
Moving and processing data between systems is a common pain point. Users need up-to-date data across systems for use in business analytics, for event-driven architectures, for creating audit trails, or for archiving data. One way to do that is to set up an external service that regularly polls the database for changes.
If you’re using CockroachDB, you can just use changefeeds. Changefeeds are built in natively, removing the need to set up, manage, and monitor an external change data capture system. They are quick and easy to use. But, as easy as they are, we hear time and again that it could be easier and more cost-efficient to run your data pipelines.
The problem is that today you are forced to stream more data than you necessarily want to (the entire table), in a predetermined format. And you often need to set up external tools or write custom sidecar processes to run operations on that data. These factors increase the cost, complexity, and setup time for your data stream.
Introducing CDC Queries
We recently introduced CDC Queries to reduce the cost & complexity of your data pipelines. CDC Queries let you:
Filter data you do not need from your stream
Chose the schema for your stream
Transform data upfront
With this capability in hand, total cost of ownership (TCO) and time-to-value for some applications can be significantly reduced with little effort.
How to simplify a fintech pipeline for fraud and money laundering checks
Let’s take, for example, a fintech company that processes payments. When a customer makes a payment, this company first saves that transaction information to their database. They additionally save some of the information about the transaction in a custom-event format in an outbox table. They build a sidecar service to poll the outbox table every five minutes for changes waiting to be streamed. The service picks those changes up and sends the new events to a fraud checking service, an anti-money-laundering service, and other important services.
Although this works, the cost and complexity of their data pipeline could be significantly reduced. Here are three examples:
Use CockroachDB changefeeds
. By using changefeeds, which are native to CockroachDB, there is no need to create a custom polling service for the outbox table. Instead, we need only a simple changefeed and send the messages directly to each service. Native changefeeds have the added benefit of being more scalable, fault-tolerant, and up-to-date with the database.
Remove the outbox table
. With CDC Queries, the outbox table is no longer necessary to create a custom-event format. This means we do not need to store a second copy of our data in the database. With CDC Queries, you can set the metadata and structure directly in the changefeed.
CREATE CHANGEFEED INTO ‘webhook-https://[endpoint]’ AS SELECT
cdc_updated_timestamp()::int AS event_timestamp,
‘users’ AS table,
IF(cdc_is_delete(),’delete’,’create’) AS type,
jsonb_build_object(‘email’,email, ‘admin’, admin) AS payload
FROM users;
In this example, our message will include metadata (the timestamp for the event, the name of the table, and whether this event was a delete or an update) and a payload column with the event data we want in json format.
Filter out unneeded messages
. CDC Queries allows you to set filters on things like whether a message is a delete message or not, or on certain criteria (such as only transactions above a certain dollar amount). This significantly cuts down the number of messages we send to our services, reducing the network, processing, and storage costs of unnecessary messages.
The simplified pipeline would instead look like this: Customer makes a payment -> transaction information is saved in the database -> necessary event information is sent directly to the services that need it.
How to cut the cost of streaming to a data warehouse by 40%
Consider this: You want to stream user data to an OLAP data warehouse (in this case into Google Pubsub and then Google BigQuery) for use in running business analytics. However, only a subset of the data is relevant for analysis. In fact, some of the information stored in your user table is sensitive information, that would create complicated compliance concerns if it was replicated off of your core database. Additionally, you want to pre-process some of the data before putting it into BigQuery.
RELATED
Forward Indexes on JSON columns
CDC Queries can be used to transform and filter out unneeded/unwanted data upfront, with a single SQL command. This significantly reduces TCO by:
Reducing throughput costs
Reducing storage costs of retained messages
Reducing cross-regional egress costs if applicable
Removing the need to build a DataFlow template to transform the data and/or remove the unwanted columns
Reducing storage costs in BigQuery
In the vanilla scenario, we would use changefeeds to stream changes to Google Pubsub, process our data using Dataflow, and finally store that data in BigQuery for use by the business analytics team.
With CDC Queries, we can first reduce the amount of data we send to Google Pubsub by filtering out columns we don’t need upfront. We can replace the need for Dataflow by adding the pre-processing to our changefeed as well. In the second scenario, we can ingest our messages straight from Google Pubsub to BigQuery.
Our changefeed would look something like this:
CREATE CHANGEFEED INTO ‘gc-pubsub://[endpoint]?region=us-east1&topic_name=bigquery’
WITH schema_change_policy=stop
AS SELECT column1, column2,
(column3 + column4 - column5) as aggregate,
(column6 + column7) as total,
FROM table;
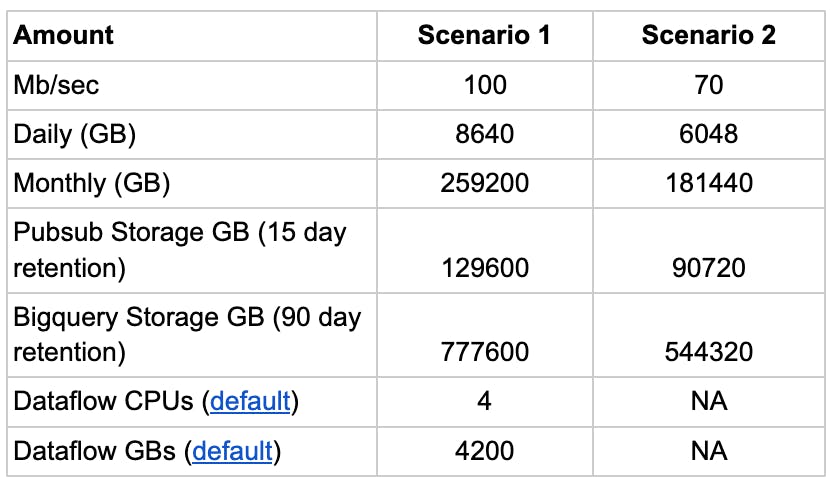
Calculating out the difference
Let’s say that with this filtering and pre-processing, we reduce our message size by 30%. Bringing the total data we send to Google Pubsub down from 100 mb/sec -> 70 mb/sec. We also remove the need to use Dataflow to process the messages. If we crunch out the numbers, we can reduce our pipeline costs by 40%.
This example illustrates that CDC Queries are an excellent tool for simplifying and cutting down data pipeline costs. Although actual savings achieved will depend on the specific workload. Check out 8 ways to use CDC Queries for more powerful data streaming for more ways to use CDC Queries in your data pipeline.

CDC Queries Demo
If you’d like to learn more about how and when to use CDC Queries check out this quick demonstration I made:
Also, if you’re interested in learning more about changefeeds and change data capture check out these resources:


