroachDB context
To understand the implementation of follower reads, let’s first talk about how strongly-consistent reads work. In CockroachDB, data is split into 512MB-wide spans called ranges. These ranges are replicated across machines using the Raft consensus protocol. Algorithms like Raft and Paxos generally require read operations to execute an instance of the consensus protocol in order to linearize the respective read with respect to writes, thus making sure that reads serve current data. Obtaining Raft consensus implies a round of communication between a quorum of replicas, which is a tall order for reads. In the case of writes, we don’t mind running them through consensus because we fundamentally want the respective data to be replicated. In the case of reads, though, this communication would be too expensive (in terms of both latency and cluster-wide throughput).
What CockroachDB does instead is distinguish a particular replica, the “leaseholder”, and force all operations (both reads and writes) to go through it. Conceptually, we can think of the leaseholder as necessarily being part of all the replication quorums. A lease covers an interval of MVCC timestamps, meaning that the leaseholder sees every write using a timestamp in that interval. Because it sees all the writes, the leaseholder can single-handedly linearize reads without coordinating with any other replica - the leaseholder decides where each read falls in the linear history of operations on a range, splitting overlapping writes into two: writes that come before the read, and writes that come after it. This ordering provides our strong consistency property: the “before” writes are reflected in the read’s results (we say that the read “sees” those writes). Every writing transaction that committed before the reading transaction started will be included in this “before” set.
Besides providing strong consistency, the linearization done by the leaseholder also helps with the transaction isolation performed by the database. Once transaction t1 reads a row, any transaction t2 writing to that row needs to be ordered after t1 in the serial order of transactions implied by CockroachDB’s SQL isolation level (serializable). To ensure this, leaseholders remember the reads they served in a data structure that we call the Timestamp Cache. This data structure interacts with our transactions’ timestamp ordering, potentially forcing t2 to change its timestamp, and perhaps even restart in the name of isolation.
Having this distinguished leaseholder gives us a lot of benefits but, on the flip side, it means that its failure is somewhat disruptive. Different leases cover disjoint MVCC timestamps and so, if a leaseholder fails, the other replicas need to wait until they make sure that it’s not serving reads any more before being able to make progress without it. This is because, generally, the other replicas cannot distinguish between a failed and a slow leaseholder and so, in order to ensure that different leases are non-overlapping, they have to wait until the old lease expires before acquiring a lease themselves and assuming the leaseholder role. Once the old lease expires, it no longer matters whether the old leaseholder was dead or just slow - it will not serve reads at timestamps covered by the next lease (so, reads that could invalidate writes served under the new lease). The passage of time implicitly synchronizes the old and the new leaseholder in this way - allowing the latter to take a new lease and telling the former to relinquish its role.
This idea of distinguishing a replica is used by many systems (for example Google’s Chubby as described in the classic Paxos Made Live paper). You can read more about our implementation in Tobi’s old post Consensus Made Thrive.
One of the consequences of having a leaseholder for a range is that, for consistent reads, the throughput of that leaseholder constrains the consistent-read throughput of the respective range. When a range is “hot”, receiving a lot of traffic, CockroachDB usually splits that range into multiple smaller ranges whose leases can be scattered independently. Still, follower reads can beneficially serve to balance traffic load across all the replicas and avoid the need for a split.
CockroachDB is a multiversion concurrency control (MVCC) database. As such, we maintain multiple versions of each row. Updating a row means writing a new version, identified by the timestamp of the transaction that wrote it. We use timestamp ordering to define the sequencing between transactions. When a transaction reads data, it reads at its timestamp - meaning that it will see writes with lower timestamps and not see writes with higher timestamps. A transaction’s timestamp is set when the transaction starts (and it can evolve over its running time, but that’s a subject for another time). A timestamp essentially identifies a snapshot of the whole database, and this snapshot is transactionally-consistent (it will either include all of a transaction’s writes or none of them).
You’ll notice that, once a transaction fixes the snapshot it’s going to read, that snapshot becomes increasingly stale as the transaction runs. We don’t usually talk about it in these terms but, from an implementation perspective, there’s no distinction between a “stale read” like an AS OF SYSTEM TIME query, and any other read. They’re all operating on fixed snapshots; the only question is what snapshot. The difference, of course, is that the snapshot of a normal transaction includes all the writes committed before the transaction started (and it may or may not include the writes of concurrent transactions), whereas when a client uses the AS OF SYSTEM TIME clause, it chooses to ignore other recent transactions.
Abstract matters: When is stale data OK?
Let’s discuss the circumstances when consulting a stale view of data is OK. There are cases when operating on a stale view is not only OK, but actually desirable.
For example, imagine writing a bank application and needing to generate daily account reports for the customers. Presumably, these reports want to read the state of accounts in the database as they were at 12:00 a.m. Any changes more recent than that are not supposed to be included in the current report; they’re deferred until tomorrow’s report.
Then, there are cases where one doesn’t particularly care about whether they get a stale view of the data or a current view. When loading the Hacker News front page, it doesn’t matter that much whether I see the latest ranking of links, or the ranking from a few seconds ago; I’m going to refresh the page later anyway and observe all the changes. So, if it’s a lot cheaper to see a slightly stale version (and it frequently is), then I’ll take it. A lot of read-only operations that are not particularly tied to any writes fit in this category.
It’s interesting to think about the cases where stale views are specifically not OK. This frequently has to do with the notion of causality: if my read was triggered by a specific write, then I want to see that write. For example, if I’ve just upvoted a Hacker News link and that button click causes a page refresh, I want the read caused by the page generation to reflect the new vote count. Tracking this causality relationship between writes and reads is generally difficult, particularly when you want to allow for relationships between different actors that the database does not have insight on - imagine yelling to a friend to tell them that you’ve sent them an email, at which point the friend refreshes their email client and expects to see the message. This is why, by default, CockroachDB takes the view that a read could be causally related to any write that committed before the read was submitted, and thus our general predilection for strong consistency.
Besides causality, there’s other types of real-time applications that want the freshest data possible. Automated systems trading stocks take split-second (split-microsecond?) decisions about whether the price they see is good to trade on or not. So presenting them with stale data doesn’t seem like a good idea. Of course, these applications care about read latency in addition to staleness, and the two can be related in inverse ways, but still, you get the point.
Another tidbit to keep in mind is that CockroachDB, being a relational database, doesn’t simply provide reads and writes. So far we’ve implicitly talked about read-only transactions. Read-write transactions, at least when operating at the SERIALIZABLE isolation level (the only one CockroachDB offers) want all their reads and writes to be atomic; reads can’t return stale data.
Even though stale reads represent a reduction in consistency, all bets are not off for them. The system is still said to provide a “consistent prefix guarantee” for these reads, meaning that it will still return a snapshot of the data in the cluster. This snapshot will just be a bit stale.
Types of stale reads
The type of stale reads that CockroachDB offers today through the SELECT...AS OF SYSTEM TIME <t> can be classified as an “exact staleness” read, meaning that the client chooses the timestamp representing the database snapshot that will be read. The timestamp expression <t> accepts two forms: an expression returning a TIMESTAMP value, or a negative INTERVAL value: SELECT * FROM t AS OF SYSTEM TIME '2021-01-02 03:04:05' vs SELECT * FROM t AS OF SYSTEM TIME '-30s'.
Recently, we introduced another flavor of stale reads: “bounded stateless reads”. In general, these are more powerful. They allow a client to say “give me whatever data you want, preferably as recent as possible, and also quickly, as long as it’s not over one minute old”.
There are interesting tradeoffs between exact staleness and bounded staleness reads. The bounded staleness reads try to minimize staleness while being tolerant of variable replication lag. For example, a bounded staleness read could generally give you data that’s a few seconds old, but the staleness can grow to, say, one minute when replication across the cluster is encountering difficulties. These reads are more costly, through, because they generally require a negotiation phase where the replicas across the different ranges involved in the read exchange information about which timestamps they can serve locally (remember that we want to serve a consistent snapshot, so all ranges need to be read at the same timestamp).
Bounded staleness reads can also provide higher availability than exact staleness reads in the face of a network partition or other failures that prevent communication with a leaseholder. With exact staleness, the client needs to guess a timestamp that a local replica can serve without communication with the leaseholder. If the guess is wrong, the read generally blocks. With bounded staleness, the client no longer needs to guess anything, instead opting into a degradation of staleness.
Finally, the negotiation phase performed by other bounded-staleness reads allows these reads to offer different blocking guarantees than exact staleness reads: bounded staleness reads can negotiate a timestamp below that of any lock held on the accessed data. This would allow these reads to be non-blocking - they don’t need to wait for other (writing) transactions to finish. Indeed, the bounded-staleness reads that CockroachDB will get will be non-blocking in nature, whereas the current exact staleness reads are not guaranteed to not block on locks. We’re going to touch again on this distinction in the Transaction commit and closed timestamps vs resolved timestamps section, as well as in the Comparison with Spanner section.
Stale reads and multi-region databases
We keep alluding to how stale reads can be served by replicas other than the leaseholder, thus becoming follower reads. One of the major benefits of follower reads is that they can provide low-latency reads in situations where the leaseholder is far away from the client, but another replica (a “follower”) is nearby. Geographically diverse clusters are prime examples of deployments where some replicas are a lot further from a client than others.
In version 21.1, CockroachDB sharpened its focus on multi-region deployments by introducing a number of primitives meant to greatly improve the capabilities and ergonomics of such clusters. A lot of them have to do with navigating the read-latency/write-latency/availability/cost trade-off space. Among the new features are REGIONAL tables which let users ask the database to optimize for writes and strongly-consistent reads to some data from a particular region. The data in question can be specified at either the table or the row level. These tables keep their leaseholder and write quorums in the specified region. By default, every other region gets a replica that can serve follower reads through a new infrastructure piece called non-voting replicas. So, by default, in a multi-region database, every region can perform stale reads on all the data with region-local latencies.
The availability properties of follower reads are particularly important in multi-region environments because users are frequently looking to maintain read availability to data in the face of network partitions. When a particular region is partitioned away from a leaseholder (or, more generally, from a quorum of replicas for a given range), clients in that region can no longer access consistent reads. They can, however, continue to access follower reads through the in-region replicas.
Another new feature in v21.1 is GLOBAL tables - a type of table able to serve strongly-consistent, low-latency reads from any region. We’re quite proud of this capability. These tables come with trade-offs though; chief among them is the fact that writes on GLOBAL tables are relatively slow, so these tables are intended for read-mostly data. These tables will be the subject of a blog post soon by the authors here. The implementation of GLOBAL tables uses many of the mechanisms enabling follower-reads that we’ll describe below.
