

The raw performance of a database starts to matter a whole lot less if that database is down: If you’re fast and you’re down, you’re still down. To be clear, raw performance still matters, but traditional benchmarks don’t measure true customer experience when conditions are less than ideal.
Earlier this year Cockroach Labs released a new methodology for benchmarking modern databases that shifts from measuring peak performance to measuring how infrastructure performs under pressure. Any benchmarking claims from vendors should be viewed with a pinch of salt, so we made it easy to run the test and see the results yourself as our benchmark methodology is fully documented and open.
Following the introduction of our Performance under Adversity Benchmark we were wondering how our distributed SQL counterparts would fare during the same tests...
So we tested them.
CockroachDB vs. Oracle GDD (23ai)
The results were more striking than we anticipated. CockroachDB offers over 5x the resilience of Oracle GDD when subjected to a suite of chaos tests including pod failures, network partitions, and disk stalls.
Before we dive deeper into what we discovered, it makes sense to clarify what we mean by “downtime” here. During the course of these resilience tests, we have a very simple workload trying to make one UPDATE request every second. Downtime can arise from either of the following scenarios:
An immediate request failure (e.g. a node is shutdown while a request is being routed to it). This type of failure will result in a small amount of downtime (measured in milliseconds) being added to the total amount of downtime experienced.
A request timeout failure. This type of failure will add the amount of time the request was left hanging (e.g. a maximum of one second for a request with a one-second timeout) to the total amount of downtime experienced. This is a common type of failure that will most greatly impact a database’s experienced downtime, and is a result of the request latency being so badly affected by a node having failed or a disk having stalled, that it simply times out. This is the point where, unless your database is built to handle such eventualities, you’ll start to breach your application Service Level Agreements (SLAs), which – for some of our large Finserv customers – can be in the low milliseconds.
Who were the contestants?
In the tests below, we pitted CockroachDB v25.3.0 against Oracle GDD 23ai. (NOTE: 23ai is the first version of Oracle that can support GDD in a Raft configuration.)
Although Oracle’s database solution is a mature technology having been developed over the past 40 years, it is generally complex to use without specialized knowledge. After a week of unsuccessful wrangling, we turned to an expert Oracle consultancy to ensure we were following Oracle best practices and to give Oracle the best chance of success (or at least a better chance of success than my initial attempts could).
Skip ahead three weeks, and they too had to throw in the towel after battling with a Kubernetes deployment of 23ai both inside and outside of Oracle Cloud Infrastructure (OCI). We decided to use the freely available version of 23ai to run our tests, which complicated things... Our reasons for choosing to run these tests using the free edition outside of OCI are numerous but include:
Other members of our team (and the wider community in general) can freely reproduce the benchmarks and scrutinize our results.
We’ve used similar editions for all of the other distributed SQL databases we’ve tested.
Oracle themselves have this to say about the free editions of their GDD containers:
But what if you could explore its full potential without any upfront investment? Enter Oracle's Globally Distributed Database free images—tailored to give developers and enterprises an easy, cost-effective gateway into the world of distributed database management. These free images allow you to rapidly deploy and test the full range of database features in your environment, across multiple platforms, without incurring any costs.
Oracle describes GDD’s free edition as offering “the full range of database features,” with some limitations on database count and serving as an entry point into GDD for people to play with and better understand the technology. Because running chaos tests like network partitions and disk stalls from within OCI wouldn’t be straightforward, we decided to use the free version of 23ai for our tests.
How did we test CockroachDB vs. Oracle GDD?
We ran a series of tests to determine the behavior of CockroachDB and Oracle GDD under a variety of real world failure scenarios: node outages, network partitions, and disk stalls. Interestingly, failures that don’t immediately bring their database offline seem to worry customers more than the simple binary types of on and off failures. These “grey failures” slowly gnaw at their latencies and degrade their services, rather than completely taking them offline.
For each test type, all nodes are tested, one at a time, with a short break to allow for any necessary recovery before moving onto the next node. All errors and downtime are calculated as an average of three separate runs and represent the total downtime experienced by the workload across all nodes. Two common Oracle errors were encountered during the tests, and here’s how they added to the total number of errors and downtime:
ORA-03996 - cannot perform DML operations during recovery of the leader for replication unit N
During the recovery of a shard’s replication log, no Data Manipulation Language (DML) requests are possible. If 10 such errors are encountered, this would add 10 errors to the total error count and 10 seconds of downtime to the total downtime duration.
ORA-01013 - User requested cancel of current operation
A request took longer than a client-side timeout to complete. For each of these errors encountered, one error is added to the total error count and the amount of time the application was waiting for the request to complete is added to the total downtime duration.
Oracle GDD demonstrated automatic recovery in all of the tests, thanks to specific workarounds in our implementation given the limitations of the free edition. Yet it still encountered more errors and downtime than CockroachDB.
Node failures - The first couple of test scenarios measure each database’s resilience in response to node failures. A database node could fail for any number of reasons, from application to power failures. We stop nodes both gracefully (e.g. giving them a few seconds to get their affairs in order) and abruptly.
We’ll start by sharing the results of the abrupt node failure tests. During these tests, a node is simply killed without any time to drain or notify other nodes of their situation. This outage scenario can be caused by everything from bugs to power failures and, unless handled correctly, will lead to significant downtime.
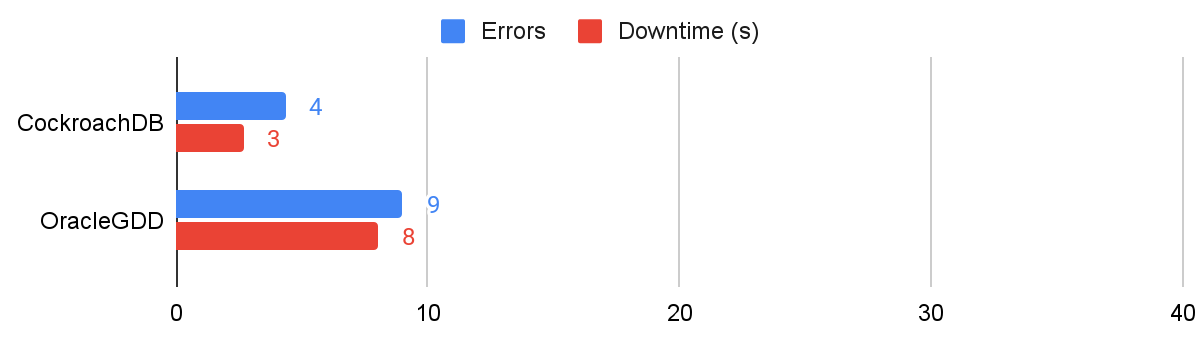
Results showing errors and downtime for immediate node failures
Next we’ll look at the more graceful node failure experiments. These kinds of node failures simulate the impact of common events like rolling restarts and security patching, so the results would ideally show zero downtime, indicating no impact to customers. CockroachDB will occasionally require a request retry in the event that a request is routed to a node that is in the process of being removed from the cluster, but across these three runs we weren’t able to cause a failure. Oracle GDD, on the other hand, encountered 15 errors with an average 6s of downtime (primarily due to request timeouts):
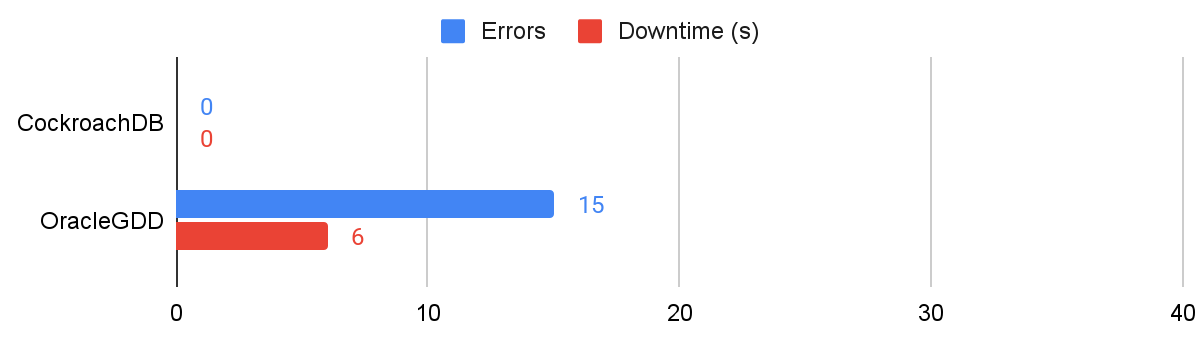
Results showing errors and downtime for graceful node failures
The last node failure test is a repeated node failure. These are implemented against each database as 10 back-to-back graceful node failure experiments, but instead of remaining down for 60s they’re paused for 5s, and unpaused for 1s. Oracle GDD encountered 78 errors averaging 87s of downtime (primarily due to DML operations not being possible during leader recovery).
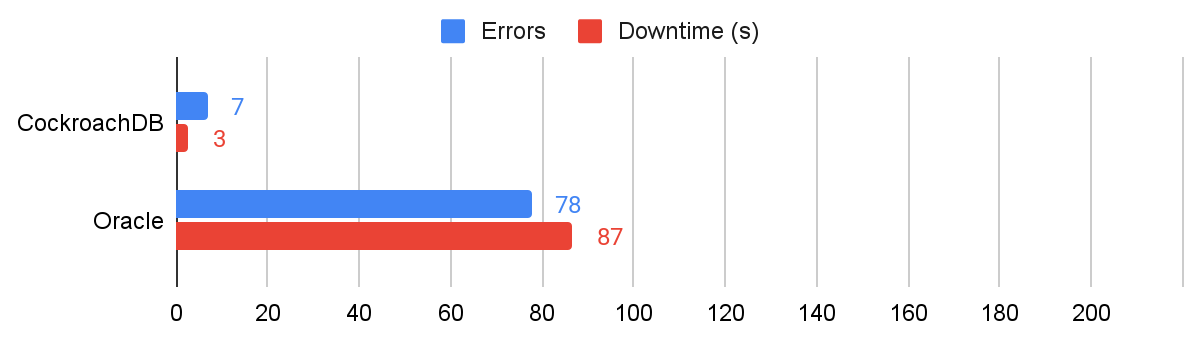
Results showing errors and downtime for repeated node failures
Network issues - Another common type of failure, we found that 38% of all downtime is caused by network issues. As with node failures, these come in many flavors although we decided to stick with three:
symmetric network partitions
asymmetric network partitions
network bandwidth restrictions
A symmetric partition is where the network is bidirectionally blocked between hosts (node A can’t talk to node B and node B can’t talk to node A). An asymmetric partition is where the network is unidirectionally blocked (node A can talk to node B but node B can’t talk to node A). 🤢
In the following tests, each node had its connection bidirectionally severed from the other nodes. CockroachDB encountered 10 errors and a total of 10s of downtime during this experiment, while Oracle GDD encountered 18 errors and a total 20s of average downtime.
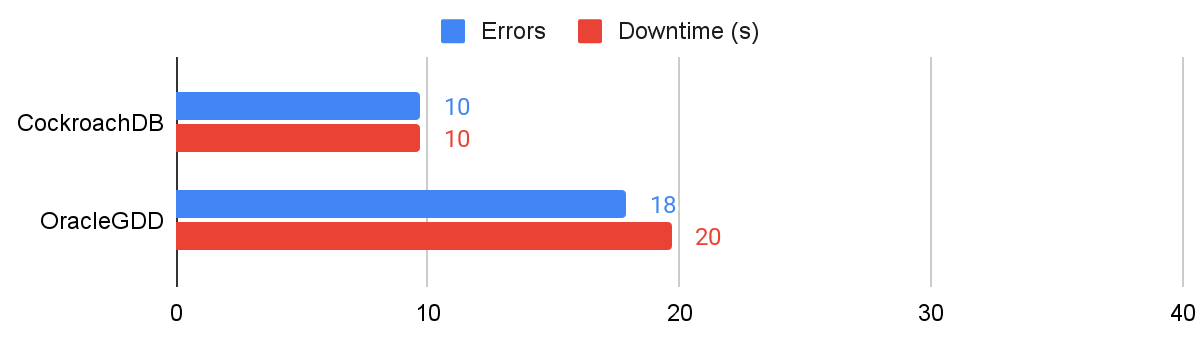
Results showing errors and downtime for symmetric network partitions
We also performed an asymmetric network partition between each node and the others. This time, CockroachDB experienced 14s of downtime, and Oracle GDD exhibited similar behavior to the symmetric partition test, encountering 20 errors and a total 34s of average downtime.
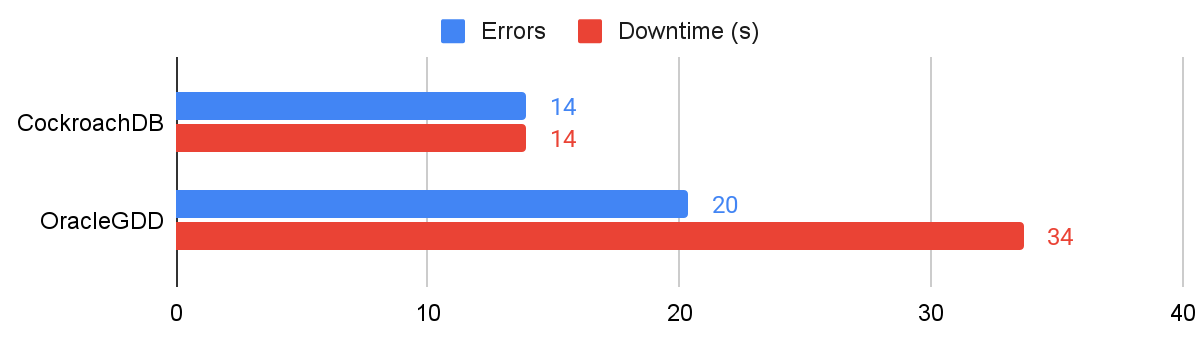
Results showing errors and downtime for asymmetric network partitions
We follow the partition tests with a particularly nasty bandwidth restriction test to see how each database copes with severe network congestion. During this test, we limit bandwidth to 256 bits per second with a burst size of 10 bytes and a queue limit of one byte. The high number of errors encountered by GDD is caused by a failure to perform DML operations for replication units, because connections between followers and leaders are disrupted.
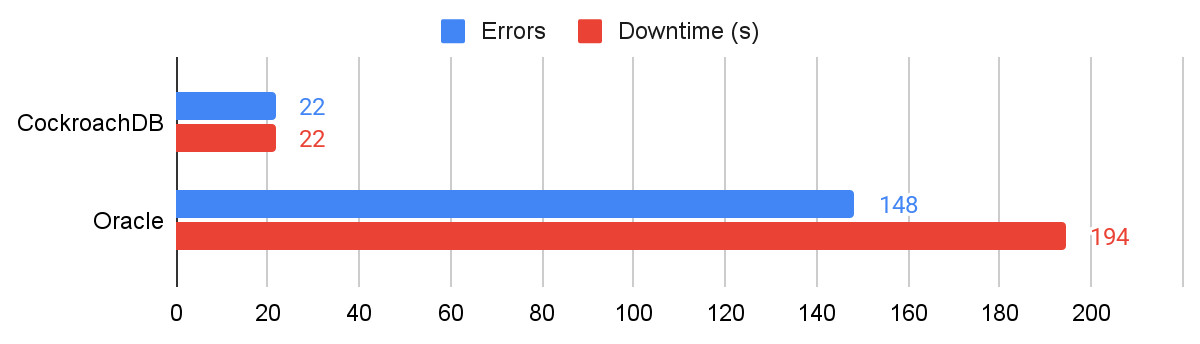
Results showing errors and downtime for bandwidth restriction
Disk stalls - Another grey failure which can and will affect your workloads at some point (based on our experience running CockroachDB Cloud). If you’re running in the cloud and using block storage, these disk stall errors occur far more frequently than you might expect. They also come in a variety of flavors, although in this test we’re simply adding latency or restricting disk operations, depending on the database and the tools available.
