
Dealing with distributed database performance issues? Let’s talk about CDNs.
Even though they’re at different levels of your tech stack, distributed databases and content delivery networks often share a similar goal: improving the availability and speed between your service and your user.
To deliver content as quickly as possible (at least when it’s static), one of the first tools teams reach for is a content delivery network. CDNs leverage a whole stack of technologies to rapidly deliver resources to users, but one of the more impactful strategies is to simply replicate data all over the globe, so user requests never have to travel far. In the parlance of operations teams, this is a multi-region deployment.
How CDN distribution works
Despite being geographically distributed, CDN replication is relatively straightforward: they simply distribute a file to more and more servers. User requests can be served by the server that’s closest to them geographically, which improves the user experience by reducing latency.
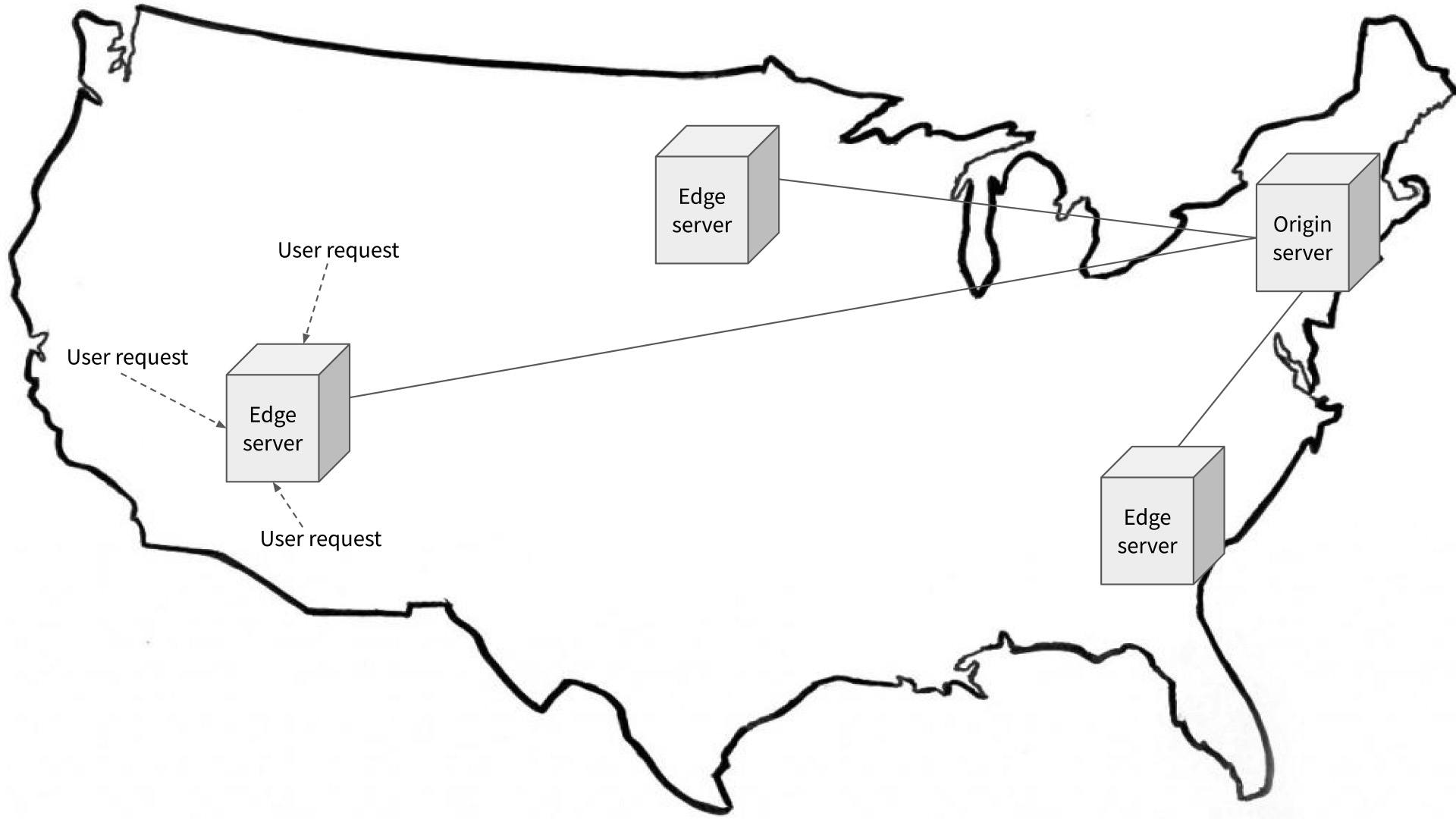
Of course, CDNs have an advantage that makes this kind of deployment easy: the data they serve changes infrequently, or not at all. Keeping the edge servers in constant sync with the origin server typically isn’t a major concern.