Implementation of follower reads
The point of follower reads is allowing a replica other than the current leaseholder to serve a particular read request. We’ll discuss how a particular replica can decide whether it can serve a particular read and how requests are routed to replicas other than the leaseholder.
From a replica’s perspective, in order to serve a read, the replica needs to either be the current leaseholder (i.e. have a lease that covers the current read’s timestamp) or have a closed timestamp that’s higher than the read’s timestamp. Closed timestamps are promises that the leaseholder makes to followers that it will not accept writes below the respective timestamp. In both of these cases, the respective replica knows that a) it has seen all the prior overlapping writes at timestamps lower than the read’s timestamp and b) there can be no further overlapping writes at lower timestamps (in the case of the leaseholder, it knows this because it itself will prevent such further writes).
From the perspective of the CockroachDB node trying to perform a read on behalf of a SQL query, if the read’s timestamp is sufficiently far in the past, then the respective read is sent to the replica that appears to be the closest based on pair-wise latency information collected in the background. Otherwise, the request is sent to the leaseholder of the respective range.
Closed Timestamps
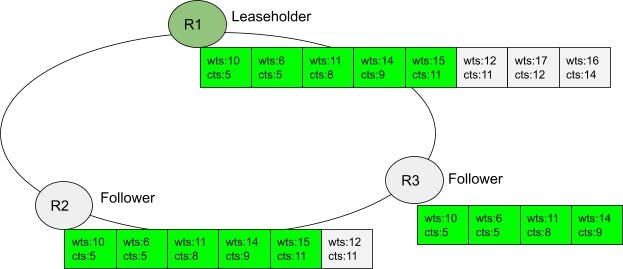
Image 2: This diagram shows a Raft group made out of 3 replicas. R1 is the leaseholder. The Raft log is shown for every replica, with entries known to be committed in green. Each log entry is annotated with the timestamp at which it’s writing, and the closed timestamp it carries. The closed timestamps are increasing monotonically between subsequent log entries. The write timestamps are generally, but not strictly, increasing; each write timestamp is higher than the closed timestamp carried by the previous entry.
To reiterate what we said above, a closed timestamp is a promise from the leaseholder to the follower replicas that it will not accept further writes below the respective timestamp. These promises are piggy-backed onto Raft commands such that the replication stream is synchronized with timestamp closing. If a Raft proposal for a command c has a closed timestamp ct, this means that the replica proposing the command (i.e. the leaseholder; only leaseholders generally make proposals) is saying that, if the command gets quorum and ends up being applied by a replica, that replica knows that once it has applied c, it has all the data necessary to serve reads with timestamps <= ct because there will be no further writes with timestamp <= ct. If the leaseholder subsequently is asked to perform a write at a timestamp <= ct, it will refuse to do so; the leaseholder will “push” the writing transaction, forcing it to write at a higher timestamp instead (pushes may lead to transaction restarts, in cases where a transaction is unable to refresh). A leaseholder will never close a timestamp above its lease expiration, leases are disjoint in time, and a leaseholder will not accept writes with timestamps lower than the start time of the current lease. Together, these invariants mean that the promise of each closed timestamp endures across lease transfers (i.e. future leaseholders will not invalidate the promise made through a timestamp closed by a previous leaseholder).
Generally speaking, a leaseholder continuously closes timestamps a few seconds in the past.
Follower reads, powered by closed timestamps, have been a feature of CockroachDB for a good while. A couple of database versions ago we rewrote their implementation in order to make it both conceptually simpler and to give closed timestamps new flexibility: different ranges can now close different timestamps, whereas before all ranges with leaseholders on the same node would close the same timestamp. This allows us to have different ranges with different closed timestamp policies.
At a high-level, the closed timestamps subsystem works by propagating information from the leaseholders to followers about what timestamp has been closed on each respective range. Updates look like <timestamp, log position> with the meaning that a follower can start serving reads with timestamps at or below <timestamp> as soon as they’ve applied all the Raft commands through <log position>.
In what follows, we’re first going to discuss the mechanics of publishing closed timestamp updates after a leaseholder has decided to close a timestamp, and then we’ll discuss what timestamps get closed.
Publishing closed timestamp
There are two ways through which a leaseholder publishes closed timestamp updates: the “Raft transport” and the “side-transport”. The Raft transport is the Raft log itself: besides the changes to the range’s data, each Raft command also may contain a closed timestamp update. The log position in this update is implicit - it is the command’s log index. In other words, each command carries a timestamp ct, which says to followers that, as soon as they applied that command, there will be no more changes to data performed at timestamps <= ct. We’ll see below how the ct is assigned; for now know that this timestamp is monotonically increasing between subsequent Raft commands, and it is common to have a span of consecutive commands that carry the same ct (meaning, commands don’t necessarily advance the closed timestamp; they might leave it as it was).
As long as there’s write traffic to a range, resulting in Raft replication, the Raft transport keeps the closed timestamp advancing on followers.