In our disk stall test, we introduced latency to CockroachDB’s disks and limited the number of read/write operations for Oracle GDD’s disk (limited in GDD’s case owing to v1 of cgroups being available rather than v2). These tests, while slightly different in their implementation, still offer insights into how each database handles disk disruptions. CockroachDB encountered an average of less than one error and less than 1s of downtime, while Oracle GDD experienced 12 errors and an average 21s of downtime.
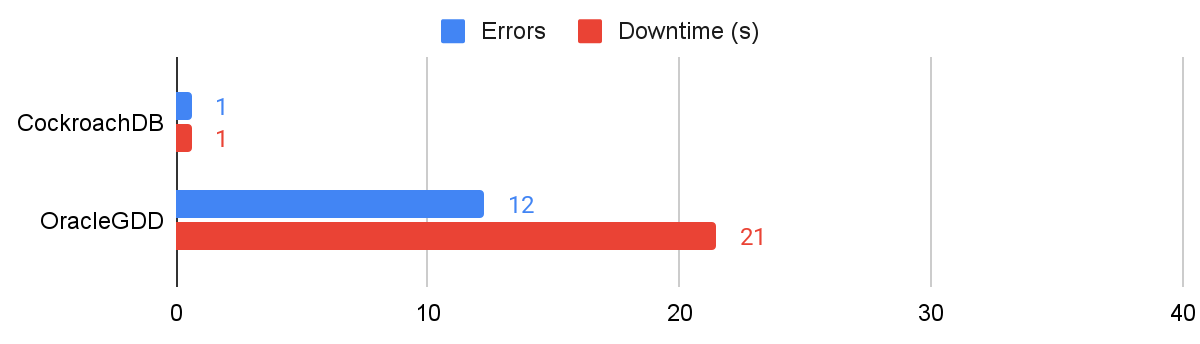
Results showing errors and downtime for disk latency/throughput restriction
The sum of all errors and downtime across the previous tests can be seen in the following chart. CockroachDB encountered an average total of 56 errors resulting in an average total of 51s of experienced downtime, while Oracle GDD encountered an average of 300 errors resulting in an average total of 369s (just over six minutes) of experienced downtime.
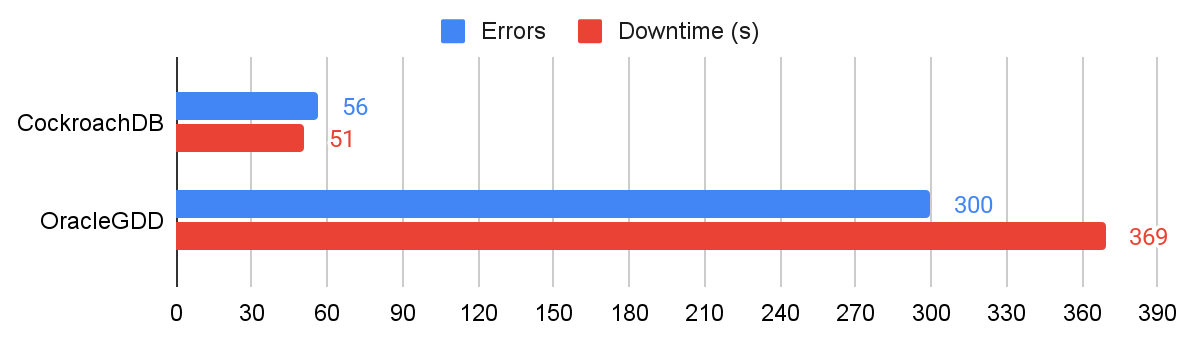
The total number of errors and downtime for all experiments
The Setup
Given that each CockroachDB node is identical and performs the same tasks, the CockroachDB configuration for this test is fairly straightforward. We ran the tests in Google’s Kubernetes Engine (GKE) and deployed three nodes across three Availability Zones (AZs). For the chaos side of things, we used the wonderful Chaos Mesh, which has fantastic support for Kubernetes-based applications.
Our CockroachDB cluster involved three identical nodes running v25.3.0 (the current released version at the time of the testing), spread across three pods in a statefulset.
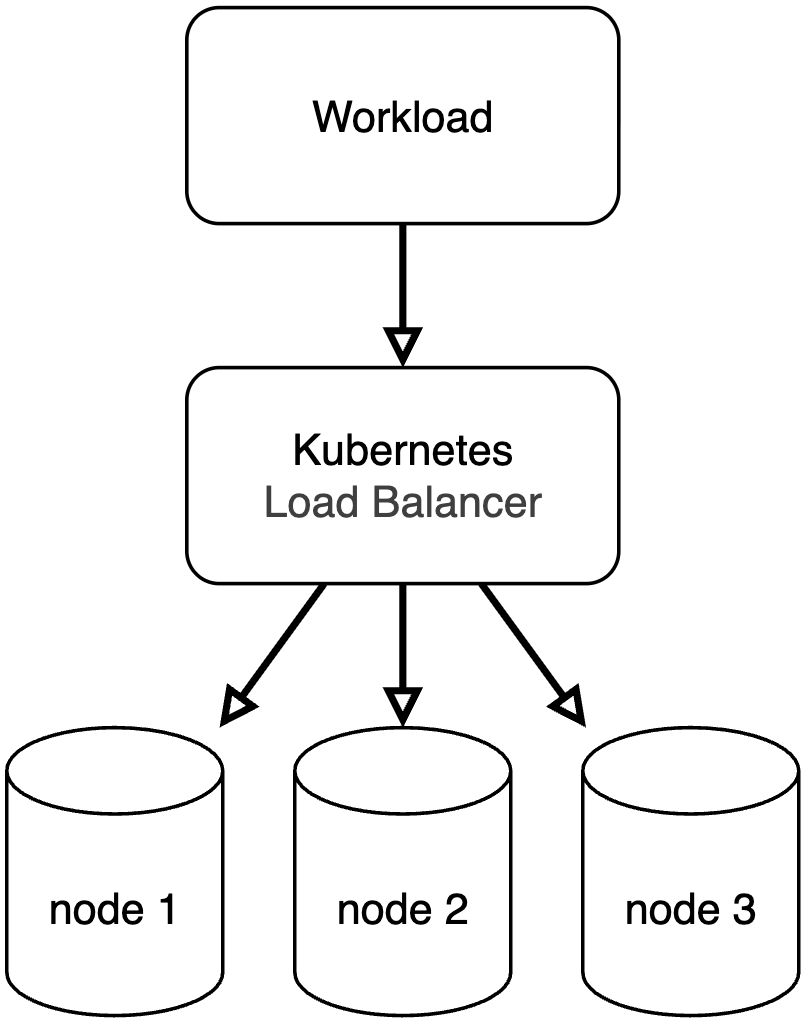
Our CockroachDB configuration
Oracle GDD requires a more involved configuration, to say the least. Rather than each component being an equal part of a larger whole, it’s separated into three distinct responsibilities (implemented across two distinct components). The result is a patchwork Frankenstein that requires specialists just to stand it up:
Shard Directors / Global Service Managers (GSM) - The central load-balancing router for requests
Shards - Independent Oracle databases
Catalogs - A separate Oracle database that stores cluster metadata and maintains information about the cluster’s topology
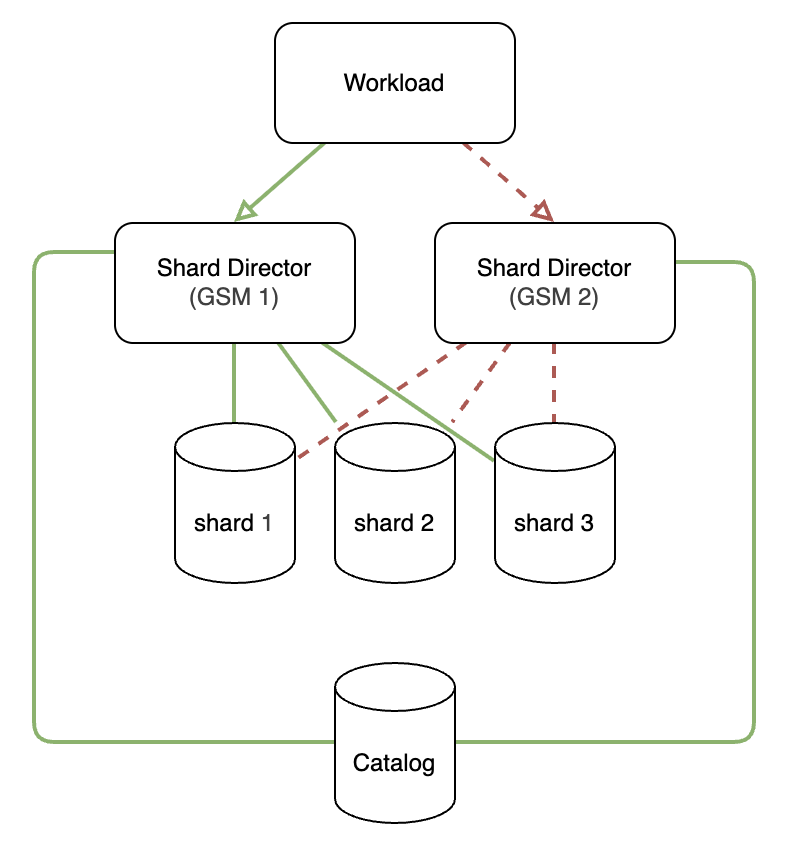
Our Oracle GDD configuration
Given the difficulties we faced deploying Oracle GDD onto Kubernetes, we fell back to a Podman installation using podman-compose. As such, we were required to manually inject chaos experiments via podman commands, iptables, and cgroups. The resulting chaos conditions in Podman resemble those in Kubernetes but they are, of course, not identical.
Our Oracle GDD cluster comprises a primary and standby GSM, three shards, and a Shard Catalog. All of these were running 23.7.0.0.
As a side note, the purpose of a distributed database is resilience through consensus. It’s worth noting that the Shard Catalog does not support Raft and must be configured to run with a Standby to achieve high availability. This results in the risk of higher downtime and data loss during an outage and extra cost to the configuration. Our workload is not running DML statements, which would suffer in the event of a Catalog outage. As such we haven’t built in HA for the Catalog during these tests.
See how to migrate from Oracle to CockroachDB, step-by-step:
How do you calculate price per resilience?
As with performance, pure resilience starts to matter less if the associated costs start to spiral. When deciding on a distributed SQL database you should be factoring:
Setup and maintenance complexity - How easy is the software to install and maintain? Do you need a large team of experts just to keep the lights on? Is the software available to run on your preferred infrastructure? Can you run across clouds for resilience to cloud-provider failure, and to mitigate cloud concentration risk?
Cost of downtime - Do you know how much an hour’s worth of downtime will cost your business? For some of our customers and as mentioned in our 2025 State of Resilience survey, downtime costs can run into the millions of dollars every minute. From a TCO perspective your distributed SQL database might actually be earning you money.
Which failure scenarios will hurt the most? - If a database doesn’t protect you against the scenarios that worry you the most, you’ll continue to worry about them. Ask your vendors to demonstrate their resilience against these failures and hold them accountable.
Databases are often benchmarked using a Price per Performance comparison, yet the true total cost of ownership needs to factor in the cost of downtime. The less downtime a database encounters during testing, the less downtime it’s likely to exhibit when running your production workloads - and the greater the ongoing savings.
It’s no secret that Oracle is an expensive and complex database. For those wishing to avoid Oracle’s high cost and complexity, there is another option: Give CockroachDB a try and see how its lower cost and 5x higher resilience could benefit your business.
Try CockroachDB Today
Spin up your first CockroachDB Cloud cluster in minutes. Start with $400 in free credits. Or get a free 30-day trial of CockroachDB Enterprise on self-hosted environments.
Rob Reid is Cockroach Labs’ Technical Evangelist and a software developer from London, England. In his career, he has written backend, frontend, and messaging software for the police, travel, finance, commodities, sports betting, telecoms, retail, and aerospace industries. He is the author of "Practical CockroachDB: Building Fault-Tolerant Distributed SQL Databases" (Apress) and "Understanding Multi-Region Application Architecture" (O’Reilly) and has two CockroachDB tattoos.


