

In 2016, LinkedIn chose not to comply with Russia's requirement for data to be stored locally. As a result, they were kindly blocked from doing business in the country. Facebook and Twitter, on the other hand, both decided that compliance in Russia is worth the effort. Neither has fully met Russia's requirements but they have shown enough progress to avoid being blocked.
This is an example of the kind of decision that data localization laws force companies to make. Should we spend the time and money to be compliant or should we do an about-face? Giving up on substantial markets is not an easy thing to do in capitalist economies, where the money you lose by slowing down often seems more important than the money you already made.
Right now roughly 69% of the world's population lives within borders governed by data privacy regulations. That percentage is likely to grow, and the existing restrictions are likely to strengthen their grip in the future. The sweeping freedom of the world-wide-web has been tamed and turned into a collection of disparate country-regulated-webs. LinkedIn is just one of many companies deciding to simply walk away from a market.
Digital businesses with global reach or global ambitions are in a difficult position. Many are not equipped with a database that scales horizontally. Even if you're using a distributed database there are costs of compliance that might outweigh the financial opportunities. The consequence of this reality is that companies are delaying their expansion into some countries, and abandoning others altogether.
To Comply Or Not To Comply?
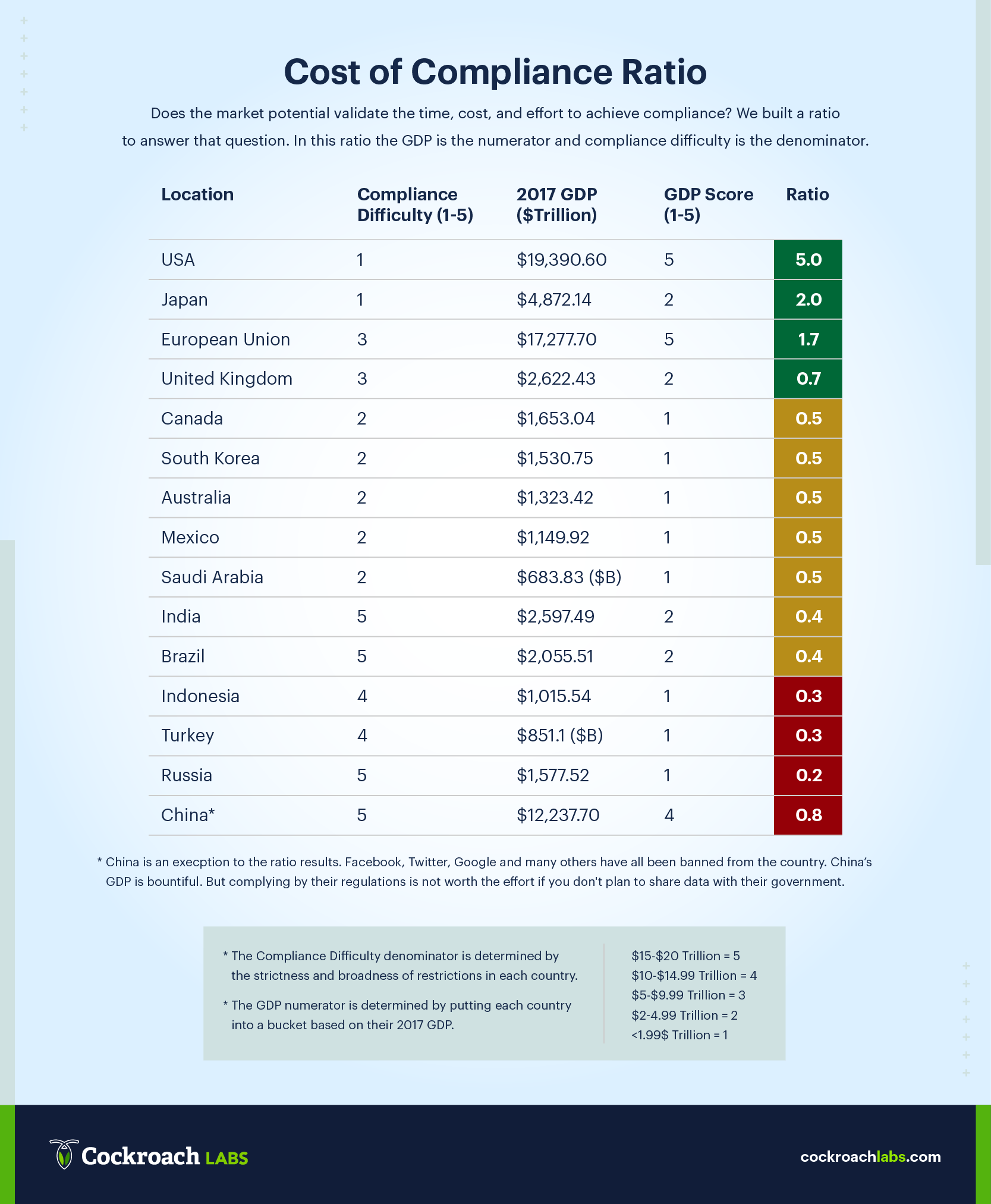
The decision to pursue or abandon compliance involves mathematical gymnastics unique to each business. Without knowing the details of your database architecture and your product roadmap we can't accurately calculate the cost/benefit of becoming compliant. That being said, there are two important factors that will inform the compliance conversation no matter what business you're in: 'compliance difficulty' & 'market opportunity.' We've taken both of those factors and built a simple ratio to help you visualize the compliance decision.
Cost of Compliance Ratio & Heat Map
Market Opportunity ÷ Compliance Difficulty = X
In our Cost of Compliance Ratio 'market opportunity' is assigned a number based on the Gross Domestic Product of each country. 'Compliance difficulty' is assigned a number based on the broadness and strictness of the regulations in each country. 'Market opportunity' is our numerator and 'compliance difficulty' is our denominator. We realize that this is not Dijkstra's Algorithm or Newton's Method. Our goal is simply to give you a bird's eye view of what the compliance challenges look like across the globe.
In the infographic below you'll find our ratio, as it applies to 15 countries with substantial GDP's. Below the chart, you'll find our Compliance R.O.I Heat Map in which we took the ratio data and applied it to a map.

The substance for each of these infographics was derived from this white paper about the current state of data localization regulations. These infographics are not hearty enough on their own to enable you to make a decision about compliance. Our hope is that these images and the corresponding white paper help you to have an informed discussion about what your compliance strategy will be.
We would love to be a resource while you go through the process of deciding where and how to comply with data localization regulations. If you're interested in learning more you can start with this blog about the Future of Data Protection Law or this blog about Compliance Strategies.