When there’s a period of no write activity, that’s when the side-transport takes over. We don’t want the follower’s view of the closed timestamp to stall. However, we also don’t want to have to periodically write to all ranges in the system just to keep their closed timestamp moving forward. The side-transport stikes a compromise here. It is implemented as a node-level process that acts as a publisher of last resort. Every 200ms (the kv.closed_timestamp.side_transport_interval cluster setting), the side-transport fixes a timestamp to close for each group of ranges (where a group is defined as all ranges with the same timestamp closing policy). The timestamps will be published en masse, for a whole set of ranges at once. The side-transport iterates through all the leaseholders on the node and, for each one, it checks whether it’s safe to close the fixed timestamp (see below for how this determination is made). All the ranges for which it is safe to close the fixed timestamps are grouped by the nodes containing their follower replicas, and bulk network messages are then sent to these nodes specifying the fixed close timestamps and the set of ranges to which they apply. Such a message looks like {{closed timestamp: 100, ranges: 1,2,3,4,5}, {closed timestamp: 200, ranges: 6,7,8,9,10}} (see the Performance considerations section).
From a follower replica’s perspective, managing incoming closed timestamp information across the two channels can be confusing. Two invariants that we’ve built into the closing process help:
When two closed timestamp updates reference different log positions, the timestamp associated with the higher position will always be equal or greater than the other one.
If both channels publish closed timestamps associated with the same log position, the side-transport will carry a higher timestamp.
Target closed timestamp policies
A leaseholder is, in principle, free to close any timestamp ct it wants as long as all the following conditions are met:
ctis lower than the expiration of its lease. In order for lease changes to not invalidate previously closed timestamps, no leaseholder closes timestamps above its lease expiration. This is generally not an issue, as we naturally want to close timestamps in the past, and the leaseholder has a lease valid for the present time (by definition). But, in the case of ranges storing the data for GLOBAL tables, we actually close timestamps in the future - a fairly mind-bending concept.ctis higher than all the previously closed timestamps - in order to keep closed timestamps monotonic.ctis lower than the oldest timestamp at which an in-flight request is currently evaluating. The act of closing a timestamp needs to synchronize with the processing of write requests (we call the relevant part of request processing “evaluation”) because, once a timestamp t has been closed, incoming requests trying to write at lower timestamps must be told to change their timestamps.
The leaseholder thus generally has a window of timestamps that it could close at any point in time. When deciding exactly what timestamp to close, there is a tradeoff to consider: there’s a tension between the desire to make followers as useful as possible by allowing them to serve follower reads at more recent timestamps, and the desire to not disturb foreground write traffic. If we close a very recent timestamp, and then are asked to evaluate a write at a lower timestamp, then that writing transaction will be forced to change its timestamp. Changing a transaction’s timestamp can be a relatively expensive operation and, at worst, can lead to an error asking the client to retry the transaction in order to get a serializable execution. Our current policy is to target the closing of timestamps 3s in the past, subject to the kv.closed_timestamp.target_duration cluster setting.
Writes Tracker
The policy described above gives us a closed timestamp target. In the context of a particular range, that target timestamp might not be safe to close: it can’t be closed if there are in-flight writes (in the process of being evaluated on that leaseholder) that are evaluating at a lower timestamp. If such a write exists and we were to close the lower target timestamp, then the write would invalidate the closed timestamp promise once it finishes evaluating and it replicates to the follower. Once a timestamp is closed, future writes will not be permitted below the closed timestamp; here we’re talking about synchronizing with writes that are already evaluating.
To avoid this race, the closing of timestamps and the evaluation of writes synchronize with one another through a “write tracker”. In order to answer the question of what is the “oldest” request currently evaluating on the range (let’s call it t_eval), the tracker maintains a compressed, approximate summary of the timestamps of evaluating requests. The Raft transport synchronizes with the tracker and ratchets back the closed timestamp target that it wants to close to t_eval. Similarly, the side-transport synchronizes with the tracker. Since this transport publishes closed timestamps in bulk for many ranges at once, it doesn’t have the option of ratcheting down the target timestamp (i.e. it doesn’t have the option of customizing the closed timestamp for a particular range), so it simply refuses to publish an update for a particular range if that range’s t_eval is below the target timestamp. The reasoning for the side-transport goes that, if this condition fires, then the range in question is not dormant (since there must be at least one write in the process evaluating), and so the side-transport is not needed for the respective range anyway; the Raft transport will advance the range’s closed timestamp once that write finishes evaluating.
The tracker’s implementation is designed to offer good throughput and scalability; writes can be processed by CockroachDB at rates of thousands/core/sec. To sustain high throughput, it’s important for different writes to coordinate with each other as little as possible. First of all, we’ve made the tracker a per-range data structure (as opposed to, say, a node-wide singleton). Thus, writes being evaluated by different ranges don’t synchronize with each other. Still, even within a single range, throughput is very important and we don’t want the tracker becoming a bottleneck.
The straightforward implementation that would encode the functional requirements of the tracker would be a min-heap, maintaining the in-flight writes ordered by their timestamp. Once each write is done evaluating, we’d take it out of the heap, at which point we could close out the remaining minimum. Implementing a heap is too expensive, unfortunately, as it requires too much locking. To make the heap cheaper, we could start compressing the requests into fewer heap entries: we could discretize the timestamps into windows of, say, 10ms. Each entry could be represented in the heap by a single element, with an atomic refcount. The heap could become simply a circular buffer, but the number of buckets could be unbounded (depending on the evaluation time of the slowest request). Going a step further would be placing a limit on the number of buckets and, once the limit is reached, just have new requests join the last bucket. What should this limit be? Well, a limit of one doesn’t really work, and the next smallest integer is two. So, at the limit, we could maintain just two buckets - which is what we’ve done. An analysis shows that this approximate compression scheme is not too bad - under constant arrival of writes and uniform evaluation time L, this Tracker produces a minimum timestamp that is lagging the actual minimum one by L, and the minimum is updated at a rate of 1/L (as opposed to an unbounded rate for the theoretical heap).
Our tracker implementation maintains two buckets of requests, with an ordering between them. Each bucket has a refcount and a lower-bound timestamp. The invariant is that the first bucket’s lower-bound is lower than the second’s. As requests arrive, they join one of the two buckets - usually the second one. When the first bucket empties, the second bucket shifts left to become the first one, and a new bucket is conceptually created. When a shift occurs, the closed timestamp can advance from the lower-bound of the destroyed bucket to the lower-bound of the remaining one.
The exact logic for apportioning incoming write requests to buckets is presented by the following hopefully suggestive diagram copied from the code.
// ^ time flows upwards | |
// | | |
// | | |
// | ts 25 joins b2 -> | | | |
// | | | | |
// | | | +----+
// | | | b2 ts: 20
// | ts 15 joins b2, -> | |
// | extending it downwards +----+
// | b1 ts: 10
// | ts 5 joins b1, ->
// | extending it downwards
//
// Our goal is to maximize the Tracker's lower bound (i.e. its conservative
// approximation about the lowest tracked timestamp), which is b1's timestamp
// (see below).
//
// - 25 is above both buckets (meaning above the buckets' timestamp), so it
// joins b2. It would be technically correct for it to join b1 too, but it'd
// be a bad idea: if b1 would be slow enough to be on the critical path for b1
// draining (which it likely is, if all the timestamp stay in the set for a
// similar amount of time) then it'd be preventing bumping the lower bound
// from 10 to 20 (which, in practice, would translate in the respective range not
// closing the [10, 20) range of timestamps).
// - 15 is below b2, but above b1. It's not quite as clear cut which
// bucket is the best one to join; if its lifetime is short and
// so it is *not* on the critical path for b1 draining, then it'd be better for
// it to join b1. Once b1 drains, we'll be able to bump the tracker's lower
// bound to 20. On the other hand, if it joins b2, then b2's timestamp comes
// down to 15 and, once b1 drains and 15 is removed from the tracked set, the
// tracker's lower bound would only become 15 (which is worse than 20). But,
// on the third hand, if 15 stays tracked for a while and is on b1's critical
// path, then putting it in b2 would at least allow us to bump the lower bound
// to 15, which is better than nothing. We take this argument, and put it in
// b2.
// - 5 is below both buckets. The only sensible thing to do is putting it
// in b1; otherwise we'd have to extend b2 downwards, inverting b1 and b2.
The actual code of our tracker is complicated by the desire of implementing it in a semi-lock-free manner. Multiple requests can enter the Tracker concurrently without blocking each other. Requests exit the bucket in batches, and they do so under an exclusive lock. This is a pattern that we’ve used in the CockroachDB codebase multiple times: protecting a data structure with a Readers-Writer Lock, and using the “read” lock for performing lock-free operations concurrently (which operations are not “read-only”) while synchronizing with a heavier class of operations that cannot be implemented lock-free, which take the “write” lock. Is there a name for this pattern?
Writes “exiting” the tracker deserve some explanations: a write no longer needs to be tracked once its Raft log position has been determined. We need synchronization between requests exiting the Tracker and requests being serialized through the Raft log; in other words, it’s important that the writes exit the tracker in the order in which they are serialized by Raft - otherwise, if they exit too early, it’d be possible for a command at a lower log index to carry a closed timestamp that will be invalidated by a subsequent command. The required serialization happens at the point when commands are proposed to the Raft machinery. Proposals happen on a goroutine pool driven by a scheduler, and they happen in batches: once a write finishes evaluation, its resulting Raft command is serialized in a buffer which gets emptied periodically. This process of emptying the buffer is the point when the order between the respective writes is finalized as they each get assigned consecutive log positions. This buffer flushing operation takes a write lock on the Tracker, which allows it to remove requests from the Tracker and to read the Tracker’s lower bound timestamp.
Performance considerations
The performance of the closed timestamp implementation was a key consideration. We’ve paid attention to performance in particular in the implementation of the writes tracker, and in the implementation of the side transport receiver. We’ve discussed the tracker’s implementation above, so we’ll focus on the side-transport here.
The evolution of the sender- and receiver-side state in the side-transport for a pair of nodes: n1 sending closed timestamp info to n3.
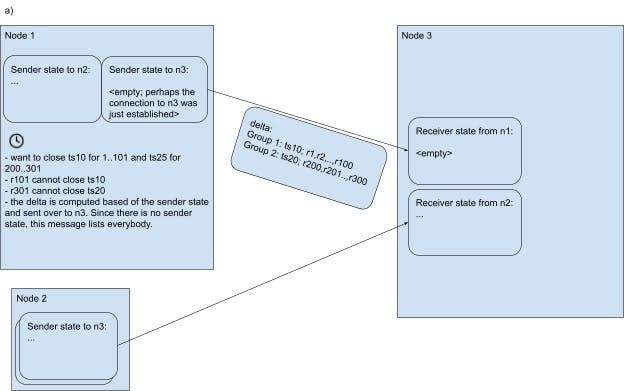
Image 3.A A network side-transport streaming RPC connection has just been established between n1 and n3 (imagine that one of the nodes just restarted or the previous connection dropped for some other reason). Both sender and receiver start with empty state. On a timer tick, n1 wants to communicate closed timestamps to n3 for all ranges for which n1 is the leaseholder and n3 has a (follower) replica. Say these ranges are r1…r101 and r200..r301. The sender groups the ranges by their target closed timestamp and within each group checks whether each range can close the target timestamp. Let’s say that there’s two targets: ts10 for r1..r101 and ts20 for r200..r301. Let’s further say that all ranges can close their target timestamps except r101 and r301. Thus, n3 sends a message saying that r1…r100 have closed ts10, and r200…r300 have closed ts20.