For distributed databases, it’s a different story. Managing state across a set of machines is a hard problem to solve, so databases have generally had to make unattractive trade-offs like settling for eventual consistency when distributing data far and wide.
Businesses have often been unwilling to accept these compromises (and rightfully so), causing them to shy away from and write off multi-region deployments. But this approach has its own price.
The costs of single-region deployments
While siloing data in a single region can make things easier from a development and ops perspective, this strategy actually limits two things that most companies really want from their databases: speed and availability.
Single-region deployments are slower
In 2023, computers are still bound by physics, and cannot compete with the speed of light. A user who is farther away from a service will experience higher latencies when communicating with it. This is the fundamental reason we use content delivery networks and stateless services wherever we can. However, even with a razor-thin time-to-first-byte, an application’s user experience can still falter if it has to communicate with a database thousands of miles away.
This problem is compounded by the fact that latencies quickly become cumulative. If your SLAs allow for a 300ms round trip between an app and a database, that’s great––but if the app needs to make multiple requests that cannot be run in parallel, it pays that 300ms latency for each request. Even if that math doesn’t dominate your application’s response times, you should account for customers who aren’t near fiber connections or who live across an ocean: that 300ms could easily be 3000ms and requests could become agonizingly slow.
If you need a gentle reminder as to why this matters for your business, Google and Amazon both have oft-cited studies showing the financial implications of latency. If your site or service is slow, people will take their attention and wallets elsewhere.
A simple solution: deploy your data to the regions where your users are.
Single-region deployments aren’t as resilient
A distributed database’s performance isn’t measured solely in ms; uptime is also a crucial factor. No matter how fast your service normally is, if it’s down, it’s worthless. To maximize the value of their services, companies and their CTOs chase down the elusive Five Nines of uptime (which implies no more than 26 seconds of downtime per month).
Achieving Five Nines requires reliable data centers with incredible networks––but what about forces of nature beyond your control? Forrester research found that 19% of major service disruptions were caused by acts of nature that could take down a cloud host’s entire region: hurricanes, floods, winter storms, and earthquakes.
As Hurricane Sandy proved, these events can be powerful enough to cripple companies deployed in only a single region, including blogosphere titans like BuzzFeed and The Huffington Post. With their sites down, they couldn’t fulfill their mission of delivering content on the world’s latest events, and instead themselves became a collateral story.
Another facet of your application’s availability guarantees is defining its point of recovery (or Recovery Point Objective/RPO) in the case of one of these catastrophes. This is particularly crucial for your customer’s data. If your data’s only located in a single region and it goes down, you are faced with a “non-zero RPO”, meaning you will simply lose all transactions committed after your last backup. If they’re mission-critical entries, you face the risk of losing not only revenue, but also your user’s trust.
So, as the weather gets weirder, the best way to ensure your application stays up and doesn’t lose data is to distribute it far and wide. This way, your users’ data is safe even if swaths of the globe go dark.
Single region deployments aren’t compliant
While latency and uptime make great headlines, there’s an ever-unfolding story that can make single-region deployments untenable: data regulations.
General Data Protection Regulation (GDPR), in particular, requires that businesses receive explicit consent from EU users before storing or even processing their data outside the EU. If the user declines? Their data must always (and only) reside within the EU.
If you’re caught not complying with GDPR, you may face fines of either 4% of annual global turnover or €20 million –– whichever is greater.
The broader global regulatory trend is also moving in this direction. Chinese and Russian data privacy laws, for example, also require you to keep their citizens' data housed within their countries. For global businesses –– or businesses that aspire to be global –– a single-region deployment probably isn’t going to cut it.
To comply with increasingly complex regulations, you’re left to choose from some unattractive option:
Foregoing huge customer bases and global expansion
Facing crippling fines
Engineering unwieldy, complex, and potentially fragile domiciling logic in your applications
…or you could consider an option that actually presents upside to your team:
Using a distributed database in a multi-region deployment with data domiciling
So: Are CDN-like multi-region database deployments worth it?
The answer is: it depends.
Not everyone faces the concerns discussed above with equal dread. Particularly for applications and services that aren’t critical to the business, some companies may be willing to accept the costs of downtime, or the user dissatisfaction associated with higher latencies, or the limitation of not being able to expand into some markets due to regulatory concerns.