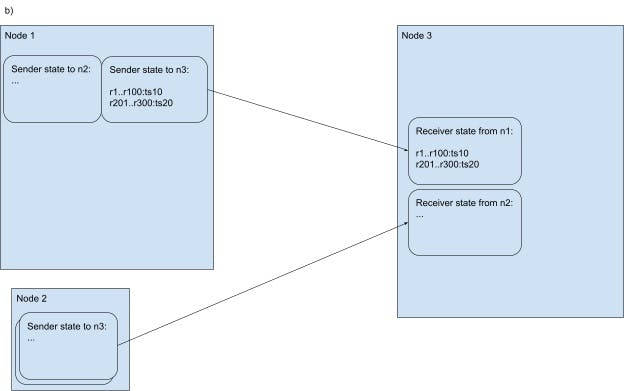
Image 3.B Upon sending the message, the n1 updates the connection’s sender-side state. Upon receiving the message, n3 updates the connection’s receiver-side state.
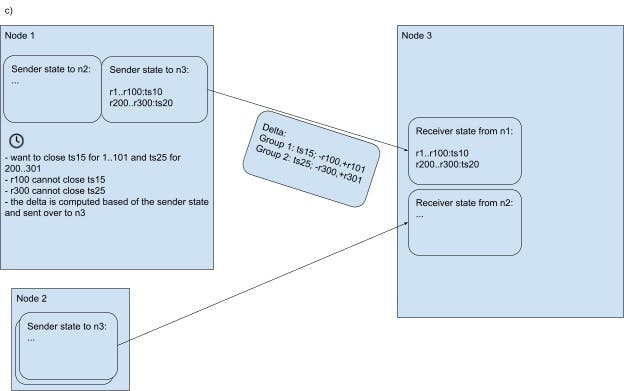
Image 3.C The ticker fires again and n1 prepares a new message for n3. The target closed timestamps are now ts15 and ts25 for the two groups of ranges. All the ranges can close their respective targets, except r100 and r300. A delta message is produced for n3 in relationship with the connection’s state. The message contains the advancement of the closed timestamp for every group, and the group membership changes.
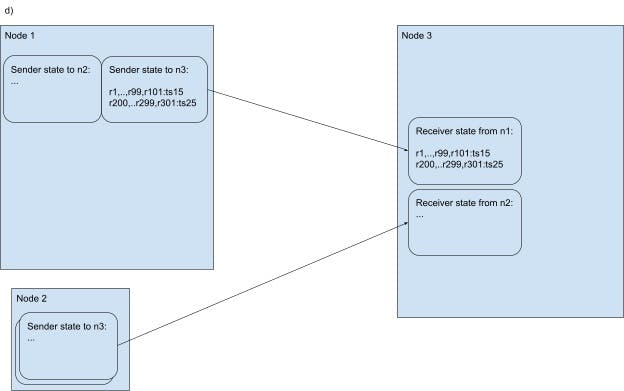
Image 3.D Upon sending the message, the n1 updates the connection’s sender-side state. Upon receiving the message, n3 updates the connection’s receiver-side state.
Each node is expected to receive side-transport closed timestamp updates from many other nodes (commonly, from all other nodes in the cluster). Thus, processing an update needs to be fast. Also, updates from different nodes should be processed concurrently. To help with the first point, the side-transport closed timestamp updates only contain deltas from the previous update sent on the same streaming RPC connection. This way, a lot of state is carried implicitly by each message, by referencing the connection’s state. For example, say that, on the previous tick, the side-transport had closed timestamp 10 for ranges 1..100, and timestamp 20 for ranges 201..300. Say that, on the current tick, it wants to close timestamp 15 for ranges 1..99,101 and timestamp 25 for ranges 201..299,301 - so, closed timestamps are advanced for all the ranges from the first message with the exception of ranges 100 and 300 for which timestamps 15 and 20 respectively cannot be currently closed for whatever reason, and, in addition, ranges 101 and 301 can have their timestamp closed. The message representing this update will contain the new timestamps, removal markers for ranges 100 and 300, and addition markers for ranges 101 and 301. Ranges 100..199 and 200..299 are referenced implicitly (see diagram above). This scheme saves network bandwidth and makes the receiver’s processing proportional to the number of additions/removal rather than the total number of ranges that the sender is referencing. Remember that a sender is expected to close timestamps on a number of ranges proportional to the number of range leases it has, whereas the additions and removals are on the order of the ranges whose state switched from relatively active to relatively inactive or vice-versa since the last tick.
To help with the parallel processing of updates, we’ve segregated the receiver’s state per sender node. There’s no state shared between senders, so there’s no need for synchronization across different network connections. A downside of this is that whoever wants to query the side-transport’s information about a particular range needs to know what sender node is sending the information the querier is looking for. In other words, whenever a closed timestamp is queried, the current leaseholder of the respective range needs to be known. Querying in conjunction with stale leaseholder information will result in retrieving stale closed timestamp information, or failure to retrieve any closed timestamp information. That’s not the end of the world, but it can mean that an opportunity to serve a read as a follower read is missed. In practice, the actors doing the querying are the follower replicas for the range being queried, and they tend to have up-to-date information on who the current leaseholder is (and if a follower doesn’t know who the leaseholder is, it generally means that it’s far behind in applying the replication log anyway).
Another code path that we’ve optimized is the closed timestamp query path. When a follower replica wants to determine the closed timestamp that it can use (i.e. the upper-bound of the timestamps for which it can serve follower-reads), that information can come from two places:
It can come from the replica state that’s maintained by the Raft log. This state is cheap to access.
It can come from the side-transport. That state is more expensive to access because it involves a map lookup and it requires synchronization with the updates being received by the side-transport.
In order to minimize access to the side-transport’s state, we do two things:
We put a per-replica cache in front of the side-transport. The cache is updated lazily, on query.
Whenever we query the closed timestamp, we do so in conjunction with a timestamp that’s “sufficient”. The queries generally aren’t “what’s the latest closed timestamp I can use for this replica”, but rather “is the closed timestamp above this threshold”? When the sufficient value is satisfied either by the replica state or by the cache, we don’t need to go to the side-transport. The sufficient threshold is the timestamp of the read which we suspect we might be able to serve locally as a follower-read.
Transaction commit and closed timestamps vs resolved timestamps
We’ve talked repeatedly about how it’s not safe to close timestamps below the timestamps that writes are evaluating at, and about how once a timestamp is closed, future writes need to change their timestamps in order to not invalidate the closed timestamp promise. We’ve been talking about writes without tying them to their parent transactions. There’s subtlety here that deserves explaining: a transaction is allowed to commit at a timestamp below the closed timestamp. So, in that sense, committing a transaction surprisingly does not count as a “write”. In fact, transaction commits are conceptually not tied to any particular range (transactions can write across ranges). As such, if commits were to be subject to closed timestamps, it’s not clear which closed timestamp would apply (as the closed timestamps are per-range attributes). The closed timestamp promise can be rationalized as a promise to not write new data below the closed timestamp. Committing a transaction releases write locks and might update the MVCC timestamp of keys in one direction - upwards. These operations are permitted to happen even below the closed timestamp.
To understand the point we’re trying to make here, let’s remember the purpose of closed timestamps: to enable follower reads. A read below the closed timestamp ct can be served by a follower. In order for this read to properly be tied to a consistent database snapshot, it must be the case that, once it evaluates, no data that it hasn’t seen gets written (i.e. committed) with a lower MVCC timestamp. A key/value pair written within a transaction that hasn’t been committed yet is called an “intent”. Intents act as write locks - they block readers at higher timestamps until the writer commits or aborts. This blocking happens for follower reads as well as for strongly-consistent reads. So, as long as uncommitted data acts as locks and the act of committing can only change a value’s timestamp upwards, commits don’t need to particularly interact with closed timestamps. And indeed, a commit can only ratchet up the timestamps of the committed keys - so it cannot cause keys to float down from >ct to <ct.
It’s worth noting that, besides closed timestamps, CockroachDB also has the notion of “resolved timestamps”, which take transaction commits into consideration. The resolved timestamp for a range is the minimum between the range’s closed timestamp and the timestamp of the oldest write lock on the range. By definition, transactions can only commit above the resolved timestamp.
Resolved timestamps enable the Change Data Capture (CDC) features, which stream CockroachDB data updates to other systems. These streams don’t publish uncommitted data (because we don’t want to be in the business of publishing retractions), and otherwise care about making promises to subscribers like “you’ve now seen all the data with timestamps below t that there’s ever going to be”. This promise is similar to the closed timestamp one. As such, resolved timestamps have a higher-level tracker that works at the level of transactions, as opposed to working at the level of replicating individual writes. The resolved timestamp tracker keeps note of what transactions are still running and their timestamps. As old transactions gradually drain out, the resolved timestamp gets incremented. That mechanism is beyond the scope of the current post (but see this CDC blog post). Besides CDC, the resolved timestamps also power the upcoming bounded staleness reads. A feature of these reads is that they are non-blocking; as such, they operate below the resolved timestamp of the keys they’re trying to read, knowing that there cannot be any conflicting locks on those keys (locks in CockroachDB are timestamp aware; a read at timestamp 10 does not conflict with a write lock at timestamp 20).
The semantic difference between closed timestamps and resolved timestamps sometimes trip up even the best of us on occasion.
Request routing
We’ve talked at length about how follower replicas figure out whether they’re up to date enough to serve a read at a particular timestamp. This section will describe how read requests get to follower replicas in the first place. CockroachDB is architected as a SQL execution engine that sits on top of a distributed key-value store. The distribution of the keys in this lower KV layer is generally abstracted away from SQL execution; the nodes performing SQL processing are frequently different from the nodes that have replicas for the data being accessed. We have a component called the DistSender that routes read/write requests to the right place. The DistSender uses a cluster-wide index containing the location of replicas for every range, and it uses an in-memory cache for keeping track of which replica is the current leaseholder.
Generally, the DistSender tries to route requests to leaseholders. But, if the request is read-only with a timestamp that’s old enough, the DistSender chooses the closest replica instead - where “closest” is determined by monitoring the pair-wise network latencies between nodes. A read timestamp is considered “old enough” if it’s likely that every follower has been informed of a closed timestamp higher than the read timestamp. This computation takes into account the configure closed timestamp lag target, the frequency of the side-transport ticker, and some slack for the network communication latency.
Comparing CockroachDB with Spanner
It’s interesting to contrast CockroachDB and Spanner, as they relate to stale reads and everything we’ve been talking about. We’ve found that contrasting our database with Spanner (at least to the extent that Spanner is described publicly) is a good way to get insights into both systems.
In Spanner, every replica serves both strongly-consistent and stale reads. When serving strongly-consistent reads, a replica that doesn’t hold the respective lease contacts the leader and asks for a log position associated with the read’s timestamp, and then waits for replication to apply commands through the respective log position locally. The ask from the follower to the leader is to essentially close a timestamp. Spanner transactions only get their timestamps at commit time, and they get a recent timestamp. So, closing a recent timestamp is not a disruptive operation for Spanner; it is the normal transaction flow. All writes within a transaction are buffered and only written out to MVCC storage at commit time, together with their timestamp.
In contrast, in CockroachDB, closing a recent timestamp can be more disruptive to transactions. A transaction gets its timestamp when it starts, and it writes data as it runs. If, during its lifetime, the transaction tries to write to a range below the range’s closed timestamp (or, more generally, below the latest time at which the respective key has been read), the transaction needs to change its timestamp - which can be an expensive operation or even cause a client-visible transaction restart in order to maintain serializability. At the very least, changing a transaction’s timestamp entails rewriting all previously-written keys in order to update their MVCC timestamps.
To avoid these issues as much as possible, CockroachDB closes timestamps a few seconds in the past - out of the way of transactions with durations shorter than this gap. The fact that we optimistically assign timestamp to transactions as they start makes it harder for us to serve strong reads from followers with a scheme as clean as Spanner’s. On the other hand, though, we get a great benefit from our scheme, which is that we can generally do without read locks, even in Serializable read-write transactions. Spanner needs to take read locks before reading anything, and these read locks need to be explicitly released at commit time. In CockroachDB, reads don’t usually take locks (although they can, for example through SELECT FOR UPDATE queries); instead, they use their optimistic timestamp to populate a best-effort data structure called the Timestamp Cache whose role is to prevent overlapping writes at lower timestamps. There’s no “release” step on this data structure so, at commit time, there’s no need for the transaction coordinator to contact the read ranges.
For historical trivia, it’s interesting that Google had a precursor system to Spanner - Percolator - which is a bit more similar to the CockroachDB transaction protocol than Spanner is. In Percolator, transactions read at a “start timestamp” and commit at a higher “commit timestamp”. Data is written before the commit timestamp is determined, and Percolator goes through some difficulties to avoid re-writing the MVCC timestamps with the commit timestamp: readers go through an indirection from one Bigtable column family to another to first figure out the timestamp at which the data is stored at, and then to actually read the data.
An interesting difference between CockroachDB and Spanner in serving follower reads (or, rather, any “snapshot reads”) is that Spanner requires a follower to have caught up to a resolved timestamp (“safe timestamp” in Spanner parlance) rather than a closed timestamp. While a Spanner transaction is prepared but not yet committed, a replica for a range that the transaction wrote to will not serve a read at a timestamp >= the transaction’s prepare time. Even if the replica can verify that it has the transaction’s writes, the state of those writes is indeterminate until the transaction performs its second phase of 2-Phase Commit, and so Spanner doesn’t attempt to serve the read on a follower.
Each leader keeps track of prepared-but-not-yet-commited transactions and piggy-backs the lower bound of their prepared timestamps onto Paxos replication messages, thus allowing followers to keep track of the highest timestamp for which all data has both been replicated locally and also is in a determinate state (committed or aborted). This means that once such a snapshot read is allowed to proceed on a replica, it can do so without checking any locks - so it won’t block. The downside is that the read has to wait until the respective replica has received a suitable resolved timestamp. A single prepared transaction that’s slow to commit holds up all reads (at timestamps above the prepare timestamp) on the ranges it touched. The Spanner paper suggests that this kind of false-conflicts can be improved by having leaders publish more fine-grained resolved timestamp information - different resolved timestamps for different key spans within a range. The paper is old; perhaps this improvement was implemented by now.
In contrast, CockroachDB implicitly avoids the false-conflicts by allowing follower reads to be served by a replica if they’re reading below the closed timestamp, not necessarily below the resolved timestamp. In case of a real conflict with a recent writing transaction, these reads will encounter a write intent (a write lock). In such cases, the read performs conflict resolution - in the simple case, it blocks until the lock is released. For implementation reasons, this means that the read ends up being redirected to the leaseholder. In order to route only requests that wouldn’t block to followers, we’d have to either implement a closed timestamp tracker at the level of each range, or to do work at query-time to discover what locks exist. Our upcoming release will support bounded-staleness reads which avoid blocking on locks, but for starters we’ll only support the reads in a limited set of circumstances, where figuring out what the read set is and what locks might exist is cheap. On its part, Spanner seems to have a similar restriction, in that bounded-staleness reads can only be performed in “single-use” transactions.