For everyone else––businesses of any size who are concerned with the experience of their users across the globe (or even across a single country)––multi-region deployments improve crucial elements of your business.
But how can you get CDN-like multi-region performance out of your database without adding a ton of complexity to your application (and by extension a ton of cost, ops work, etc.)?
How to achieve optimal database performance with CDN behavior
As we mentioned at the top of this post, there have been many attempts to overcome the obstacles of deploying a database to multiple regions, but most solutions make difficult-to-accept compromises.
Let’s take a look and assess some of the common options:
“Cloud-native” databases
Many “cloud-native” databases tout survivability as a selling point, because they run across “multiple zones.” Particularly when filtered through the lens of marketing, this often gives the impression that a given cloud database can be distributed across the globe. However, they often aren’t –– the “zones” they refer to are Availability Zones (AZs), and they’re often all located in the same geographical area.
There are caveats to this, of course. “Cloud native” is a broad term, and some cloud-native databases –– including CockroachDB, of course –– do support multi-region deployments.
There are also alternative deployment methods that get you closer to multi-region –– with Amazon RDS, for example, you can create read-only replicas that cross regions. But this approach is still effectively single-region for writes, which means it comes with the same downsides as single-region deployments for workloads that include a significant number of writes.
This type of approach also risks introducing anomalies because of asynchronous replication. For some use cases, that’s a totally acceptable trade-off, but for critical business systems like payment processing, anomalies can equal millions of dollars in lost revenue (or fines if you’re audited).
Go with NoSQL
NoSQL was conceived as a set of principles to build high-performing distributed databases, meaning it could easily take advantage of CDN-like multi-region deployments. However, the technology achieved this by forgoing data integrity. Without consistency, NoSQL databases are a poor choice for tier-zero and business-critical applications like payments, IAM, inventory management, metadata, etc.
For example, NoSQL databases can suffer from split-brain during partitions (i.e. availability events), with different nodes having different data that becomes impossible to reconcile. When partitions heal, you might have to make ugly decisions: which version of your customers' data to you choose to discard? If two partitions received updates, it’s a lose-lose situation.
Inconsistent data also jeopardizes an application’s recovery point objective (RPO, i.e. the point in time of your last backup). If your database is in a bad state when it’s backed up, you can’t be sure how much data you’ll lose during a restore.
That said, if an application can tolerate inconsistent data, NoSQL is a valid option that can make it relatively simple to distribute data geographically and enjoy “CDN-like” advantages.
Shard your relational databases
Sharded relational databases come in many shapes and can suffer from as many different types of ailments when deployed across regions: some sacrifice replication and availability for consistency, some do the opposite. Many will require a significant amount of manual work and application refactoring, because they weren’t originally designed with distributed data (or even cloud deployments) in mind.
Sharding your existing MySQL or Postgres database, for example, may be a valid option in the short term, but it’s something that companies must consider carefully. What are the costs of all of that manual work? What will the ops requirements be? And what will the costs be the next time you want to scale up or add a new region and have to do at least some of that manual work all over again?
Use CockroachDB
One option to consider for a multi-region database is CockroachDB, which uniquely meets all of the requirements for a multi-region deployment. (This is not a coincidence; it was built that way from the ground up to address the inherent shortcomings traditional relational databases have when it comes to distributing data).
CockroachDB lets you deploy to multiple regions and ensure all data is kept close to all users without locking you into a specific cloud vendor (or the places they have data centers). It offers stronger consistency and lets you control where your data is laid out with our geo-partitioning feature.
And all of that can be accomplished with simple SQL commands – all of the actual distibution and the work of maintaining consistency between nodes happens automatically under the hood, meaning very little manual work is needed. From an application perspective, a multi-region CockroachDB database can be treated just like a single-instance Postgres database.
(If you’re using a multi-region deployment, be sure to check out our multi-region deployment topology docs.
And if you don’t want to deal with the hassle of deploying and managing CockroachDB yourself, managed options like CockroachDB dedicated and serverless exist to take all of that work out of your hands, so that you can focus more on building the applications that matter to your business.
Evaluating a distributed database
As we’ve shown above, there are lots of options available for when your applications need to provide speed and availability to a global audience. When shopping for a distributed database or evaluating your options for scaling, remember to keep the following characteristics in mind. A truly distributed database should:
Deploy anywhere
Reduce latency by performing reads and writes close to users (while still enforcing consistency, even across a distributed deployment)
Maintain uptime by tolerating faults
Offer granular control over geographical placement of your data for regulatory compliance
Learn more about how CockroachDB helped a sports-betting company speed up its expansion using a multi-region deployment:


